Java基础知识:Collection接口
*本文是最近学习到的知识的记录以及分享,算不上原创。
*参考文献见文末。
这篇文章主要讲的是java的Collection接口派生的两个子接口List和Set。
目录
Collection框架
List接口
Set接口
1.Collection框架
首先我们综合性地看一下java的Collection接口的框架,如下图:
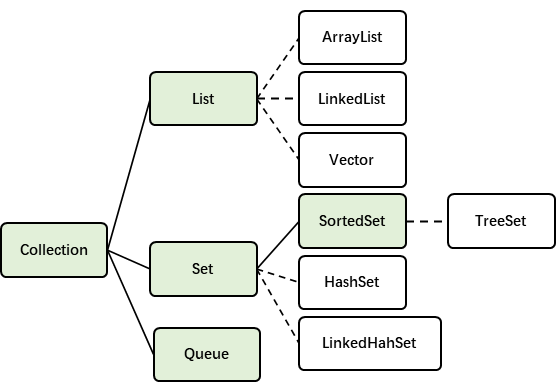
*图中绿色表示接口,白色表示类。
List接口和Set接口是Collection接口派生的主要的两个子接口。
2.List接口
List的主要特征
(1)有序(ordered):元素的存取是有序的,保证了取出的元素的顺序与输入的元素顺序保持一致。
例如:
1 import java.util.ArrayList;
2 import java.util.LinkedList;
3 import java.util.Vector;
4
5 public class CollectionDemo {
6 public static void main(String[] args) {
7 //ArrayList
8 ArrayList<String> list=new ArrayList<String>();
9 list.add("11");
10 list.add("22");
11 list.add("33");
12 for(int i=0;i<list.size();++i){
13 System.out.print(list.get(i)+" "); //output: 11 22 33
14 }
15 System.out.println("");
16 //LinkedList
17 LinkedList<String> list2=new LinkedList<String>();
18 list2.add("11");
19 list2.add("22");
20 list2.add("33");
21 for(int i=0;i<list2.size();++i){
22 System.out.print(list.get(i)+" "); //output: 11 22 33
23 }
24 System.out.println("");
25 //Vector
26 Vector<String> list3=new Vector<String>();
27 list3.add("11");
28 list3.add("22");
29 list3.add("33");
30 for(int i=0;i<list3.size();++i){
31 System.out.print(list.get(i)+" "); //output: 11 22 33
32 }
33 System.out.println("");
34 }
35 }
List元素存取有序
(2)索引(index):允许用户根据索引对元素进行精准定位并进行查询、插入、删除等操作。
*所以,对List的遍历,不仅可以通过Iterator,还可以通过索引(index)。
(3)允许重复:允许多个重复的元素存在。
List的主要方法
https://docs.oracle.com/javase/7/docs/api/java/util/List.html
在提到List接口的各种实现类之前,首先我们回顾一下数据结构中数组和链表的各自的特色。
数组易于对元素的查询、遍历,但对元素的增删操作比较繁琐;链表能够方便地对元素进行增删,但不利于元素的查询、遍历。
2.1 ArrayList
http://www.cnblogs.com/skywang12345/p/3308556.html
ArrayList元素存储的数据结构是数组结构。ArrayList相当于动态数组,既保持了数组查询快速的优点,又不像数组那样对元素的增删慢,所以是最常用的集合。
ArrayList的Clone()
ArrayList的clone()属于浅拷贝。
浅拷贝与深拷贝的问题,这与引用对象的存储方式有关系。浅拷贝简单地说,就是把复制一个指向该对象的箭头给你,深拷贝简单地说,就是复制一个对象给你。

当ArrayList中的元素为基本数据类型时,可以说不存在浅拷贝与深拷贝的问题。
例如:
import java.util.ArrayList;
public class ListDemo3 {
public static void main(String[] args) {
ArrayList<Integer> a1=new ArrayList<Integer>();
a1.add(1);
a1.add(2);
a1.add(3);
//基本数据类型: byte short int long float double boolean char
ArrayList<Integer> a2=(ArrayList<Integer>) a1.clone();
System.out.println(a1); //[1, 2, 3]
System.out.println(a2); //[1, 2, 3]
a1.set(0, 10);
a2.remove(2);
System.out.println(a1); //[10, 2, 3]
System.out.println(a2); //[1, 2]
}
}
当ArrayList中的元素为引用数据类型时,要意识到浅拷贝与深拷贝的问题。
例如:
import java.util.ArrayList;
public class ListDemo3 {
public static void main(String[] args) {
ArrayList<Student> b1=new ArrayList<Student>();
Student s1=new Student(001,"zhangsan",22);
Student s2=new Student(002,"lisi",21);
Student s3=new Student(003,"wangwu",18);
