“你什么意思”之基于RNN的语义槽填充(Pytorch实现)
1. 概况
1.1 任务
口语理解(Spoken Language Understanding, SLU)作为语音识别与自然语言处理之间的一个新兴领域,其目的是为了让计算机从用户的讲话中理解他们的意图。SLU是口语对话系统(Spoken Dialog Systems)的一个非常关键的环节。下图展示了口语对话系统的主要流程。
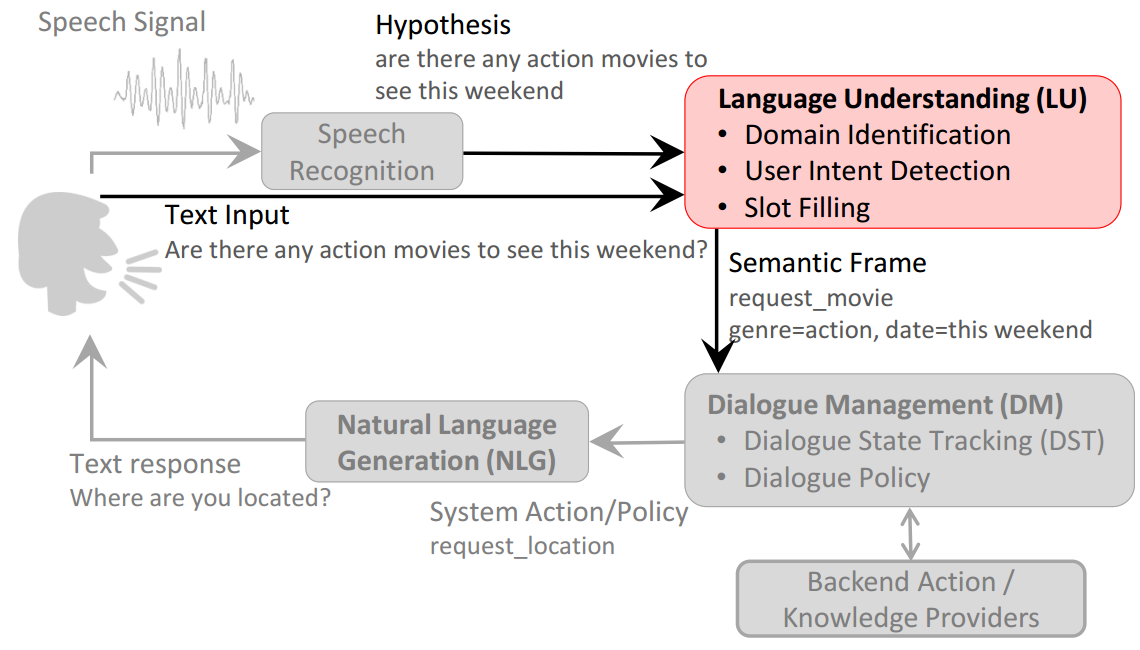
SLU主要通过如下三个子任务来理解用户的语言:
- 领域识别(Domain Detection)
- 用户意图检测(User Intent Determination)
- 语义槽填充(Semantic Slot Filling)
例如,用户输入“播放周杰伦的稻香”,首先通过领域识别模块识别为"music"领域,再通过用户意图检测模块识别出用户意图为"play_music"(而不是"find_lyrics" ),最后通过槽填充对将每个词填充到对应的槽中:"播放[O] / 周杰伦[B-singer] / 的[O] / 稻香[B-song]"。
从上述例子可以看出,通常把领域识别和用户意图检测当做文本分类问题,而把槽填充当做序列标注(Sequence Tagging)问题,也就是把连续序列中每个词赋予相应的语义类别标签。本次实验的任务就是基于ATIS 数据集进行语义槽填充。(完整代码地址:https://github.com/llhthinker/slot-filling)
1.2 数据集
本次实验基于ATIS(Airline Travel Information Systems )数据集。顾名思义,ATIS数据集的领域为"Airline Travel"。ATIS数据集采取流行的"in/out/begin(IOB)标注法": "I-xxx"表示该词属于槽xxx,但不是槽xxx中第一个词;"O"表示该词不属于任何语义槽;"B-xxx"表示该词属于槽xxx,并且位于槽xxx的首位。部分ATIS训练数据集如下:
what O
is O
the O
arrival B-flight_time
time I-flight_time
in O
san B-fromloc.city_name
francisco I-fromloc.city_name
for O
the O
DIGITDIGITDIGIT B-depart_time.time
am I-depart_time.time
flight O
leaving O
washington B-fromloc.city_name
ATIS数据集一共有83种语义槽,因此序列标注的标签类别一共有\(83+83+1=167\)个。ATIS数据集分为训练集和测试集,数据规模如下表:
| 训练集 | 测试集 | |
|---|---|---|
| 句子总数 | 4978个 | 893个 |
| 词语总数 | 56590个 | 9198个 |
| 句子平均词数 | 11.4个 | 10.3个 |
2. 模型
上文中提到,通常把槽填充当做序列标注问题。很多机器学习算法都能够解决序列标注问题,包括HMM/CFG,hidden vector state(HVS)等生成式模型,以及CRF, SVM等判别式模型。本次实验主要参考论文《Using Recurrent Neural Networks for Slot Filling in Spoken Language Understanding 》 ,基于RNN来实现语义槽填充。
RNN可以分为简单RNN(Simple RNN)和门控机制RNN(Gated RNN),前者的RNN单元完全接收上个时刻的输入;后者基于门控机制,通过学习到的参数自行决定上个时刻的输入量和当前状态的保留量。下面将介绍Elman-RNN, Jordan-RNN, Hybrid-RNN(Elman和Jordan结合)这三种简单RNN,以及经典的门控机制RNN:LSTM。
2.1 Elman-RNN
Elman-RNN将当前时刻的输入\(x_t\)和上个时刻的隐状态输出\(h_{(t-1)}\)作为输入,具体如下:
\]
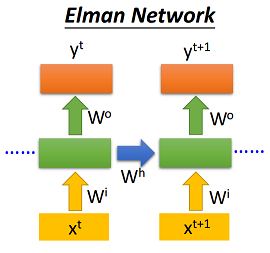
需要说明的是,Pytorch默认的RNN即为Elman-RNN,但是它只支持\(\tanh\)和ReLU两种激活函数。本次实验按照论文设置,激活函数均采取sigmoid函数,使用Pytorch具体实现如下:
class ElmanRNNCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(ElmanRNNCell, self).__init__()
self.hidden_size = hidden_size
self.i2h_fc1 = nn.Linear(input_size, hidden_size)
self.i2h_fc2 = nn.Linear(hidden_size, hidden_size)
self.h2o_fc = nn.Linear(hidden_size, hidden_size)
def forward(self, input, hidden):
hidden = F.sigmoid(self.i2h_fc1(input) + self.i2h_fc2(hidden))
output = F.sigmoid(self.h2o_fc(hidden))
return output, hidden
2.2 Jordan-RNN
Jordan-RNN将当前时刻的输入\(x_t\)和上个时刻的输出层输出\(y_{(t-1)}\)作为输入,具体如下:
\]
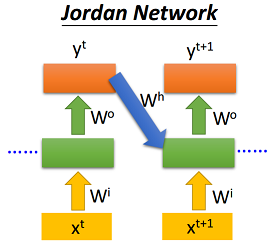
使用Pytorch具体实现如下,其中\(y_0\)初始化为可训练的参数:
class JordanRNNCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(JordanRNNCell, self).__init__()
self.hidden_size = hidden_size
self.i2h_fc1 = nn.Linear(input_size, hidden_size)
self.i2h_fc2 = nn.Linear(hidden_size, hidden_size)
self.h2o_fc = nn.Linear(hidden_size, hidden_size)
self.y_0 = nn.Parameter(nn.init.xavier_uniform(torch.Tensor(1, hidden_size)), requires_grad=True)
def forward(self, input, hidden=None):
if hidden is None:
hidden = self.y_0
hidden = F.sigmoid(self.i2h_fc1(input) + self.i2h_fc2(hidden))
output = F.sigmoid(self.h2o_fc(hidden))
return output, output
2.4 Hybrid-RNN
Hybrid-RNN将当前时刻的输入\(x_t\),上个时刻的隐状态\(h_{(t-1)}\) 以及上个时刻输出层输出\(y_{(t-1)}\)作为输入,具体如下:
```python
class HybridRNNCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(HybridRNNCell, self).__init__()
self.hidden_size = hidden_size
self.i2h_fc1 = nn.Linear(input_size, hidden_size)
self.i2h_fc2 = nn.Linear(hidden_size, hidden_size)
self.i2h_fc3 = nn.Linear(hidden_size, hidden_size)
self.h2o_fc = nn.Linear(hidden_size, hidden_size)
self.y_0 = nn.Parameter(nn.init.xavier_uniform(torch.Tensor(1, hidden_size)), requires_grad=True)
def forward(self, input, hidden, output=None):
if output is None:
output = self.y_0
hidden = F.sigmoid(self.i2h_fc1(input)+self.i2h_fc2(hidden)+self.i2h_fc3(output))
