第三节最大似然推导mse损失函数(深度解析最小二乘来源)
在第二节中,我们介绍了高斯分布的来源,以及其概率密度函数对应的参数的解释。本节的话,我们结合高斯分布从数学原理部分解释为什么损失函数是最小二乘。我们再来回归下高斯分布的概率密度函数实际上是这个形式的:


那么这个函数有什么用?其实就是给一个X,就能知道X发生的可能性有多大?相当于给每一个X的一个得分。那么我们回忆一下,在咱们讲这概率论之前,咱们讲的最后一个概念是什么?最小二乘损失函数。我们由什么推到最小二乘?实际上是由误差的概念推导而来,
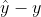
为什么会有误差?实际上因为咱们收集上来的特征不够全面,咱们提出一个假设,就是说我之所以没预测准,不是因为我模型不行,而是因为好多我该知道的事你没告诉我,比如我想预测房价,你就告诉我一个房子尺寸,你没告诉我这房子死没死人,这是一凶宅,结果卖的很便宜,所以我们受到了好多个没有收集到的因素得影响,产生了一个误差,我们叫做ε,而这个东西和我们讲的高斯分布是不是就有点能联系上。那么误差本身是大是小,应该服从一个什么分布最合理,
误差究竟怎么来的?其实是由好多个没统计到的随机变量X共同决定着误差是大是小的。这么多没统计到的随机变量,所以我假设误差服从高斯分布是不是最合理?。我没说它一定就客观上服从高斯分布,但你也不知道它服从什么分布的情况下,就硬让你服从一个分布,你选什么你只能选高斯分布。因为适用性最广。所以我们的线性回归里面核心的一点就是它认为背后的误差是服从一个均值为零的高斯分布的。
误差为什么均值为零?假设就是这么假设的,你想误差如果均值不为零的话,那就说明你这条线整个就偏了,假如普遍大家都有1的误差,有的比1小点,有的比1大点,说明你此时的θ肯定不是最好的θ。你一旦将θ调整到最好了之后,你的误差一定均值得为零,因为你的基准线一定要落在你预测的这条线上才对。如果你想你的误差是服从一个均值为1,方差为某个数的高斯分布,那说明大家普遍都差了1,说明你这个预测不是最好的预测,你普遍都差着呢。既然均值为零,所以误差有的往正的偏,有的往负的偏,你偏得越多的点应该越少,偏的越少的点应该越多,这样才能满足误差为零。这个理论和假设实际上是线性回归的基石,就是它没有任何道理,当然也不能说没有一点道理,还是有一些道理的,假设误差服从一个均值为零的高斯分布,这点大家是否能够明白,能够意识到它是合理的 ,为什么要用高斯分布估计它? 因为它是若干个你没看到的X共同影响的那么一个结果,这些
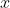
不一定是相加的关系,没关系,反正我也不知道它是怎么回事,我干脆就拿高斯分布来做,至少这个东西不会差的太多。
好的,至此为止,你已经了解了线性回归模型的假设,并且能体会到它有一定的道理。那么我们接着讲误差的事。看下面的公式:

咱们逐个元素的去分析公式中的含义,
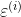
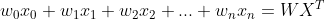
我们总结下上面说的核心。误差是由我们多个未观测到的属性或者叫特征决定的,多个未观测到的属性共同决定误差,我们应该假设它符合同一个高斯分布,什么样的高斯分布呢?就是误查服从一个均值为零,方差虽然你不知道,但一定也是某个确定的值的高斯分布。好,上面的核心你已了解,我们就可以引入一个概率的问题,一个可能性问题。既然误差服从均值为零的高斯分布,那误差自己的概率密度函数写出来如下:
某一个误差发生的概率是不是就应该等于上面的公式。用心观察一下这个式子怎么来的?还记得高斯分布的概率密度函数吗?
对比发现是不是只有


变了,为什么变了? 均值为零,它本来应该减个零,把减零去掉了。那么每个样本被采样到的概率也应该为:
上面公式要怎么理解呢?那么假如有一个样本,预测的
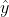
是1.6,真实的
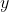
是2.0,那么它的误差

是0.4,带入误差的概率密度函数是不是可以计算出0.4发生的概率是有多大? 而
为0.4发生就代表一个真实结果为2.0的值被你取到了。因为你预测的
已经算出来了就等于1.6了,所以它们是可以唯一相互确定的,这点要想透。

