JDK8 HashMap 源码解析
HashMap中数据结构
在jdk1.7中,HashMap采用数组+链表(拉链法)。因为数组是一组连续的内存空间,易查询,不易增删,而链表是不连续的内存空间,通过节点相互连接,易删除,不易查询。HashMap结合这两者的优秀之处来提高效率。
而在jdk1.8时,为了解决当hash碰撞过于频繁,而链表的查询效率(时间复杂度为O(n))过低时,当链表的长度达到一定值(默认是8)时,将链表转换成红黑树(时间复杂度为O(lg n)),极大的提高了查询效率。
如图所示:
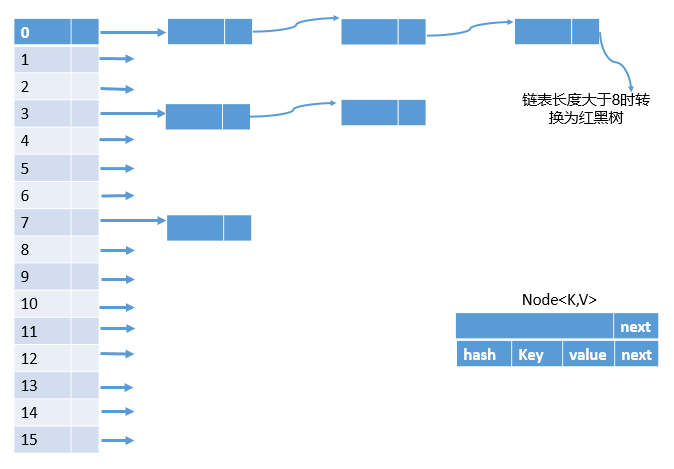
HashMap初始化
以下代码未经特别声明,都是jdk1.8。
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
HashMap的默认大小是16。查看HashMap的构造方法,发现没有执行new操作,猜测可能跟ArrayList一样是在第一次add的时候开辟的内存,于是查看put方法。
put方法
关于Node节点
HashMap将hash,key,value,next已经封装到一个静态内部类Node上。它实现了Map.Entry<K,V>接口。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
然后在定义一个Node数组table
transient Node<K,V>[] table;
hash实现
当我们put的时候,首先计算 key的hash值,这里调用了 hash方法,hash方法实际是让key.hashCode()与key.hashCode()>>>16进行异或操作,高16bit补0,一个数和0异或不变,所以 hash 函数大概的作用就是:高16bit不变,低16bit和高16bit做了一个异或,目的是减少碰撞。按照函数注释,因为bucket数组大小是2的幂,计算下标index = (table.length - 1) & hash,如果不做 hash 处理,相当于散列生效的只有几个低 bit 位,为了减少散列的碰撞,设计者综合考虑了速度、作用、质量之后,使用高16bit和低16bit异或来简单处理减少碰撞,而且JDK8中用了复杂度 O(logn)的树结构来提升碰撞下的性能。