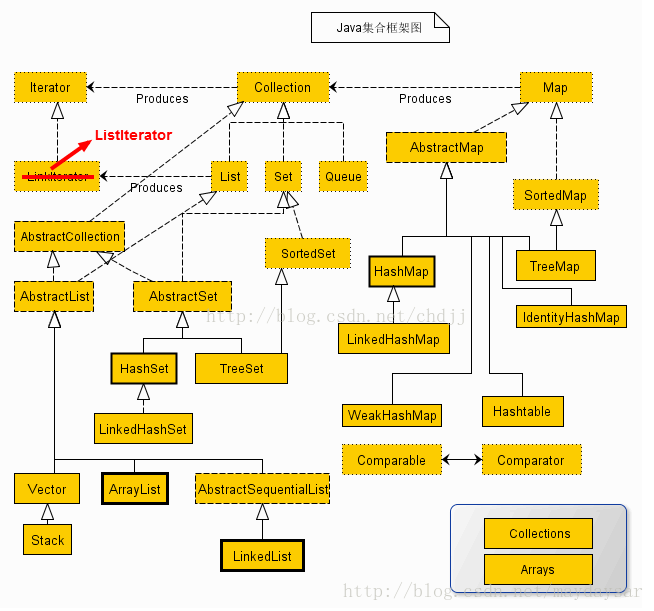
Java集合框架汇总
HashMap是一个最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为NULL,允许多条记录的值为NUll。HashMap不支持线程的同步,即任意时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。
1)HashMap的默认大小为16,即桶数组的默认长度为16。
2)HashMap的默认装载因子为0.75。
3)HashMap内部的桶数组存储的是Entry对象,也就是键值对对象。
4)构造器支持指定初始容量和装载因子,为避免数组扩容带来的性能问题,建议根据需求指定初始容量。装载因子尽量不要修改,0.75是个比较靠谱的值。
5)桶数组的长度始终是2的整数次方(大于等于指定的初始容量),这样做可以减少冲突概率,提高查找效率。
6)HashMap接受null键。
7)HashMap不允许键重复,但是值可以重复,若键重复,那么新值会覆盖旧值。
8)HashMap通过链表法解决冲突问题,每个Entry都有一个next指针指向下一个Entry,冲突元素(不是键相同,而是hash值相同)会构成一个链表。
9)当容量超过阈值(threshold为16*0.75)时,会发生扩容,扩容后的数组是原数组的两倍。扩容操作需要开辟新数组,并对原数组中所有键值对重新散列,非常耗时。我们应该尽量避免HashMap扩容。
10)HashMap非线程安全。Hashtable与HashMap类似,它继承自Dictionary类,不同的是,它不允许记录的键或者值为空;它支持线程的同步即任意时刻只有一个线程能写Hashtable,因此也导致了Hashtable在写入时会较慢;和HashMap一样,Hashtable取得数据的顺序也是无序的。
1)Hashtable是线程安全的类(HashMap非线程安全)。
2)Hashtable并不允许键和值为空(null),若为空,会抛出空指针(HashMap可以)。
3)Hashtable不允许键重复,若键重复,则新插入的值会覆盖旧值(同HashMap)。
4)Hashtable同样是通过链表法解决冲突的。
5)Hashtable根据hashcode计算索引时将hashcode值先与上0x7FFFFFFF,折是为了保证hash值始终为正数。
6)Hashtable的容量为任意正数(最小为1),而HashMap的容量始终为2的n次方。Hashtable默认容量为11,HashMap的默认容量为16。
7)Hashtable每次扩容,新容量为旧容量的2倍加2,而HashMap为旧容量的2倍。
8)Hashtable和HashMap默认负载因子都为0.75。LinkedHashMap
1)LinkedHashMap继承自HashMap,具有HashMap的大部分特性,比如支持null键和值,默认容量为16,装载因子为0.75,非线程安全等等。
2)LinkedHashMap通过设置accessOrder控制遍历顺序是按照插入顺序(默认为false)还是按照访问顺序。当accessOrder为true时,可以利用其完成LRU缓存的功能。
3)LinkedHashMap内部维护了一个双向循环链表,并且其迭代操作是通过链表完成的,而不是去遍历hash表。TreeMap实现SortMap接口,取出来的是排序后的键值对。但如果您要按自然顺序(默认,但是传入的类必须实现comparable借口,否则抛出ClassCastException)或自定义顺序(传入比较器)遍历键,那么TreeMap会更好。
1)TreeMap的实现基于红黑树。
2)TreeMap不允许插入null键,但允许null值。
3)TreeMap线程不安全。
4)插入结点时,若键重复,则新值覆盖旧值。
5)TreeMap要求Key必须实现Comparable接口,或者初始化时传入Comparator比较器。
6)遍历TreeMap得到的结果集是有序的(中序遍历);(红黑树是一种二叉排序树,而且是平衡树,中序遍历结果就是自然排序结果)。
7)TreeMap的各项操作的平均时间复杂度为O(logn)。HashSet,TreeSet,LinkedHashSet分别建立了一个对应的HashMap,TreeMap,LinkedHashMap的实例,value存放的是同一个new Object(),方法完全调用对应Map的方法。
StringBuffer和StringBuilder
1)StringBuilders jdk1.5引进的,而StringBuffer在1.0就有了。
