Numpy&Pandas
Numpy & Pandas 简介
此篇笔记参考来源为《莫烦Python》
运算速度快:numpy 和 pandas 都是采用 C 语言编写, pandas 又是基于 numpy, 是 numpy 的升级版本。
消耗资源少:采用的是矩阵运算,会比 python 自带的字典或者列表快好多
Numpy 学习
2.1 numpy属性
ndim:维度shape:行数和列数size:元素个数
举例说明:
import numpy as np array = np.array([[1,2,3],[2,3,4]]) #列表转化为矩阵
print(array) print('number of dim:',array.ndim) # 维度
# number of dim: 2
print('shape :',array.shape) # 行数和列数
# shape : (2, 3)
print('size:',array.size) # 元素个数
# size: 6
2.2 Numpy 的创建 array
array:创建数组dtype:指定数据类型zeros:创建数据全为0ones:创建数据全为1empty:创建数据接近0arrange:按指定范围创建数据linspace:创建线段
import numpy as np #创建数组array
a = np.array([2,3,4])
print(a)
#[2 3 4] #指定数据类型dtype
b = np.array([2,3,4],dtype = np.int)
print(b.dtype)
#int32 #三行四列全零数组,括号内为shape
c = np.zeros((3,4))
print(c)
'''
[[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]]
''' #全一数组
d = np.ones((3,4))
print(d)
'''
[[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]]
''' #创建全空数组, 其实每个值都是接近于零的数
e = np.empty((3,4))
print(e) #用 arange 创建连续数组,与range用法类似
f = np.arange(10,20,2)#10-19 的数据,2步长
print(f)
#[10 12 14 16 18] #使用 reshape 改变数据的形状
g = np.arange(12).reshape((3,4))
print(g)
'''
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
''' #用 linspace 创建线段型数据
h = np.linspace(1,10,5)
print(h)
#[ 1. 3.25 5.5 7.75 10. ]
2.3 Numpy 基础运算1
- 加减乘除
- 幂运算
- sum、max、min
- 按行或按列(axis)
import numpy as np a = np.array([10,20,30,40])
b = np.arange(4) c = a + b # [10, 21, 32, 43]
c = a - b # [10, 19, 28, 37]
c = b**2 # [0, 1, 4, 9]
c=10*np.sin(a) # [-5.44021111, 9.12945251, -9.88031624, 7.4511316 ] print(b<3)# [ True, True, True, False]
a = np.array([[1,1],
[0,1]])
b = np.arange(4).reshape((2,2)) #对应元素相乘
c = a*b
'''
[[0 1]
[0 3]]
'''
#矩阵乘
c_dot = np.dot(a,b)
#c_dot = a.dot(b) '''
[[2 4]
[2 3]]
'''
a=np.random.random((2,4))
print(a) '''
[[ 0.35861795 0.4763303 0.62510912 0.64853572]
[ 0.53853158 0.70065019 0.17649662 0.99089602]]
''' np.sum(a) # 4.4043622002745959
np.min(a) # 0.23651223533671784
np.max(a) # 0.90438450240606416
如果你需要对行或者列进行查找运算,就需要在上述代码中为 axis 进行赋值。 当axis的值为0的时候,将会以列作为查找单元, 当axis的值为1的时候,将会以行作为查找单元。例:
print("sum =",np.sum(a,axis=1))
print("sum =",np.sum(a,axis=0))
2.4 Numpy 基础运算2
- argmin/argmax:求矩阵最小/大值的索引
- mean/average:求均值
- median:中位数
- cumsum:累加
- diff:累差
- nonzero:将所有非零元素的行与列坐标分割开,重构成两个分别关于行和列的矩阵
- sort:仅针对每一行进行从小到大排序操作
- 转置 transpose/T
- clip:
clip(Array,Array_min,Array_max)
import numpy as np A = np.arange(2,14).reshape((3,4))
print(A)
'''
[[ 2 3 4 5]
[ 6 7 8 9]
[10 11 12 13]]
'''
#均值
