使用Keras对交通标志进行分类
一、概述
本文主要记录的在使用Keras过程中,实现交通标志分类。
文本主要使用的环境为:
Python3.5.2
Tensorflow 1.7
Keras 2.1.4
win10
所有程序均亲测可以通过。文中将使用Keras对图像进行分类处理,处理过程包括了
1.图像的预处理
2.神经网络的训练,得到训练后的模型
3.使用训练后的模型,对图像进行预测。
二、图像预处理
本文获取的交通标志图片,是从德国一家交通标志数据集的站点 上获取图像,因为从网站上获取的图像是PPM格式的,所以使用Opencv将图像从PPM转换为png。具体实现代码如下:
import cv2import os# 训练集路径ORIGINAL_TRAIN_PATH = 'datasets/Train'# 测试集路径ORIGINAL_TEST_PATH = 'datasets/Test'# 处理训练集的图像,将其转换为同名称的PNG格式for train_class in os.listdir(ORIGINAL_TRAIN_PATH):# train_class:当前文件夹的文件夹名称for pic in os.listdir(ORIGINAL_TRAIN_PATH + '/' + train_class):# pic:当前的PPM文件名称if not (pic.split('.')[1] == 'ppm'):continue# 读取图像文件im = cv2.imread(ORIGINAL_TRAIN_PATH + '/' + train_class + '/' + pic)# 获取文件名称name = pic.split('.')[0]# 生成新的文件名称new_name = name + '.png'print(new_name)# 生成图像文件cv2.imwrite('datasets/GTSRB_Final_Training_Images/GTSRB/Final_Training/Images/' + train_class + '/' + new_name, im)# 注释与训练集解析相同for test_class in os.listdir(ORIGINAL_TEST_PATH):for pic in os.listdir(ORIGINAL_TRAIN_PATH + '/' + test_class):if not (pic.split('.')[1] == 'ppm'):continueim = cv2.imread(ORIGINAL_TRAIN_PATH + '/' + test_class + '/' + pic)name = pic.split('.')[0]new_name = name + '.png'print(new_name)cv2.imwrite('datasets/GTSRB_Online-Test-Images-Sorted/GTSRB/Online-Test-sort/' + test_class + '/' + new_name, im)
三、训练神经网络
此过程使用了Keras搭建神经网络,使用的CNN是经典的LeNet,实验相对简单,适用性好。在图像的处理用,对图像分类存储的要求:
- 图像按照一个文件类型一个文件夹的形式存放
- 文件夹使用整数型表示,从0开始
完整的实现的代码如下:
# 导入必要的模块from keras.models import Sequentialfrom keras.layers.convolutional import Conv2Dfrom keras.layers.convolutional import MaxPooling2Dfrom keras.layers.core import Activationfrom keras.layers.core import Flattenfrom keras.layers.core import Densefrom keras import backend as Kimport matplotlibmatplotlib.use("Agg")from keras.preprocessing.image import ImageDataGeneratorfrom keras.optimizers import Adamfrom keras.preprocessing.image import img_to_arrayfrom keras.utils import to_categoricalfrom imutils import pathsimport matplotlib.pyplot as pltimport numpy as npimport argparseimport randomimport cv2import osimport syssys.path.append('..')# matplotlib中,显示中文,置换字体from pylab import*mpl.rcParams['font.sans-serif'] = ['SimHei']# 搭建的神经网络模型(LeNet)class LeNet:@staticmethoddef build(width, height, depth, classes):# 初始化模型model = Sequential()inputShape = (height, width, depth)# 如果使用了 "channels last", 更新输入shapeif K.image_data_format() == "channels_first": # for tensorflowinputShape = (depth, height, width)# 设置第一层 CONV => RELU => POOL 层model.add(Conv2D(20, (5, 5), padding="same", input_shape=inputShape))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))# 