单例模式,堆,BST,AVL树,红黑树
单例模式
第一种(懒汉,线程不安全):
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
这种写法lazy loading很明显,但是致命的是在多线程不能正常工作。
第二种(懒汉,线程安全):
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
这种写法能够在多线程中很好的工作,而且看起来它也具备很好的lazy loading,但是,遗憾的是,效率很低,99%情况下不需要同步。
第三种(饿汉):
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}
这种方式基于classloder机制避免了多线程的同步问题,不过,instance在类装载时就实例化,虽然导致类装载的原因有很多种,在单例模式中大多数都是调用getInstance方法, 但是也不能确定有其他的方式(或者其他的静态方法)导致类装载,这时候初始化instance显然没有达到lazy loading的效果。
第四种(饿汉,变种):
public class Singleton {
private Singleton instance = null;
static {
instance = new Singleton();
}
private Singleton (){}
public static Singleton getInstance() {
return this.instance;
}
}
表面上看起来差别挺大,其实更第三种方式差不多,都是在类初始化即实例化instance。
第五种(静态内部类):
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
这种方式同样利用了classloder的机制来保证初始化instance时只有一个线程,它跟第三种和第四种方式不同的是(很细微的差别):第三种和第四种方式是只要Singleton类被装载了,那么instance就会被实例化(没有达到lazy loading效果),而这种方式是Singleton类被装载了,instance不一定被初始化。因为SingletonHolder类没有被主动使用,只有显示通过调用getInstance方法时,才会显示装载SingletonHolder类,从而实例化instance。想象一下,如果实例化instance很消耗资源,我想让他延迟加载,另外一方面,我不希望在Singleton类加载时就实例化,因为我不能确保Singleton类还可能在其他的地方被主动使用从而被加载,那么这个时候实例化instance显然是不合适的。这个时候,这种方式相比第三和第四种方式就显得很合理。
第六种(枚举):
public enum Singleton {
INSTANCE;
public void whateverMethod() {
}
}
这种方式是Effective Java作者Josh Bloch 提倡的方式,它不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象,可谓是很坚强的壁垒啊,不过,个人认为由于1.5中才加入enum特性,用这种方式写不免让人感觉生疏,在实际工作中,我也很少看见有人这么写过。
第七种(双重校验锁):
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
这个是第二种方式的升级版,俗称双重检查锁定,详细介绍请查看:http://www.ibm.com/developerworks/cn/java/j-dcl.html
在JDK1.5之后,双重检查锁定才能够正常达到单例效果。
总结
有两个问题需要注意:
1、如果单例由不同的类装载器装入,那便有可能存在多个单例类的实例。假定不是远端存取,例如一些servlet容器对每个servlet使用完全不同的类 装载器,这样的话如果有两个servlet访问一个单例类,它们就都会有各自的实例。
2、如果Singleton实现了java.io.Serializable接口,那么这个类的实例就可能被序列化和复原。不管怎样,如果你序列化一个单例类的对象,接下来复原多个那个对象,那你就会有多个单例类的实例。
对第一个问题修复的办法是:
private static Class getClass(String classname)
throws ClassNotFoundException {
ClassLoader classLoader = Thread.currentThread().getContextClassLoader(); if(classLoader == null)
classLoader = Singleton.class.getClassLoader(); return (classLoader.loadClass(classname));
}
}
对第二个问题修复的办法是:
public class Singleton implements java.io.Serializable {
public static Singleton INSTANCE = new Singleton();
protected Singleton() {
}
private Object readResolve() {
return INSTANCE;
}
}
对我来说,我比较喜欢第三种和第五种方式,简单易懂,而且在JVM层实现了线程安全(如果不是多个类加载器环境),一般的情况下,我会使用第三种方式,只有在要明确实现lazy loading效果时才会使用第五种方式,另外,如果涉及到反序列化创建对象时我会试着使用枚举的方式来实现单例,不过,我一直会保证我的程序是线程安全的,而且我永远不会使用第一种和第二种方式,如果有其他特殊的需求,我可能会使用第七种方式,毕竟,JDK1.5已经没有双重检查锁定的问题了。
不过一般来说,第一种不算单例,第四种和第三种就是一种,如果算的话,第五种也可以分开写了。所以说,一般单例都是五种写法。懒汉,恶汉,双重校验锁,枚举和静态内部类。
堆
TopK问题是指从大量数据(源数据)中获取最大(或最小)的K个数据。
TopK问题是个很常见的问题:例如学校要从全校学生中找到成绩最高的500名学生,再例如某搜索引擎要统计每天的100条搜索次数最多的关键词。
对于这个问题,解决方法有很多:
方法一:对源数据中所有数据进行排序,取出前K个数据,就是TopK。
但是当数据量很大时,只需要k个最大的数,整体排序很耗时,效率不高。
方法二:维护一个K长度的数组a[],先读取源数据中的前K个放入数组,对该数组进行升序排序,再依次读取源数据第K个以后的数据,和数组中最小的元素(a[0])比较,如果小于a[0]直接pass,大于的话,就丢弃最小的元素a[0],利用二分法找到其位置,然后该位置前的数组元素整体向前移位,直到源数据读取结束。
这比方法一效率会有很大的提高,但是当K的值较大的时候,长度为K的数据整体移位,也是非常耗时的。
对于这种问题,效率比较高的解决方法是使用最小堆。
最小堆(小根堆)是一种数据结构,它首先是一颗完全二叉树,并且,它所有父节点的值小于或等于两个子节点的值。
最小堆的存储结构(物理结构)实际上是一个数组。如下图:

堆有几个重要操作:
BuildHeap:将普通数组转换成堆,转换完成后,数组就符合堆的特性:所有父节点的值小于或等于两个子节点的值。
Heapify(int i):当元素i的左右子树都是小根堆时,通过Heapify让i元素下降到适当的位置,以符合堆的性质。
