API的理解和使用——键管理
核心知识点:
1.键重命名:rename和renamenx,使用renamenx时newkey必须不存在,重命名后会使用del删除原来的键,如果值比较大也会会造成阻塞。
2.随机返回一个值:randomkey
3.键过期:
a.除了expire、ttl之外,expireat、pexpireat、pexpire,内部都是使用的pexpireat;
b.expire键不存在返回0,设置负的过期时间,会立即删除键;persist和set会清除过期时间。
4.键迁移:
a.move库与库之间迁移数据,不常用
b.tump+restore,dump将键序列化(格式化采用RDB格式),然后restore复原;非原子性、客户端分布完成
c.migrate,dump+restore+del的组合,原子性,数据直接传输,收到之后会返回ok,相对tump+restore提升了效率
5.遍历键:
a.keys,可能带来阻塞,在不提供服务或者键总数比较少的情况下,可以使用;keys提供模式匹配,*、?、[]、\X;
b.scan,分批次遍历,不能保证能遍历完所有的键。
6.数据库管理:
a.select可以切换数据,有0-15这16个库;
b.多个数据库被“丢弃”的原因?单线程、库与库之间可能会相互影响、部分客户端不支持;
c.可以在一台机器上开启多个Redis实例
d.flushdb清空当前库,flishall清空所有库
e.使用flushdb\flushall会清空数据非常危险,同时可能会造成阻塞
之前介绍了一系列的关于各种数据结构的一些命令,接下来会介绍一些键的管理操作。
下面会从单个键管理、遍历键和数据库管理这三个方面进行介绍。
一、单个键管理
1.键重命名
命令:rename key newkey
127.0.0.1:6379> set name kebi
OK
127.0.0.1:6379> rename name name:kb
OK
127.0.0.1:6379> get name:kb
"kebi"
如果重新命令的这个键名在之前已经存在,那么它的值将会被覆盖:
127.0.0.1:6379> set a b
OK
127.0.0.1:6379> set c d
OK
127.0.0.1:6379> rename a c
OK
127.0.0.1:6379> get c
"b"
为了防止强行rename,Redis提供了renamenx命令,确保只有newkey不存在的时候才能被覆盖:
127.0.0.1:6379> set kebi dsb
OK
127.0.0.1:6379> set maoxian lsb
OK
127.0.0.1:6379> renamenx kebi maoxian
(integer) 0 #没有执行成功返回0
127.0.0.1:6379> get maoxian
"lsb"
127.0.0.1:6379> get kebi
"dsb"
在使用重命名的时候有两点要注意:
(1)由于重命令期间会执行del删除旧的键,如果键对应的值比较大,会存在阻塞Redis的可能性。
(2)如果key和newkey相同,在Redis3.2和之前的版本中,返回的结果可能会不同。
2.随机返回一个键
命令:randomkey
127.0.0.1:6379> dbsize
(integer) 33 #当前系统中有33个键
127.0.0.1:6379> randomkey
"name:kb" #每次都会随机返回一个键
127.0.0.1:6379> randomkey
"set:sunion:1_2"
127.0.0.1:6379> randomkey
"user:1"
3.键过期
之前在介绍Redis所有数据结构通用的命令时介绍过expire,它可以自动将带有过期时间的键删除,
除了expire、ttl命令之外,Redis还提供了expireat、pexpire、pexpireat、pttl、persist等命令。
- expire key seconds:键在reconds秒后过期。
- expireat key timestamp:键在秒级时间戳timestamp后过期。
127.0.0.1:> set hello world
OK
127.0.0.1:> expire hello
(integer) #设置成功
127.0.0.1:> ttl hello
(integer) #还是3秒
127.0.0.1:> ttl hello
(integer)
127.0.0.1:> ttl hello
(integer) - #键已经被删除
ttl命令和pttl都可以查询键的剩余过期时间,但是pttl精度更高,可以达到毫秒级别,有3种返回值:
- 大于等于0的整数:键的剩余过期时间(ttl是秒,pttl是毫秒)。
- -1:键没有设置过期时间。
- -2:键不存在。
