简易数据分析 02 | Web Scraper 的下载与安装

这是简易数据分析系列的第 2 篇文章。
上篇说了数据分析在生活中的重要性,从这篇开始,我们就要进入分析的实战内容了。数据分析数据分析,没有数据怎么分析?所以我们首先要学会采集数据。
我调研了很多采集数据的软件,综合评定下来发现最好用的还是 Web Scraper,这是一款 Chrome 浏览器插件。
推荐的理由有这几个:
- 门槛足够低,只要你电脑上安装了 Chrome 浏览器就可以用
- 永久免费,无付费功能,无需注册
- 操作简单,点几次鼠标就能爬取网页,真正意义上的 0 行代码写爬虫
既然这么棒,当然是立马安装啦。
因为 Web Scraper 是 Chrome 浏览器插件,我当然是首推使用 Chrome。但是限于国内的网络环境,可能访问 Chrome 插件应用商店不是很方便,如果第一条路走不通,我们可以尝试第二条路,用 QQ 浏览器曲线救国(360 浏览器暂时不提供 Web Scraper 插件)。
这两个浏览器内核都是一样的,只是界面不一样。我后续的教程都将以 Chrome 浏览器为主力,QQ 浏览器可能会稍有一点点的不同,如果有不一样的地方,还需读者自行分辨差异。