回到上面的取TopK问题上,用最小堆的解决方法就是:先去源数据中的K个元素放到一个长度为K的数组中去,再把数组转换成最小堆。再依次取源数据中的K个之后的数据和堆的根节点(数组的第一个元素)比较,根据最小堆的性质,根节点一定是堆中最小的元素,如果小于它,则直接pass,大于的话,就替换掉跟元素,并对根元素进行Heapify,直到源数据遍历结束。
最小堆的实现
public class MinHeap
{
// 堆的存储结构 - 数组
private int[] data; // 将一个数组传入构造方法,并转换成一个小根堆
public MinHeap(int[] data)
{
this.data = data;
buildHeap();
} // 将数组转换成最小堆
private void buildHeap()
{
// 完全二叉树只有数组下标小于或等于 (data.length) / 2 - 1 的元素有孩子结点,遍历这些结点。
// *比如上面的图中,数组有10个元素, (data.length) / 2 - 1的值为4,a[4]有孩子结点,但a[5]没有*
for (int i = (data.length) / 2 - 1; i >= 0; i--)
{
// 对有孩子结点的元素heapify
heapify(i);
}
} private void heapify(int i)
{
// 获取左右结点的数组下标
int l = left(i);
int r = right(i); // 这是一个临时变量,表示 跟结点、左结点、右结点中最小的值的结点的下标
int smallest = i; // 存在左结点,且左结点的值小于根结点的值
if (l < data.length && data[l] < data[i])
smallest = l; // 存在右结点,且右结点的值小于以上比较的较小值
if (r < data.length && data[r] < data[smallest])
smallest = r; // 左右结点的值都大于根节点,直接return,不做任何操作
if (i == smallest)
return; // 交换根节点和左右结点中最小的那个值,把根节点的值替换下去
swap(i, smallest); // 由于替换后左右子树会被影响,所以要对受影响的子树再进行heapify
heapify(smallest);
} // 获取右结点的数组下标
private int right(int i)
{
return (i + 1) << 1;
} // 获取左结点的数组下标
private int left(int i)
{
return ((i + 1) << 1) - 1;
} // 交换元素位置
private void swap(int i, int j)
{
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
} // 获取对中的最小的元素,根元素
public int getRoot()
{
return data[0];
} // 替换根元素,并重新heapify
public void setRoot(int root)
{
data[0] = root;
heapify(0);
}
}
利用最小堆获取TopK:
public class TopK
{
public static void main(String[] args)
{
// 源数据
int[] data = {56,275,12,6,45,478,41,1236,456,12,546,45}; // 获取Top5
int[] top5 = topK(data, 5); for(int i=0;i<5;i++)
{
System.out.println(top5[i]);
}
} // 从data数组中获取最大的k个数
private static int[] topK(int[] data,int k)
{
// 先取K个元素放入一个数组topk中
int[] topk = new int[k];
for(int i = 0;i< k;i++)
{
topk[i] = data[i];
} // 转换成最小堆
MinHeap heap = new MinHeap(topk); // 从k开始,遍历data
for(int i= k;i<data.length;i++)
{
int root = heap.getRoot(); // 当数据大于堆中最小的数(根节点)时,替换堆中的根节点,再转换成堆
if(data[i] > root)
{
heap.setRoot(data[i]);
}
}
return topk;
}
}
BST
一:二叉搜索树的定义
他的定义与树的定义是类似的,也是一个递归的定义:
1、要么是一棵空树
2、如果不为空,那么其左子树节点的值都小于根节点的值;右子树节点的值都大于根节点的值
3、其左右子树也是二叉搜索树
在算法导论中的定义:

下图中是BST的两个例子:
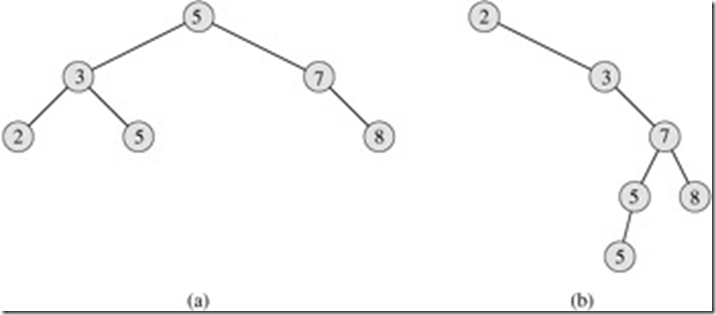
其中(b)图中的树是很不平衡的(所谓不平衡是值左右子树的高度差比较大)
BST在数据结构中占有很重要的地位,一些高级树结构都是其的变种,例如AVL树、红黑树等,因此理解BST对于后续树结构的学习有很好的作用。同时利用BST可以进行排序,称为二叉排序,也是很重要的一种思想。
二:二叉搜索树的操作定义
在BST中有下列操作:
1、在树中插入一个节点:insert(tree *root, datatype t)
2、在将树中的某个节点删除: remove(tree *root, datatype t);
3、查找树中值最大/小的节点:find_max(tree root) / find_min(tree root);
4、查找树中的某个节点:search_tree(tree root, datatype t);
当然作为二叉树,还有对BST的各种遍历,主要是中序遍历,对BST的中序遍历其实就是二叉搜索的实现。
上面的几个操作中最复杂的一个操作是删除树中的节点,后面会详细介绍。
三:BST的具体操作实现
typedef struct node_t
{
datatype data;
struct node_t *lchild, *rchild;
}node, *tree;
下面就根据BST的定义和各个操作的含义,实现BST的相应操作。
1、插入操作insert(tree *root, datatype t)
插入操作是在指定的BST中插入一个节点,该节点的数据域为t。同时插入节点后需要保证BST仍然满足二叉搜索树的定义
插入操作的大概过程如下:
将root->data 与t进行比较,如果t < root->data,那么递归将t插入到root->lchild; 否则将t插入到root->rchild中。如果root是空的话,则新建一个节点。
void insert(tree *root, node *t)
{
if(*root == NULL)
{
*root =t;
return;
}
if(t->data < temp->data) //左子树
{
insert(&((*root)->lchid), t);
}
else //插入到右子树
{
insert(&((*root)->rchild), t);
}
}
上面是插入操作的一个简单实现,在图形化中的二叉搜索树的展示如下:
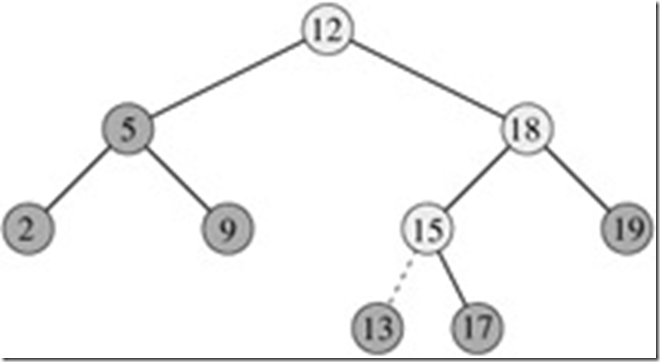
这里是插入节点13
从上面实现可以知道,插入操作的时间复杂度是O(lgn),其中n是节点的个数,也就是时间复杂度是树的高度。当然在最坏情况下时间复杂度是O(n)
2、二叉搜索树的删除操作
在介绍完二叉搜索树的插入操作后,下面介绍下二叉搜索树中最负责的操作,删除节点操作remove(tree *root, datatype t).二叉搜索树的删除操作是相对要复杂的,这是因为删除操作有多种情况需要考虑,下面分别一一介绍:
假设要删除的节点是p,该节点的父节点是q,那么对p有下面的一些考察:
p和q的关系如下图所示:其中p的两个子节点用虚线表示,表示可能有也可能没有子节点;同时p也有可能是q的右孩子
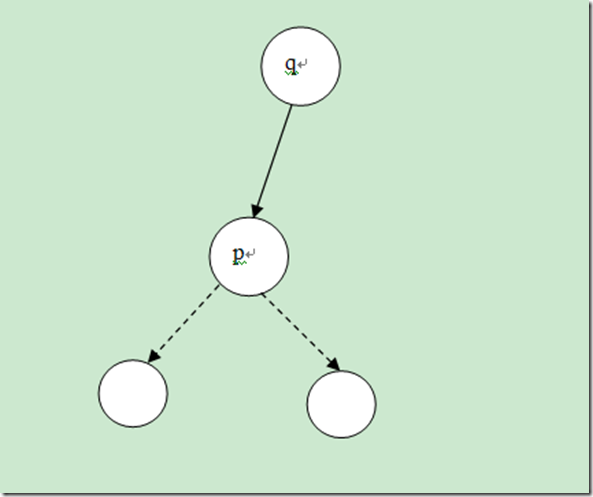
针对上面的描述,可能有下面的几种情况需要考虑
a、如果p节点没有孩子节点,也就是说p节点是叶子节点,那么直接删除p对二叉搜索树是没有影响的,这样的情况下可以直接将q相应的子节点指针设置为空,然后free掉p
b、如果p的孩子节点有一个为空,例如左孩子为空或者右孩子为空。
对于这样的情况也可以分成两种讨论
if(p的左孩子为空)
{
if(p是q的左孩子)
{
q->左孩子 = p->右孩子:
}
if(p是q的右孩子)
{
q->右孩子 = p->右孩子
}
}
同理
if(p的右孩子为空)
{
if(p是q的左孩子)
{
q->左孩子 = p->左孩子
}
if(p是q的右孩子)
{
q->右孩子 = p->左孩子
}
}
上面是p的一个孩子为空
c、p的左右孩子都不为空,这是最复杂的一种情况
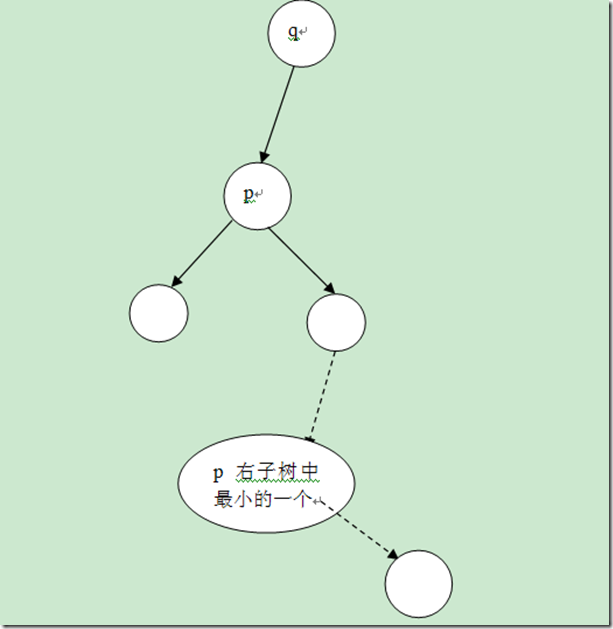
在这种情况下需要考虑的比较多,如果要删除p节点的话,需要找到p的后继者(此时p的后继者肯定是p的右子树中最小的一个,因为p有右孩子),然后将其放在p的位置,这样才能保证维持BST的性质。因此这种情况下就可以先找到p节点的后继者,然后将其和p进行交换,然后将交换后的节点删除。
下图是《算法导论》中删除节点的三种情况描述:
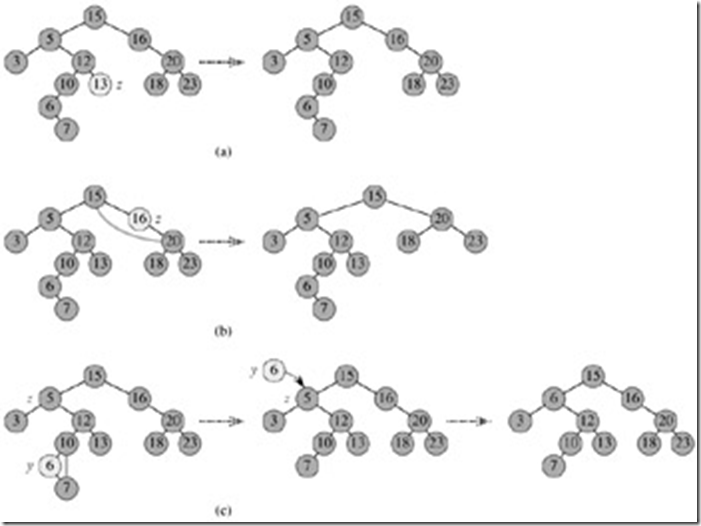
其中z节点是要删除的节点。(c)中的y节点是z的后继者
对于p的左右孩子都不为空的伪代码如下:
node *successor; //指向p的后继者
successor = find_min(p->rchild); //找到p的后继者y
p->data = successor->data; //将后继者y的值copy到p的数据域中
successor->parent->lchild = successor->rchild;//这里successor一定是其父节点的左孩子,因为如果他是父节点的右孩子的话,那么p的后继者就不是successor了,而应该是successor的parent了,因为successor的parent比successor小。这是这条语句左边的原因;对于右边来说,因为successor是p的后继者,那么successor一定是没有左孩子的,如果有的话,p的后继者就不是successor了,而是successor的左孩子了,因此successor至多有一个右孩子。这是对这条语句的解释。
操作完后就可以将successor释放掉了。
这些基本就是二叉搜索树的操作了,比较复杂的是插入和删除操作。
二叉搜索树是一种很基础的树,后续的AVL、红黑树等都是在此基础上增加了一些其他限制条件形成的。
java实现
import java.util.LinkedList; import ljn.help.*;
public class OperationsOnBinarySearchTree { /**
* It shows the operations on Binary Search Tree.
* see also: http://blog.csdn.net/jiqiren007/article/details/6534810
*/
private Node root;
public static void main(String[] args) {
int[] data={12,5,18,2,9,15,19,0,0,8,0,0,17,};
/* 12
/ \
5 18
/ \ / \
2 9 15 19
/ \
8 17
*/
OperationsOnBinarySearchTree bst=new OperationsOnBinarySearchTree(data);
bst.levelTraverse();
bst.insert(13);
bst.levelTraverse();
bst.delete(13);
bst.levelTraverse();
bst.delete(12);
bst.levelTraverse();
bst.inOrder(bst.root); }
public OperationsOnBinarySearchTree(int[] data){
root=Helper.createTree(data);
} public void delete(int dataDelete){
if(root==null){
return;
}
Node curNode=root;
NodePair pair=findNodeAndParent(curNode,dataDelete);
Node nodeDelete=pair.son;
Node parent=pair.parent;
if(nodeDelete==null){
return;
}
if(isLeaf(nodeDelete)){
if(parent.getLeft()==nodeDelete){
parent.setLeft(null);
}
if(parent.getRight()==nodeDelete){
parent.setRight(null);
}
}else{
if( hasLeftOnly(nodeDelete) ){
if(parent.getLeft()==nodeDelete){
parent.setLeft(nodeDelete.getLeft());
}
if(parent.getRight()==nodeDelete){
parent.setRight(nodeDelete.getLeft());
}
}else if( hasRightOnly(nodeDelete) ){
if(parent.getLeft()==nodeDelete){
parent.setLeft(nodeDelete.getRight());
}
if(parent.getRight()==nodeDelete){
parent.setRight(nodeDelete.getRight());
}
}else{//has both left child and right child.Successor is in the min(curNode.getRight())
NodePair tmpPair=min(nodeDelete.getRight());
Node successor=tmpPair.son;
Node sParent=tmpPair.parent;
nodeDelete.setData(successor.getData());
if(null==sParent){
nodeDelete.setRight(null);
}else{
sParent.setLeft(successor.getRight());
}
}
} } public NodePair findNodeAndParent(Node curNode,int data){
if(curNode==null){
return null;
}
Node parent=null;
Node son=null;
NodePair pair=null;
while(curNode!=null){
int curData=curNode.getData();
if(curData==data){
son=curNode;//when curNode.getData()==data,'parent' is null.Is it OK?