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
实现方法
- 如果当前数组table为null,进行resize()初始化
- 否则计算数组索引
i = (n - 1) & hash - 如果这个table[i]值为空,那么就将这个Node键值对放在这里
- 判断key是否与table[i]重复,重复则替换
- 不重复在判断table[i]是否连接了一个链表,链表为空则new 一个Node键值对,链表不为空就循环直到最后一个节点的next为null或者出现出现重复key值
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 默认容量初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果table[i]为空,那就把这个键值对放在table[i], i = (n - 1) & hash 相等于 hash % n,
//但是hash后按位与 n-1,比%模运算取余要快
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//当另一个key的hash值已经存在时
else {
Node<K,V> e; K k;
// table[i].key == key
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//JDK8在哈希碰撞的链表长度达到TREEIFY_THRESHOLD(默认8)后,
//会把该链表转变成树结构,提高了性能。
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//遍历table[i]所对应的链表,直到最后一个节点的next为null或者有重复的key值
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//key重复,替换value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
get方法
首先通过hash函数找到索引,然后判断map为null,再判断table[i]是否等于key,然后在找与table相连的链表的key是否相等。
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
jdk1.7中的线程安全问题(resize死循环)
当HashMap的size超过Capacity*loadFactor时,需要对HashMap进行扩容。具体方法是,创建一个新的,长度为原来Capacity两倍的数组,保证新的Capacity仍为2的N次方,从而保证上述寻址方式仍适用。同时需要通过如下transfer方法将原来的所有数据全部重新插入(rehash)到新的数组中。
下列代码基于 jdk1.7.0_79
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
该方法并不保证线程安全,而且在多线程并发调用时,可能出现死循环。其执行过程如下。从步骤2可见,转移时链表顺序反转。
- 遍历原数组中的元素
- 对链表上的每一个节点遍历:用next取得要转移那个元素的下一个,将e转移到新数组的头部,使用头插法插入节点
- 循环2,直到链表节点全部转移
- 循环1,直到所有元素全部转移
单线程rehash
单线程情况下,rehash无问题。下图演示了单线程条件下的rehash过程
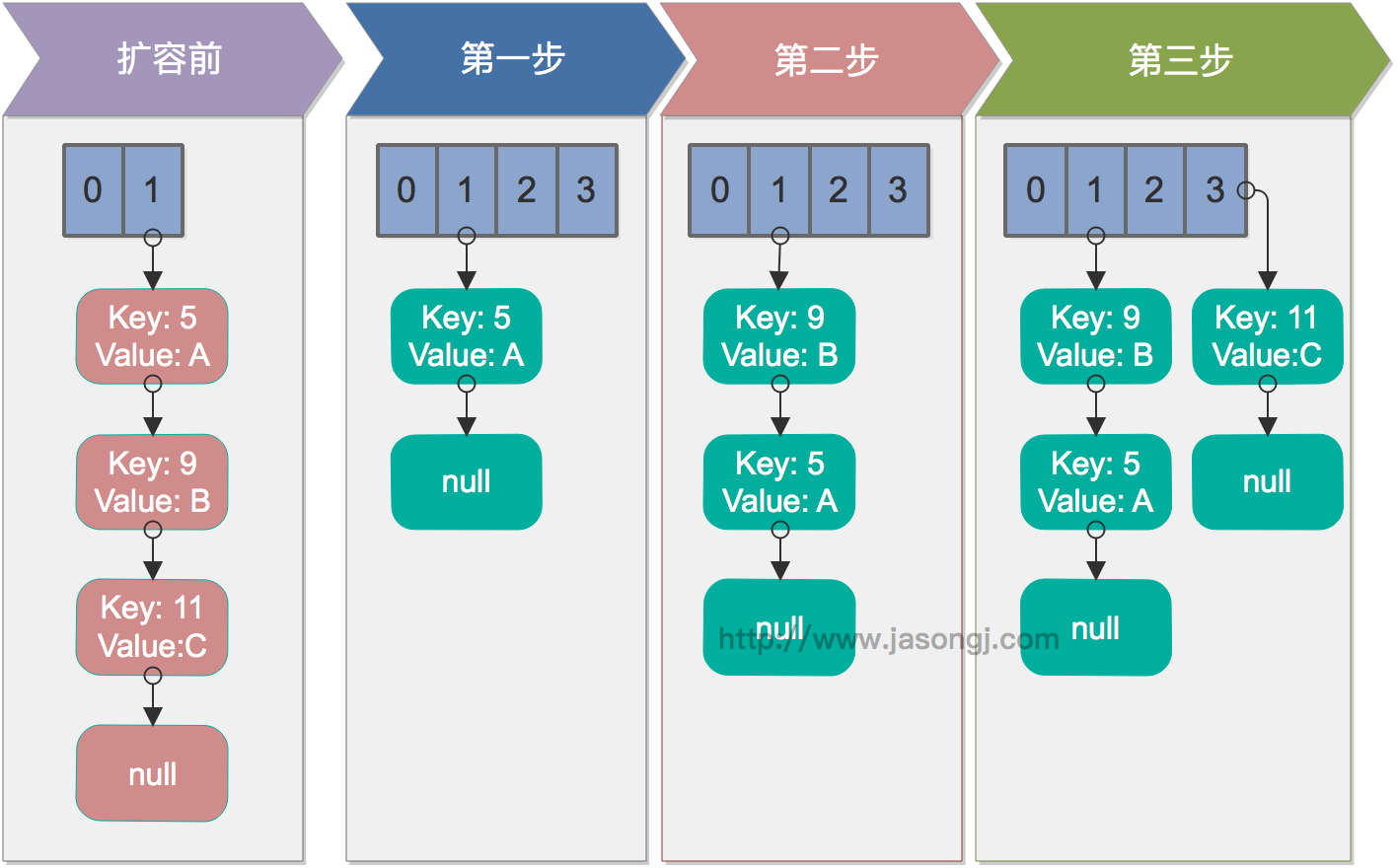
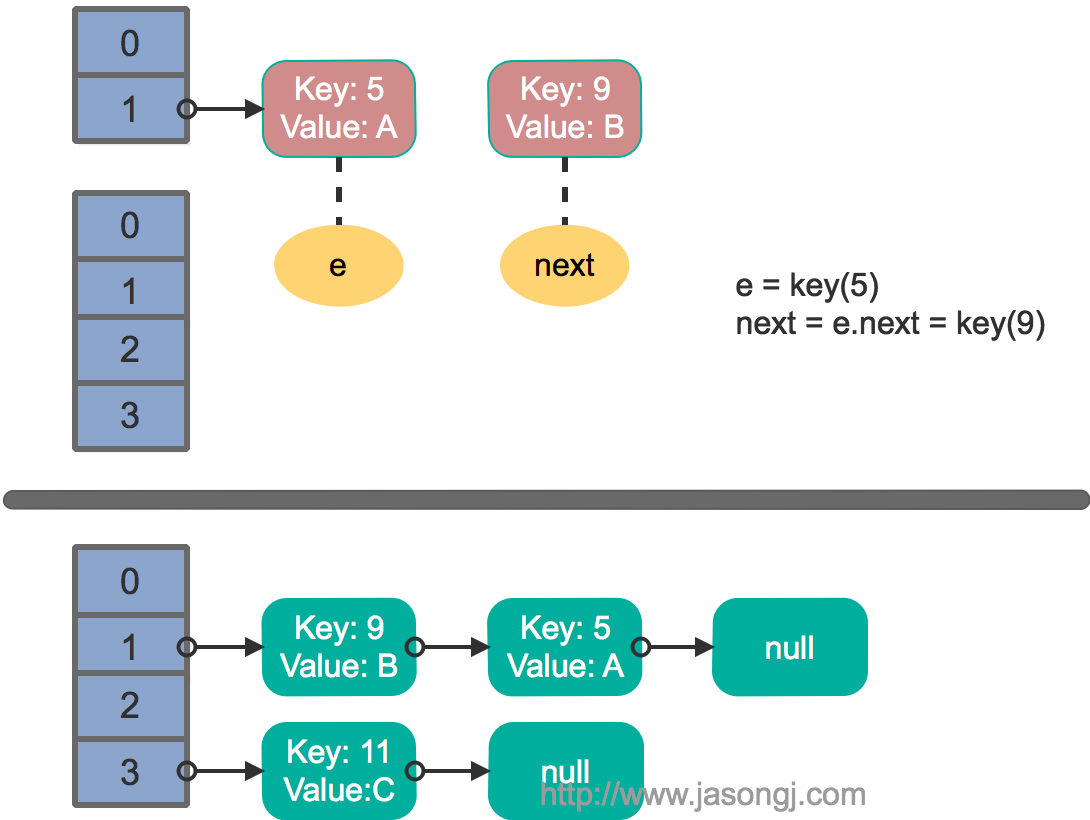
多线程并发下的rehash
这里假设有两个线程同时执行了put操作并引发了rehash,执行了transfer方法,并假设线程一进入transfer方法并执行完next = e.next后,因为线程调度所分配时间片用完而“暂停”,此时线程二完成了transfer方法的执行。此时状态如下。
