EM算法(Expectation Maximization)
1 极大似然估计
假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么?
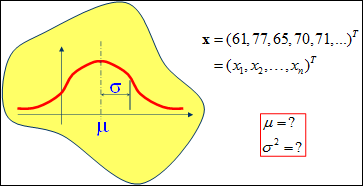 图1 学生成绩的分布
图1 学生成绩的分布
欲求在抽样X时,最优的μ和σ2参数估计,虽然模型的原型已知,但不同的参数对应着不同的学生成绩分布,其中一种最简单有效的参数估计方法就是估计的参数在目前抽样的数据上表现最好,即使得f(X|μ,σ2)的联合概率最大,这就是极大似然估计,常用L(μ,σ2|X)表示,满足公式(1)所示的关系。在实际计算中,对数函数是一个严格递增的函数,对似然函数取代数后,计算要简单很多,而且直接的似然函数计算中涉及大量浮点概率的乘法,容易导致计算机浮点计算精不够而出现机器0值,从而常用公式(2)的l(μ,σ2|X)来求极大似然估计,更普遍的如公式(3)所示。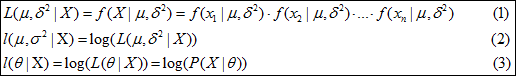 余下的问题,就是求l(μ,σ2|X)的极大值的过程,即参数的一阶偏导为0的极值点,在此不详述了,可参看下图。
余下的问题,就是求l(μ,σ2|X)的极大值的过程,即参数的一阶偏导为0的极值点,在此不详述了,可参看下图。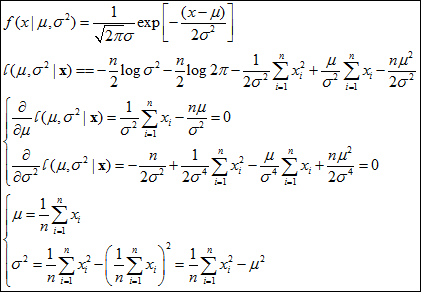
非常庆幸,对于正态分布来说,μ和σ2都能解析地直接求解,从而得到学生成绩满足何种正态分布。但实际情况是,许多应用模型中求解μ和σ2都十分困难。
2 隐含状态的极大似然估计
如第1节中所述,学生的单科成绩满足高斯分布f(x|μ,σ2),假设抽取的X是学生的语文和数学成绩,显然这样的成绩应该符合分布g(x|λ1,λ2,μ1,μ2,σ12,σ22),如公式(3)所示,两个混合的高斯分布,λ1,λ2分别表示f(x|μ1,σ12)和f(x|μ2,σ22)的在模型中的比率。
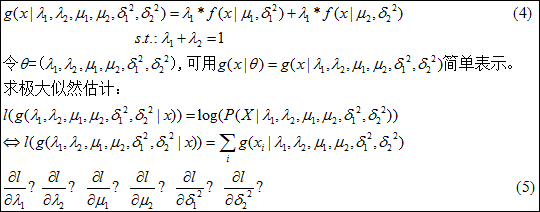 对于公式(5)所示的极大似然估计求解中,偏导的方程组,由于和的对数的存在,方程组的求解已经是神鬼难助了。
对于公式(5)所示的极大似然估计求解中,偏导的方程组,由于和的对数的存在,方程组的求解已经是神鬼难助了。
如果知道Xm={x1,x2,…,xm}属于语文成绩,Xelse={x1+m,x2+m,…,xn}属于数学成绩,g(x|θ)将变得极其简单,完全可以由第1节方法求解;如果知道μ1,μ2,σ12,σ22,求Xm和Xelse也很容易——鸡蛋困境?