break;
}
if(data<curData){
parent=curNode;
curNode=curNode.getLeft();
}
if(data>curData){
parent=curNode;
curNode=curNode.getRight();
}
}
pair=new NodePair(son,parent);
return pair;
}
public boolean hasLeftOnly(Node node){
return node!=null&&node.getLeft()!=null&&node.getRight()==null;
}
public boolean hasRightOnly(Node node){
return node!=null&&node.getRight()!=null&&node.getLeft()==null;
}
public boolean isLeaf(Node node){
return node!=null&&node.getLeft()==null&&node.getRight()==null;
}
public NodePair min(Node curNode){
if(curNode==null){
return null;
}
Node parent=null;
while(curNode.getLeft()!=null){//when 'curNode' has no left child,'curNode' is min,and its parent is null(ok?)
parent=curNode;
curNode=curNode.getLeft();
}
return new NodePair(curNode,parent);
} //we don't get 'max''s parent node like 'min'
public Node max(Node curNode){
if(curNode==null){
return null;
}
while(curNode.getRight()!=null){
curNode=curNode.getRight();
}
return curNode;
} public Node find(int target){
if(root==null){//empty tree
return null;
}else{
return findHelp(root,target);
}
}
public Node findHelp(Node curNode,int target){
Node result=null;
int curData=curNode.getData();
if(target==curData){
result=curNode;
}
if(target<curData){
findHelp(curNode.getLeft(),target);
}
if(target>curData){
findHelp(curNode.getRight(),target);
}
return result;
} public void insert(int dataInsert){
if(root==null){//the tree is empty
root=new Node(dataInsert);
}else{
insertHelp(root,dataInsert);
}
} public void insertHelp(Node curNode,int dataInsert){
Node nodeToInsert=new Node(dataInsert);
int curData=curNode.getData();
if(dataInsert<=curData){//insert into left tree
Node left=curNode.getLeft();
if(left==null){
curNode.setLeft(nodeToInsert);
}else{
insertHelp(left,dataInsert);
}
}
if(dataInsert>curData){//insert into right tree
Node right=curNode.getRight();
if(right==null){
curNode.setRight(nodeToInsert);
}else{
insertHelp(right,dataInsert);
}
}
} public void levelTraverse(){
if(root==null){
return;
}
Node node=root;
LinkedList<Node> queue=new LinkedList<Node>();
queue.addLast(node);
while(!queue.isEmpty()){
node=queue.removeFirst();
System.out.print(node.getData()+" ");
if(node.getLeft()!=null){
queue.addLast(node.getLeft());
}
if(node.getRight()!=null){
queue.addLast(node.getRight());
}
}
System.out.println();
} public void inOrder(Node curNode){
if(curNode==null){
return;
}
inOrder(curNode.getLeft());
System.out.print(curNode.getData()+" ");
inOrder(curNode.getRight());
}
//when deleting a node,we need the node and its parent.
private static class NodePair{ Node son;
Node parent; NodePair(Node son,Node parent){
this.son=son;
this.parent=parent;
} } }
AVL树
平衡二叉树的定义 (AVL—— 发明者为Adel'son-Vel'skii 和 Landis)
平衡二叉查找树,又称 AVL树。 它除了具备二叉查找树的基本特征之外,还具有一个非常重要的特点:它 的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值(平衡因子 ) 不超过1。 也就是说AVL树每个节点的平衡因子只可能是-1、0和1(左子树高度减去右子树高度)。
那么如何是二叉查找树在添加数据的同时保持平衡呢?基本思想就是:当在二叉排序树中插入一个节点时,首先检查是否因插入而破坏了平衡,若 破坏,则找出其中的最小不平衡二叉树,在保持二叉排序树特性的情况下,调整最小不平衡子树中节点之间的关系,以达 到新的平衡。所谓最小不平衡子树 指离插入节点最近且以平衡因子的绝对值大于1的节点作为根的子树。
平衡二叉树的操作
1. 查找操作
平衡二叉树的查找基本与二叉查找树相同。
2. 插入操作
在平衡二叉树中插入结点与二叉查找树最大的不同在于要随时保证插入后整棵二叉树是平衡的。那么调整不平衡树的基本方法就是: 旋转 。 下面我们归纳一下平衡旋转的4中情况
1) 绕某元素左旋转
80 90
/ \ 左旋 / \
60 90 ---- -> 80 120
/ \ / \ /
85 120 60 85 100
/
100
a) BST树 b ) AVL树
分析一下:在插入数据100之前,a图的B ST树只有80节点的平衡因子是-1(左高-右高),但整棵树还是平衡的。加入100之后,80节点的平衡因子就成为了-2,此时平衡被破坏。需要左旋转成b 图。
当树中节点X的右孩子的右孩子上插入新元素,且平衡因子从-1变成-2后,就需要绕节点X进行左旋转。
2) 绕某元素右旋转
100 85
/ \ 右旋 / \
85 120 ------ -> 60 100
/ \ \ / \
60 90 80 90 120
\
80
a) B ST树 b) AVL树
当树中节点X的左孩子的左孩子上插入新元素,且平衡因子从1变成2后,就需要绕节点X进行右旋转。
3) 绕某元素的左子节点左旋转,接着再绕该元素自己右旋转。 此情况下就是左旋与右旋 的结合,具体操作时可以分 解成这两种操作,只是围绕点不一样而已。
100 100 90
/ \ 左旋 / \ 右旋 / \
80 120 ------> 90 120 ------> 80 100
/ \ / / \ \
60 90 80 60 85 120
/ / \
85 60 85
当树中节点X的左孩子的右孩子上插入新元素,且 平衡因子从1变成2后,就需要 先绕X的左子节点Y左旋转,接着再绕X右旋转
4) 绕某元素的右子节点右旋转,接着再绕该元素自己左旋转。 此情况下就是 右旋与左旋 的结合,具体操作时可以分解 成这两种操作,只是围绕点不一样而已 。
80 80 85
/ \ 右 旋 / \ 左 旋 / \
60 100 ------> 60 85 -------> 80 100
/ \ \ / / \
85 120 100 60 90 120
\ / \
90 90 120
