Hadoop2.0伪分布式平台环境搭建
一、搭建环境的前提条件
环境:ubuntu-16.04
hadoop-2.6.0
jdk1.8.0_161。这里的环境不一定需要和我一样,基本版本差不多都ok的,所需安装包和压缩包自行下载即可。
因为这里是配置Hadoop的教程,配置Java以及安装VMware Tools就自行百度解决哈,这里就不写了(因为教程有点长,可能有些地方有些错误,欢迎留言评论,我会在第一时间修改的)。
二、搭建的详细步骤
1.配置免密码登陆ssh
先判断是否安装ssh,输入命令:ssh localhost,若提示输入密码,即已经安装。如果没有安装,输入命令:sudo apt-get install openssh-server 安装

修改ssh配置文件:
输入命令:vim /etc/ssh/ssh_config 将其中的 Port 22 字段和 PermitLocalCommand no 字段前面的 '#’删除,并且,将 PermitLocalCommand 后面的 no 改为 yes
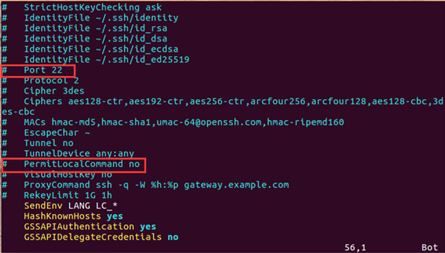
修改过后截图:
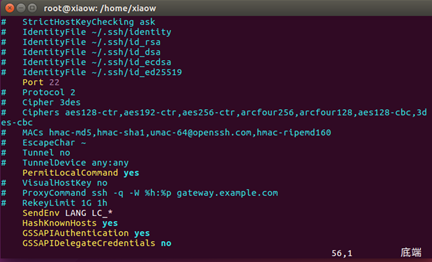
查看在根目录下是否存在.ssh文件夹:
输入命令:cd
ls -a

若没有则在根目录下创建.ssh文件夹,输入命令:mkdir .ssh
产生密钥,输入命令:cd /root/.ssh
ssh-keygen -t rsa
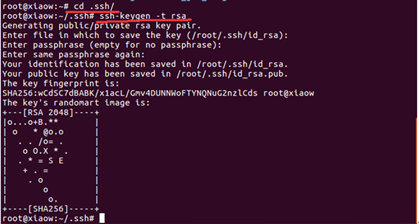
将生成的公钥追加到授权的key中去
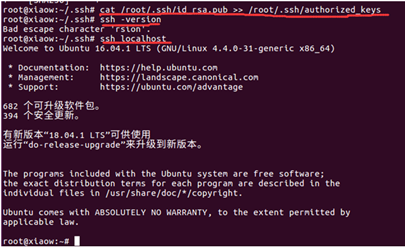
输入命令:cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
验证安装是否成功,输入命令:ssh –version
ssh localhost 提示不需要输入密码则安装成功。
2. 配置Hadoop
将下载好的Hadoop压缩包文件拖进Linux下,为了后续的学习的过程,最好单独创建一个文件夹存放这些文件。我这里使用命令:mkdir /home/xiaow/hadoop2.0创建了一个名为hadoop2.0的文件夹,再将hadoop2.6.0压缩包拖进里面并解压。
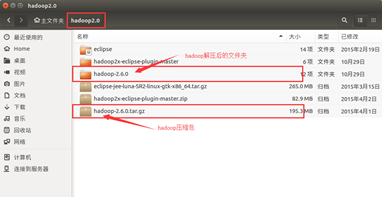
配置环境变量,输入命令:cd /etc
vim profile
在末尾追加:export HADOOP_HOME=/home/xiaow/hadoop2.0/hadoop-2.6.0
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
注意:这里的路径为自己解压后的路径,每个人的路径不相同。