print(np.mean(A)) #7.5
print(A.mean()) #7.5
print(np.average(A)) #7.5 #累加
print(np.cumsum(A))
#[ 2 5 9 14 20 27 35 44 54 65 77 90] #累差
print(np.diff(A))
'''
[[1 1 1]
[1 1 1]
[1 1 1]]
''' print(np.nonzero(A))
#(array([0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2], dtype=int64), array([0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3], dtype=int64)) #转置
print(np.transpose(A))
print(A.T) #clip
print(np.clip(A,5,9))
'''
[[5 5 5 5]
[6 7 8 9]
[9 9 9 9]]
'''
2.5 Numpy 索引
- 与数组类似,二维索引可用print(A[1][1])或者print(A[1,1])
- 可以使用分片操作,例A[1,1:3]
- flatten flat
import numpy as np
A = np.arange(3,15).reshape((3,4)) print(A.flatten())
# array([3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]) for item in A.flat:
print(item) #
#
……
#
flatten是一个展开性质的函数,将多维的矩阵进行展开成1行的数列。而flat是一个迭代器,本身是一个object属性
2.6 Numpy array 合并
nump.vstack() 竖直方向/上下合并
import numpy as np
A = np.array([1,1,1])
B = np.array([2,2,2]) print(np.vstack((A,B))) # vertical stack
"""
[[1,1,1]
[2,2,2]]
"""
水平方向/左右合并
D = np.hstack((A,B)) # horizontal stack print(D)
# [1,1,1,2,2,2]
nump.newaxis()新增一个维度
nump.concatenate():把合并多个矩阵
2.7 Numpy array 分割
axis = 1,表示行(x轴),切割行,分成多列
axis = 0,表示行(y轴),切割列,分成多行
import numpy as np A = np.arange(12).reshape((3,4))
print(A) print(np.split(A,2,axis = 1))
'''
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2, 3],
[ 6, 7],
[10, 11]])]
'''
print(np.split(A,3,axis = 0))
#[array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])] #不等量分割
print(np.array_split(A, 3, axis=1))
'''
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2],
[ 6],
[10]]), array([[ 3],
[ 7],
[11]])]
''' #vsplit与hsplit
print(np.vsplit(A, 3)) #等于 print(np.split(A, 3, axis=0))
# [array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])] print(np.hsplit(A, 2)) #等于 print(np.split(A, 2, axis=1))
"""
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2, 3],
[ 6, 7],
[10, 11]])]
"""
2.8 Numpy copy & deep copy
同Python初学基础
= 的赋值方式会带有关联性 ,copy() 的赋值方式没有关联性
Pandas 学习
3.1 Pandas 基本介绍
如果用 python 的列表和字典来作比较, 那么可以说 Numpy 是列表形式的,没有数值标签,而 Pandas 就是字典形式。Pandas是基于Numpy构建的,让Numpy为中心的应用变得更加简单。
Series
>>> import pandas as pd
>>> s = pd.Series([1,2,3,np.nan,44,1])
>>> print(s)
0 1.0
1 2.0
2 3.0
3 NaN
4 44.0
5 1.0
dtype: float64
Series的字符串表现形式为:索引在左边,值在右边。由于我们没有为数据指定索引。于是会自动创建一个0到N-1(N为长度)的整数型索引。
DataFrame
DataFrame是一个表格型的数据结构,它包含有一组有序的列,每列可以是不同的值类型(数值,字符串,布尔值等)。DataFrame既有行索引也有列索引, 它可以被看做由Series组成的大字典
>>> import pandas as pd
>>> import numpy as np
>>> s = pd.Series([1,2,3,np.nan,44,1])