1. 在 Chrome 浏览器上安装 Web Scraper 插件
1.1 安装 Chrome 浏览器
这个没啥好说的,Windows 电脑的各大应用商店都有最新版的 Chrome 浏览器,或者百度一下,首页一般都会有安装包地址,下载安装就好;
(为了减少兼容性问题,最好安装最新版本的 Chrome 浏览器)
1.2 安装 Web Scraper 插件
可以访问外网的同学,直接访问"Chrome 网上应用店",搜索 Web Scraper 下载安装就可:

暂时无条件访问外网,我们可以手动安装插件曲线救国一下,当然和上面比会稍微麻烦一些:
首先,我们访问 www.gugeapps.net 这个国内浏览器插件网站,搜索 Web Scraper,下载插件,注意这时候插件不是直接安装到浏览器上的,而是下载到了本地:

然后,我们在浏览器的的网址输入框里输入 chrome://extensions/ ,这样我们就可以打开浏览器的插件管理后台:
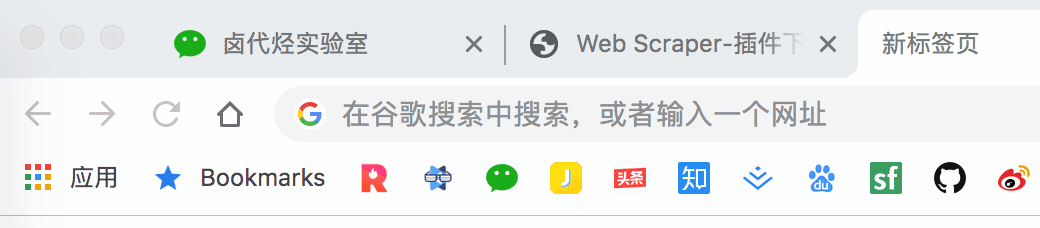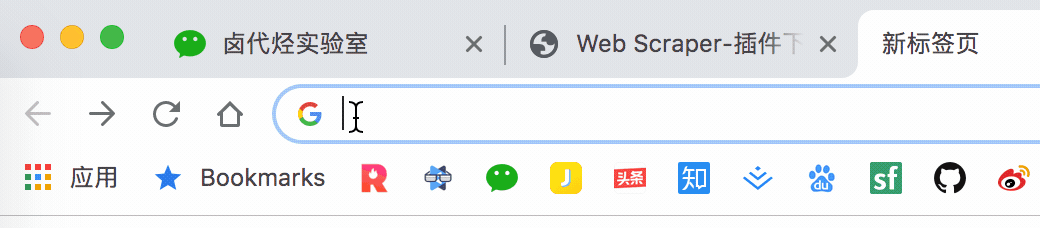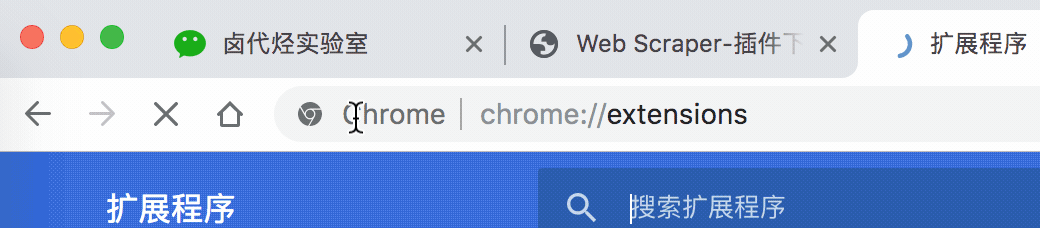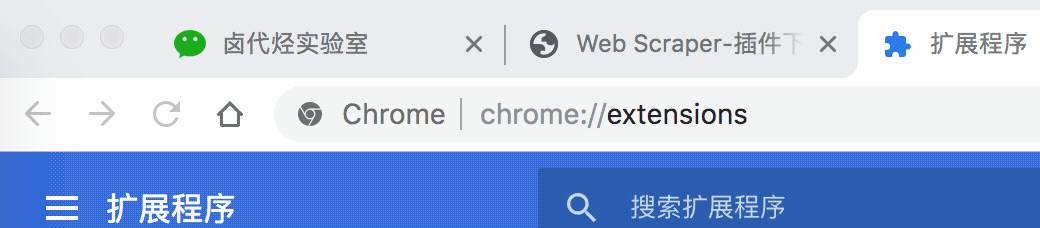