expireat命令可以设置键的秒级过期时间戳如果需要将键hello在2017-12-19 00:00:00(秒级时间戳为1513612800)过期,可以这样:
127.0.0.1:> set hello world
OK
127.0.0.1:> expireat hello
(integer)
除此之外,Redis2.6版本以后提供了毫秒级的过期方案:
- pexpire key millseconds:键在milliseconds毫秒后过期。
- pexpireat key milliseconds-timestamp:键在毫秒时间戳timestamp后过期。
但无论是使用过期时间还是时间戳,秒级还是毫秒级,在Redis内部最终使用的都是pexpireat。
在使用Redis相关过期命令时,需要注意以下几点。
(1)如果expire的键不存在,返回的结果是0:
127.0.0.1:> expire not_exist_key
(integer)
(2)如果过期时间为负值,键会立即被删除,犹如使用del命令一样:
127.0.0.1:> set age
OK
127.0.0.1:> expire age -
(integer)
127.0.0.1:> get age
(nil)
(3)persist命令可以将键的过期时间清除:
127.0.0.1:> set sex boy
OK
127.0.0.1:> expire sex
(integer)
127.0.0.1:> ttl sex
(integer)
127.0.0.1:> persist sex
(integer)
127.0.0.1:> ttl sex
(integer) - #代表没有设置过期时间
(4)对于字符串类型键,执行set命令会去掉过期时间,这个问题很容易在开发中被忽视。
如下是Redis源码中,set命令的函数setKey,可以看到最后执行了removeExpire(db,key)函数去掉了过期时间:
void setKey(redisDb *db,robj *key,robj * val) (
if (lookupKeyWrite(db,key) == NULL) {
dbAdd(db,key,val);
} else {
dbOverwrite(db,key,val);
}
incrRefCount(val);
//去掉过期时间
removeExpire(db,key);
signalModifiedKey(db,key);
}
下面的例子证明set会导致过期时间失效:
127.0.0.1:> set hello world
OK
127.0.0.1:> expire hello
(integer)
127.0.0.1:> ttl hello
(integer)
127.0.0.1:> set hello world
OK
127.0.0.1:> ttl hello
(integer) - #代表没有设置过期时间
(5)Redis不支持二级数据结构(例如哈希、列表)内部元素的过期功能,例如不能对列表类型的一个元素设置过期时间。
(6)setex命令作为set+expire的组合,不但是原子执行,同时减少了一次网络通讯的时间。
4.迁移键
迁移的功能非常重要,因为有时候我们只想把部分数据由一个Redis迁移到另一个Redis(例如从生产环境迁移到测试环境),
Redis发展历程中提供了move、dump+restore、migrate三组迁移键的方法,它们的实现方式及使用场景不大相同,下面分别介绍:
(1)move
命令:move key db
move命令用于在Redis内部进行数据迁移,Redis内部可以有多个数据库,每个数据库在数据上是相互隔离的,
move key db就是把指定的键从源数据库迁移到目标数据库中。不建议在生产环境中使用。
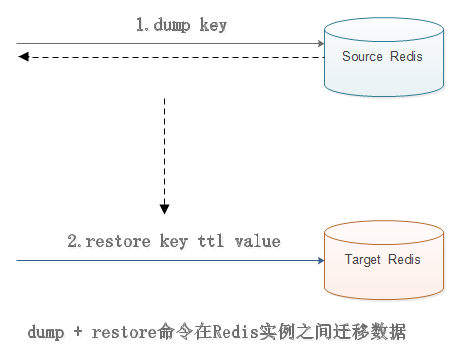
(2)dump+restore
命令:
dump restore
restore key ttl value
dump + restore可以实现在不同的Redis实例之间进行数据迁移功能,整个迁移过程分两步:
第一步,在源Redis上,dump命令会将键值序列化,格式化采用的是RDB格式。
第二步,在目标Redis上,restore命令将上面序列化的值进行复原,其中ttl参数代表过期时间,如果ttl=0代表没有过期时间。
有关dump+restore有两点需要注意:
第一,整个迁移过程并非原子性的,而是通过客户端分步完成的。
第二,迁移过程是开启两个客户端连接,所以dump的结果不是在源Redis和目标Redis之间进行传输。
(3)migrate
命令:migrate host port key|“”destination-db timeout [copy] [replace] [keys key [key ...]]