配置完环境变量后,需要系统配置一下环境变量,以便生效。
输入命令:source /etc/profile

3. 修改Hadoop配置文件
需要修改的 hadoop 的配置文件有 5 个,即 core-site.xml、hdfs-site.xml、yarn-site.xml、 slaves、hadoop-env.sh 五个文件。这5个文件的位置为:
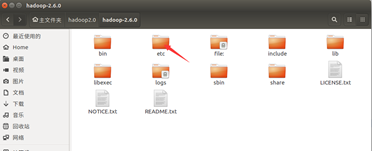
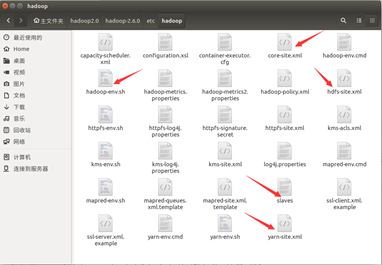
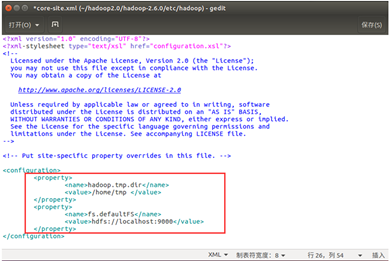
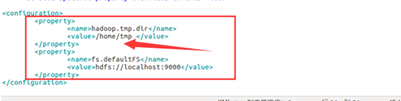
(1). 配置core-site.xml文件
<property>
<name>hadoop.tmp.dir</name>
<value>/home/tmp </value> 设置临时文件夹,只要在 home 下即可 </property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value> 也可以改为本机 IP 地址
</property>
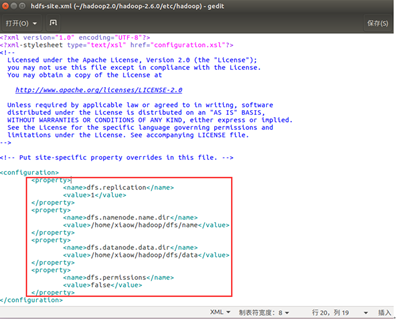
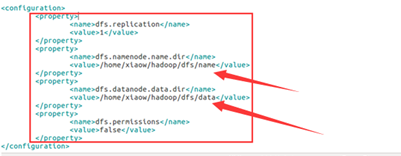
(2). 配置hdfs-site.xml文件
<property>
<name>dfs.replication</name>
<value>1</value> 备份数目,单节点上是 1,多节点一般为 3
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/xiaow/hadoop/dfs/name</value> NameNode 所在路径
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/xiaow/hadoop/dfs/data</value> dataNode 所在路径
</property>
<property>
<name>dfs.permissions</name>
<value>false</value> HDFS 的权限,默认就行
</property>
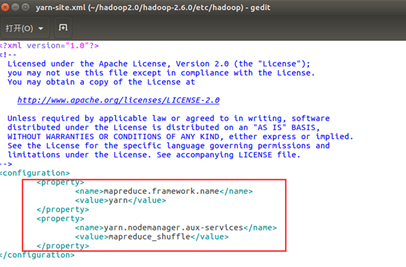
(3). 配置yarn-site.xml文件
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
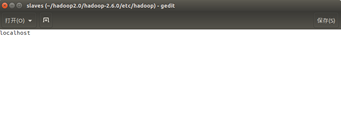
(4). 配置slaves文件
默认就好,不用修改
(5). 配置hadoop-env.sh
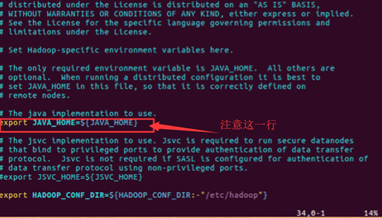
将里面的 JAVA_HOME=${JAVA_HOME}修改为自己安装的jdk地址
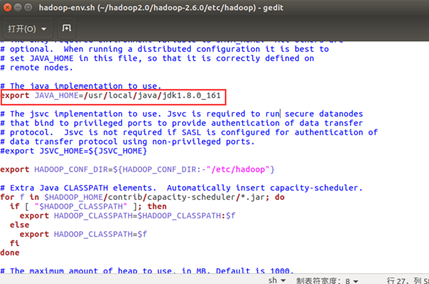
至此hadoop配置文件的修改,已经全部完成。
三、启动Hadoop
输入命令:
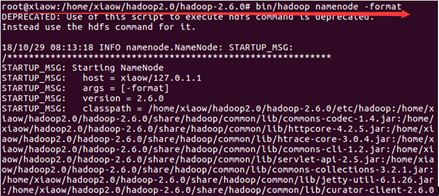
cd /home/xiaow/hadoop2.0/hadoop-2.6.0
bin/hadoop namenode –format
sbin/start-all.sh
jps
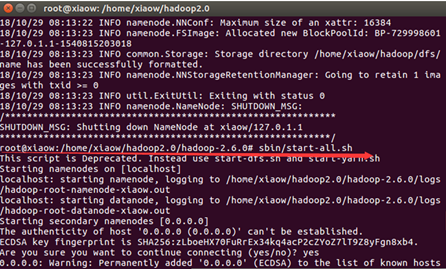
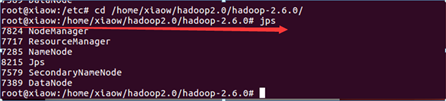
出现如下图所示6个Java进程,则Hadoop伪分布式成功搭建。
四、补充说明
1、如果出现下面这种情况

输入命令:source /etc/profile 即可解决
2、出现进程不够的情况(一般是少一个datanode进程)
应先输入 sbin/stop-all.sh 停止 hadoop所有进程
解决办法可能有以下两种:
1. 再仔细检查刚才配置文件是否出现错误。一般自己检查不出错误,可叫同学帮忙检查一下,必须仔细比对。 再依次使用这三个命令启动Hadoop:

2.可能是临时文件夹没删掉。
找到上图箭头所指示的文件夹并删掉,在重新启动hadoop,如此问题解决。
Hadoop2.0伪分布式平台环境搭建的更多相关文章
- Win7下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper【转】
Win7下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper 1.软件工具箱 在本文的实践中,需要用到以下的软件: Tomcat-7.0.62+solr-5.0.0+ ...
- hadoop2.5.2学习及实践笔记(一)—— 伪分布式学习环境搭建
软件 工具:vmware 10 系统:centOS 6.5 64位 Apache Hadoop: 2.5.2 64位 Jdk: 1.7.0_75 64位 安装规划 /opt/softwares ...
- hadoop_spark伪分布式实验环境搭建和运行实例详细教程
hadoop+spark伪分布式环境搭建 安装须知 单机模式(standalone): 该模式是Hadoop的默认模式.这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统 ...
- windows下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper
原文出自:http://sbp810050504.blog.51cto.com/2799422/1408322 按照该方法,伪分布式solr部署成功 ...
- Hadoop 2.7.0模拟分布式实验环境搭建[亲测]
实验目的: 本实验通过在PC电脑上同时运行3个虚拟机,一个为master节点,两个slave节点. 搭建环境: 主机:mac os 10.10 OS:CenOS 6.5 虚拟机:VMware ...
- hadoop伪分布式平台组件搭建
第一部分:系统基础配置 系统基础配置中主完成了安装大数据环境之前的基础配置,如防火墙配置和安装MySQL.JDK安装等 第一步:关闭防火墙 Hadoop与其他组件的服务需要通过端口进行通信,防火墙的存 ...
- Hadoop伪分布式HDFS环境搭建和使用
1.环境要求 Java版本不低于Hadoop要求,并配置环境变量 2.安装 1)在网站hadoop.apache.org下载稳定版本的Hadoop包 2)解压压缩包 检查Hadoop是否可用 hado ...
- Spark2.4.0伪分布式环境搭建
一.搭建环境的前提条件 环境:ubuntu-16.04 hadoop-2.6.0 jdk1.8.0_161. spark-2.4.0-bin-hadoop2.6.这里的环境不一定需要和我一样,基本版 ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
随机推荐
- 优雅地实现CSS Animation delay
今天写一个css动画时遇到一个有意思的问题,记录如下: 1.需求: 等待元素A的动画加载完,再加载B元素的动画(下图中A为大熊猫,B为下方卡片) 先来看下最后的效果啦: 2.初始思路: 在B元素的动画 ...
- Embedded servlet containers
73. Embedded servlet containers 73.1 Add a Servlet, Filter or Listener to an application There are t ...
- LESS的好处
今日目标: 1:今天的学习内容是在工作完成的情况下,学习Less(之所以学习Less是因为项目中使用的是Less)-------------当前进度(0%) 注意项: 务必确保在 less.js 之前 ...
- Apache启动不了httpd: apr_sockaddr_info_get() failed xgp
httpd: apr_sockaddr_info_get() failed for hoteel httpd: Could not reliably determine the server's fu ...
- 使用wordpress搭建自己的独立博客
最近想要搭建自己的私人博客, 各种百度,完整的搭建步骤如下! 首先得要有自己的vps或者云主机,我这里是自己的云主机,有自己的域名(我这边目前没有买域名)! 搭建步骤! 1,安装lnmp(linux+ ...
- Java 读书笔记 (十七) Java 重写(Override)与重载(Overload)
重写(Override) 重写是子类对父类的允许访问的方法的实现过程重新编写,返回值和形参都不能改变,即外壳不变,核心重写. // 如果重写不是相当于重新定义了一个方法?那为什么不直接写,还要exte ...
- BZOJ_1954_Pku3764 The xor-longest Path_Trie树
Description 给定一棵n个点的带权树,求树上最长的异或和路径 把根到点路径上点权异或和求出来,然后变成了Trie树裸题. 代码: #include <cstdio> #inc ...
- BZOJ_3048_[Usaco2013 Jan]Cow Lineup _双指针
BZOJ_3048_[Usaco2013 Jan]Cow Lineup _双指针 Description Farmer John's N cows (1 <= N <= 100,000) ...
- B20J_3231_[SDOI2014]旅行_树链剖分+线段树
B20J_3231_[SDOI2014]旅行_树链剖分+线段树 题意: S国有N个城市,编号从1到N.城市间用N-1条双向道路连接,城市信仰不同的宗教,为了方便,我们用不同的正整数代表各种宗教. S国 ...
- Ubuntu18.04 Desktop Entry
1.Desktop Entry 是什么? 我们都知道,在Windows里软件在安装的时候都会询问是不是要在开始菜单和桌面创建快捷方式,这样就不用在使用软件的时候去安装目录启动,而是直接去开始菜单点击相 ...