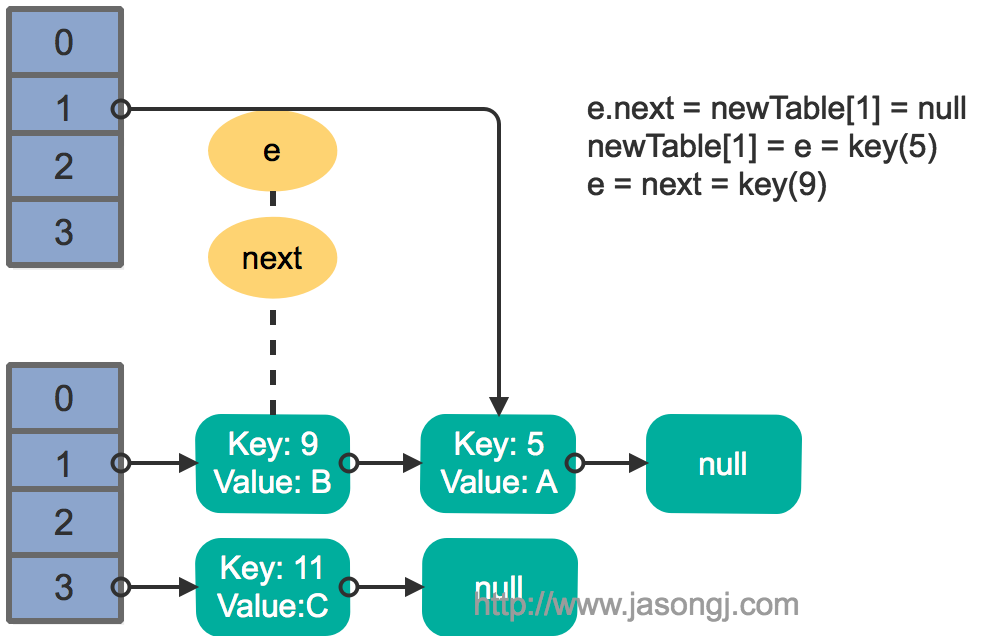
接着线程1被唤醒,继续执行第一轮循环的剩余部分
e.next = newTable[1] = null
newTable[1] = e = key(5)
e = next = key(9)
结果如下图所示
接着执行下一轮循环,结果状态图如下所示
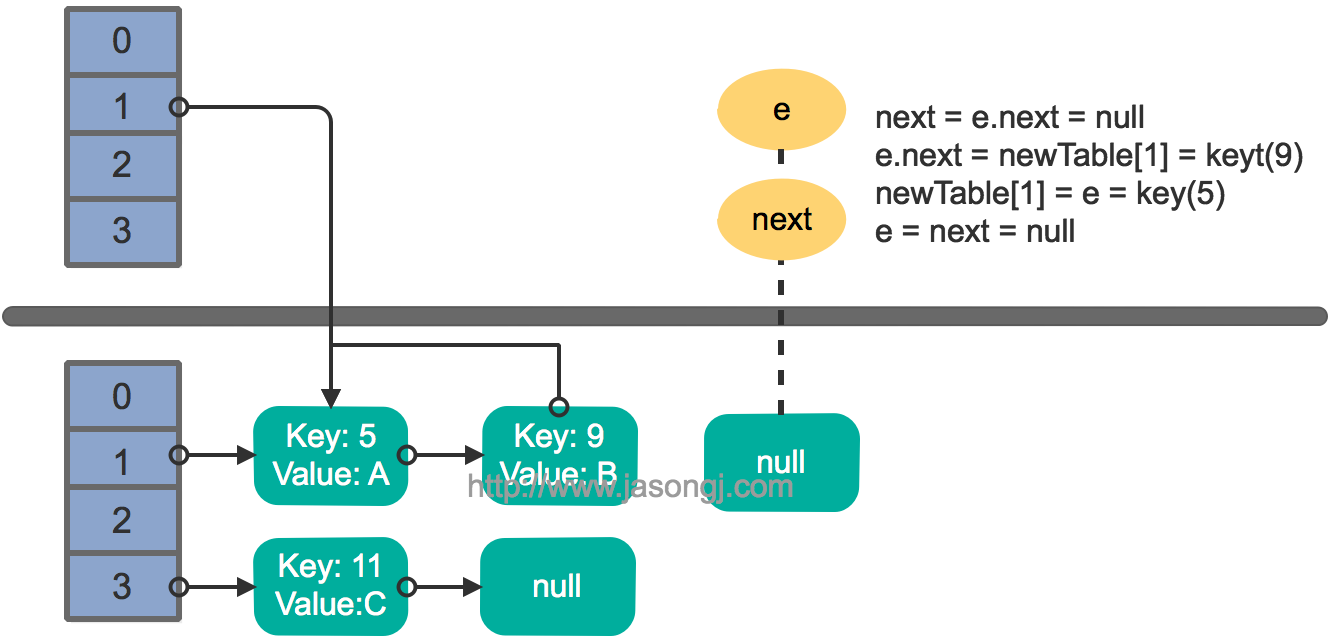
此时循环链表形成,并且key(11)无法加入到线程1的新数组。在下一次访问该链表时会出现死循环。
jdk1.8中的扩容
在jdk1.8中采用resize方法来对HashMap进行扩容。
resize方法
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
// 清除原来table[i]中的值
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 带有链表时优化重hash
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引,(e.hash & oldCap) == 0 说明 在put操作通过 hash & newThr
//计算出的索引值等于现在的索引值。
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap,不是原索引,就移动原来的长度
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
声明两对指针,维护两个链表,依次在末端添加新的元素,在多线程操作的情况下,无非是第二个线程重复第一个线程一模一样的操作。
因此不会产生jdk1.7扩容时的resize死循环问题。
jdk1.8中hashmap的确不会因为多线程put导致死循环,但是依然有其他的弊端。因此多线程情况下还是建议使用concurrenthashmap。
面试问题
如果new HashMap(19),bucket数组多大?