接下来就是解压安装刚刚下载的插件了。
如果你是 Mac 用户,首先要把这个安装包的后缀名 .crx 改为 .zip。

再切到浏览器的插件管理后台,打开右上角的开发者模式,把 Web Scraper.zip 这个文件拖进去,这样就安装好了。
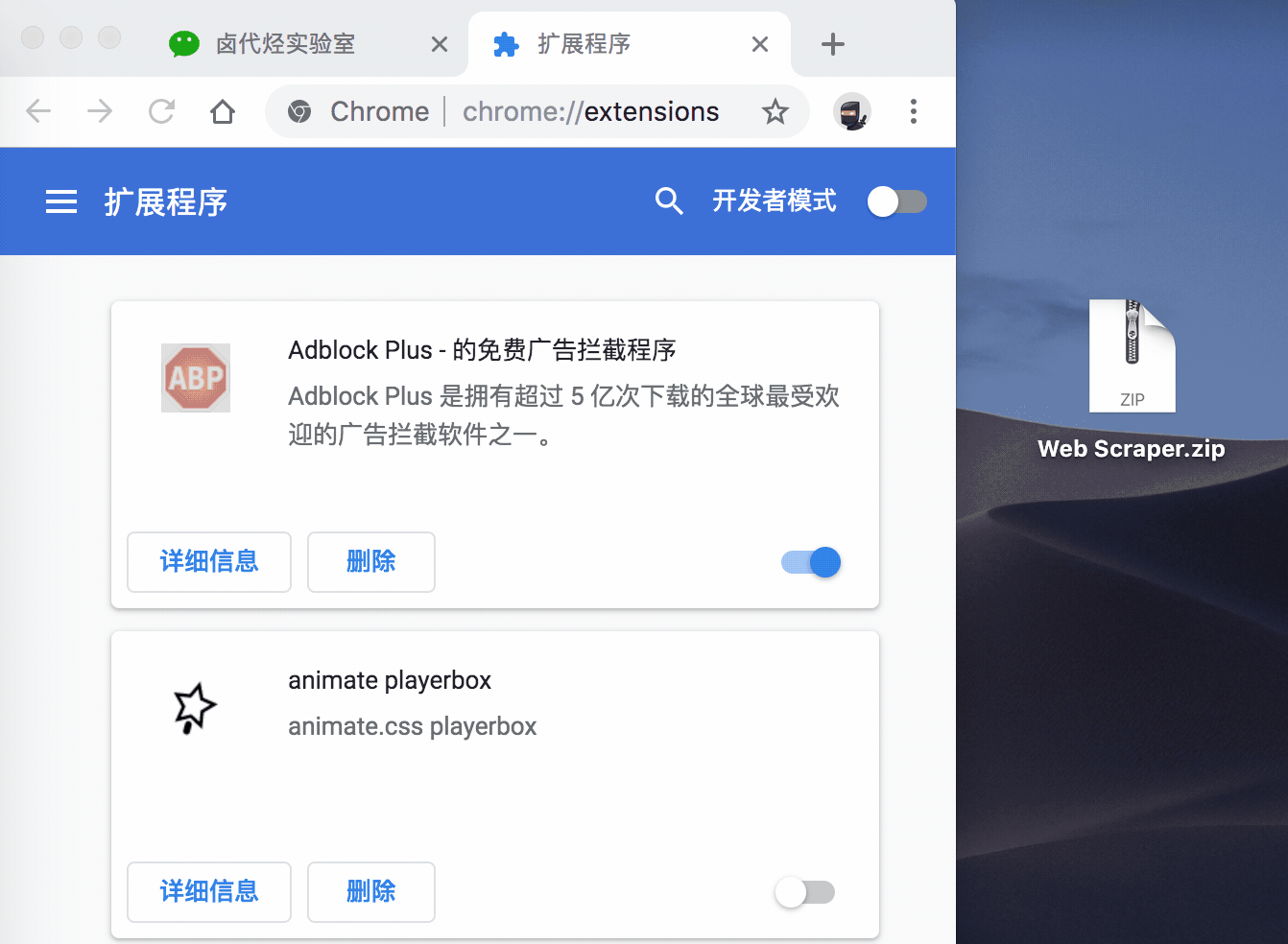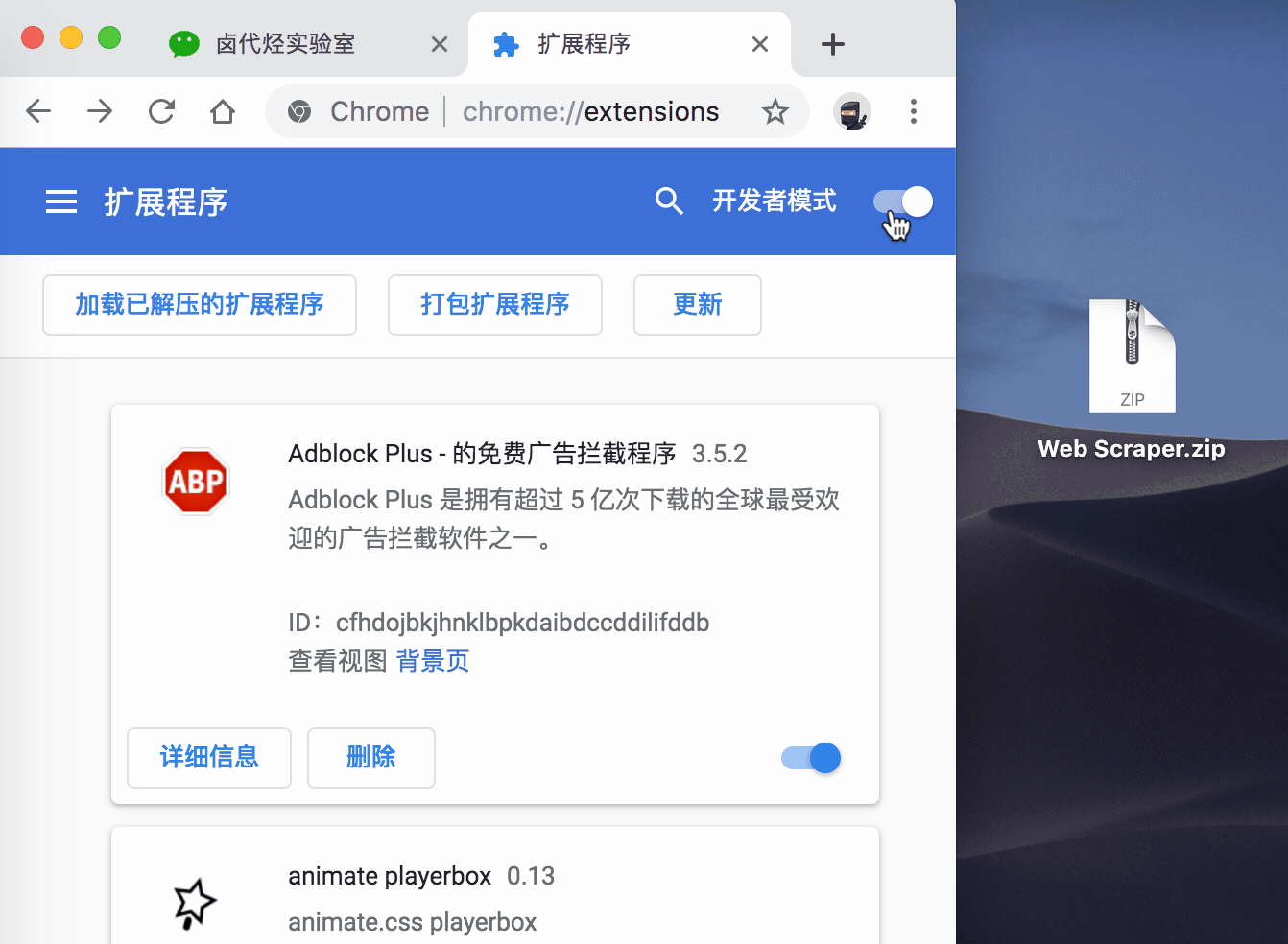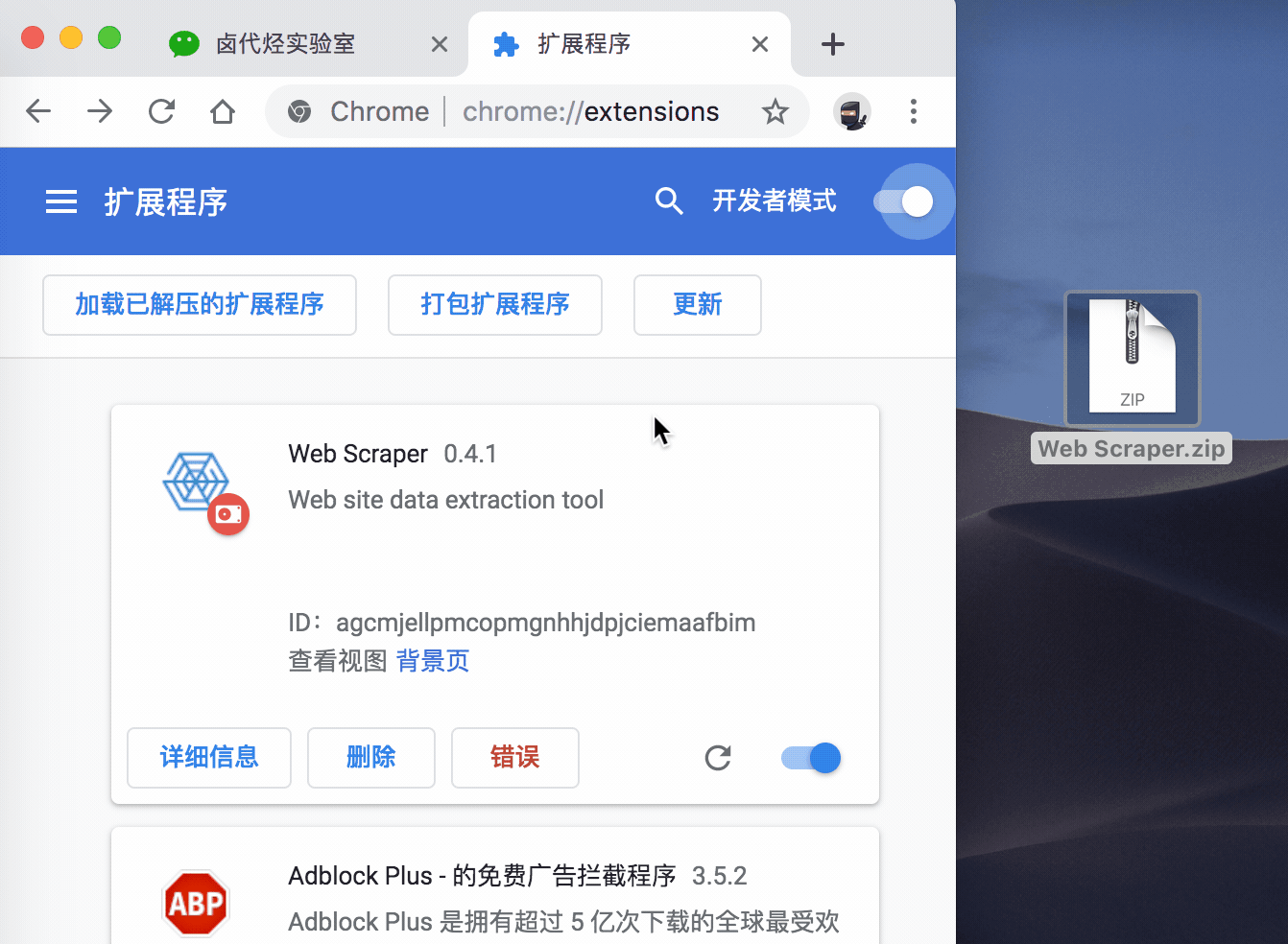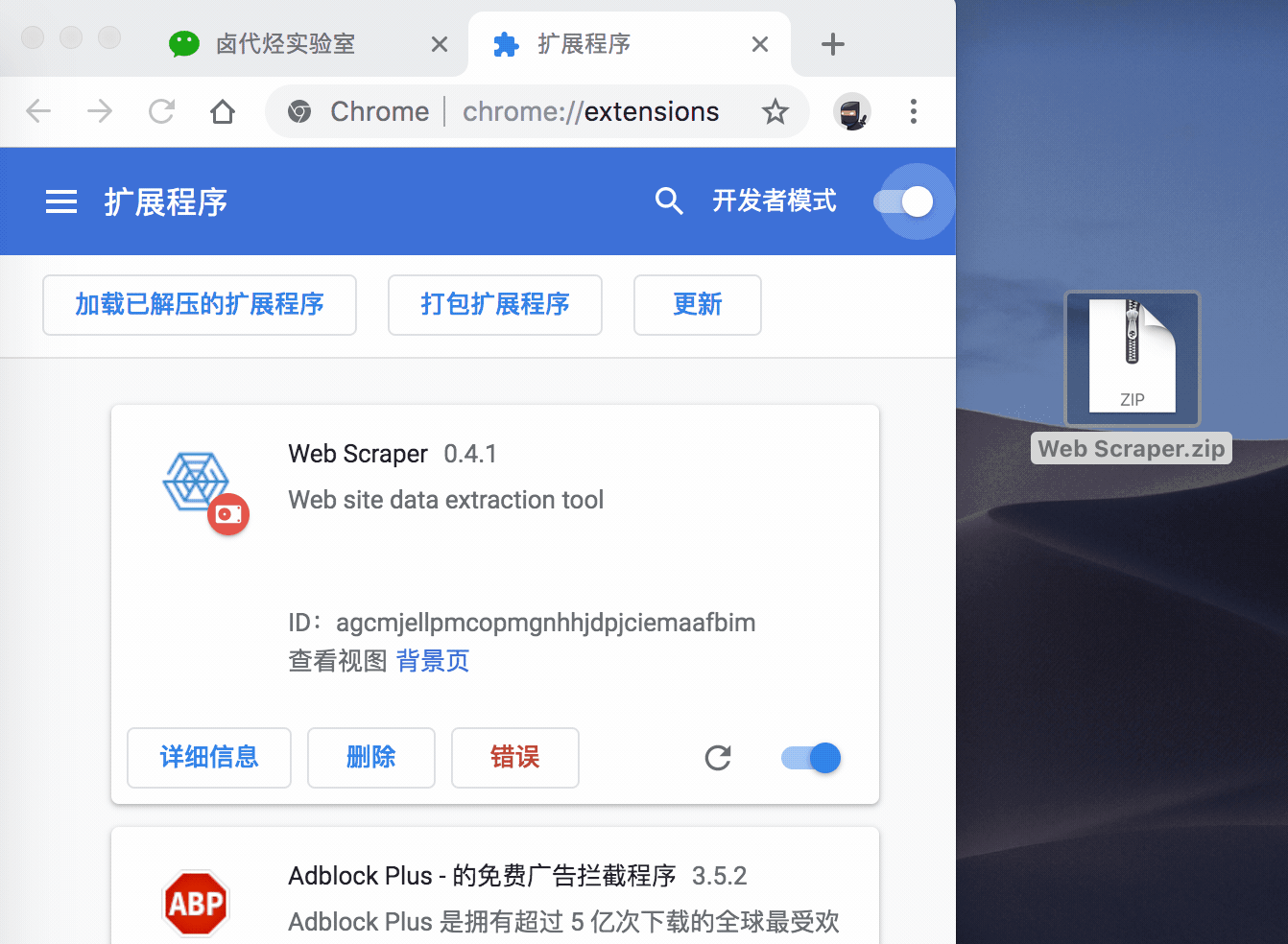
一般这样安装会有一个红色的错误按钮,我们不用管它,直接忽略就行。
如果你是 windows 用户,你需要这样做:
1.把后缀为 .crx 的插件改为 .rar,然后解压缩
2.进入 chrome://extensions/ 这个页面,开启开发者模式
3.点击"加载已解压的扩展程序",选择第一步中解压的文件夹,正常情况下就安装成功了。
