网络IO和磁盘IO详解
1. 缓存IO
缓存I/O又被称作标准I/O,大多数文件系统的默认I/O操作都是缓存I/O。在Linux的缓存I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。
读操作:操作系统检查内核的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。
写操作:将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令(详情参考《【珍藏】linux 同步IO: sync、fsync与fdatasync》)。
缓存I/O的优点:1)在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;2)可以减少读盘的次数,从而提高性能。
缓存I/O的缺点:在缓存 I/O 机制中,DMA 方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输,这样,数据在传输过程中需要在应用程序地址空间(用户空间)和缓存(内核空间)之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的。
2. 直接IO
直接IO就是应用程序直接访问磁盘数据,而不经过内核缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序缓存的数据复制。比如说数据库管理系统这类应用,它们更倾向于选择它们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
直接IO的缺点:如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,这种直接加载会非常缓存。通常直接IO与异步IO结合使用,会得到比较好的性能。(异步IO:当访问数据的线程发出请求之后,线程会接着去处理其他事,而不是阻塞等待)
下图分析了写场景下的DirectIO和BufferIO:

首先,磁盘IO主要的延时是由(以15000rpm硬盘为例): 机械转动延时(机械磁盘的主要性能瓶颈,平均为2ms) + 寻址延时(2~3ms) + 块传输延时(一般4k每块,40m/s的传输速度,延时一般为0.1ms) 决定。(平均为5ms)
而网络IO主要延时由: 服务器响应延时 + 带宽限制 + 网络延时 + 跳转路由延时 + 本地接收延时 决定。(一般为几十到几千毫秒,受环境干扰极大)
所以两者一般来说网络IO延时要大于磁盘IO的延时。
用Redis作缓存是因为,Redis就是设计来做缓存的阿。
Reids作缓存的几大优势:
1, 简单的K-V式数据存储方式,单一的 get set 模式比传统SQL性能提升显著
2, 纯in mem db 形式,将数据缓存在内存中,减少服务器磁盘IO时间。
更新一下数据源:
<img src="https://pic4.zhimg.com/50/v2-0bca913bed8f7d40ac523dbb7688da07_hd.jpg" data-rawwidth="1008" data-rawheight="418" class="origin_image zh-lightbox-thumb" width="1008" data-original="https://pic4.zhimg.com/v2-0bca913bed8f7d40ac523dbb7688da07_r.jpg">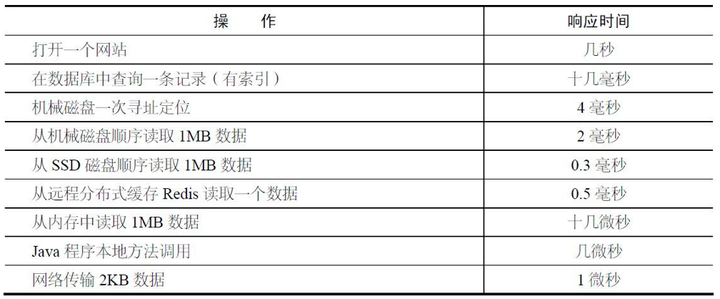
ref :
《大型网站技术架构:核心原理与案例分析》
链接:https://www.zhihu.com/question/47589908/answer/114768530
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Google的Jeff Dean给的一些数据(一个talk的ppt, "Designs, Lessons and Advice from Building Large Distributed Systems" 23页),可以看到1Gbps的网络比硬盘的bandwidth高了很多,记住这些数据对设计高性能系统和对系统的性能估算很有帮助。
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns
Mutex lock/unlock 25 ns
Main memory reference 100 ns
Compress 1K bytes with Zippy 3,000 ns
Send 2K bytes over 1 Gbps network 20,000 ns
Read 1 MB sequentially from memory 250,000 ns
Round trip within same datacenter 500,000 ns
Disk seek 10,000,000 ns
Read 1 MB sequentially from disk 20,000,000 ns
Send packet CA->Netherlands->CA 150,000,000 ns
PIO与DMA
有必要简单地说说慢速I/O设备和内存之间的数据传输方式。
PIO
我们拿磁盘来说,很早以前,磁盘和内存之间的数据传输是需要CPU控制的,也就是说如果我们读取磁盘文件到内存中,数据要经过CPU存储转发,这种方式称为PIO。显然这种方式非常不合理,需要占用大量的CPU时间来读取文件,造成文件访问时系统几乎停止响应。DMA
后来,DMA(直接内存访问,Direct Memory Access)取代了PIO,它可以不经过CPU而直接进行磁盘和内存的数据交换。在DMA模式下,CPU只需要向DMA控制器下达指令,让DMA控制器来处理数据的传送即可,DMA控制器通过系统总线来传输数据,传送完毕再通知CPU,这样就在很大程度上降低了CPU占有率,大大节省了系统资源,而它的传输速度与PIO的差异其实并不十分明显,因为这主要取决于慢速设备的速度。
可以肯定的是,PIO模式的计算机我们现在已经很少见到了。
标准文件访问方式