b1.add(s1);
b1.add(s2);
b1.add(s3);
//基本数据类型: byte short int long float double boolean char
//引用数据类型:接口interface, 类class, 数组
ArrayList<Student> b2=(ArrayList<Student>) b1.clone();
System.out.println(b1);
System.out.println(b2);
/*
* [Student [id=1, name=zhangsan, age=22], Student [id=2, name=lisi, age=21], Student [id=3, name=wangwu, age=18]]
* [Student [id=1, name=zhangsan, age=22], Student [id=2, name=lisi, age=21], Student [id=3, name=wangwu, age=18]]
*/
b2.remove(2);
System.out.println(b1);
System.out.println(b2);
/*
* [Student [id=1, name=zhangsan, age=22], Student [id=2, name=lisi, age=21], Student [id=3, name=wangwu, age=18]]
* [Student [id=1, name=zhangsan, age=22], Student [id=2, name=lisi, age=21]]
*/
b1.get(0).setName("wangmazi");
System.out.println(b1);
System.out.println(b2);
/*
* [Student [id=1, name=wangmazi, age=22], Student [id=2, name=lisi, age=21], Student [id=3, name=wangwu, age=18]]
* [Student [id=1, name=wangmazi, age=22], Student [id=2, name=lisi, age=21]]
*/
}
}
第一步:创建ArrayList对象b1
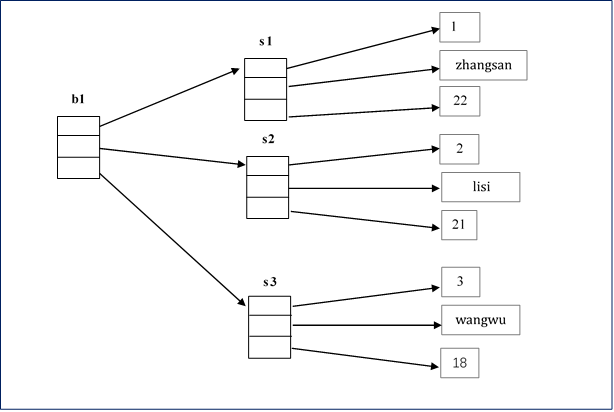
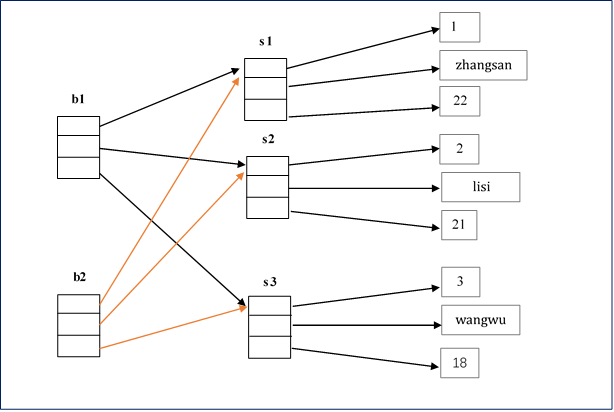
第二步:clone()
从下图中,可以看到左边的箭头和右边的箭头,箭头左边是地址,箭头右边是指向的对象。我们可以发现虽然b1和b2的地址不同,但指向相同的对象。如果仅仅改变左边的箭头,如改变b1的箭头则不会影响到b2,但如果改变了右边的箭头,如改变了s1的箭头,就会同时对b1, b2造成影响。
Arraylist的遍历
ArrayList有三种遍历方式。
例如:
import java.util.ArrayList;
import java.util.Iterator; public class ListDemo2 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<String>();
list.add("11");
list.add("22");
list.add("33");
//第一种遍历方式:Iterator
Iterator<String> it=list.iterator();
while(it.hasNext()){
System.out.print(it.next()+" "); //11 22 33
}
System.out.println("");
//第二种遍历方式
for(int i=0;i<list.size();++i){
System.out.print(list.get(i)+" "); //11 22 33
}
System.out.println("");
//第三种遍历方式
for(String s:list){
System.out.print(s+" "); //11 22 33
}
System.out.println("");
}
}
结果显示,这三种遍历方法中,第二种(使用索引index)的效率最高,第一种(使用Iterator)的效率最低。
ArrayList的toArray(T[] contents)
Arraylist提供了两个将ArrayList转换为数组的方法:
Object[] toArray()
<T> T[] toArray(T[] contents)
由于toArray()返回的类型是Object[],如果进行强制类型转换会造成java.lang.ClassCastException。因此调用toArray()容易出错,更建议使用toArray(T[] contents)。
例如:
import java.util.ArrayList;
import java.util.Arrays; public class ListDemo2 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<String>();
list.add("11");
list.add("22");
list.add("33");
//方法1
String[] str=new String[list.size()];
str=list.toArray(str);
System.out.println(Arrays.toString(str)); //[11, 22, 33]
//方法2
String[] str2=(String[])list.toArray(new String[0]);
System.out.println(Arrays.toString(str2)); //[11, 22, 33]
}
}
2.2 LinkedList
LinkedList元素存储的数据结构是链表结构。LinkedList能够方便地对元素进行增删。