当树中节点X的右孩子的左孩子上插入新元素,且 平衡因子从-1变成-2后,就需要 先绕X的右子节点Y右旋转,接着再绕X左旋转
平衡二叉树性能分析
平衡二叉树的性能优势:
很显然,平衡二叉树的优势在于不会出现普通二叉查找树的最差情况。其查找的时间复杂度为O(logN)。
平衡二叉树的缺陷:
(1) 很遗憾的是,为了保证高度平衡,动态插入和删除的代价也随之增加。因此,我们在下一专题中讲讲《红黑树》 这种更加高效的查找结构。
(2) 所有二叉查找树结构的查找代价都与树高是紧密相关的,能否通过减少树高来进一步降低查找代价呢。我们可以通过多路查找树的结构来做到这一点,在后面专题中我们将通过《多路查找树/B-树/B+树 》来介绍。
(3) 在大数据量查找环境下(比如说系统磁盘里的文件目录,数据库中的记录查询 等),所有的二叉查找树结构(BST、AVL、RBT)都不合适。如此大规模的数据量(几G数据),全部组织成平衡二叉树放在内存中是不可能做到的。那么把这棵树放在磁盘中吧。问题就来了:假如构造的平衡二叉树深度有1W层。那么从根节点出发到叶子节点很可能就需要1W次的硬盘IO读写。大家都知道,硬盘的机械部件读写数据的速度远远赶不上纯电子媒体的内存。 查找效率在IO读写过程中将会付出巨大的代价。在大规模数据查询这样一个实际应用背景下,平衡二叉树的效率就很成问题了。对这一问题的解决:我们也会在《多路查找树/B-树/B+树 》 将详细分析。
上面提到的红黑树和多路查找树都是属于深度有界查找树(depth-bounded tree —DBT)
平衡二叉树插入实现
package net.hr.algorithm.search;
/**平衡因子枚举类*/
enum B
alanceFactor{
LH("左子树高"),EH("左右等高"),RH("右子树高"); private String illustration=""; private BalanceFactor(String s){
this.illustration=s;
} public String toString(){
return this.illustration;
}
}
/**
* 平衡二叉树结点
*/
class AVLNode<E extends Comparable<E>>{
/**结点关键字*/
E key=null;
/**结点的平衡因子*/
BalanceFactor bFactor=BalanceFactor.EH;
/**结点的直接父亲*/
AVLNode<E> parent=null;
/**结点的左右孩子*/
AVLNode<E> lchild,rchild=null; AVLNode(E k){
this.key=k;
}
/**
* 格式输出结点
*/
public String toString(){
//String fomateStr="";
//if(this.lchild==null)
String lchildStr=(this.lchild==null)?"null":this.lchild.key.toString();
String rchildStr=(this.rchild==null)?"null":this.rchild.key.toString();
return this.key+"[lchild="+lchildStr+",rchild="+rchildStr+"]";
} }
/**
* 平衡二叉查找树
* @author heartraid
*/
public class AVL<E extends Comparable<E>> { /**树根*/
private AVLNode<E> root=null;
/**当前树是否变高*/
public boolean isTaller=false; public AVL(){
} public boolean insert(E key){
System.out.print("插入["+key+"]:");
if(key==null) return false;
if(root==null){
System.out.println("插入到树根。");
root=new AVLNode<E>(key);
return true;
}
else{
System.out.print("搜索路径[");
return insertAVL(key,root);
}
} private boolean insertAVL(E key,AVLNode<E> node){
System.out.print(node.key+" —>");
// 树中存在相同的key,不需要插入
if(node.key.compareTo(key)==0){
System.out.println("]. 搜索有相同关键字,插入失败");
isTaller=false;
return false;
}
else{
//左子树搜索
if(node.key.compareTo(key)>0){
//当前node的左孩子为空,则插入到结点的做孩子并修改结点的平衡因子为LH
if(node.lchild==null){
System.out.println("]. 插入到"+node.key+"的左孩子");
AVLNode<E> newNode=new AVLNode<E>(key);
node.lchild=newNode; //设置左孩子结点
newNode.parent=node; //设置父亲结点
isTaller=true; //树长高了
}
//左孩子不为空,则继续搜索下去
else{
insertAVL(key,node.lchild);
}
//当前如果树长高了,说明是因为左孩子的添加改变了平衡因子(左高)。
if(isTaller){
System.out.print(" 树变化了,"+node.key+"的平衡因子变化");
switch(node.bFactor){
//原来结点平衡因子是LH(bf=1),则左高以后bf=2,因此需要做左平衡旋转
case LH: {
System.out.println("[LH=1 ——> LH=2]. 出现了不平衡现象[左比右高2]");
System.out.println(" ★ 以"+node.key+"为根将树进行左平衡处理");
leftBalance(node);
isTaller=false;
break;
}
//原来结点平衡因子是EH(bf=0),则左高了以后bf=1,不需要平衡处理。
case EH:{
System.out.println("[EH=0 ——> LH=1]. 没有不平衡现象");
node.bFactor=BalanceFactor.LH;
isTaller=true;
break;
}
//原来结点平衡因子是RH(bf=-1),则左高以后bf=0,不需要平衡处理。
case RH:{
System.out.println("[RH=-1 ——> EH=0]. 没有不平衡现象");
node.bFactor=BalanceFactor.EH;
isTaller=false;
break;
}
}//end switch
}//end if
}//end if
//右子树搜索
else{
if(node.rchild==null){
System.out.println("]. 插入到"+node.key+"的右孩子");
AVLNode<E> newNode=new AVLNode<E>(key);
node.rchild=newNode; //设置右孩子结点
newNode.parent=node; //设置父亲结点
isTaller=true; //树长高了
}
else{
insertAVL(key,node.rchild);
}
//当前如果树长高了,说明是因为右孩子的添加改变了平衡因子(右高)。
if(isTaller){
System.out.print(" 树变化了,"+node.key+"的平衡因子变化");
switch(node.bFactor){
//原来结点平衡因子是LH(bf=1),则右高以后bf=0,不需要平衡处理。
case LH: {
System.out.println("[LH=1 ——> EH=0]. 没有不平衡现象");
node.bFactor=BalanceFactor.EH;
isTaller=false;
break;
}
//原来结点平衡因子是EH(bf=0),则右高了以后bf=-1,不需要平衡处理。
case EH:{
System.out.println("[EH=0 ——> RH=-1]. 没有不平衡现象");
node.bFactor=BalanceFactor.RH;
isTaller=true;
break;
}
//原来结点平衡因子是RH(bf=-1),则右高以后bf=0,因此需要做右平衡旋转。
case RH:{
System.out.println("[RH=-1 ——> RH=-2]. 出现了不平衡现象[左比右矮2]");
rightBalance(node);
isTaller=false;
break;
}
}//end switch
}//end if(isTaller)
}//end else
return true;
}//end else
}
/**
* 左平衡旋转处理
* 先对node的左子树进行单左旋处理,在对node树进行单右旋处理