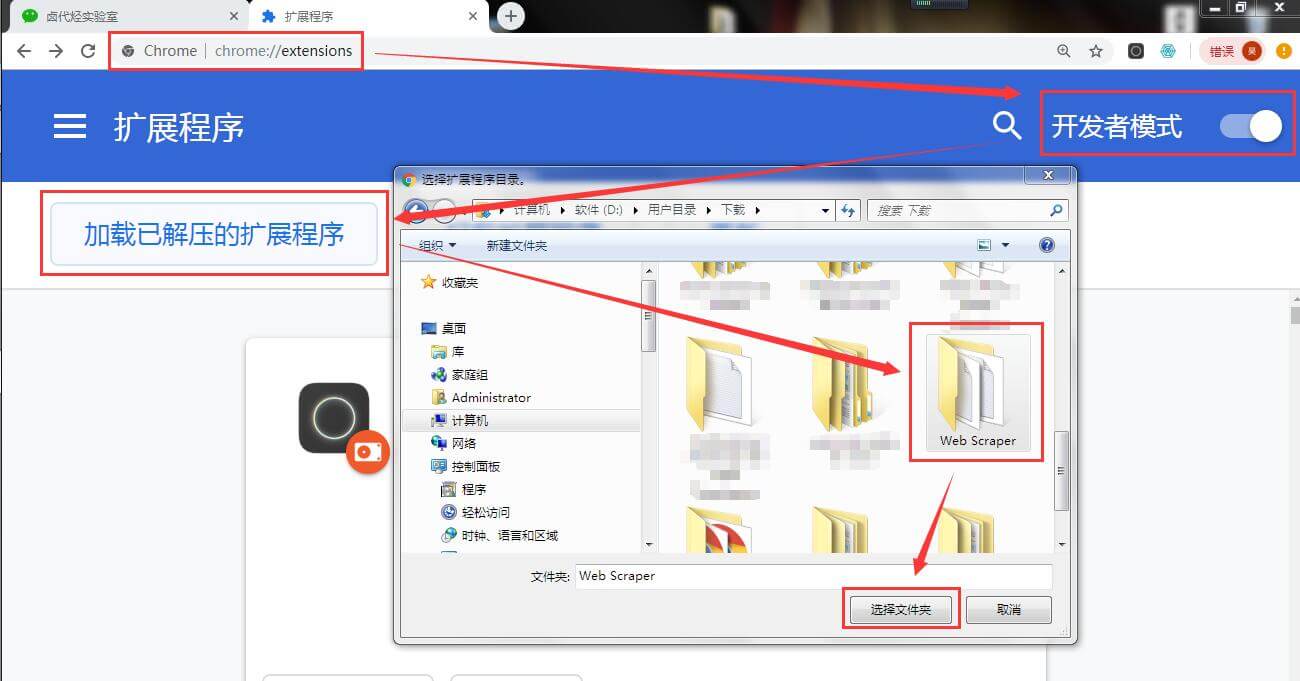
到这里我们的 Chrome 浏览器就成功安装好 Web Scraper 插件了。
2.在 QQ 浏览器上安装 Web Scraper 插件
2.1 安装 QQ 浏览器
去各大应用商店或者访问 QQ 浏览器官网下载安装就可。
QQ 浏览器 PC 版官网下载地址:https://browser.qq.com/
QQ 浏览器 Mac 版官网下载地址:https://browser.qq.com/mac/
2.2 安装 Web Scraper 插件
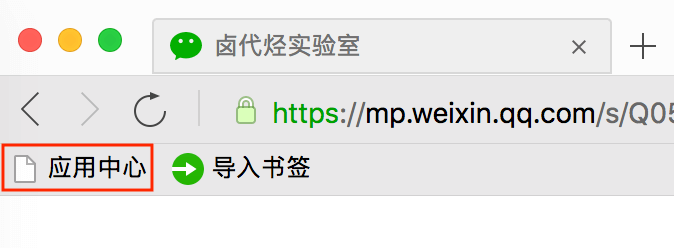
Mac 用户直接访问浏览器左上角的"应用中心",点击进入并搜索 Web Scraper 安装即可。
Windows 用户要先点击浏览器左上角的 ≡ 菜单栏,在弹出的菜单栏里选择"应用中心",点击进入并搜索 Web Scraper 安装即可。
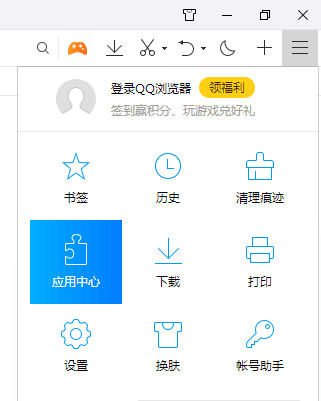
到这里我们的 Web Scraper 插件就安装成功啦,下一篇我们要探索一些浏览器的骚操作,为我们的后续学习打个好的基础。