LinkedList提供了一些方法,来方便对首尾元素的操作。
LinkedList还可以作为堆栈、队列的结构使用,所以提供了一些和堆栈、队列相关的方法。
例如:
import java.util.LinkedList;
public class ListDemo1 {
public static void main(String[] args) {
LinkedList<String> list=new LinkedList<String>();
list.add("11");
list.add("22");
list.add("33");
while(!list.isEmpty()){
System.out.print(list.pop()+" "); //output: 11 22 33
}
System.out.println("");
}
}
LinkedList的pop()
*注意元素存取的顺序,保持着先进先出的顺序。
2.3 Vector
Vector元素存储的数据结构是数组结构。Vector与ArrayList类似,Vector提供的Enumeration与ArrayList提供的Iterator类似,二者在功能上可以说的上是重复的。
例如:
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.Iterator;
import java.util.Vector; public class ListDemo1 {
public static void main(String[] args) {
//ArrayList和Iterator
ArrayList<String> list=new ArrayList<String>();
list.add("11");
list.add("22");
list.add("33");
Iterator<String> it=list.iterator();
while(it.hasNext()){
System.out.print(it.next()+" ");
}
System.out.println("");
//Vector和Enumeration
Vector<String> list2=new Vector<String>();
list2.add("11");
list2.add("22");
list2.add("33");
Enumeration<String> en=list2.elements();
while(en.hasMoreElements()){
System.out.print(en.nextElement()+" ");
}
System.out.println("");
}
}
ArrayList和Iterator vs.Vector和Enumration
3.Set接口
Set的主要特征
(1)不允许重复:元素不允许重复。Set在存储元素时会通过hashCode()和equals()来保证元素的唯一性。
Set如何保证元素的唯一性
Set在存储元素时,通过hashCode()和equals()来保证元素的唯一性。
事实上,当存储一个新的元素时,仅仅通过equals()来逐一判断新元素是否与集合中已有的元素是否重合,这种方法也是可行的,那为什么还需要hashCode()呢。因为当Set中元素数量很多时,通过equals()逐一判断并不是一个高效率的方法,所以同时通过hashCode()和equals()进行判断可以提高判断的效率。
首先,我们回忆一下什么是hashcode。
https://www.cnblogs.com/dolphin0520/p/3681042.html
hashCode()是Object的类,每个对象都具有hashCode值。不同的对象可能会有相同的hashCode值,但hashCode值不相同的两个对象肯定不同。
我们可以用映射的概念来理解对象与hashCode之间的关系,对象(value)与hashCode(key)构成了多对一的映射。
当每次存储新的元素时,首先通过hashCode()获得新元素的hashCode,判断是否与已有元素的hashCode相同。如果没有,将新元素加入到集合中。如果有,再通过equals()判断元素是否相同,如果相同,则不添加该元素,如果不同,则把该元素加到集合中。
3.1 HashSet
HashSet元素存储的结构是哈希表。
hashSet除了不允许重复元素外,还不能保证元素存取的顺序。
例如:
import java.util.HashSet;
import java.util.Iterator; public class setDemo1 {
public static void main(String[] args) {
HashSet<String> hash=new HashSet<String>();
hash.add("11");
hash.add("22");
hash.add("33");
Iterator<String> it=hash.iterator();
while(it.hasNext()){
System.out.print(it.next()+" ");
}
System.out.println(""); //output: 22 33 11
}
}
不能保证存取顺序
hashCode()和equals()的重写
就像我们刚才提到的,hashSet是通过hashCode()和equals()来保证元素的唯一性。JaveAPI中的每个类(如String, Integer类)都能获得hashCode和equals的比较方法,所以这类元素可以直接用hashSet存储,但是用户自定义的类,也需要先重写hashCode()和equals(),之后才能用hashSet存储该类元素。
*Object的equals()与==功能相同,判断的是地址是否相同。所以想要判断内容是否相同,必须要重写equals(),比如String类。
例如:
//用户自定义类
public class Student {
private int id;