参数说明:
- host:目标Redis的IP地址
- port:目标Redis的端口
- key|“”:在Redis3.0.6版本之前,migrate只支持迁移一个键,之后的版本支持迁移多个键,如果需要迁移多个键,此处为“”
- destination-db:目标Redis的数据库索引
- timeout:迁移的超时时间(单位为毫秒)
- [copy]:如果添加此选项,迁移后并不删除源键
- [replace]:如果添加此选项,migrate不管目标Redis是否存在该键都会正常迁移进行数据覆盖
- [keys key [key ...]]:迁移多个键。
migrate命令也是用于在Redis实例间进行数据迁移的,实际上migrate命令就是将dump、restore、del三个命令进行组合,从而简化了操作流程。
migrate命令具有原子性,而且从Redis3.0.6版本以后已经支持迁移多个键功能,有效地提高了迁移效率。
实现过程和dump+restore基本类似,但是有三点不大相同:
第一,整个过程是原子执行,不需要在多个Redis实例上开启客户端的,只需要在源Redis上执行migreate命令即可。
第二,migrate命令数据传输直接在源Redis和目标Redis上完成的。
第三,目标Redis完成restore后会发送OK给源Redis,源Redis接收后会根据migrate对应的选项来决定是否在源Redis上删除对应的键。
| 命令 | 作用域 | 原子性 | 支持多个键 |
| move | Redis实例内部 | 是 | 否 |
| dump+restore | Redis实例之间 | 否 | 否 |
| migrate | Redis实例之间 | 是 | 是 |
二、遍历键
1.全量遍历键
命令:keys pattern
之前介过绍过keys *这个命令,实际上keys命令是是支持pattern(模式)匹配的。之前我们是这样用的:
127.0.0.1:> keys *
) "key"
) "user:ranking:1"
) "list:2"
) "setkey3"
) "kebi"
) "maoxian"
) "listkey"
) "str:2"
) "sex"
) "set:sunion:2_1"
) "hello"
) "user:2"
) "user:1"
) "list:1"
) "user:ranking:2"
) "name:kb"
) "setkey2"
) "user1:1"
) "str:1"
) "str"
) "list:test1"
上面为了遍历所有的键,pattern直接使用星号,这是因为pattern使用的是glob风格的通配符:
- *代表匹配任意个字符。
- ?代表匹配一个字符。
- [ ]代表匹配部分字符,例如[1,3]匹配1和3,[1-4]匹配1-4之间的任意数字。
- \x用来做转义,例如要匹配星号、问号需要进行转义。
例如,要匹配三个字符的键:
127.0.0.1:> keys ???