设置第二层CONV => RELU => POOL 层model.add(Conv2D(50, (5, 5), padding="same"))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))# 首先 (也是唯一设置) FC => RELU 层model.add(Flatten())model.add(Dense(500))model.add(Activation("relu"))# softmax 分类器model.add(Dense(classes))model.add(Activation("softmax"))# 返回构建好的网络体系结构return model# 基本的参数配置信息:#训练迭代次数EPOCHS = 8#INIT_LR = 1e-3# 一个训练batch中的训练数据个数BS = 64# 分类数(分类个数,此模型是按照文件夹的个数分类的)CLASS_NUM = 43# 图像尺寸的大小(这个需要根据实际情况进行调整,此模型均归一化成正方形)norm_size = 64# 加载数据信息,图像与标签信息(图像与数字标签)def load_data(path):print("[INFO] loading images...")# 图像数据数组即:xdata = []# 标签数据数组即:ylabels = []# 获取图像路径imagePaths = sorted(list(paths.list_images(path)))random.seed(43)# 对图像路径随机分配处理random.shuffle(imagePaths)# 循环输入图像for imagePath in imagePaths:# 加载图像,预处理图像,并将其存储在数据列表中image = cv2.imread(imagePath)image = cv2.resize(image, (norm_size, norm_size))image = img_to_array(image)data.append(image)# 从图像路径中提取类标签并更新标签列表label = int(imagePath.split(os.path.sep)[-2])labels.append(label)# 数据进行归一化处理 将原始像素强度缩放到范围[0,1]data = np.array(data, dtype="float") / 255.0labels = np.array(labels)# 将标签从整数转换为矢量(即每个位置转换为0或1,)# to_categorical(y, num_classes=None)# 将类别向量(从0到nb_classes的整数向量)映射为二值类别矩阵,# 用于应用到以categorical_crossentropy为目标函数的模型中.# y: 类别向量# num_classes:总共类别数labels = to_categorical(labels, num_classes=CLASS_NUM)return data, labels# 训练神经网络def train(aug, trainX, trainY, testX, testY, args):print("[INFO] compiling model...")# 初始化模型model = LeNet.build(width=norm_size, height=norm_size, depth=3, classes=CLASS_NUM)opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)model.compile(loss="categorical_crossentropy", optimizer=opt,metrics=["accuracy"])# 训练神经网络print("[INFO] training network...")H = model.fit_generator(aug.flow(trainX, trainY, batch_size=BS),validation_data=(testX, testY), steps_per_epoch=len(trainX) // BS,epochs=EPOCHS, verbose=1)# 将模型保存至硬盘print("[INFO] serializing network...")model.save(args["model"])# 绘制训练损失和准确性曲线并保存plt.style.use("ggplot")plt.figure()N = EPOCHSplt.plot(np.arange(0, N), H.history["loss"], label="train_loss")plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")plt.plot(np.arange(0, N), H.history["acc"], label="train_acc")plt.plot(np.arange(0, N), H.history["val_acc"], label="val_acc")# 标题 X轴名称 Y轴名称plt.title("图像分类识别")plt.xlabel("迭代步数#")plt.ylabel("误差")plt.legend(loc="lower left")# 保存图像曲线plt.savefig(args["plot"])# 主程序入口if __name__=='__main__':args = {}# 存储模型的地址args['model'] = 'MODE/traffic_sign.model'# 输出训练曲线的地址args['plot'] = 'MODE/plot.png'# 训练图像集合文件夹路径args['dataset_train'] = "datasets/GTSRB_Final_Training_Images/GTSRB/Final_Training/Images"# 