Scrapy 框架流程详解
框架流程图
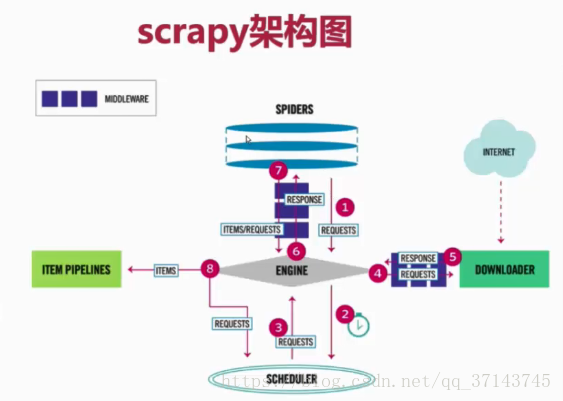
Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向):

简单叙述一下每层图的含义吧:
- Spiders(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
- Engine(引擎):框架核心,负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等
- Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理队列,当引擎需要时,交还给引擎
- Downloader(下载器):负责下载Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Engine(引擎),由引擎交给Spider来处理
- ItemPipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方
- Downloader Middlewares(下载中间件):介于Scrapy引擎和下载器之间的中间件,主要是处理Scrapy引擎与下载器之间的请求及响应
- Spider Middlewares(Spider中间件):介于Scrapy引擎和爬虫之间的中间件,主要工作是处理蜘蛛的响应输入和请求输出
- Scheduler Middlewares(调度中间件):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
执行过程描述
Scrapy执行流程图:
用scrapy框架的时候,一定要先明白执行的顺序,代码已写好,程序开始运行~
- SPIDERS的yeild将request发送给ENGIN
- ENGINE对request不做任何处理发送给SCHEDULER
- SCHEDULER( url调度器),生成request交给ENGIN
- ENGINE拿到request,通过MIDDLEWARE进行层层过滤发送给DOWNLOADER
- DOWNLOADER在网上获取到response数据之后,又经过MIDDLEWARE进行层层过滤发送给ENGIN
- ENGINE获取到response数据之后,返回给SPIDERS,SPIDERS的parse()方法对获取到的response数据进行处理,解析出items或者requests
- 将解析出来的items或者requests发送给ENGIN
- ENGIN获取到items或者requests,将items发送给ITEMPIPELINES,将requests发送给SCHEDULER
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
过程描述:
1.引擎:Hi!Spider, 你要处理哪一个网站?
2.Spider:老大要我处理xxxx.com(初始URL)。
3.引擎:你把第一个需要处理的URL给我吧。
4.Spider:给你,第一个URL是xxxxxxx.com。
5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6.调度器:好的,正在处理你等一下。
7.引擎:Hi!调度器,把你处理好的request请求给我。
8.调度器:给你,这是我处理好的request
9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。
10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14.管道、调度器:好的,现在就做!
一些重要的命令
创建项目:scrapy startproject proname
进入项目:cd proname
创建爬虫:scrapy genspider spiname(爬虫名) xxx.com (爬取域)
创建规则爬虫:scrapy genspider -t crawl spiname(爬虫名) xxx.com (爬取域)
运行爬虫:scrapy crawl spiname -o file.json

开发Scrapy爬虫的步骤
- 创建项目:scrapy startproject proname(项目名字,不区分大小写)
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
- 添加启动程序文件(start.py):等同于此命令(scrapy crawl xxx -o xxx.json),from scrapy import cmdline cmdline.execute("scrapy crawl 项目名".split())
parse()方法的工作机制
- 因为使用的yield,而不是return。parse函数将会被当做一个生成器使用。scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型;
- 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他类型则返回错误信息;
- scrapy取到第一部分的request不会立马就去发送这个request,只是把这个request放到队列里,然后接着从生成器里获取;
- 取尽第一部分的request,然后再获取第二部分的item,取到item了,就会放到对应的pipeline里处理;
- parse()方法作为回调函数(callback)赋值给了Request,指定parse()方法来处理这些请求 scrapy.Request(url, callback=self.parse);
- Request对象经过调度,执行生成 scrapy.http.response()的响应对象,并送回给parse()方法,直到调度器中没有Request(递归的思路);
- 取尽之后,parse()工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作;
- 程序在取得各个页面的items前,会先处理完之前所有的request队列里的请求,然后再提取items;
- 这一切的一切,Scrapy引擎和调度器将负责到底。
至此。转载请注明出处。