private String name;
private int age;
//构造方法
public Student() {
// TODO Auto-generated constructor stub
}
public Student(int id,String name,int age){
this.id=id;
this.name=name;
this.age=age;
}
//getter and setter
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//overwrite hashCode() and equals()
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + id;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (id != other.id)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
//overwrite toString()
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + ", age=" + age + "]";
}
} //hashSet分别存储JavaAPI类和用户自定义类
import java.util.HashSet;
import java.util.Iterator; public class setDemo1 {
public static void main(String[] args) {
//用HashSet存储JavaAPI类,如String、Integer等
HashSet<String> hash=new HashSet<String>();
hash.add("11");
hash.add("22");
hash.add("33");
hash.add("22");
Iterator<String> it=hash.iterator();
while(it.hasNext()){
System.out.print(it.next()+" ");
}
/*
* 不允许重复元素
* 不保证存取顺序
*/
System.out.println(""); //output: 22 33 11
//用HashSet存储用户自定义类
//首先在用户自定义类中需要重写hashCode()和equals()
HashSet<Student> hash2=new HashSet<Student>();
Student s1=new Student(001,"zhangsan",22);
Student s2=new Student(002,"lisi",21);
Student s3=new Student(003,"wangwu",18);
hash2.add(s1);
hash2.add(s2);
hash2.add(s3);
hash2.add(s1);
Iterator<Student> it2=hash2.iterator();
while(it2.hasNext()){
System.out.println(it2.next()+" ");
}
/*
* output:
* Student [id=3, name=wangwu, age=18]
* Student [id=1, name=zhangsan, age=22]
* Student [id=2, name=lisi, age=21]
*/
}
}
3.2 LinkedHashSet
LinkedHashSet的元素的存储结构是链表和哈希表。
LinkedHashSet保证了元素存取的顺序。
*LinkedHashSet遵循先进先出的顺序
例如:
import java.util.Iterator;
import java.util.LinkedHashSet; public class setDemo2 {
public static void main(String[] args) {
LinkedHashSet<String> lset=new LinkedHashSet<String>();
lset.add("11");
lset.add("22");
lset.add("33");
Iterator<String> it=lset.iterator();
while(it.hasNext()){
System.out.print(it.next()+" ");
}
System.out.println(""); //output: 11 22 33
}
}
3.3 TreeSet
TreeSet可以保证元素存取的顺序。
参考文献
https://docs.oracle.com/javase/7/docs/api/java/util/List.html
https://www.cnblogs.com/dolphin0520/p/3681042.html
https://www.cnblogs.com/jmsjh/p/7740123.html
Java基础知识:Collection接口的更多相关文章
- Java基础知识回顾之七 ----- 总结篇
前言 在之前Java基础知识回顾中,我们回顾了基础数据类型.修饰符和String.三大特性.集合.多线程和IO.本篇文章则对之前学过的知识进行总结.除了简单的复习之外,还会增加一些相应的理解. 基础数 ...
- Java基础知识总结(超级经典)
Java基础知识总结(超级经典) 写代码: 1,明确需求.我要做什么? 2,分析思路.我要怎么做?1,2,3. 3,确定步骤.每一个思路部分用到哪些语句,方法,和对象. 4,代码实现.用具体的java ...
- 毕向东—Java基础知识总结(超级经典)
Java基础知识总结(超级经典) 写代码: 1,明确需求.我要做什么? 2,分析思路.我要怎么做?1,2,3. 3,确定步骤.每一个思路部分用到哪些语句,方法,和对象. 4,代码实现.用具体的java ...