测试图像集合文件夹路径args['dataset_test'] = "datasets/GTSRB_Online-Test-Images-Sorted/GTSRB/Online-Test-sort"train_file_path = args['dataset_train']test_file_path = args['dataset_test']# 加载训练集合的输入端数据与输出端数据trainX,trainY = load_data(train_file_path)# 加载测试集合的输入端数据与输出端数据testX,testY = load_data(test_file_path)# 构建用于数据增强的图像生成器aug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1,height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,horizontal_flip=True, fill_mode="nearest")# 开始训练train(aug,trainX,trainY,testX,testY,args)
四、图像预测
预测图像时,程序执行的步骤如下:
- 加载训练好的模型
- 对输入图像进行必要的前处理,如修改尺寸,序列化;
- 将序列化的图像输入模型中
- 得到序列结果,找到最大概率与对应位置
测过程即为输入图像,得到它是哪种分类的可能性最大以及对应的概率。
具体实现代码如下:
# 加载工程中必要的库from keras.preprocessing.image import img_to_arrayfrom keras.models import load_modelimport numpy as npimport argparseimport imutilsimport cv2# 根据使用的模型,确定图像需要resize的尺寸norm_size = 64# 预测函数,# 输入: 包含配置参数的字典def predict(args):# 加载训练好的卷积神经网络print("[INFO] loading network...")model = load_model(args["model"])# 加载图像image = cv2.imread(args["image"])# 因为对图像需要进行写入标签,影响较大所以复制一个图像orig = image.copy()# 预处理图像进行分类# 图像的尺寸重载image = cv2.resize(image, (norm_size, norm_size))# 图像的序列的归一化处理image = image.astype("float") / 255.0# 将图像进行序列化image = img_to_array(image)# 展开数组的形状.# 插入一个新的轴,该轴将出现在扩展阵列形状的轴位置image = np.expand_dims(image, axis=0)# 对输入的图像进行分类result = model.predict(image)[0]# print (result.shape)proba = np.max(result)label = str(np.where(result == proba)[0])label = "{}: {:.2f}%".format(label, proba * 100)print(label)# 在需要加载图像的情况下if args['show']:output = imutils.resize(orig, width=400)# 在图像上绘制标签字符串cv2.putText(output, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,0.7, (0, 255, 0), 2)# 显示带标签的图像cv2.imshow("Output", output)cv2.waitKey(0)# python predict.py --model traffic_sign.model -i ../2.png -sif __name__ == '__main__':args = {}# 模型的输入路径args['model'] = 'MODE/traffic_sign2.model'# 图像的输入路径args['image'] = 'predict/00000_00005.png'args['show'] = 'true'# 执行预测predict(args)
训练的图像如下图:
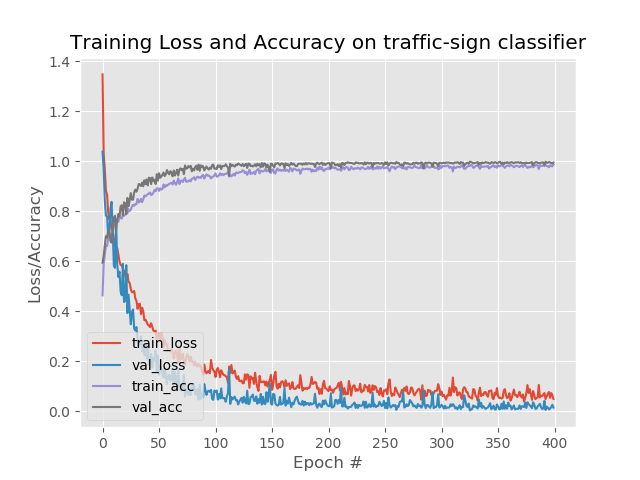
使用Keras对交通标志进行分类的更多相关文章
- 人工智能深度学习框架MXNet实战:深度神经网络的交通标志识别训练
人工智能深度学习框架MXNet实战:深度神经网络的交通标志识别训练 MXNet 是一个轻量级.可移植.灵活的分布式深度学习框架,2017 年 1 月 23 日,该项目进入 Apache 基金会,成为 ...
- TSR交通标志检测与识别
TSR交通标志检测与识别 说明: 传统图像处理算法的TSR集成在在ARM+DSP上运行,深度学习开发的TSR集成到FPGA上运行. 输入输出接口 Input: (1)图像视频分辨率(整型int) (2 ...
- AI在汽车中的应用:实用深度学习
https://mp.weixin.qq.com/s/NIza8E5clC18eMF_4GMwDw 深度学习的“深度”层面源于输入层和输出层之间实现的隐含层数目,隐含层利用数学方法处理(筛选/卷积)各 ...
- 【Keras】从两个实际任务掌握图像分类
我们一般用深度学习做图片分类的入门教材都是MNIST或者CIFAR-10,因为数据都是别人准备好的,有的甚至是一个函数就把所有数据都load进来了,所以跑起来都很简单,但是跑完了,好像自己还没掌握图片 ...