推广一下我的公众号:卤代烃实验室,同步更新内容,觉得我写的不错的同学可以点个关注,在微信里可以及时收到消息。

简易数据分析 02 | Web Scraper 的下载与安装的更多相关文章
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- 简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用
这是简易数据分析系列的第 15 篇文章. 年末事情比较忙,很久不更新了,后台一直有读者催更,我看了一些读者给我的私信,发现一些通用的问题,所以单独写篇文章,介绍一些 Web Scraper 的进阶用法 ...
随机推荐
- 洛谷 - P2324 - 骑士精神 - A*搜索
为什么估价是16,因为最后一步复原空格可以恢复两个位置,当然设成17.18都可以. #include<bits/stdc++.h> using namespace std; typedef ...
- 洛谷P3668 [USACO17OPEN]Modern Art 2 现代艺术2
P3668 [USACO17OPEN]Modern Art 2 现代艺术2 题目背景 小TY的同学HF也想创作艺术 HF只有一块长条状的画布(画条),所以每一次涂色只能涂上连续几个单位的颜料,同样新的 ...
- express前后的分离session的使用
express前后端分离session的使用 1.后端app.js中增加 app.all('*', function(req, res, next) { res.header("Access ...
- mysql-5.5.56免安装版配置方法
1. 下载mysql-5.5.56-winx64 网址:dev.mysql.com/downloads/mysql/ 2. 解压MySQL压缩包 将以下载的MySQL压缩包解压到自定义目录下,我 ...
- 9.Python初窥门径(函数初识)
Python(函数初识) 一.初识函数 面向过程缺点 : 代码重复,代码描述性不高 函数 : 函数是以功能为导向,一个函数封装一个功能. 函数的优点 : 减少代码重复性,增强了代码的可读性 二.函数的 ...
- 微信小程序请求openid错误码40163
通过wx.login({})方法获取到的code只能使用一次,如果需要在哎服务器端再次请求获取openid来进行校验,需要再次通过wx.login({})方法获取code 否则会报错误代码40163, ...
- struts2 具体学习资料
[struts2]<package>的配置:https://www.cnblogs.com/ningvsban/p/3734562.html struts2 具体学习资料 :http:/ ...
- 各种安卓模拟器连接Adb
夜神模拟器:adb connect 127.0.0.1:62001 逍遥安卓模拟器:adb connect 127.0.0.1:21503 天天模拟器:adb connect 127.0.0.1:65 ...
- AngularJS(四):控制器、事件
本文也同步发表在我的公众号“我的天空” 控制器 控制器可以说是AngularJS中最重要的部分了!之前的一些示例,除了第一讲的示例以外,我们对于AngularJS的使用都集中在HTML部分,其实Ang ...
- CF1168A Increasing by Modulo
思路: 首先得做个转化,如果某个解法最终分别对a[i](i = 1, 2, ..., n)做了b[i](i = 1, 2, ..., n)次加1再取余的运算,那么可以等价地构造出x次(x = max( ...