- 沉淀,再出发:Java基础知识汇总
沉淀,再出发:Java基础知识汇总 一.前言 不管走得多远,基础知识是最重要的,这些知识就是建造一座座高楼大厦的基石和钢筋水泥.对于Java这门包含了编程方方面面的语言,有着太多的基础知识了,从最初的 ...
- Java基础知识常识总结
Java基础知识常识总结 1.面向对象的特征以及对他的理解? 封装,继承,多态,如果再增加一条就是抽象. 2.Object有几种方法,分别是什么? 在JDK1.5中的11种方法,分别有: toStri ...
- java基础知识一览(二)
一.java基础知识 1.一个文件中只能有一个public的类,因为他的类名要求和文件名相同. 2.classpath变量可以设置其它目录下的类. 例如:类文件所在目录是:F:\Javajdk,那么没 ...
- 黑马毕向东Java基础知识总结
Java基础知识总结(超级经典) 转自:百度文库 黑马毕向东JAVA基础总结笔记 侵删! 写代码: 1,明确需求.我要做什么? 2,分析思路.我要怎么做?1,2,3. 3,确定步骤.每一个思路部 ...
- JAVA基础知识|lambda与stream
lambda与stream是java8中比较重要两个新特性,lambda表达式采用一种简洁的语法定义代码块,允许我们将行为传递到函数中.之前我们想将行为传递到函数中,仅有的选择是使用匿名内部类,现在我 ...
- Java基础知识(壹)
写在前面的话 这篇博客,是很早之前自己的学习Java基础知识的,所记录的内容,仅仅是当时学习的一个总结随笔.现在分享出来,希望能帮助大家,如有不足的,希望大家支出. 后续会继续分享基础知识手记.希望能 ...
- java基础知识小总结【转】
java基础知识小总结 在一个独立的原始程序里,只能有一个 public 类,却可以有许多 non-public 类.此外,若是在一个 Java 程序中没有一个类是 public,那么该 Java 程 ...
随机推荐
- P1868 饥饿的奶牛
题目描述 有一条奶牛冲出了围栏,来到了一处圣地(对于奶牛来说),上面用牛语写着一段文字. 现用汉语翻译为: 有N个区间,每个区间x,y表示提供的x~y共y-x+1堆优质牧草.你可以选择任意区间但不能有 ...
- linux下的tomcat开机自启动(亲测),更改静态ip
开机自启动Tomcat: 1.修改脚本文件rc.local:vim /etc/rc.d/rc.local 这个脚本是使用者自定的开机启动程序,可以在里面添加想在系统启动之后执行的脚本或者脚本执行命令 ...
- 构建第一个spring boot2.0应用之项目启动运行的几种方式(二)
方法一. 配置Run/Debug Configuration 选择Main Class为项目 Application启动类(入口main方法) (2).进行项目目录,即包含pom.xml的目录下,启 ...
- 在ActionBar中,即便设置showAsAction="always",items仍然在overflow中显示的问题
今天很是苦恼,明明设置了android:showAsAction="always",但是所有的items全部都显示在overflow中,然后在官网发现了答案. 如果你为了兼容 An ...
- python3基础06(随机数的使用)
#!/usr/bin/env python# -*- coding:utf-8 -*- import osimport randomimport string la=[0,1,2,3,4,5,6,7, ...
- 允许被ping设置方法
参考下图设置:
- jquery实现加载更多效果
情况是当滑动条滑动到最底部的时候,数据显示出一部分的更多 思路:获取到浏览器屏幕的高度client,文档的高度h和滑动距离顶部的距离scroll,当h<=client+scroll的时候就是滑动 ...
- noip模拟赛#42
T1:给len=1e5的数字串,操作为将某个位置起始的后缀搬到最前面.求有多少个不重复的比原串大和多少个小. =>maya这铁定可以找出些什么规律来.然后就over 了. =>字符串has ...
- 自动释放池的前世今生 ---- 深入解析 autoreleasepool
http://draveness.me/autoreleasepool.html 关注仓库,及时获得更新:iOS-Source-Code-Analyze Follow: Draveness · Git ...
- 动态规划专题(四)——单调队列优化DP
前言 单调队列优化\(DP\)应该还算是比较简单容易理解的吧,像它的升级版斜率优化\(DP\)就显得复杂了许多. 基本式子 单调队列优化\(DP\)的一般式子其实也非常简单: \[f_i=max_{j ...