2)StringBuilder和StingBuffer都是可变的字符串,可以通过append或者insert等方法修改串的内容。
3)StingBuffer是线程安全的,而StringBuilder不是,因而在多线程的环境下优先使用StringBuffer,而其他情况下推荐使用StringBuilder,因为它更快。
4)StringBuilder和StringBuffer都继承自AbstractStingBuilder类,AbstractStringBuilder主要实现了扩容、append、inset方法,StringBuilder和StringBuffer的相关方法都直接调用的父类。
5)StringBuilder和StringBuffer的初始容量都是16,程序员尽量手动设置初始值,以避免多次扩容所带来的性能问题。
6)StringBuilder和StringBuffer的扩容机制:首先试着将当前数组容量扩充为原数组容量的2倍加上2,如果这个新容量仍然小于预定的最小值(minimunCapacity),那么久将新容量定为(minimumCapacity),最后判断是否溢出,若溢出,则将容量定位整型的最大值0x7fffffff。ArrayList
1)ArrayList内部是通过一个Object数组实现的,当数组填满之后会根据需要进行扩容
2)最好预估ArrayList的大小,并设置其初始容量,以避免不必要的扩容所造成的性能问题。
3)ArrayList的初始容量是10,ArrayList每次扩容都将容量变为原来的1.5倍,若还小于所需的最小值,那么直接分配容量为所需值。
4)ArrayList线程不安全,允许空(null)的元素。
5)ArrayList内部有两个内部类,分别实现Iterator和ListIterator,定义了迭代的规则。LinkedList
1)LinkedList内部通过双向链表实现。
2)LinkedList线程不安全,支持null元素。
3)LinkedList插入删除元素较方便,但是查找操作较耗时(对比ArrayList),虽然内部进行的优化(根据位置选择顺序还是逆序遍历,小于size>>2从头开始顺序查找,否则从末尾开始查找)。
4)LinkedList内部同样通过内部类的形式实现了迭代器(仅实现了ListIterator,iterator方法返回的也是ListIterator对象)。
5)LinkedList实现了Deque接口,可以当成栈,队列,双端队列来使用。Vector和Stack
1)Vector是线程安全的类而ArrayList不是;
2)Vector的扩容基于扩容增量,若扩容增量不为0。每次扩容的大小都为原始容量加上扩容增量,若扩容增量为0,也就是默认的情况下,扩容大小为元素容量的两倍。
3)Vector默认大小为10。
4)Vector支持null(ArrayList也可以)。
5)Vector出来可以使用listIterator和iterator遍历集合,也可以使用Enumeration的方法遍历。
6)Stack类继承了Vector,并封装了栈的操作,同时也是一个线程安全的类。
7)从性能上看,推荐使用ArrayList和LinkedList而不使用Vector和Stack。8)HashSet:底层实现是一个HashMap,把值存在map的key上,value存的是一个object对象,就是说底层的HashMap中value都是一样的。
9)LinkedHashSet:基于HashSet,底层实现是一个LinkedHashMap,通过equals()方法比较两个对象是否相等,初始容量16,加载因子0.75。
使用链表维护数据的顺序,所以说是有序的,不重复的,对象都是存在底层map的key上,所有允许有且只有一个对象为null。
Collection和Collections的区别
java.util.Collection 是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式。
java.util.Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,服务于Java的Collection框架。
转自:http://svenliu.blog.163.com/blog/static/262873054201681743834691/
———-这是分割线———
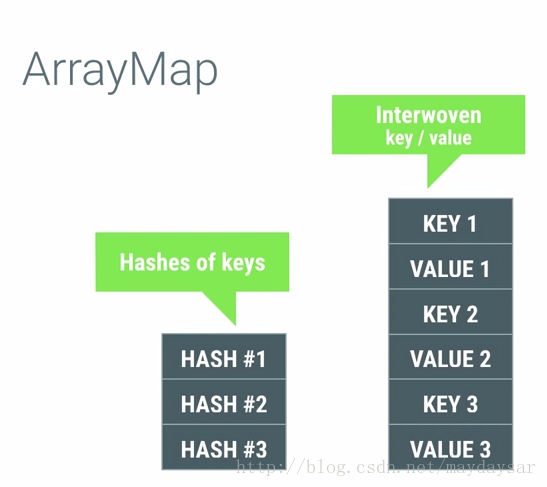
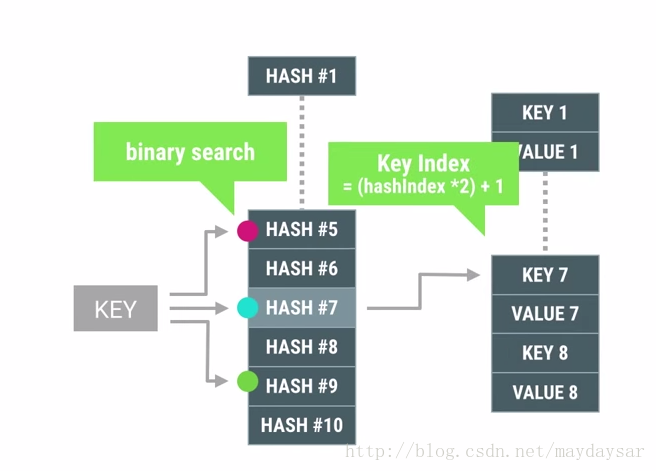
ArrayMap:他用两个数组来模拟Map,第一个数组存放存放item的hash值,第二数组是把key,value连续的存放在数组里,通过先算hash在第一个数组里找到它的hash index,根据这个index在去第二个数组里找到这个key-value。