) "key"
) "sex"
) "str"
要匹配以u和l开头的键:
127.0.0.1:> keys [u,l]*
) "user:ranking:1"
) "list:2"
) "listkey"
) "user:2"
) "user:1"
) "list:1"
) "user:ranking:2"
) "user1:1"
) "list:test1"
当需要遍历所有键时(例如检测过期或者闲置时间、寻找大对象等),keys是一个很有帮助的命令。
但是如果考虑到Redis的单线程架构就不妙了,如果Redis包含了大量的键,执行keys命令很可能会带来Redis阻塞,
所以一般不嫁你在生产环境下使用keys命令,但是有时候确实有遍历键的需求该怎么办,可以在以下三种情况下使用:
- 在一个不对外提供服务的Redis从节点上执行,这样不会阻碍到客户端的请求,但是会影响到主从复制。
- 如果确认键值总数比较少,可以执行该命令。
- 使用下面要介绍的scan命令渐进式的遍历所有键,可以有效防止阻塞。
2.渐进式遍历
Redis从2.8版本后,提供了一个新的命令scan,它能有效的解决keys命令存在的问题。
和keys命令执行时会遍历所有键不同,scan采用渐进式遍历的方式来解决keys的命令可能带来的阻塞问题,每次scan命令的时间复杂度是O(1)。
但是要真正实现keys的功能,需要执行多次scan。Redis存储键值对实际使用的是hashtable的数据结构,其基本模型如下:
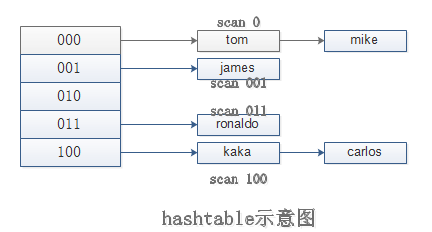
那么每次执行scan,可以想象成只扫描一个字典中的一部分,直到将字典中所有键遍历完毕。
scan的使用方法如下:
scan cursor [match pattern] [count number]
参数解释:
- cursor是必须参数,实际上cousor是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标的值,直到游标值为0,表示遍历结束。
- match pattern是可选参数,它的作用是做模式的匹配,这点和keys的模式匹配很像。
- count number是可选参数,它的作用是表明每次要遍历的键的个数,默认值为10。
现在内存中有16个键:
127.0.0.1:> keys *
) "key"
) "list:2"
) "setkey3"
) "kebi"
) "maoxian"
) "listkey"
) "str:2"
) "sex"
) "set:sunion:2_1"
) "hello"
) "list:1"
) "name:kb"
) "setkey2"
) "str:1"
) "str"
) "list:test1"
使用scan做遍历,记住必须从0开始:
127.0.0.1:> scan
) ""
) ) "sex"
) "key"
) "hello"
) "list:1"
) "kebi"
) "str:1"
) "list:2"
) "listkey"
) "str"
) "maoxian"
默认返回10个键,第一行表示需要开始的cursor的位置,接着访问:
127.0.0.1:> scan
) ""
) ) "setkey3"
) "name:kb"
) "str:2"
) "setkey2"
) "set:sunion:2_1"
) "list:test1"
返回0,代表已经遍历完成。
除了scan之外,Redis提供了面向哈希类型、集合类型、有序集合的扫描遍历命令,
解决诸如hgetall、smembers、zrange可能产生的阻塞问题,对应的命令分别是hscan、sscan、zscan,它们的用法和scan基本类似。
但是scan并不是万能的,如果在scan的过程中如果有键的变化(增加、删除、修改),
那么遍历效果可能会碰到如下问题:新增的键可能没有遍历到,遍历出了重复的键的情况,也就是说scan并不能保证完整的遍历出所有的键。
三、数据库管理
Redis提供了几个面向Redis数据库的操作,它们分别是dbsize、select、flushdb/flushall命令。
1.切换数据库
命令:select dbIndex
许多关系型数据库,例如MySQL支持在一个实例下有多个数据库存在的,但是与关系型数据库用字符来区分不同的数据库名不同,
Redis只是用数字作为多个数据库的实现,Redis默认配置中是有16个数据库,
select 0操作将切换到第一个数据库,默认也是进入第一个数据库,select 15操作切换到最后一个数据库,
但是0号数据库和15号数据库之间的数据没有任何关联,甚至可以存在相同的键:
127.0.0.1:> get hello
"world" #默认0号库
127.0.0.1:> select #切换到15号库
OK
127.0.0.1:[]> get hello #不存在hello键
(nil)
127.0.0.1:[]> set hello WORLD
OK
127.0.0.1:[]> get hello #不同库之间可以存在相同的键
"WORLD"
关于库之间的切换可以看下图:
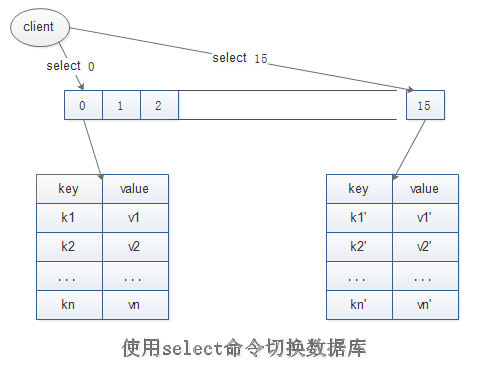
是否可以使用测试数据库和正式数据一样,把正式数据放在0号数据库,测试数据放在1号数据库了?彼此之间会有影响吗?