output = F.sigmoid(self.h2o_fc(hidden))
return output, hidden
```
## 2.5 LSTM
LSTM引入了**记忆单元**$c_t$和3种控制门,包括**输入门**(input gate)$i_t$,**遗忘门**(forget gate)$f_t$,**输出门**(output gate)$o_t$, 首先,输入层接受当前时刻输入$x_t$和上个时刻隐状态输出$h_{(t-1)}$,通过$\tanh$激活函数得到记忆单元的输入$g_t$; 然后遗忘门$f_t$决定上个时刻记忆单元$c_{(t-1)}$的保留比例,输入门$i_t$决定当前时刻记忆单元的输入$g_t$的保留比例,两者相加得到当前的记忆单元$c_t$; 最后记忆单元$c_t$通过$\tanh$激活函数得到的值在输出门$o_t$的控制下得到最终的当前时刻隐状态$h_t$, 具体如下:
$$\begin{split}\begin{array}{ll}i_t = \sigma(W_{ii} x_t + b_{ii} + W_{hi} h_{(t-1)} + b_{hi}) \\f_t = \sigma(W_{if} x_t + b_{if} + W_{hf} h_{(t-1)} + b_{hf}) \\g_t = \tanh(W_{ig} x_t + b_{ig} + W_{hg} h_{(t-1)} + b_{hg}) \\o_t = \sigma(W_{io} x_t + b_{io} + W_{ho} h_{(t-1)} + b_{ho}) \\c_t = f_t c_{(t-1)} + i_t g_t \\h_t = o_t \tanh(c_t)\end{array}\end{split}\]
Pytorch已经实现了LSTM, 只需要调用相应的API即可,调用的代码片段如下:
self.rnn = nn.LSTM(input_size=embedding_dim,
hidden_size=hidden_size,
bidirectional=bidirectional,
batch_first=True)
3. 实验
3.1 实验设置
实验基于Python 3.6 和Pytorch 0.4.0,为进行对照实验,下列设置针对所有RNN模型:
- 所有RNN模型均只使用单层;
- 词向量维度设置为100维,并且随机初始化,在训练过程中进行调整;
- 隐状态维度设置为75维;
- 采用带动量的随机梯度下降(SGD),batch size为1,学习率(learning rate)为0.1,动量(momentum)为0.9并保持不变;
- epoch=10;
- 每种RNN模型都实现单向(Single)和双向(Bi-Directional),并分别训练。
3.2 实验结果
在使用CPU的情况下,不同模型在测试集的\(F_1\)得分以及平均一个epoch训练时长的结果如下:
| \(F_1(\%) / T(s)\) | Elman | Jordan | Hybrid | LSTM |
|---|---|---|---|---|
| Single | 87.26 / 438 | 87.90 / 487 | 88.46 / 494 | 92.16 / 3721 |
| Bi-Directional | 92.88 / 565 | 90.31 / 580 | 91.85 / 613 | 93.75 / 4357 |
从上表中可以看出:
- 基于门控机制的LSTM由于其参数和运算步骤的增加,一个epoch的训练时长是另外三种Simple RNN的9倍左右,而\(F_1\)得分也比Simple RNN高;
- 双向(Bi-Directional)RNN的\(F_1\)得分普遍比单向(Single)RNN高,而运行时间也多一些。
在使用同一块GPU的情况下,不同模型在测试集的\(F_1\)得分以及平均一个epoch训练时长的结果如下:
| \(F_1(\%) / T(s)\) | Elman | Jordan | Hybrid | LSTM |
|---|---|---|---|---|
| Single | 88.89 / 35.2 | 88.36 / 41.3 | 89.65 / 43.5 | 92.44 / 16.8 |
| Bi-Directional | 91.78 / 68.0 | 89.82 / 72.2 | 93.61 / 81.6 | 94.26 / 18.7 |