>>> print(s)
0 1.0
1 2.0
2 3.0
3 NaN
4 44.0
5 1.0
dtype: float64
>>> dates = pd.date_range('',periods=6)
>>> df = pd.DataFrame(np.random.randn(6,4),index = dates,columns=['a','b','c','d'])
>>> df
a b c d
2018-01-01 -0.837319 0.250373 -1.218879 -0.018287
2018-01-02 0.094332 -0.546386 2.248513 -0.944102
2018-01-03 -0.805855 0.550253 0.552966 -1.704637
2018-01-04 -0.272391 0.150142 0.710317 0.397553
2018-01-05 -2.615182 -1.338799 -0.301048 0.732760
2018-01-06 0.281869 0.376154 0.092362 -1.588711
>>>
>>> df1 = pd.DataFrame(np.arange(12).reshape((3,4)))
>>> df1
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11 #还可以用字典的方式生成
>>> df2 = pd.DataFrame({'A' : 1.,
'B' : pd.Timestamp(''),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo'}) >>> print(df2)
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
>>>
DataFrame 的一些简单运用
>>> print(df['b'])
2018-01-01 0.250373
2018-01-02 -0.546386
2018-01-03 0.550253
2018-01-04 0.150142
2018-01-05 -1.338799
2018-01-06 0.376154
Freq: D, Name: b, dtype: float64 >>> #查看数据中的类型
>>> print(df2.dtypes)
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object >>> #查看对应行的序号
>>> print(df2.index)
Int64Index([0, 1, 2, 3], dtype='int64') >>> #查看对应列
>>> print(df2.columns)
Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object') >>> #只查看所有df2的值
>>> print(df2.values)
[[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'foo']
[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'train' 'foo']
[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'foo']
[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'train' 'foo']] >>> #数据总结
>>> df2.describe()
A C D
count 4.0 4.0 4.0
mean 1.0 1.0 3.0
std 0.0 0.0 0.0
min 1.0 1.0 3.0
25% 1.0 1.0 3.0
50% 1.0 1.0 3.0
75% 1.0 1.0 3.0
max 1.0 1.0 3.0 >>> #对数据的index排序
>>> print(df2.sort_index(axis=1,ascending=False))
F E D C B A
0 foo test 3 1.0 2013-01-02 1.0
1 foo train 3 1.0 2013-01-02 1.0
2 foo test 3 1.0 2013-01-02 1.0
3 foo train 3 1.0 2013-01-02 1.0 >>> #对数据值排序
>>> print(df2.sort_values(by='E'))
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
2 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
3 1.0 2013-01-02 1.0 3 train foo
3.2 Pandas 选择数据
简单的筛选
import pandas as pd
import numpy as np dates = pd.date_range('',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D']) print(df) print(df['A']) #或print(df.A)
'''
2013-01-01 0
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
Freq: D, Name: A, dtype: int32
''' #跨越多行或多列