接下来详述的EM(Expectation Maximization, EM)算法解决的就是这个鸡蛋困境,不管是先有鸡还是先有蛋,最终命运都会被享用。
3 EM算法
在此先将问题抽象,已知模型为p(x|θ),X=(x1,x2,…,xn),求θ。引入隐含变量Z=(z1,z2,…,zn),使得模型满足公式(6)或公式(7)的关系。由第1节的极大似然估计有,l(θ)满足公式(8)。
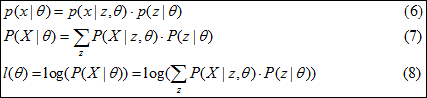 和很多求极值的算法一样(NN的BP算法),EM算法也是通过迭代计算l(θ) 的极值的。假设第n轮迭代计算出的
和很多求极值的算法一样(NN的BP算法),EM算法也是通过迭代计算l(θ) 的极值的。假设第n轮迭代计算出的
θ为θn,在新的迭代中,最简单的想法就是新的θ要优于θn即可,有l(θ)-l(θn)如下所示。如公式(9)描述,计算的的难度主要在于log函数中的求和,为解决这个问题和找到l(θ)-l(θn)的下界值,引入Jensen不等式。
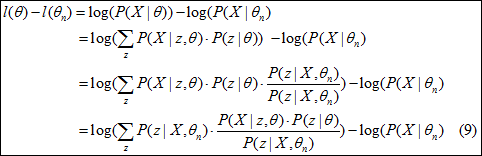
函数的凹凸性与Jensen不等式:
如果f(x)为凸函数,f(x)满足公式(10)的关系,具体证明不述,紧述的函数图就明了地描绘了这种关系。更一般地说,f(x)满足公式(11)中的关系,证明可由公式(10)导出,称为Jensen不等式。
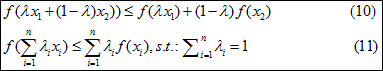
至于什么是凸函数,f(x)的二阶偏导恒大于(或等于)0,如果x为高维向量,hessian矩阵必须(半)正定,凹函数属性相对。
而f(x)=log(x), f’’=-1/x2<0 就为一个典型的凹函数,满足关系(11)。
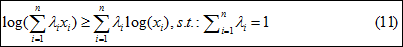
公式(9)中的l(θ)-l(θn)满足如下关系: 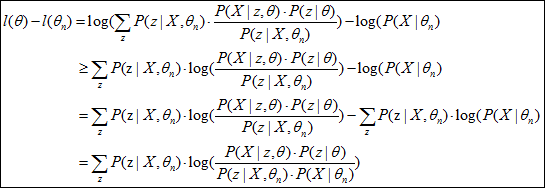
进而有:
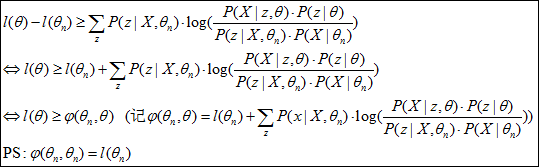
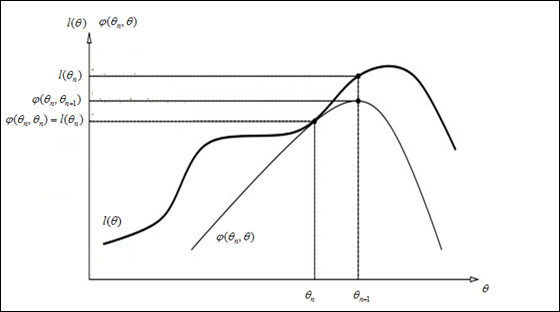 图2 l(θ)和φ(θn,θ)关系图
图2 l(θ)和φ(θn,θ)关系图
可见l(θ)的下界为φ(θn,θ),φ(θn,θ)值越大, l(θ)的下界也将越大(其中的θn为已知变量),具体l(θ)和φ(θn,θ)的关系可从图2可看出:φ(θn,θ)增长的方向也是l(θ)增长的方向,也就是任意增长φ(θn,θ)值的θ,都将使l(θ)下界增大,从而迭代使l(θ)逼近理想值。当然,在此最好的φ(θn,θ)值的θ便是,max(φ(θn,θ))处的θ,计算如下:
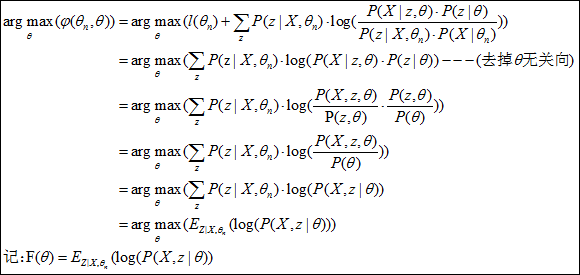 这样,迭代求θ的方法就显而易见了:
这样,迭代求θ的方法就显而易见了:
随机初始化θ0。