从上表中可以看出,即使是随机梯度下降(batch_size=1),GPU的加速效果仍然相当明显。值得指出的是,虽然LSTM的运算步骤比其他三种Simple-RNN多,但是用时却是最少的,这可能是由于LSTM是直接调用Pytorch的API,针对GPU有优化,而另外三种的都是自己实现的,GPU加速效果没有Pytorch好。
4. 总结与展望
总的来说,将槽填充问题当做序列标注问题是一种有效的做法,而RNN能够较好的对序列进行建模,提取相关的上下文特征。双向RNN的表现优于单向RNN,而LSTM的表现优于Simple RNN。对于Simple RNN而言,Elman的表现不比Jordan差(甚至更好),而用时更少并且实现更简单,这可能是主流深度学习框架(TensorFlow / Pytorch等)的simple RNN是基于Elman的原因。而Hybrid作为Elman和Jordan的混合体,其训练时间都多余Elman和Jordan,\(F_1\)得分略有提升,但不是特别明显(使用CPU时的双向Elman表现比双向Hybrid好),需要更多实验进行验证。
从实验设置可以看出,本次实验没有过多的调参。如果想取得更好的结果,可以进行更细致的调参,包括 :
- 改变词向量维度和隐状态维度;
- 考虑采用预训练词向量,然后固定或者进行微调;
- 采用正则化技术,包括L1/L2, Dropout, Batch Normalization, Layer Normalization等;
- 尝试使用不同的优化器(如Adam),使用mini-batch,调整学习率;
- 增加epoch次数。
此外,可以考虑在输入时融入词性标注和命名实体识别等信息,在输出时使用Viterbi算法进行解码,也可以尝试不同形式的门控RNN(如GRU,LSTM变体等)以及采用多层RNN,并考虑是否使用残差连接等。
参考资料
Mesnil G, Dauphin Y, Yao K, et al. Using recurrent neural networks for slot filling in spoken language understanding[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(3): 530-539.
Wikipedia. Recurrent neural network. https://en.wikipedia.org/wiki/Recurrent_neural_network
PyTorch documentation. Recurrent layers. http://pytorch.org/docs/stable/nn.html#recurrent-layers
Hung-yi Lee. Machine Learning (2017,Spring). http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2017/Lecture/RNN.pdf
YUN-NUNG (VIVIAN) CHEN. Spring 105 - Intelligent Conversational Bot. https://www.csie.ntu.edu.tw/~yvchen/s105-icb/doc/170321_LU.pdf
“你什么意思”之基于RNN的语义槽填充(Pytorch实现)的更多相关文章
- 基于PaddlePaddle的语义匹配模型DAM,让聊天机器人实现完美回复 |
来源商业新知网,原标题:让聊天机器人完美回复 | 基于PaddlePaddle的语义匹配模型DAM 语义匹配 语义匹配是NLP的一项重要应用.无论是问答系统.对话系统还是智能客服,都可以认为是问题和回 ...
- 基于RNN的音频降噪算法 (附完整C代码)
前几天无意间看到一个项目rnnoise. 项目地址: https://github.com/xiph/rnnoise 基于RNN的音频降噪算法. 采用的是 GRU/LSTM 模型. 阅读下训练代码,可 ...
- TensorFlow练习7: 基于RNN生成古诗词
http://blog.topspeedsnail.com/archives/10542 主题 TensorFlow RNN不像传统的神经网络-它们的输出输出是固定的,而RNN允许我们输入输出向量 ...