print(df[0:3]) #或print(df['20130102':'20130104']) '''
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
'''
根据标签loc
#select by label:loc
print(df.loc[''])
'''
A 4
B 5
C 6
D 7
Name: 2013-01-02 00:00:00, dtype: int32
''' print(df.loc[:,['A','B']])
''' A B
2013-01-01 0 1
2013-01-02 4 5
2013-01-03 8 9
2013-01-04 12 13
2013-01-05 16 17
2013-01-06 20 21
'''
根据序列iloc
#select by position:iloc
print(df.iloc[3,1])
# print(df.iloc[[1,3,5],1:3])
'''
B C
2013-01-02 5 6
2013-01-04 13 14
2013-01-06 21 22
'''
混合 ix
print(df.ix[:3,['A','C']])
"""
A C
2013-01-01 0 2
2013-01-02 4 6
2013-01-03 8 10
"""
通过判断的筛选
print(df[df.A>8])
"""
A B C D
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
"""
3.3 Pandas 设置值
可根据位置设置loc和iloc
例df.loc[2,2]=1111
df.loc['20130101','B']=2222
根据条件设置
df.B[df.A>4] = 0
"""
A B C D
2013-01-01 0 2222 2 3
2013-01-02 4 5 6 7
2013-01-03 8 0 1111 11
2013-01-04 12 0 14 15
2013-01-05 16 0 18 19
2013-01-06 20 0 22 23
"""
按行或列设置
df['F'] = np.nan
"""
A B C D F
2013-01-01 0 2222 2 3 NaN
2013-01-02 4 5 6 7 NaN
2013-01-03 8 0 1111 11 NaN
2013-01-04 12 0 14 15 NaN
2013-01-05 16 0 18 19 NaN
2013-01-06 20 0 22 23 NaN
"""
或者加上Series序列,但是长度必须对齐
df['E'] = pd.Series([1,2,3,4,5,6], index=pd.date_range('',periods=6))
"""
A B C D F E
2013-01-01 0 2222 2 3 NaN 1
2013-01-02 4 5 6 7 NaN 2
2013-01-03 8 0 1111 11 NaN 3
2013-01-04 12 0 14 15 NaN 4
2013-01-05 16 0 18 19 NaN 5
2013-01-06 20 0 22 23 NaN 6
"""
3.4 Pandas 处理丢失数据
首先创建包含NaN的矩阵
dates = pd.date_range('', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates, columns=['A','B','C','D'])
df.iloc[0,1] = np.nan
df.iloc[1,2] = np.nan
"""
A B C D
2013-01-01 0 NaN 2.0 3
2013-01-02 4 5.0 NaN 7
2013-01-03 8 9.0 10.0 11
2013-01-04 12 13.0 14.0 15
2013-01-05 16 17.0 18.0 19
2013-01-06 20 21.0 22.0 23
"""
dropna:去掉有NaN的行或列
print(df.dropna(axis=0,how='any')) # 'any': 只要存在 NaN 就 drop 掉; 'all': 必须全部是 NaN 才 drop
'''
A B C D
2013-01-03 8 9.0 10.0 11
2013-01-04 12 13.0 14.0 15
2013-01-05 16 17.0 18.0 19
2013-01-06 20 21.0 22.0 23
'''
fillna():将NaN的值用其他值代替
print(df.fillna(value=0))
'''
A B C D
2013-01-01 0 0.0 2.0 3
2013-01-02 4 5.0 0.0 7
2013-01-03 8 9.0 10.0 11
2013-01-04 12 13.0 14.0 15
2013-01-05 16 17.0 18.0 19
2013-01-06 20 21.0 22.0 23
'''
isnull():判断是否有缺失数据NaN,为True表示缺失数据
print(df.isnull())
'''
A B C D
2013-01-01 False True False False
2013-01-02 False False True False
2013-01-03 False False False False
2013-01-04 False False False False
2013-01-05 False False False False
2013-01-06 False False False False