*
* 100 100 90
* / \ 左旋 / \ 右旋 / \
* 80 120 ------> 90 120 ------> 80 100
* / \ / / \ \
* 60 90 80 60 85 120
* / / \
* 85 60 85
*
* @param node 需要做处理的子树的根结点
*/
private void leftBalance(AVLNode<E> node){
// node.parent指向新的孩子结点
AVLNode<E> lc=node.lchild;//lc指向node的左孩子结点
switch(lc.bFactor){
case LH:{ //新结点插入在node的左孩子的左子树上,则需要单右旋处理
System.out.println(" ┖ 对"+node.key+"进行单右旋转处理");
node.bFactor=lc.bFactor=BalanceFactor.EH;
rRotate(node);
break;
}
case RH:{ //新结点插入在node的左孩子的右子树上,需要双旋处理
System.out.println(" ┖ 对"+node.key+"的左子树进行单左旋转处理,再对其本身树进行单右循环处理");
AVLNode<E> rd=lc.rchild; //rd指向node左孩子的右子树根
switch(rd.bFactor){ //修改node与其左孩子的平衡因子
case LH:{
node.bFactor=BalanceFactor.RH;
lc.bFactor=BalanceFactor.EH;
break;
}
case EH:{
node.bFactor=lc.bFactor=BalanceFactor.EH;
break;
}
case RH:{
node.bFactor=BalanceFactor.EH;
lc.bFactor=BalanceFactor.LH;
break;
}
}//switch
rd.bFactor=BalanceFactor.EH;
lRotate(node.lchild);
rRotate(node);
break;
}
} }
/**
* 右平衡旋转处理
*
* 80 80 85
* / \ 右 旋 / \ 左 旋 / \
* 60 100 ------> 60 85 -------> 80 100
* / \ \ / / \
* 85 120 100 60 90 120
* \ / \
* 90 90 120
*
* @param node
*/
private void rightBalance(AVLNode<E> node){
AVLNode<E> lc=node.rchild;//lc指向node的右孩子结点
switch(lc.bFactor){
case RH:{ //新结点插入在node的右孩子的右子树上,则需要单左旋处理
node.bFactor=lc.bFactor=BalanceFactor.EH;
lRotate(node);
break;
}
case LH:{ //新结点插入在node的右孩子的左子树上,需要双旋处理
AVLNode<E> rd=lc.lchild; //rd指向node右孩子的左子树根
switch(rd.bFactor){ //修改node与其右孩子的平衡因子
case LH:{
node.bFactor=BalanceFactor.EH;
lc.bFactor=BalanceFactor.RH;
break;
}
case EH:{
node.bFactor=lc.bFactor=BalanceFactor.EH;
break;
}
case RH:{
node.bFactor=BalanceFactor.LH;
lc.bFactor=BalanceFactor.EH;
break;
}
}//switch
rd.bFactor=BalanceFactor.EH;
rRotate(node.rchild);
lRotate(node);
break;
}
}
} /**
* 对以node为根的子树进行单右旋处理,处理后node.parent指向新的树根,即旋转之前
* node的左孩子结点
* 100<-node.parent 80<-node.parent
* / / \
* 80 ———> 60 100
* / \ /
* 60 85 85
*/
private void rRotate(AVLNode<E> node){ AVLNode<E> lc=node.lchild;//lc指向node的左孩子结点 node.lchild=lc.rchild;
lc.rchild=node;
if(node.parent==null){
root=lc;
}
else if(node.parent.lchild.key.compareTo(node.key)==0)
node.parent.lchild=lc;
else node.parent.rchild=lc;
}
/**
* 对以node为根的子树进行单左旋处理,处理后node.parent指向新的树根,即旋转之前
* node的右孩子结点
* 100<-node.parent 110<-node.parent
* \ / \
* 110 ————> 100 120
* / \ \
* 105 120 105
*/
private void lRotate(AVLNode<E> node){
AVLNode<E> rc=node.rchild;//lc指向node的右孩子结点
node.rchild=rc.lchild;
rc.lchild=node;
if(node.parent==null){
root=rc; }
else if(node.parent.lchild.key.compareTo(node.key)==0)
node.parent.lchild=rc;
else node.parent.rchild=rc;
} /**
* 得到BST根节点
* @return BST根节点f
*/
public AVLNode<E> getRoot(){
return this.root;
} /**
* 递归前序遍历树
*/
public void preOrderTraverse(AVLNode<E> node){
if(node!=null){
System.out.println(node);
preOrderTraverse(node.lchild);
preOrderTraverse(node.rchild);
}
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
AVL<Integer> avl=new AVL<Integer>();
avl.insert(new Integer(80));
avl.insert(new Integer(60));
avl.insert(new Integer(90));
avl.insert(new Integer(85));
avl.insert(new Integer(120));
avl.insert(new Integer(100)); System.out.println("前序遍历AVL:");
avl.preOrderTraverse(avl.getRoot()); }
}
红黑树
红黑树的性质与定义
红黑树(red-black tree) 是一棵满足下述性质的二叉查找树:
1. 每一个结点要么是红色,要么是黑色。
2. 根结点是黑色的。
3. 所有叶子结点都是黑色的(实际上都是Null指针,下图用NIL表示)。叶子结点不包含任何关键字信息,所有查询关键字都在非终结点上。
4. 每个红色结点的两个子节点必须是黑色的。换句话说:从每个叶子到根的所有路径上不能有两个连续的红色结点
5. 从任一结点到其每个叶子的所有路径都包含相同数目的黑色结点

黑深度 ——从某个结点x出发(不包括结点x本身)到叶结点(包括叶子结点)的路径上的黑结点个数,称为该结点x的黑深度,记为bd(x),根结点的黑深度就是该红黑树的黑深度。叶子结点的黑深度为0。比如:上图bd(13)=2,bd(8)=2,bd(1)=1
内部结点 —— 红黑树的非终结点
外部节点 —— 红黑树的叶子结点
红黑树相关定理
1. 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。
根据上面的性质5我们知道上图的红黑树每条路径上都是3个黑结点。因此最短路径长度为2(没有红结点的路径)。再根据性质4(两个红结点不能相连)和性质1,2(叶子和根必须是黑结点)。那么我们可以得出:一条具有3个黑结点的路径上最多只能有2个红结点(红黑间隔存在)。也就是说黑深度为2(根结点也是黑色)的红黑树最长路径为4,最短路径为2。从这一点我们可以看出红黑树是 大致平衡的。 (当然比平衡二叉树要差一些,AVL的平衡因子最多为1)
2. 红黑树的树高(h)不大于两倍的红黑树的黑深度(bd),即h<=2bd
根据定理1,我们不难说明这一点。bd是红黑树的最短路径长度。而可能的最长路径长度(树高的最大值)就是红黑相间的路径,等于2bd。因此h<=2bd。
3. 一棵拥有n个内部结点(不包括叶子结点)的红黑树的树高h<=2log(n+1)