1、求条件期望F(θ,θn),如上公共所示;
2、求F(θ,θn)的极值处θn+1。
3、反复迭代1,2计算,直到θn收敛,即|θn+1-θn|<α(收敛条件)。
这样,EM算法就完全解决了鸡和蛋的问题了,至于初始化条件可以是鸡(θ0),也可以是蛋(z0)。
PS:EM算法的敛散性,由计算中的下界迭代,可很清晰的看到,EM算法收敛,但可能收敛于局部最优解,证明不述。
精髓:再回过头来看EM算法,可见EM算法只是在辅助求极大似然参数估计,因对数参数和的存在,使偏导计算难解,EM则利用Jensen不等式,找到似然函数的下界,且使对数参数和变成了最喜见的对数参数积。
4 缺失数据问题
可以说EM算法天生就是用来解决缺失数据的问题的,将第3节的隐变量z看成是数据中缺失的数据即可。
在完全数据X(无缺失数据)下,知模型为f(x|θ),求数据满足何种模型?这可以由第1节的极大似然估计求解;如果采样数据存在部分未知Z,预测这些含未知的数据的数据符何什么模型?这就可借用第3节的EM算法了,先随机假设θ0,迭代求解,最后求知f(x|θ),当然也就可出了z。
5 GMM
很多常见的模型,其解的过程都属于EM算法,最简单的Kmeans,稍复杂的有混合高斯模型(GMM),PLSA,HMM的学习问题……在此主要讲述GMM,其它模型将在其它篇章介绍。
如第2节所述,GMM模型为第2节案例的扩展,由K个高斯分布模型构成:
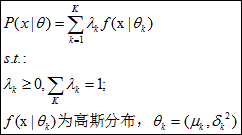 1、隐变量:
1、隐变量:  2、E步有隐变量期望:
2、E步有隐变量期望:
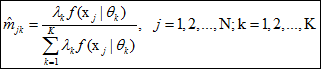
3、M步求参数估计:
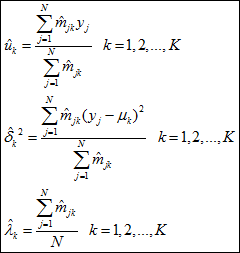 具体计算请参看李航的《统计学习方法》。
具体计算请参看李航的《统计学习方法》。
PS:Kmeans为只考虑正球体时的GMM情况。
参考资料:
1、Sean Borman. The Expectation Maximization Algorithm;
2、李航. 统计学习方法;
3、虞台文. EM Algorithm.
对于同仁们的布道授业,一并感谢。
----
EM算法(Expectation Maximization)的更多相关文章
- EM算法(Expectation Maximization Algorithm)
EM算法(Expectation Maximization Algorithm) 1. 前言 这是本人写的第一篇博客(2013年4月5日发在cnblogs上,现在迁移过来),是学习李航老师的< ...
- EM算法(Expectation Maximization Algorithm)初探
1. 通过一个简单的例子直观上理解EM的核心思想 0x1: 问题背景 假设现在有两枚硬币Coin_a和Coin_b,随机抛掷后正面朝上/反面朝上的概率分别是 Coin_a:P1:-P1 Coin_b: ...