- 深度学习应用系列(二) | 如何使用keras进行迁移学习,以训练和识别自己的图片集
本文的keras后台为tensorflow,介绍如何利用预编译的模型进行迁移学习,以训练和识别自己的图片集. 官网 https://keras.io/applications/ 已经介绍了各个基于Im ...
- TB3_Autorace之交通杆检测
利用blob检测算法识别交通杆,控制TB3机器人完成对交通杆的起停动作! 上一篇博文中<TB3_Autorace之路标检测>订阅了原始图像信息,经过SIFT检测识别出道路交通标志,这里我们 ...
- GAN︱生成模型学习笔记(运行机制、NLP结合难点、应用案例、相关Paper)
我对GAN"生成对抗网络"(Generative Adversarial Networks)的看法: 前几天在公开课听了新加坡国立大学[机器学习与视觉实验室]负责人冯佳时博士在[硬 ...
- 预测学习、深度生成式模型、DcGAN、应用案例、相关paper
我对GAN"生成对抗网络"(Generative Adversarial Networks)的看法: 前几天在公开课听了新加坡国立大学[机器学习与视觉实验室]负责人冯佳时博士在[硬 ...
- TensorFlow和最近发布的slim
笔者将和大家分享一个结合了TensorFlow和最近发布的slim库的小应用,来实现图像分类.图像标注以及图像分割的任务,围绕着slim展开,包括其理论知识和应用场景. 之前自己尝试过许多其它的库,比 ...
随机推荐
- java多线程的(一)-之java线程的使用
一.摘要 每天都和电脑打交道,也相信大家使用过资源管理器杀掉过进程.而windows本身就是多进程的操作系统 在这里我们理解两组基本概念: 1.进程和线程的区别???? 2.并行与并发的区别???? ...
- C语言博客作业—数组
一.PTA实验作业 题目1:简化的插入排序 1. 本题PTA提交列表 2. 设计思路 (1)定义n,number,i,j,temp; (2)输入n; (3)定义数组a[n+1]; //把所有的数都放入 ...
- 2017-2018-1 Java演绎法 第三周 作业
团队任务:团队展示与选题 团队展示 队员学号及姓名 学号 姓名 主要负责工作 20162315 马军 日常统计,项目部分代码 20162316 刘诚昊 项目部分代码,代码质量测试 20162317 袁 ...
- alpha-咸鱼冲刺day4
一,合照 emmmmm.自然还是没有的. 二,项目燃尽图 三,项目进展 QAQ具体工作量没啥进展.但是前后端终于可以数据交互了!.. 四,问题困难 日常啥都不会,百度真心玩一年. 还得自学nodejs ...
- Archlinux下i3wm与urxvt的配置
前段时间学习了GitHub的两位前辈:Airblader和wlh320.他们的相关教程在https://github.com/Airblader/i3和https://github.com/wlh32 ...
- 20145237 《Java程序设计》第七周学习总结
20145237 <Java程序设计>第七周学习总结 教材学习内容总结 第十三章 一.认识时间与日期 1.时间的度量 在正式认识Java提供了哪些时间处理API之前,得先来了解 ...
- 如何使用ILAsm与ILDasm修改.Net exe(dll)文件
一.背景 最近项目组新上项目,交付的时间比较急迫,原本好的分支管理习惯没有遵守好,于是出现下面状况: 多个小伙伴在不同的分支上开发. 原本QA环境也存在一个阻碍性的bug A 一位同事在QA环境发布了 ...
- vue下拉列表
最近在弄作品,做了个下拉列表.心想各位小哥哥.小姐姐可能会用到相同的需求,就把下拉列表封装一下,希望能对各位小哥哥,小姐姐有帮助 github地址:https://github.com/ClmPisc ...
- 新概念英语(1-63)Thank you, doctor.
新概念英语(1-63)Thank you, doctor. Who else is in bed today? why? A:How's Jimmy today? B:Better. Thank yo ...
- 证明二叉查找树所有节点的平均深度为O(logN)
数据结构与算法分析(c语言描述)第4章 P78 概念一:一棵树所有节点的深度和称为内部路径长 令D(N)为一棵有N节点的树的内部路径长么,即有D(1)=0, 设一棵树的左子树的内部路径长为D(i),则 ...