- 深度学习实战篇-基于RNN的中文分词探索
深度学习实战篇-基于RNN的中文分词探索 近年来,深度学习在人工智能的多个领域取得了显著成绩.微软使用的152层深度神经网络在ImageNet的比赛上斩获多项第一,同时在图像识别中超过了人类的识别水平 ...
- 提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件
提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件 11月5日,在『WAVE Summit+』2019 深度学习开发者秋季峰会上,百度对外发布基于 ERNIE 的语义理解 ...
- 基于olami开放语义平台的微信小程序遥知之源码实现
概述 实现一个智能生活信息查询的小秘书功能,支持查天气.新闻.日历.汇率.笑话.故事.百科.诗词.邮编.区号.菜谱.股票.节目预告,还支持闲聊.算24点.数学计算.单位换算.购物.搜索等功能. 使用方 ...
- 用CNTK搞深度学习 (二) 训练基于RNN的自然语言模型 ( language model )
前一篇文章 用 CNTK 搞深度学习 (一) 入门 介绍了用CNTK构建简单前向神经网络的例子.现在假设读者已经懂得了使用CNTK的基本方法.现在我们做一个稍微复杂一点,也是自然语言挖掘中很火 ...
- 基于卷积神经网络的面部表情识别(Pytorch实现)----台大李宏毅机器学习作业3(HW3)
一.项目说明 给定数据集train.csv,要求使用卷积神经网络CNN,根据每个样本的面部图片判断出其表情.在本项目中,表情共分7类,分别为:(0)生气,(1)厌恶,(2)恐惧,(3)高兴,(4)难过 ...
- 基于jq的表单填充
//表单填充 formDataLoad: function (domId, obj) { for (var property in obj) { if (obj.hasOwnProperty(prop ...
随机推荐
- nginx和nfs
1.安装nginx #yum install epel-release -y #yum install nginx -y #vim /usr/local/nginx/conf/nginx.conf - ...
- Django多级评论
一.原理 #多级评论原理简单原理,弄完之后发现基础白学了 msg_list = [ {'id':1,'content':'xxx','parent_id':None}, {'id':2,'conten ...
- Hive函数:GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
参考:lxw大数据田地:http://lxw1234.com/archives/2015/04/193.htm 数据准备: CREATE EXTERNAL TABLE test_data ( mont ...
- 'NoneType' object is not iterable
"TypeError: 'NoneType' object is not iterable" 一般是返回值为None同时赋值给了多个变量
- Mac安装opencv指南
最近接到了新的调研任务.主要是和人脸,各种所谓'AI'相关的.因为这里要处理视频和图像.于是在网上看到很多资料都是关于opencv的所以准备用opencv来开发这些东西.既然要用到opencv.那 ...
- 直接插入排序算法:ArrayList实现和数组实现
直接插入排序算法思想: 排序区间R[1..n]: 在排序的过程中,整个排序区间被分为两个子区间: 有序区R[ 1 ... i-1 ]和无序区R[ i ... n ]: 共进行n-1趟排序,每趟排序都是 ...
- Centos常用命令之:搜索
在linux中,所有的文件都是以目录树的形式存在的.而每个发行版的文件存放之间又会有些差别. 这时候,如果我们想看某个命令或者文档的时候就必须先通过某种方式找到改文档的所在位置. 在linux中提供了 ...
- [AHOI2006]基因匹配
题目描述 卡卡昨天晚上做梦梦见他和可可来到了另外一个星球,这个星球上生物的DNA序列由无数种碱基排列而成(地球上只有4种),而更奇怪的是,组成DNA序列的每一种碱基在该序列中正好出现5次!这样如果一个 ...
- ●BZOJ 1444 [Jsoi2009]有趣的游戏
题链: http://www.lydsy.com/JudgeOnline/problem.php?id=1444题解.1: 概率dp,矩阵乘法,快速幂. 对所有串建立AC自动机, 那么如果在trie树 ...
- reserve的使用
reserve: 强迫容器将它的容量变成n 可以避免不必要的重新分配 如果n大于当前容量,那么正常. 如果n小于当前容量,vector会忽略,string则是减小为 max(size(),n). 如果 ...