Scrapy 框架流程详解的更多相关文章
- Scrapy框架-scrapy框架架构详解
1.Scrapy框架介绍 写一个爬虫,需要做很多的事情.比如:发送网络请求.数据解析.数据存储.反反爬虫机制(更换ip代理.设置请求头等).异步请求等.这些工作如果每次都要自己从零开始写的话,比较浪费 ...
- SSH框架流程详解
解图: 由图可见,有三个框架{ ①. Struts_2 ②. Spring ③. Hibernate } 框架 作用 本质 同等于 Struts_2 实现MVC / 控制.跳转 过滤器(Filter) ...
- Django Rest框架 流程详解
什么是Restful REST与技术无关,代表的是一种软件架构风格,REST是Representational State Transfer的简称,中文翻译为“表征状态转移” REST从资源的角度类审 ...
- Scrapy笔记03- Spider详解
Scrapy笔记03- Spider详解 Spider是爬虫框架的核心,爬取流程如下: 先初始化请求URL列表,并指定下载后处理response的回调函数.初次请求URL通过start_urls指定, ...
- 测试框架mochajs详解
测试框架mochajs详解 章节目录 关于单元测试的想法 mocha单元测试框架简介 安装mocha 一个简单的例子 mocha支持的断言模块 同步代码测试 异步代码测试 promise代码测试 不建 ...
- 【python3+request】python3+requests接口自动化测试框架实例详解教程
转自:https://my.oschina.net/u/3041656/blog/820023 [python3+request]python3+requests接口自动化测试框架实例详解教程 前段时 ...
- Lucene系列六:Lucene搜索详解(Lucene搜索流程详解、搜索核心API详解、基本查询详解、QueryParser详解)
一.搜索流程详解 1. 先看一下Lucene的架构图 由图可知搜索的过程如下: 用户输入搜索的关键字.对关键字进行分词.根据分词结果去索引库里面找到对应的文章id.根据文章id找到对应的文章 2. L ...
- python+requests接口自动化测试框架实例详解
python+requests接口自动化测试框架实例详解 转自https://my.oschina.net/u/3041656/blog/820023 摘要: python + requests实 ...
- Scrapy笔记05- Item详解
Scrapy笔记05- Item详解 Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API, ...
随机推荐
- 面试前必须要知道的Redis面试题
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 回顾前面: 从零单排学Redis[青铜] 从零单排学 ...
- 一文快速了解MaxCompute
很多刚初次接触MaxCompute的用户,面对繁多的产品文档内容以及社区文章,往往很难快速.全面了解MaxCompute产品全貌.同时,很多拥有大数据开发经验的开发者,也希望能够结合自身的背景知识,将 ...
- python:前端(HTML)+后端(Django)+数据库(MySQL)
1.创建一个html文件用于简单的网页注册demo <!DOCTYPE html> <html lang="en"> <head> <me ...
- Android之Lottie动画详解
文章大纲 一.Lottie介绍二.Lottie实战三.项目源码下载四.参考文章 一.Lottie介绍 1. 什么是Lottie Lottie是Android和iOS的移动库,用于解析Adobe ...
- C# Npoi 实现Excel与数据库相互导入
十年河东,十年河西,莫欺少年穷! NPOI支持对 Word 和 Excel 文件的操作! 针对 Word 的操作一般用于打印技术!说白了就是利用 Word 文件作为模板,生成各种不同的打印!具体用到的 ...
- perlin噪声
手贱去点了图形学里面的噪声课程,然后一个周末就交代在这上面了,还是有些云里雾里. 噪声就是给定一个输入变量,生成一个值在0~1范围内的伪随机变量的函数.在图形学中一般是输入一个坐标得到一个范围在0~1 ...
- 【死磕 Spring】----- IOC 之 获取 Document 对象
原文出自:http://cmsblogs.com 在 XmlBeanDefinitionReader.doLoadDocument() 方法中做了两件事情,一是调用 getValidationMode ...
- VMware端口映射配置步骤
1:编辑->虚拟网络编辑器 2:点击NAT模式-->NAT设置 3:注意:主机端口就是物理机的端口,虚拟机就是wmware中的系统 点击添加
- Markdown 语法文档
Markdown 语法文档 前言 Markdown 是一种轻量级标记语言,创始人为約翰・格魯伯(英语:John Gruber); 它允许人们 "使用易读易写的纯文本格式编写文档,然后转换成有 ...
- MySQL命令窗口下中文显示乱码的解决过程
在dos客户端输出窗口中查询表中的数据,还有项目部署到服务器上时前台的页面,中文数据都显示成乱码,如下图所示: 这个问题困扰了我一天,后来解决了才发现原来我的方向错了,一直我以为是SpringBoot ...