''' print(np.any(df.isnull())==True)
#True
3.5 Pandas 导入导出
pandas可以读取与存取的资料格式有很多种,像csv、excel、json、html与pickle等…, 详细请看官方说明文件
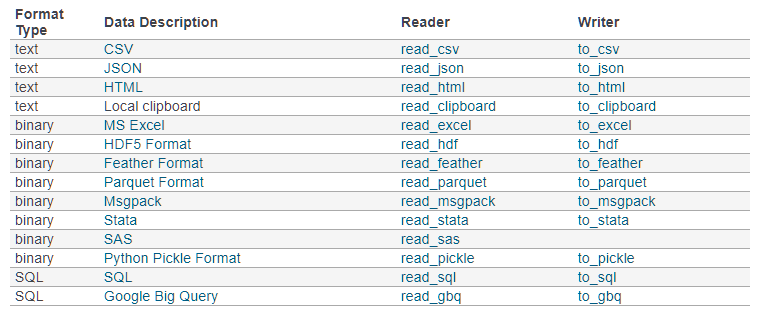
读取csv
示范档案下载 - student.csv
读取csv
#读取csv
data = pd.read_csv('student.csv') #打印出data
print(data)
将资料存取成pickle
data.to_pickle('student.pickle')
3.6 Pandas 合并 concat
使用concat合并
import pandas as pd
import numpy as np #定义资料集
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2, columns=['a','b','c','d']) #concat纵向合并
res = pd.concat([df1, df2, df3], axis=0) #函数默认axis=0。 #打印结果
print(res)
# a b c d
# 0 0.0 0.0 0.0 0.0
# 1 0.0 0.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0
# 0 1.0 1.0 1.0 1.0
# 1 1.0 1.0 1.0 1.0
# 2 1.0 1.0 1.0 1.0
# 0 2.0 2.0 2.0 2.0
# 1 2.0 2.0 2.0 2.0
# 2 2.0 2.0 2.0 2.0
通过设置ignore_index可重置index
res = pd.concat([df1, df2, df3], axis=0, ignore_index=True) #打印结果
print(res)
# a b c d
# 0 0.0 0.0 0.0 0.0
# 1 0.0 0.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0
# 3 1.0 1.0 1.0 1.0
# 4 1.0 1.0 1.0 1.0
# 5 1.0 1.0 1.0 1.0
# 6 2.0 2.0 2.0 2.0
# 7 2.0 2.0 2.0 2.0
# 8 2.0 2.0 2.0 2.0
join合并
默认为outer值,纵向合并,有相同的column上下合并在一起,其他独自的column个自成列,原本没有值的位置皆以NaN填充。
值为inner时,只有相同的column合并在一起,其余舍弃
res = pd.concat([df1, df2], axis=0, join='inner', ignore_index=True)
print(res)
# b c d
# 0 0.0 0.0 0.0
# 1 0.0 0.0 0.0
# 2 0.0 0.0 0.0
# 3 1.0 1.0 1.0
# 4 1.0 1.0 1.0
# 5 1.0 1.0 1.0
join_axes 依照axes合并
res = pd.concat([df1, df2], axis=1, join_axes=[df1.index]) #打印结果
print(res)
# a b c d b c d e
# 1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN
# 2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
# 3 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
append添加数据
只有纵向合并,没有横向合并
3.7 Pandas 合并 merge
pandas中的merge和concat类似,但主要是用于两组有key column的数据,统一索引的数据. 通常也被用在Database的处理当中
3.8 Pandas plot 出图
主要讲了ploy与scatter画散点图的用法,与matlab中的类似
为什么用 Numpy 还是慢, 你用对了吗?
Numpy&Pandas的更多相关文章
- Ipython自动导入Numpy,pandas等模块
一.引言 最近在学习numpy,书上要求安装一个Ipythpn,可以自动导入Numpy,pandas等数据分析的模块,可是当我安装后,并不能自动导入numpy模块,还需要自己import.我就去查了一 ...
- python 数据分析工具之 numpy pandas matplotlib
作为一个网络技术人员,机器学习是一种很有必要学习的技术,在这个数据爆炸的时代更是如此. python做数据分析,最常用以下几个库 numpy pandas matplotlib 一.Numpy库 为了 ...
- 有关python numpy pandas scipy 等 能在YARN集群上 运行PySpark
有关这个问题,似乎这个在某些时候,用python写好,且spark没有响应的算法支持, 能否能在YARN集群上 运行PySpark方式, 将python分析程序提交上去? Spark Applicat ...
- 第一章:AI人工智能 の 数据预处理编程实战 Numpy, Pandas, Matplotlib, Scikit-Learn
本课主题 数据中 Independent 变量和 Dependent 变量 Python 数据预处理的三大神器:Numpy.Pandas.Matplotlib Scikit-Learn 的机器学习实战 ...