Redis3.0中已经逐渐弱化了这个功能,例如Redis的分布式实现Redis Cluster只允许使用0号数据库,只不过为了兼容老版本,该功能还没有完全废除。
下面分析以下为什么要废弃Redis的这项功能:
(1)Redis是单线程。如果使用多个数据库,那个这些数据库仍然是使用一个CPU,彼此之间还是会收到影响。
(2)对数据库的使用方式,会让调试和运维不同业务的数据库变得困难。如果一个数据库有慢查询存在,就会影响其他的数据库。
(3)部分Redis客户端根本不支持这种方式
如果要使用多个数据库功能,完全可以在一台机器上部署多个Redis实例,彼此使用端口来做区分,
因为一般的服务器都有多个CPU,这样多个数据库之间就不会收到影响,还能充分利用资源。
2.flushdb/flushall
flushdb/flushall命令用于清除数据库,两者的区别在于,flishdb只会清除当前数据库,而flushall会清除所有数据库。
现有三个库:
127.0.0.1:[]> select
OK
127.0.0.1:> dbsize #0号库有16个键
(integer)
127.0.0.1:> select
OK
127.0.0.1:[]> dbsize #2号库有3个键
(integer)
127.0.0.1:[]> select
OK
127.0.0.1:[]> dbsize #15号库有1个键
(integer)
在2号库上使用flushdb命令:
127.0.0.1:[]> select
OK
127.0.0.1:[]> flushdb
OK
127.0.0.1:[]> dbsize
(integer) #2号库已经清空
127.0.0.1:[]> select
OK
127.0.0.1:> dbsize
(integer) #0号库依然存在
在0号库上执行flushall命令:
127.0.0.1:> select
OK
127.0.0.1:> flushall
OK
127.0.0.1:> dbsize #0号库空
(integer)
127.0.0.1:> select
OK
127.0.0.1:[]> dbsize #15号空
(integer)
127.0.0.1:[]> select
OK
127.0.0.1:[]> dbsize #2号空
(integer)
flushdb/flishall虽然可以很方便的清理数据,但是也会有两个问题:
(1)如果当前库键值数量非常多,很有可能会造成Redis阻塞;
(2)flushdb/flushall会将所有数据全部清除,这是非常危险的,后面会讲如何规避和如何恢复数据。
API的理解和使用——键管理的更多相关文章
- 深入理解Redis主键失效原理及实现机制(转)
原文:深入理解Redis主键失效原理及实现机制 作为一种定期清理无效数据的重要机制,主键失效存在于大多数缓存系统中,Redis 也不例外.在 Redis 提供的诸多命令中,EXPIRE.EXPIREA ...
- Redis(二)数据结构与键管理
一.基础知识 1.全局命令 keys * :查看所有键 dbsize:返回当前数据库中键的总数 exists key:检查键是否存在 del key ... :删除键 expire key sec ...
- qnx:从API开始理解QNX -- 消息传递
从API开始理解QNX -- 消息传递 http://www.openqnx.com/chinese/viewtopic.php?f=5&t=2161 1. 频道与连接 Chann ...