- 简单理解EM算法Expectation Maximization
1.EM算法概念 EM 算法,全称 Expectation Maximization Algorithm.期望最大算法是一种迭代算法,用于含有隐变量(Hidden Variable)的概率参数模型的最 ...
- EM 算法 Expectation Maximization
- EM(Expectation Maximization)算法
EM(Expectation Maximization)算法 参考资料: [1]. 从最大似然到EM算法浅解 [2]. 简单的EM算法例子 [3]. EM算法)The EM Algorithm(详尽 ...
- 最大期望算法 Expectation Maximization概念
在统计计算中,最大期望(EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Lat ...
- 机器学习-EM算法
最大期望算法 EM算法的正式提出来自美国数学家Arthur Dempster.Nan Laird和Donald Rubin,其在1977年发表的研究对先前出现的作为特例的EM算法进行了总结并给出了标准 ...
- 数据挖掘十大经典算法(5) 最大期望(EM)算法
在统计计算中,最大期望(EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Lat ...
- EM算法及其推广
概述 EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计. EM算法的每次迭代由两步组成:E步,求期望(expectation): ...
随机推荐
- 项目升级-oracle改版sql server问题点汇总
目录 1.符号使用 1.1 :->@ 1.2 mod()->% 1.3 ||->+ 1.4 off等表别名 1.5 columnnum=1->top 1 1.6 minus-& ...
- ASP.NET Aries 高级开发教程:Excel导入配置之规则说明(下)
前言: 前面两篇都是大体介绍流程,有一些配置细节,没有细说,这里用一篇补上. 1.Excel配置项 起始行索引.列头跨行数: 对于自定义的Excel导入模板(有时候模板是由客户提供,模板的规则很乱) ...
- #Java学习之路——基础阶段二(第二篇)
我的学习阶段是跟着CZBK黑马的双源课程,学习目标以及博客是为了审查自己的学习情况,毕竟看一遍,敲一遍,和自己归纳总结一遍有着很大的区别,在此期间我会参杂Java疯狂讲义(第四版)里面的内容. 前言: ...
- Java实现点击导出excel页面遮罩屏蔽,下载完成后解除遮罩
一.问题场景 最近在做数据统计功能,需求是导出大数据量的excel,时间间隔较长,大概需要十秒左右,点击导出后,页面没有做任何处理,用户也不知道是否正在导出:如果没有做交互上的限制,用户可以一直点击导 ...
- Linux知识要点(文件压缩打包解压缩)
tar 的选项与参数非常的多!我们只讲几个常用的选项,更多选项您可以自行 man tar 查询啰! 其实最简单的使用 tar 就只要记忆底下的方式即可(gzip方式): 压 缩: tar -zcvf ...
- python2到python3代码转化:2to3
Mac系统上: 安装完python3后,2to3可以作为指令直接执行,-w代表"Write back modified files","."代表当前整个文件夹, ...
- 我的那些年(9)~我来团队了,Mvc兴起了
回到目录 我的那些年(9)~我来团队了,Mvc兴起了 在一次后出办事后直接去面试了 面试就是答卷子 六里桥一个好地址 搬回老家了 在老婆的建议下学驾照了 拿到大专毕业证了 买车了 愉一切可以愉的时间学 ...
- [翻译]Mock 在 Python 中的使用介绍
目录 Mock 在 Python 中的使用介绍 原文链接与说明 恐惧系统调用 一个简单的删除函数 使用 Mock 重构 潜在陷阱 向 'rm' 中加入验证 将文件删除作为服务 方法 1:模拟实例的方法 ...
- [Javascript] js的类和对象
类 graph LR 类-->构造函数 类-->prototype对象 类-->instanceof运算符 类-->constructor属性 类-->isPrototy ...
- c# Lambda操作类封装
using System; using System.Collections.Generic; using System.Linq; using System.Linq.Expressions; us ...