- Numpy+Pandas读取数据
1.为什么使用Numpy+Pandas 在使用Numpy读取csv文件时,文件中含有字符串时,会出现ValueError错误 2.Pandas读取csv文件:
- linux下安装numpy,pandas,scipy,matplotlib,scikit-learn
python在数据科学方面需要用到的库: a.Numpy:科学计算库.提供矩阵运算的库. b.Pandas:数据分析处理库 c.scipy:数值计算库.提供数值积分和常微分方程组求解算法.提供了一个非 ...
- Python: NumPy, Pandas学习资料
NumPy 学习资料 书籍 NumPy Cookbook_[Idris2012] NumPy Beginner's Guide,3rd_[Idris2015] Python数据分析基础教程:NumPy ...
- 常用统计分析python包开源学习代码 numpy pandas matplotlib
常用统计分析python包开源学习代码 numpy pandas matplotlib 待办 https://github.com/zmzhouXJTU/Python-Data-Analysis
- Numpy Pandas
数据分析 : 是把隐藏在一些看似杂乱无章的数据背后的信息提炼出来,总结出所研究对象的内在规律. 数据分析三剑客 - Numpy Pandas Matplotlib # Numpy 基于一维或多维的数 ...
随机推荐
- Redis set集合结构及命令详解
set 无序集合 集合的性质: 唯一性,无序性,确定性 注: 在string和link的命令中,可以通过range 来访问string中的某几个字符或某几个元素 但,因为集合的无序性,无法通过下标或范 ...
- 深入解读 Js 中的面向对象编程
前言:今天看了一篇文章觉得很不错,所以给大家分享一下,也许很多人都看过面向对象编程甚至写过这样博客,觉得面向对象编程就那样,没啥好说的,那可能是因为你对这方面知识已经了解,可以选择性跳过.那如果有更通 ...
- supervisor进程管理工具的使用
supervisor是一款进程管理工具,当想让应用随着开机启动,或者在应用崩溃之后自启动的时候,supervisor就派上了用场. 广泛应用于服务器中,用于引导控制程序的启动 安装好superviso ...
- 移动端H5地图矢量SHP网格切分打包方案
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 与离线瓦片方案一样,同样是为了解决移动端网速和流量问题,但是却 ...
- 【Alpha版本】冲刺阶段 - Day2 - 漂流
今日进展 袁逸灏:实现车辆的子弹发射(3.5h) 启动类,子弹类(修改类),游戏画面类(修改类) 刘伟康:继续借鉴其他 alpha 冲刺博客,初步了解墨刀.leangoo等工具(2h) 刘先润:解决了 ...
- 学号:201621123032 《Java程序设计》第12周学习总结
1:本周学习总结 1.1:以你喜欢的方式(思维导图或其他)归纳总结多流与文件相关内容. 2:面向系统综合设计-图书馆管理系统或购物车 2.1: 简述如何使用流与文件改造你的系统.文件中数据的格式如何? ...
- C++中文件的读写
C++中文件的读写 在C++中如何实现文件的读写? 一.ASCII 输出 为了使用下面的方法, 你必须包含头文件<fstream.h>(译者注:在标准C++中,已经使用<fstrea ...
- 第四十三条:返回零长度的数组或者集合,而不是null
如果一个方法的返回值类型是集合或者数组 ,如果在方法内部需要返回的集合或者数组是零长度的,也就是没有实际对象在里面, 我们也应该放回一个零长度的数组或者集合,而不是返回null.如果返回了null,客 ...
- linux 下 nc 命令的使用
netcat被誉为网络安全界的'瑞士军刀',一个简单而有用的工具,透过使用TCP或UDP协议的网络连接去读写数据.它被设计成一个稳定的后门工具,能够直接由其它程序和脚本轻松驱动.同时,它也是一个功能强 ...
- Ubuntu安装使用latex
TeX Live is a TeX distribution to get up and running with the TeX document production system. To ins ...