- 自己写的书《深入理解Android虚拟机内存管理》,不出版只是写着玩
百度网盘地址:https://pan.baidu.com/s/1jI4xZgE 我给起的书名叫做<深入理解Android虚拟机内存管理>.本书分为两个部分,前半部分主要是我对Linux0. ...
- 理解vuex的状态管理模式架构
理解vuex的状态管理模式架构 一: 什么是vuex?官方解释如下:vuex是一个专为vue.js应用程序开发的状态管理模式.它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证以一种可预测的 ...
- Redis键管理
Redis键管理 Redis 键命令用于管理 redis 的键. 语法 Redis 键命令的基本语法如下: redis > COMMAND KEY_NAME redis > SET w3c ...
- 第二章 API的理解和使用
2.1.1全局命令 Key * 查看所有键,(慎用,会把所有键都遍历一次并列出) Dbsize 查看键总数,不会遍历所有键,只是从内置函数中读取一个数 Exists [key] 检查键是否存在 Del ...
- 2.API的理解和使用
标题 : 2.API的理解和使用 目录 : Redis 序号 : 2 zset的成员是唯一的,但分数(score)却可以重复. 有序集合的内部编码 1.ziplist(压缩列表):当有序集合的 ...
- Redis学习笔记(三)redis 的键管理
Redis 的键管理 一.Redis 数据库管理 Redis 是一个键值对(key-value pair)的数据库服务器,其数据保存在 src/server.h/redisDb 中(网上很多帖子说在 ...
随机推荐
- node/webpack/react
node是运行引擎,通过他可以直接在后端运行js语法 webpack是打包工具 react是前端框架 通过 npm 使用 React 我们建议在 React 中使用 CommonJS 模块系统,比如 ...
- 【温故知新】——HTML基础重要知识点复习
前言:本文是自己在学习课程中的课程笔记,这里用来温故知新的,并非本人原创. 一.HTML快速入门(重点) 1.HTML概述 1.什么是HTML HTML : Hyper Text Markup Lan ...
- 转:代码管理技巧——两步创建本地SVN服务器图文教程
from: http://www.cnblogs.com/tianhonghui/archive/2012/07/22/2603454.html 当我们进行开发的时候,不论是独立开发还是处在团队中 ...
- 怎样通过Html网页调用本地安卓app
怎样使用html网页和本地app进行传递数据呢?经过研究.发现还是有方法的,总结了一下,大致有一下几种方式 一.通过html页面打开Android本地的app 1.首先在编写一个简单的html页面 & ...
- redis实现訪问频次限制的几种方式
结合上一篇文章<redis在学生抢房应用中的实践小结>中提及的用redis实现DDOS设计时遇到的expire的坑.事实上,redis官网中对incr命令的介绍中已经有关于怎样用redis ...
- storm - 可靠机制
一 可靠性简单介绍 Storm的可靠性是指Storm会告知用户每个消息单元是否在一个指定的时间(timeout)内被全然处理. 全然处理的意思是该MessageI ...
- SQLserver字符串分割函数
一.按指定符号分割字符串,返回分割后的元素个数,方法很简单,就是看字符串中存在多少个分隔符号,然后再加一,就是要求的结果.CREATE function Get_StrArrayLength( @s ...
- iPhone X
iPhone X前置深度摄像头带来了Animoji和face ID,同时也将3D Face Tracking的接口开放给了开发者.有幸去Cupertino苹果总部参加了iPhone X的封闭开发,本文 ...
- Android有关surfaceView又一次创建的问题。
近期在做一个Android视频播放器的项目.遇到一个问题,就是锁屏之后.surfaceview就会被销毁掉,然后就会出现各种错误.到csdn论坛去发帖提问,各种所谓的大神都说,解锁屏在又一次创建一个, ...
- 数据挖掘之pandas
sdata={'语文':89,'数学':96,'音乐':39,'英语':78,'化学':88} #字典向Series转化 @@ >>> studata=Series(sdata) & ...