HashMap的bucket 数组大小一定是2的幂,如果new的时候指定了容量且不是2的幂,实际容量会是最接近(大于)指定容量的2的幂,比如 new HashMap<>(19),比19大且最接近的2的幂是32,实际容量就是32。
基础知识
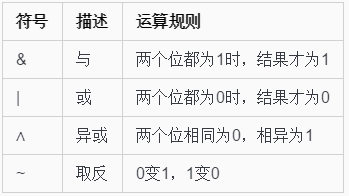
简便方法:
如对a按位取反,则得到的结果为-(a+1)。
此条运算方式对正数负数和零都适用。
源码/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
解析
先来分析有关n位操作部分:先来假设n的二进制为01xxx...xxx。接着
对n右移1位:001xx...xxx,再位或:011xx...xxx
对n右移2为:00011...xxx,再位或:01111...xxx
此时前面已经有四个1了,再右移4位且位或可得8个1
同理,有8个1,右移8位肯定会让后八位也为1。
综上可得,该算法让最高位的1后面的位全变为1。
最后再让结果n+1,即得到了2的整数次幂的值了。
现在回来看看第一条语句:
int n = cap - 1;
让cap-1再赋值给n的目的是另找到的目标值大于或等于原值。例如二进制1000,十进制数值为8。如果不对它减1而直接操作,将得到答案10000,即16。显然不是结果。减1后二进制为111,再进行操作则会得到原来的数值1000,即8。
这种方法的效率非常高,可见Java8对容器优化了很多,很强哈。其他之后再进行分析吧。HashMap什么时候开辟bucket数组占用内存?
HashMap在new 后并不会立即分配bucket数组,而是第一次put时初始化,类似ArrayList在第一次add时分配空间。HashMap何时扩容?
HashMap 在 put 的元素数量大于 Capacity * LoadFactor(默认16 * 0.75) 之后会进行扩容。当两个对象的hashcode相同会发生什么?
碰撞如果两个键的hashcode相同,你如何获取值对象?
遍历与hashCode值相等时相连的链表,直到相等或者null你了解重新调整HashMap大小存在什么问题吗?
参考文档
- HashMap实现原理分析
- 由阿里巴巴Java开发规约HashMap条目引发的故事
- Java8 HashMap之tableSizeFor
- Java 8系列之重新认识HashMap
- Java进阶(六)从ConcurrentHashMap的演进看Java多线程核心技术
JDK8 HashMap 源码解析的更多相关文章
- JDK8集合类源码解析 - HashSet
HashSet 特点:不允许放入重复元素 查看源码,发现HashSet是基于HashMap来实现的,对HashMap做了一次“封装”. private transient HashMap<E,O ...
- Java中的容器(集合)之HashMap源码解析
1.HashMap源码解析(JDK8) 基础原理: 对比上一篇<Java中的容器(集合)之ArrayList源码解析>而言,本篇只解析HashMap常用的核心方法的源码. HashMap是 ...
- 【转】Java HashMap 源码解析(好文章)
.fluid-width-video-wrapper { width: 100%; position: relative; padding: 0; } .fluid-width-video-wra ...