下面我们首先证明一颗有n个内部结点的红黑树满足n>=2^bd-1。这可以用数学归纳法证明,施归纳于树高h。当h=0时,这相当于是一个叶结点,黑高度bd为0,而内部结点数量n为0,此时0>=2^0-1成立。假设树高h<=t时,n>=2^bd-1成立,我们记一颗树高 为t+1的红黑树的根结点的左子树的内部结点数量为nl,右子树的内部结点数量为nr,记这两颗子树的黑高度为bd'(注意这两颗子树的黑高度必然一 样),显然这两颗子树的树高<=t,于是有nl>=2^bd'-1以及nr>=2^bd'-1,将这两个不等式相加有nl+nr>=2^(bd'+1)-2,将该不等式左右加1,得到n>=2^(bd'+1)-1,很显然bd'+1>=bd,于是前面的不等式可以 变为n>=2^bd-1,这样就证明了一颗有n个内部结点的红黑树满足n>=2^bd-1。
在根据定理2,h<=2bd。即n>=2^(h/2)-1,那么h<=2log(n+1)
从这里我们能够看出,红黑树的查找长度最多不超过2log(n+1),因此其查找时间复杂度也是O(log N)级别的。
红黑树的操作
因为每一个红黑树也是一个特化的二叉查找树,因此红黑树上的查找操作与普通二叉查找树上的查找操作相同。然而,在红黑树上进行插入操作和删除操作会导致不 再符合红黑树的性质。恢复红黑树的属性需要少量(O(log n))的颜色变更(实际是非常快速的)和不超过三次树旋转(对于插入操作是两次)。 虽然插入和删除很复杂,但操作时间仍可以保持为 O(log n) 次 。
插入操作
我们首先以二叉查找树的方法增加节点并标记它为红色。 ( 如果设为黑色,就会导致根到叶子的路径上有一条路上,多一个额外的黑节点,这个是很难调整的。但是设为红色节点后,可能会导致出现两个连续红色节点的冲突,那么可以通过颜色调换(color flips)和树旋转来调整。) 下面要进行什么操作取决于其他临近节点的颜色。同人类的家族树中一样,我们将使用术语叔父节点来指一个节点的父节点的兄弟节点。
假设新加入的结点为N,父亲结点为P,叔父结点为Ui(叔父结点就是一些列P的兄弟结点),祖父结点G(父亲结点P的父亲)。下面会给出每一种情况,我们将使用C示例代码来展示。通过下列函数,可以找到一个节点的叔父和祖父节点:
情况1. 当前红黑树为空,新结点N位于树的根上,没有父结点。
此时很简单,我们将直接插入一个黑结点N(满足性质2),其他情况下插入的N为红色(原因在前面提到了)。
情况2. 新结点N的父结点P是黑色。
在这种情况下,我们插入一个红色结点N(满足性质5)。
注意:在情况3,4,5下,我们假定新节点有祖父节点,因为父节点是红色;并且如果它是根,它就应当是黑色。所以新节点总有一个叔父节点,尽管在情形4和5下它可能是叶子。
情况3.如果父节点P和叔父节点U二者都是红色。
如下图,因为新加入的N结点必须为红色,那么我们可以将父结点P(保证性质4),以及N的叔父结点U(保证性质5)重新绘制成黑色。如果此时祖父结点G是根,则结束变化。如果不是根,则祖父结点重绘为红色(保证性质5)。但是,G的父亲也可能是红色的,为了保证性质4。我们把G递归当做新加入的结点N在进行各种情况的重新检查。

注意:在情形4和5下,我们假定父节点P 是祖父结点G 的左子节点。如果它是右子节点,情形4和情形5中的左和右应当对调。
情况4. 父节点P是红色而叔父节点U是黑色或缺少; 另外,新节点N是其父节点P的右子节点,而父节点P又是祖父结点G的左子节点。
如下图, 在这种情形下,我们进行一次左旋转调换新节点和其父节点的角色(与AVL树的左旋转相同); 这导致某些路径通过它们以前不通过的新节点N或父节点P中的一个,但是这两个节点都是红色的,所以性质5没有失效。但目前情况将违反性质4,所以接着,我们按下面的情况5继续处理以前的父节点P。

情况5. 父节点P是红色而叔父节点U 是黑色或缺少,新节点N 是其父节点的左子节点,而父节点P又是祖父结点的G的左子节点。
如下图: 在这种情形下,我们进行针对祖父节点P 的一次右旋转; 在旋转产生的树中,以前的父节点P现在是新节点N和以前的祖父节点G 的父节点。我们知道以前的祖父节点G是黑色,否则父节点P就不可能是红色。我们切换以前的父节点P和祖父节点G的颜色,结果的树满足性质4[3]。性质 5[4]也仍然保持满足,因为通过这三个节点中任何一个的所有路径以前都通过祖父节点G ,现在它们都通过以前的父节点P。在各自的情形下,这都是三个节点中唯一的黑色节点。

删除操作
如果需要删除的节点有两个儿子,那么问题可以被转化成删除另一个只有一个儿子的节点的问题(为了表述方便,这里所指的儿子,为非叶子节点的儿子)。 对于二叉查找树,在删除带有两个非叶子儿子的节点的时候,我们找到要么在它的左子树中的最大元素、要么在它的右子树中的最小元素,并把它的值转移到要删除 的节点中(如在这里所展示的那样)。我们接着删除我们从中复制出值的那个节点,它必定有少于两个非叶子的儿子。因为只是复制了一个值而不违反任何属性,这 就把问题简化为如何删除最多有一个儿子的节点的问题。它不关心这个节点是最初要删除的节点还是我们从中复制出值的那个节点。
在本文余下的部分中,我们只需要讨论删除只有一个儿子的节点(如果它两个儿子都为空,即均为叶子,我们任意将其中一个看作它的儿子)。如果我们删除一个红色节点,它的父亲和儿子一定是黑色的。所以我们可以简单的用它的黑色儿子替换它,并不会破坏属性3和4。通过被删除节点的所有路径只是少了一个红色 节点,这样可以继续保证属性5。另一种简单情况是在被删除节点是黑色而它的儿子是红色的时候。如果只是去除这个黑色节点,用它的红色儿子顶替上来的话,会 破坏属性4,但是如果我们重绘它的儿子为黑色,则曾经通过它的所有路径将通过它的黑色儿子,这样可以继续保持属性4。
需要进一步讨论的是在要删除的节点和它的儿子二者都是黑色的时候,这是一种复杂的情况。我们首先把要删除的节点替换为它的儿子。出于方便,称呼这个儿子为 N,称呼它的兄弟(它父亲的另一个儿子)为S。在下面的示意图中,我们还是使用P称呼N的父亲,SL称呼S的左儿子,SR称呼S的右儿子。我们将使用下述 函数找到兄弟节点:
我们可以使用下列代码进行上述的概要步骤,这里的函数 replace_node 替换 child 到 n 在树中的位置。出于方便,在本章节中的代码将假定空叶子被用不是 NULL 的实际节点对象来表示(在插入章节中的代码可以同任何一种表示一起工作)。
如果 N 和它初始的父亲是黑色,则删除它的父亲导致通过 N 的路径都比不通过它的路径少了一个黑色节点。因为这违反了属性 4,树需要被重新平衡。有几种情况需要考虑:
情况1. N 是新的根。
在这种情况下,我们就做完了。我们从所有路径去除了一个黑色节点,而新根是黑色的,所以属性都保持着。
注意: 在情况2、5和6下,我们假定 N 是它父亲的左儿子。如果它是右儿子,则在这些情况下的左和右应当对调。
情况2. S 是红色。
在这种情况下我们在N的父亲上做左旋转,把红色兄弟转换成N的祖父。我们接着对调 N 的父亲和祖父的颜色。尽管所有的路径仍然有相同数目的黑色节点,现在 N 有了一个黑色的兄弟和一个红色的父亲,所以我们可以接下去按 4、5或6情况来处理。(它的新兄弟是黑色因为它是红色S的一个儿子。)

情况 3: N 的父亲、S 和 S 的儿子都是黑色的。
在这种情况下,我们简单的重绘 S 为红色。结果是通过S的所有路径, 它们就是以前不通过 N 的那些路径,都少了一个黑色节点。因为删除 N 的初始的父亲使通过 N 的所有路径少了一个黑色节点,这使事情都平衡了起来。但是,通过 P 的所有路径现在比不通过 P 的路径少了一个黑色节点,所以仍然违反属性4。要修正这个问题,我们要从情况 1 开始,在 P 上做重新平衡处理。
 、
、
情况4. S 和 S 的儿子都是黑色,但是 N 的父亲是红色。
在这种情况下,我们简单的交换 N 的兄弟和父亲的颜色。这不影响不通过 N 的路径的黑色节点的数目,但是它在通过 N 的路径上对黑色节点数目增加了一,添补了在这些路径上删除的黑色节点。

情况5. S 是黑色,S 的左儿子是红色,S 的右儿子是黑色,而 N 是它父亲的左儿子。
在这种情况下我们在 S 上做右旋转,这样 S 的左儿子成为 S 的父亲和 N 的新兄弟。我们接着交换 S 和它的新父亲的颜色。所有路径仍有同样数目的黑色节点,但是现在 N 有了一个右儿子是红色的黑色兄弟,所以我们进入了情况 6。N 和它的父亲都不受这个变换的影响。

void delete_case5(struct node *n)
{
struct node *s = sibling(n); if (s->color == BLACK)
if ((n == n->parent->left) &&
(s->right->color == BLACK) &&
(s->left->color == RED)) { // this last test is trivial too due to cases 2-4.
s->color = RED;
s->left->color = BLACK;
rotate_right(s);
} else if ((n == n->parent->right) &&
(s->left->color == BLACK) &&
(s->right->color == RED)) {// this last test is trivial too due to cases 2-4.