这个叫做条件概率,表示在已知
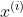
的情况下,
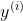
发生的概率。其实换个角度也能理解,就是因为
替换成
,结果是一样的,只不过我们要从实际含义去理解。
既然知道每个样本采样到的概率后,那我们来计算这个概率。可以发现这里面真正变得是
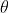
,因为其他参数都是已知,假如
全等于0,你算出来的是一个概率,假如
全等于1,算出来是另一个概率,也就是说每一条样本被采样到的可能性是随着
的变化而变化的。这是某一条样本被采样到的概率,而最终所有的样本都被你采样到了。比如说你拿到了1万条数据,拿第一条数据,是不是有一组
,有一个
,分别是
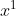
和
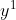
,带进去上面的概率公式,得到一个关于
的一个表达式。只要
确定,结果也就确定了。那么第一条样本被抽样到的概率是一个关于
的表达式,第二个样本被抽样到的概率也是一个关于
的表达式,跟第一个表达式不一样,因为带进去的
跟
是不一样的,这样下去,你会得到1万个表达式, 每个表达式代表每一个点被抽样到的概率,1万个点共同的被抽样到了,那么你通通把它乘起来,就代表这1万个点共同被你抽样到的概率,得到了一个总的概率。总的概率是高是低取决于谁?
已知
已知,所以总概率高低取决于
,
变一变,这总概率就变一变。 那么你希望找到的
是使总概率越高还是越低越好?因为你已经抽样到了这些数据,你最合理的
应该能让样本总体被抽样到的概率越高越好,
才越趋近于真实。我们称这种思想叫做极大似然估计(MLE)。所谓似然就是上面说的1万个
的表达式相乘的结果就叫似然,其实就是最大概率估计,只不过民国时期翻译那些经典的数学书籍的时候,把概率翻译成了似然。
由于训练集上的样本被抽选到这个随机事件是彼此独立的,那么训练集上所有的样本全部都被抽选到的概率转换为数学公式就是:
通常我们称上面的总概率函数为似然函数。那什么样的
是最好的
呢?能够使这个式子最大的θ就是最好的
。因为它代表整个训练及被抽样到的总概率,既然它已经发生的事情,概率理应最大,这样
才最真实,否则
计算出来,这个概率没有达到最大,说明给的
不够好,毕竟这些东西已经被你抽到了,这个概率还没达到最高值,说明给的
不够合理。所以最大似然的思想就是已经抽样到的样本的总概率应该最大,而最合理的
就应该是让似然函数最大的
。这一点只要理解透了,后面的东西都很简单,这是本节最大的重点,极大似然估计会出现在机器学习的方方面面。方方面面都会有极大似然估计,它的核心思想就是已经发生的概率理应最大,而且概率取决于谁?取决于
。
我们不要忘记初心,我们机器学习,学习的是一组参数