- HashMap源码解析 非原创
Stack过时的类,使用Deque重新实现. HashCode和equals的关系 HashCode为hash码,用于散列数组中的存储时HashMap进行散列映射. equals方法适用于比较两个对象 ...
- 最全的HashMap源码解析!
HashMap源码解析 HashMap采用键值对形式的存储结构,每个key对应唯一的value,查询和修改的速度很快,能到到O(1)的平均复杂度.他是非线程安全的,且不能保证元素的存储顺序. 他的关系 ...
- HashMap源码解析和设计解读
HashMap源码解析 想要理解HashMap底层数据的存储形式,底层原理,最好的形式就是读它的源码,但是说实话,源码的注释说明全是英文,英文不是非常好的朋友读起来真的非常吃力,我基本上看了差不多 ...
- 详解HashMap源码解析(下)
上文详解HashMap源码解析(上)介绍了HashMap整体介绍了一下数据结构,主要属性字段,获取数组的索引下标,以及几个构造方法.本文重点讲解元素的添加.查找.扩容等主要方法. 添加元素 put(K ...
- 【Java深入研究】9、HashMap源码解析(jdk 1.8)
一.HashMap概述 HashMap是常用的Java集合之一,是基于哈希表的Map接口的实现.与HashTable主要区别为不支持同步和允许null作为key和value.由于HashMap不是线程 ...
- java容器三:HashMap源码解析
前言:Map接口 map是一个存储键值对的集合,实现了Map接口的主要类有以下几种 TreeMap:用红黑树实现 HashMap:数组和链表实现 HashTable:与HashMap类似,但是线程安全 ...
随机推荐
- 了解adb的基本原理
ADB就是Android调试桥的意思,很形象.但不知道是windows本身的原因还是windows乱七八糟软件太多,用USB调试手机时,经常连不上ADB,或者就出现offline,导致费时费力,焦头烂 ...
- Luogu P1231 教辅的组成
Luogu P1231 教辅的组成 题目背景 滚粗了的HansBug在收拾旧语文书,然而他发现了什么奇妙的东西. 题目描述 蒟蒻HansBug在一本语文书里面发现了一本答案,然而他却明明记得这书应该还 ...
- b9934107349625014ec251e1333d73a8 这个代码是mad5值
Message Digest Algorithm MD5(中文名为消息摘要算法第五版)为计算机安全领域广泛使用的一种散列函数,用以提供消息的完整性保护.该算法的文件号为RFC 1321(R.Rives ...
- Codeforces 777B Game of Credit Cards
B. Game of Credit Cards time limit per test:2 seconds memory limit per test:256 megabytes input:stan ...
- 2017广东工业大学程序设计竞赛决赛 题解&源码(A,数学解方程,B,贪心博弈,C,递归,D,水,E,贪心,面试题,F,贪心,枚举,LCA,G,dp,记忆化搜索,H,思维题)
心得: 这比赛真的是不要不要的,pending了一下午,也不知道对错,直接做过去就是了,也没有管太多! Problem A: 两只老虎 Description 来,我们先来放松下,听听儿歌,一起“唱” ...
- hdu_1029_hash/map
http://acm.hdu.edu.cn/showproblem.php?pid=1029 太水了,一次过,直接上代码吧,只想说最愚蠢的hash都要比map快! #include<cstdio ...
- 搬寝室(经典dp)
题目连接:http://acm.hdu.edu.cn/showproblem.php?pid=1421 hdu_1421:搬寝室 Time Limit: 2000/1000 MS (Java/Othe ...
- ThinkPHP基础知识
1.入口文件中定义的内容 // 检测PHP环境if(version_compare(PHP_VERSION,'5.3.0','<')) die('require PHP > 5.3.0 ! ...
- HTTP协议简介
一.简介 HTTP(HyperText Transfer Protocol, 超文本传输协议) 是访问互联网使用的核心通信协议,也是所有web应用程序使用的通信协议.消息模型:客户端发送请求消息,服务 ...
- 在Android studio模拟器中运行apk文件
菜鸟级玩家比看文. win平台下下载的apk文件,怎么能模拟运行出来. 首先得安装Android SDK,不会的自行百度一下. 接下来,打开AVD模拟器,自己创建一个模拟器(过程自己实践) 然后,将你 ...