具体步骤:
当应用程序调用read接口时,操作系统检查在内核的高速缓存有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回,如果没有,则从磁盘中读取,然后缓存在操作系统的缓存中。
应用程序调用write接口时,将数据从用户地址空间复制到内核地址空间的缓存中,这时对用户程序来说,写操作已经完成,至于什么时候再写到磁盘中,由操作系统决定,除非显示调用了sync同步命令。

内存映射(减少数据在用户空间和内核空间之间的拷贝操作,适合大量数据传输)
Linux内核提供一种访问磁盘文件的特殊方式,它可以将内存中某块地址空间和我们要指定的磁盘文件相关联,从而把我们对这块内存的访问转换为对磁盘文件的访问,这种技术称为内存映射(Memory Mapping)。
操作系统将内存中的某一块区域与磁盘中的文件关联起来,当要访问内存中的一段数据时,转换为访问文件的某一段数据。这种方式的目的同样是减少数据从内核空间缓存到用户空间缓存的数据复制操作,因为这两个空间的数据是共享的。
内存映射是指将硬盘上文件的位置与进程逻辑地址空间中一块大小相同的区域一一对应,当要访问内存中一段数据时,转换为访问文件的某一段数据。这种方式的目的同样是减少数据在用户空间和内核空间之间的拷贝操作。当大量数据需要传输的时候,采用内存映射方式去访问文件会获得比较好的效率。
使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行I/O操作,这意味着在对文件进行处理时将不必再为文件申请并分配缓存,所有的文件缓存操作均由系统直接管理,由于取消了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等步骤,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。

访问步骤

在大多数情况下,使用内存映射可以提高磁盘I/O的性能,它无须使用read()或write()等系统调用来访问文件,而是通过mmap()系统调用来建立内存和磁盘文件的关联,然后像访问内存一样自由地访问文件。
有两种类型的内存映射,共享型和私有型,前者可以将任何对内存的写操作都同步到磁盘文件,而且所有映射同一个文件的进程都共享任意一个进程对映射内存的修改;后者映射的文件只能是只读文件,所以不可以将对内存的写同步到文件,而且多个进程不共享修改。显然,共享型内存映射的效率偏低,因为如果一个文件被很多进程映射,那么每次的修改同步将花费一定的开销。
直接I/O(绕过内核缓冲区,自己管理I/O缓存区)
在Linux 2.6中,内存映射和直接访问文件没有本质上差异,因为数据从进程用户态内存空间到磁盘都要经过两次复制,即在磁盘与内核缓冲区之间以及在内核缓冲区与用户态内存空间。
引入内核缓冲区的目的在于提高磁盘文件的访问性能,因为当进程需要读取磁盘文件时,如果文件内容已经在内核缓冲区中,那么就不需要再次访问磁盘;而当进程需要向文件中写入数据时,实际上只是写到了内核缓冲区便告诉进程已经写成功,而真正写入磁盘是通过一定的策略进行延迟的。
然而,对于一些较复杂的应用,比如数据库服务器,它们为了充分提高性能,希望绕过内核缓冲区,由自己在用户态空间实现并管理I/O缓冲区,包括缓存机制和写延迟机制等,以支持独特的查询机制,比如数据库可以根据更加合理的策略来提高查询缓存命中率。另一方面,绕过内核缓冲区也可以减少系统内存的开销,因为内核缓冲区本身就在使用系统内存。
应用程序直接访问磁盘数据,不经过操作系统内核数据缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序缓存的数据复制。这种方式通常是在对数据的缓存管理由应用程序实现的数据库管理系统中。
直接I/O的缺点就是如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘进行加载,这种直接加载会非常缓慢。通常直接I/O跟异步I/O结合使用会得到较好的性能。

访问步骤

Linux提供了对这种需求的支持,即在open()系统调用中增加参数选项O_DIRECT,用它打开的文件便可以绕过内核缓冲区的直接访问,这样便有效避免了CPU和内存的多余时间开销。
顺便提一下,与O_DIRECT类似的一个选项是O_SYNC,后者只对写数据有效,它将写入内核缓冲区的数据立即写入磁盘,将机器故障时数据的丢失减少到最小,但是它仍然要经过内核缓冲区。
sendfile/零拷贝(网络I/O,kafka用到此特性)
普通的网络传输步骤如下:
1)操作系统将数据从磁盘复制到操作系统内核的页缓存中
2)应用将数据从内核缓存复制到应用的缓存中
3)应用将数据写回内核的Socket缓存中
4)操作系统将数据从Socket缓存区复制到网卡缓存,然后将其通过网络发出