s->color = RED;
s->right->color = BLACK;
rotate_left(s);
}
}
delete_case6(n);
}
情况6. S 是黑色,S 的右儿子是红色,而 N 是它父亲的左儿子。
在这种情况下我们在 N 的父亲上做左旋转,这样 S 成为 N 的父亲和 S 的右儿子的父亲。我们接着交换 N 的父亲和 S 的颜色,并使 S 的右儿子为黑色。子树在它的根上的仍是同样的颜色,所以属性 3 没有被违反。但是,N 现在增加了一个黑色祖先: 要么 N 的父亲变成黑色,要么它是黑色而 S 被增加为一个黑色祖父。所以,通过 N 的路径都增加了一个黑色节点。
此时,如果一个路径不通过 N,则有两种可能性:
它通过 N 的新兄弟。那么它以前和现在都必定通过 S 和 N 的父亲,而它们只是交换了颜色。所以路径保持了同样数目的黑色节点。
它通过 N 的新叔父,S 的右儿子。那么它以前通过 S、S 的父亲和 S 的右儿子,但是现在只通过 S,它被假定为它以前的父亲的颜色,和 S 的右儿子,它被从红色改变为黑色。合成效果是这个路径通过了同样数目的黑色节点。
在任何情况下,在这些路径上的黑色节点数目都没有改变。所以我们恢复了属性 4。在示意图中的白色节点可以是红色或黑色,但是在变换前后都必须指定相同的颜色。

同样的,函数调用都使用了尾部递归,所以算法是就地的。此外,在旋转之后不再做递归调用,所以进行了恒定数目(最多 3 次)的旋转。
红黑树的优势
红黑树能够以O(log2(N))的时间复杂度进行搜索、插入、删除操作。此外,任何不平衡都会在3次旋转之内解决。这一点是AVL所不具备的。
而且实际应用中,很多语言都实现了红黑树的数据结构。比如 TreeMap, TreeSet(Java )、 STL(C++)等。
单例模式,堆,BST,AVL树,红黑树的更多相关文章
- AVL树,红黑树
AVL树 https://baike.baidu.com/item/AVL%E6%A0%91/10986648 在计算机科学中,AVL树是最先发明的自平衡二叉查找树.在AVL树中任何节点的两个子树的高 ...
- 浅谈AVL树,红黑树,B树,B+树原理及应用(转)
出自:https://blog.csdn.net/whoamiyang/article/details/51926985 背景:这几天在看<高性能Mysql>,在看到创建高性能的索引,书上 ...
- 浅谈AVL树,红黑树,B树,B+树原理及应用
背景:这几天在看<高性能Mysql>,在看到创建高性能的索引,书上说mysql的存储引擎InnoDB采用的索引类型是B+Tree,那么,大家有没有产生这样一个疑问,对于数据索引,为什么要使 ...
- 数据结构(一)二叉树 & avl树 & 红黑树 & B-树 & B+树 & B*树 & R树
参考文档: avl树:http://lib.csdn.net/article/datastructure/9204 avl树:http://blog.csdn.net/javazejian/artic ...
- 树:BST、AVL、红黑树、B树、B+树
我们这个专题介绍的动态查找树主要有: 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree).这四种树都具备下面几个优势: (1) 都是动态结构.在删除,插入操 ...
- 数据结构与算法--从平衡二叉树(AVL)到红黑树
数据结构与算法--从平衡二叉树(AVL)到红黑树 上节学习了二叉查找树.算法的性能取决于树的形状,而树的形状取决于插入键的顺序.在最好的情况下,n个结点的树是完全平衡的,如下图"最好情况&q ...
- 数据结构图解(递归,二分,AVL,红黑树,伸展树,哈希表,字典树,B树,B+树)
递归反转 二分查找 AVL树 AVL简单的理解,如图所示,底部节点为1,不断往上到根节点,数字不断累加. 观察每个节点数字,随意选个节点A,会发现A节点的左子树节点或右子树节点末尾,数到A节点距离之差 ...
- B树 B+树 红黑树
B-Tree(B树) 具体讲解之前,有一点,再次强调下:B-树,即为B树.因为B树的原英文名称为B-tree,而国内很多人喜欢把B-tree译作B-树,其实,这是个非常不好的直译,很容易让人产生误解. ...
- 2-3 树/红黑树(red-black tree)
2-3 tree 2-3树节点: null节点,null节点到根节点的距离都是相同的,所以2-3数是平衡树 2叉节点,有两个分树,节点中有一个元素,左树元素更小,右树元素节点更大 3叉节点,有三个子树 ...
- 平衡树B树B+树红黑树
二叉树与二叉查找树的操作是必须要熟练掌握的,接下来说的这些树实现起来很困难,所以我们重点去了解他们的特点. 一.平衡二叉查找树与红黑树 平衡树AVL:追求绝对的高度平衡,它具有稳定的logn的高度,因 ...
随机推荐
- 图片文档倾斜矫正算法 附完整c代码
2年前在学习图像算法的时候看到一个文档倾斜矫正的算法. 也就是说能将一些文档图像进行旋转矫正, 当然这个算法一般用于一些文档扫描软件做后处理 或者用于ocr 文字识别做前处理. 相关的关键词: 抗倾斜 ...
- 官方新出的 Kotlin 扩赞库 KTX,到底帮你干了什么?
Kotlin KTX 2月5号的时候,Google 发布了一款 Kotlin 的扩展库,叫 Android KTX,不过现在还处于预览版的状态.它能使 Android 上的 Kotlin 代码更简洁, ...
- windows上搭建svn 、 Eclipse上安装svn插件 、 eclipse中如何使用svn
折腾了许久终于搞出来了. svn搭建 一.svn概述 SVN就是用于多个人共同开发同一个项目,共用资源的目的,该文描述了把svn搭建在本地上,和搭建在Eclipse4.5.2上. 二.svn分类 分为 ...
- Java 解压zip压缩包
因为最近项目需要批量上传文件,而这里的批量就是将文件压缩在了一个zip包里,然后读取文件进行解析文件里的内容. 因此需要先对上传的zip包进行解压.以下直接提供代码供参考: 1.第一个方法是用于解压z ...
- Linux中的Buffer 与 Cache
A buffer is something that has yet to be "written" to disk. A cache is something tha ...
- BZOJ 3698: XWW的难题 [有源汇上下界最大流]
3698: XWW的难题 题意:(1)A[N][N]=0:(2)矩阵中每行的最后一个元素等于该行前N-1个数的和:(3)矩阵中每列的最后一个元素等于该列前N-1个数的和.给A中的数进行取整操作(可以是 ...
- 读书共享 Primer Plus C-part11
第十四章结构和其他数据形式 关于fread以及fwrite fread(char* buff,int size,int count,FILE* fp) fwrite(char* buff,int si ...
- htmlUtil 网页爬取工具
Htmlunit是一款模拟浏览抓取页面内容的Java框架,具有js解析引擎(rhino),可以解析页面的js脚本,得到完整的页面内容,特殊适合于这种非完整页面的站点抓取 /** * 获取页面的TITL ...
- 一个客户端一键安装环境和服务的shell脚本
#!/bin/bash basepath=$(cd `dirname $0`; pwd)SHELL_DIR="${basepath}/shell"PACKAGE_DIR=" ...
- angularjs 控制器、作用域、广播详解
一.控制器 首先列出几种我们平常使用控制器时的几种误区: 我们知道angualrJs中一个控制器时可以对应不同的视图模板的,但这种实现方式存在的问题是: 如果视图1和视图2根本没有任何逻辑关系,这样& ...