,其实就是
,本质就想找到一组最好的
,现在似然函数是不是相当于给了我们一个指导方针? 能够让总概率最大(也就是似然函数最大)的
就是最好的
。
那么这跟那MSE函数(损失函数)有什么关系?我们回顾之前的知识,我们的目的是想找到一组一组参数
,即(
),使损失函数(MSE)最小,而本节讲的是让这组参数
(即
),使似然函数最大,那么他们之间矛盾吗?要是能找到他们之间的关系,是不是所有的原理,无论从哪一方面都能解释通了。所以下一节中,我们来解剖MSE和最大似然之间的真正关系。
- 大白话5分钟带你走进人工智能-第二十节逻辑回归和Softmax多分类问题(5)
大白话5分钟带你走进人工智能-第二十节逻辑回归和Softmax多分类问题(5) 上一节中,我们讲 ...
- 大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2)
大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2) 上一节中我们讲解了随机森林的基本概念,本节的话我们讲解随机森 ...
- 大白话5分钟带你走进人工智能-第四节最大似然推导mse损失函数(深度解析最小二乘来源)(2)
第四节 最大似然推导mse损失函数(深度解析最小二乘来源)(2) 上一节我们说了极大似然的思想以及似然函数的意义,了解了要使模型最好的参数值就要使似然函数最大,同时损失函数(最小二乘)最小,留下了一 ...
- 大白话5分钟带你走进人工智能-第32节集成学习之最通俗理解XGBoost原理和过程
目录 1.回顾: 1.1 有监督学习中的相关概念 1.2 回归树概念 1.3 树的优点 2.怎么训练模型: 2.1 案例引入 2.2 XGBoost目标函数求解 3.XGBoost中正则项的显式表达 ...
- 大白话5分钟带你走进人工智能-第十四节过拟合解决手段L1和L2正则
第十四节过拟合解决手段L1和L2正则 第十三节中, ...
- 大白话5分钟带你走进人工智能-第31节集成学习之最通俗理解GBDT原理和过程
目录 1.前述 2.向量空间的梯度下降: 3.函数空间的梯度下降: 4.梯度下降的流程: 5.在向量空间的梯度下降和在函数空间的梯度下降有什么区别呢? 6.我们看下GBDT的流程图解: 7.我们看一个 ...
- 大白话5分钟带你走进人工智能-第36节神经网络之tensorflow的前世今生和DAG原理图解(4)
目录 1.Tensorflow框架简介 2.安装Tensorflow 3.核心概念 4.代码实例和详细解释 5.拓扑图之有向无环图DAG 6.其他深度学习框架详细描述 6.1 Caffe框架: 6.2 ...
- 大白话5分钟带你走进人工智能-第二十六节决策树系列之Cart回归树及其参数(5)
第二十六节决策树系列之Cart回归树及其参数(5) 上一节我们讲了不同的决策树对应的计算纯度的计算方法, ...
- 大白话5分钟带你走进人工智能-第30节集成学习之Boosting方式和Adaboost
目录 1.前述: 2.Bosting方式介绍: 3.Adaboost例子: 4.adaboost整体流程: 5.待解决问题: 6.解决第一个问题:如何获得不同的g(x): 6.1 我们看下权重与函数的 ...
随机推荐
- Using Sass with the Angular CLI
https://www.tuicool.com/articles/mauiMzY One of the first things you'll usually do in a project is t ...
- 解决ubuntu unity下gvim菜单消失的问题
#问题描述:在终端下用gvim 指令打开 gvim就不显示菜单.在不启用unity的桌面环境下用终端打开gvim是有菜单的.从程序菜单中打开gvim是显示菜单的.用sudo打开gvim也可以显示菜单, ...
- android 开发中,经常遇到http://dl-ssl.google.com/ 无法访问的问题解决
window - android sdk manager 在选择某个版本sdk安装时,总是出现http://dl-ssl.google.com/无法链接的问题,那是因为qiang太高了,不过也还是有办 ...
- Mysql 快速指南
Mysql 快速指南 本文的示例在 Mysql 5.7 下都可以测试通过. 知识点 概念 数据库(database):保存有组织的数据的容器(通常是一个文件或一组文件). 数据表(table):某种特 ...
- 微信公众号网页授权登录--JAVA
网上搜资料时,网友都说官方文档太垃圾了不易看懂,如何如何的.现在个人整理了一个通俗易懂易上手的,希望可以帮助到刚接触微信接口的你. 请看流程图!看懂图,就懂了一半了: 其实整体流程大体只需三步:用户点 ...
- java之Spring实现控制反转
先来复习一下多态吧,简单点讲,就是一个类的引用可以指向其本身以及其子类的对象. Like these: FatherClass a = new FatherClass(); FatherClass a ...
- javaXML文件的写入之DOM和DOM4J
1.DOM篇 首先是DOM的操作方法,字符串数据可以从对象中读,例如上篇提到的Person对象,这里为了方便直接手写. package com.dom.node; import javax.xml.p ...
- jdk和tomcat环境配置
一.安装JDK和Tomcat 1,安装JDK:直接运行jdk-7-windows-i586.exe可执行程序,默认安装即可. 备注:路径可以其他盘符,不建议路径包含中文名及特殊符号. 2.安装Tomc ...
- 3D Lut 电影级调色算法 附完整C代码
在前面的文章,我提到过VSCO Cam 的胶片滤镜算法实现是3d lut. 那么3d lut 到底是个什么东西呢? 或者说它是用来做什么的? 长话短说,3d lut(全称 : 3D Lookup t ...
- C语言下double转char*或者std::string,可以精确转换不含多余的0
char* GetDoubleStr(double value) { char buf[32]={0};//长度可以自定义 sprintf(buf,"%.8f",value);// ...