1、当调用read系统调用时,通过DMA(Direct Memory Access)将数据copy到内核模式
2、然后由CPU控制将内核模式数据copy到用户模式下的 buffer中
3、read调用完成后,write调用首先将用户模式下 buffer中的数据copy到内核模式下的socket buffer中
4、最后通过DMA copy将内核模式下的socket buffer中的数据copy到网卡设备中传送。
从上面的过程可以看出,数据白白从内核模式到用户模式走了一圈,浪费了两次copy,而这两次copy都是CPU copy,即占用CPU资源。
sendfile

通过sendfile传送文件只需要一次系统调用,当调用 sendfile时:
1、首先通过DMA copy将数据从磁盘读取到kernel buffer中
2、然后通过CPU copy将数据从kernel buffer copy到sokcet buffer中
3、最终通过DMA copy将socket buffer中数据copy到网卡buffer中发送
sendfile与read/write方式相比,少了 一次模式切换一次CPU copy。但是从上述过程中也可以发现从kernel buffer中将数据copy到socket buffer是没必要的。
为此,Linux2.4内核对sendfile做了改进,下图所示
改进后的处理过程如下:
1、DMA copy将磁盘数据copy到kernel buffer中
2、向socket buffer中追加当前要发送的数据在kernel buffer中的位置和偏移量
3、DMA gather copy根据socket buffer中的位置和偏移量直接将kernel buffer中的数据copy到网卡上。
经过上述过程,数据只经过了2次copy就从磁盘传送出去了。(事实上这个Zero copy是针对内核来讲的,数据在内核模式下是Zero-copy的)。
当前许多高性能http server都引入了sendfile机制,如nginx,lighttpd等。

FileChannel.transferTo(Java中的零拷贝)
Java NIO中FileChannel.transferTo(long position, long count, WriteableByteChannel target)方法将当前通道中的数据传送到目标通道target中,在支持Zero-Copy的linux系统中,transferTo()的实现依赖于 sendfile()调用。

传统方式对比零拷贝方式:

整个数据通路涉及4次数据复制和2个系统调用,如果使用sendfile则可以避免多次数据复制,操作系统可以直接将数据从内核页缓存中复制到网卡缓存,这样可以大大加快整个过程的速度。
大多数时候,我们都在向Web服务器请求静态文件,比如图片、样式表等,根据前面的介绍,我们知道在处理这些请求的过程中,磁盘文件的数据先要经过内核缓冲区,然后到达用户内存空间,因为是不需要任何处理的静态数据,所以它们又被送到网卡对应的内核缓冲区,接着再被送入网卡进行发送。
数据从内核出去,绕了一圈,又回到内核,没有任何变化,看起来真是浪费时间。在Linux 2.4的内核中,尝试性地引入了一个称为khttpd的内核级Web服务器程序,它只处理静态文件的请求。引入它的目的便在于内核希望请求的处理尽量在内核完成,减少内核态的切换以及用户态数据复制的开销。
同时,Linux通过系统调用将这种机制提供给了开发者,那就是sendfile()系统调用。它可以将磁盘文件的特定部分直接传送到代表客户端的socket描述符,加快了静态文件的请求速度,同时也减少了CPU和内存的开销。
在OpenBSD和NetBSD中没有提供对sendfile的支持。通过strace的跟踪看到了Apache在处理151字节的小文件时,使用了mmap()系统调用来实现内存映射,但是在Apache处理较大文件的时候,内存映射会导致较大的内存开销,得不偿失,所以Apache使用了sendfile64()来传送文件,sendfile64()是sendfile()的扩展实现,它在Linux 2.4之后的版本中提供。
这并不意味着sendfile在任何场景下都能发挥显著的作用。对于请求较小的静态文件,sendfile发挥的作用便显得不那么重要,通过压力测试,我们模拟100个并发用户请求151字节的静态文件,是否使用sendfile的吞吐率几乎是相同的,可见在处理小文件请求时,发送数据的环节在整个过程中所占时间的比例相比于大文件请求时要小很多,所以对于这部分的优化效果自然不十分明显。
网络IO和磁盘IO详解的更多相关文章
- Linux进程实时IO监控iotop命令详解
介绍 Linux下的IO统计工具如iostat, nmon等大多数是只能统计到per设备的读写情况, 如果你想知道每个进程是如何使用IO的就比较麻烦. iotop 是一个用来监视磁盘 I/O 使用状况 ...
- 网络编程socket基本API详解(转)
网络编程socket基本API详解 socket socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信. socket ...
- [转]网络性能评估工具Iperf详解(可测丢包率)
原文链接:安全运维之:网络性能评估工具Iperf详解:http://os.51cto.com/art/201410/454889.htm 参考博文:http://linoxide.com/monito ...
- 网工最实用最常用的网络命令之一——Ping 命令详解(一)
Ping是Windows.Unix和Linux系统下的一个命令.ping也属于一个通信协议,是TCP/IP协议的一部分.利用“ping”命令可以检查网络是否连通,可以很好地帮助我们分析和判定网络故障. ...
- [转帖]技术扫盲:新一代基于UDP的低延时网络传输层协议——QUIC详解
技术扫盲:新一代基于UDP的低延时网络传输层协议——QUIC详解 http://www.52im.net/thread-1309-1-1.html 本文来自腾讯资深研发工程师罗成的技术分享, ...
- 入木三分学网络第一篇--VRRP协议详解第一篇(转)
因为keepalived使用了VRRP协议,所有有必要熟悉一下. 虚拟路由冗余协议(Virtual Router Redundancy Protocol,简称VRRP)是解决局域网中配置静态网关时,静 ...
- Python网络请求urllib和urllib3详解
Python网络请求urllib和urllib3详解 urllib是Python中请求url连接的官方标准库,在Python2中主要为urllib和urllib2,在Python3中整合成了urlli ...
- UNIX高级环境编程(14)文件IO - O_DIRECT和O_SYNC详解 < 海棠花溪 >
春天来了,除了工作学习,大家也要注意锻炼身体,多出去运动运动. 上周末在元大都遗址公园海棠花溪拍的海棠花. 进入正题. O_DIRECT和O_SYNC是系统调用open的flag参数.通过指定o ...
- linux磁盘分区详解【转】
本文装载自:http://blog.csdn.net/aaronychen/article/details/2270048#comments 在学习 Linux 的过程中,安装 Linux 是每一个初 ...
随机推荐
- jQuery:多个AJAX/JSON请求对应单个回调
原文链接:jQuery: Multiple AJAX and JSON Requests, One Callback 原文日期: 2014年4月15日 翻译日期: 2014年4月22日 翻译人员: 铁 ...
- iOS中判断照片和相机权限
1.照片权限判断 在iOS6之后,app中使用照片(即自带相册)需要用户权限验证,所以我们可以做一个权限判断给出友好的提示或者界面效果. 相册判断需要导入 <AssetsLibrary/Asse ...
- source insight 中tab键的设置
转:http://xinzero.com/source-insight-code-alignment-ended.html source insight代码对齐Tab键终极版 以前也写过一个sourc ...
- javascript算术运算溢出
js中的算术在溢出overflow,下溢underflow或被0整除时不会报错. 当数字结果超过了数字上限时,结果为一个特殊的无穷大(infinity)值,在js中以Infinity表示:同理,当负数 ...
- 关于并发下内存及CPU使用情况的思考
鉴于昨天的文章<<使用Interlocked在多线程下进行原子操作,无锁无阻塞的实现线程运行状态判断>>里面有一个封装好的无锁的类库可以判断并发下的结束状况,我们可以完成并发时 ...
- 基于event 实现的线程安全的优先队列(python实现)
event 事件是个很不错的线程同步,以及线程通信的机制,在python的许多源代码中都基于event实现了很多的线程安全,支持并发,线程通信的库 对于优先队列的堆实现,请看<python下实现 ...
- centos下 redmind2.6安装
1.下载安装redmind有关软件 cd /tmp wget http://cache.ruby-lang.org/pub/ruby/2.1/ruby-2.1.5.tar.gz wget http:/ ...
- 排序算法入门之归并排序(java实现)
归并排序是采用分治法的典型应用. 参考<数据结构与算法分析-Java语言描述> 归并排序其实要做两件事: (1)"分解"--将序列每次折半划分. (2)"合并 ...
- Spring的事务 之 9.4 声明式事务 ——跟我学spring3
9.4 声明式事务 9.4.1 声明式事务概述 从上节编程式实现事务管理可以深刻体会到编程式事务的痛苦,即使通过代理配置方式也是不小的工作量. 本节将介绍声明式事务支持,使用该方式后最大的获益是简 ...
- FFPLAY的原理(六)
显示视频 这就是我们的视频线程.现在我们看过了几乎所有的线程除了一个--记得我们调用schedule_refresh()函数吗?让我们看一下实际中是如何做的: static void schedule ...