在这里,在第一个数组里查找hash index的方法当然是用二分查找啦(binary search)。
这个数据结构的设计就做到了,有多个item我就分配多少内存,做到了memory的节约。并且因为数据结构是通过数组组织的,所以遍历的时候可以用index直接遍历也是很方便的有没有!但是缺点也很明显,查找达不到HashMap O(1)的查找时间。
当要存储的对象较少的时候(1000以下的时候)可以考虑用ArrayMap来减少内存的占用。
Java集合框架汇总的更多相关文章
- Java集合框架,你了解多少?相信你看了这篇汇总一目了然!
相信大多数的程序员都知道,Dictionary.Vertor.Stack和Properties这些类被用来存储和操作对象组.但是他们缺少一个核心的主题的. 集合框架设计成要满足以下的几个目标 第一条: ...
- Java集合框架总结—超详细-适合面试
Java集合框架总结—超详细-适合面试 一.精简: A.概念汇总 1.Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口, ...
- Java - 27 Java 集合框架
Java 集合框架 早在Java 2中之前,Java就提供了特设类.比如:Dictionary, Vector, Stack, 和Properties这些类用来存储和操作对象组. 虽然这些类都非常有用 ...
- Java-Runoob-高级课程:Java 集合框架
ylbtech-Java-Runoob-高级课程:Java 集合框架 1.返回顶部 1. Java 集合框架 早在 Java 2 中之前,Java 就提供了特设类.比如:Dictionary, Vec ...
- 一起学 Java集合框架、数据结构、泛型
一.Java 集合框架 集合框架是一个用来代表和操纵集合的统一架构.所有的集合框架都包含如下内容: 接口:是代表集合的抽象数据类型.接口允许集合独立操纵其代表的细节.在面向对象的语言,接口通常形成一个 ...
- 20180826(02)-Java集合框架
Java 集合框架 早在Java 2中之前,Java就提供了特设类.比如:Dictionary, Vector, Stack, 和Properties这些类用来存储和操作对象组. 虽然这些类都非常有用 ...
- Java集合框架(不全,待继续整理)
技术在线学习网站: https://www.runoob.com/java/java-collections.html 从上面的集合框架图可以看到: 1.Java 集合框架主要包括两种类型的容器: 1 ...
- Java集合框架List,Map,Set等全面介绍
Java集合框架的基本接口/类层次结构: java.util.Collection [I]+--java.util.List [I] +--java.util.ArrayList [C] +- ...
- Java集合框架练习-计算表达式的值
最近在看<算法>这本书,正好看到一个计算表达式的问题,于是就打算写一下,也正好熟悉一下Java集合框架的使用,大致测试了一下,没啥问题. import java.util.*; /* * ...
随机推荐
- python学习四(处理数据)
head first python中的一个数据处理的例子 有四个U10选手的600米成绩,请取出每个选手跑的最快的3个时间.以下是四位选手的9次成绩 James 2-34,3:21,2.34,2.45 ...
- Storm概念学习系列之storm的特性
不多说,直接上干货! storm的特性 Storm 是一个开源的分布式实时计算系统,可以简单.可靠地处理大量的数据流. Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快 ...
- 2 - Bootstrap-引导类-Bootstrap/ServerBootstrap
2.1 ChannelOption和属性 //设置属性 bootstrap.option("xxx", 1231231); bootstrap.attr("xxx&quo ...
- CentOS-7.5 解决ifconfig报错
1.报错信息:-bash: ifconfig: command not found 2.检查IP地址是否设置正常 ip addr 以上说明ip设置正常,如果没有获取到IP地址则设置一个即可,设置i ...
- Redis中String类型的Value最大可以容纳数据长度
项目中使用redis存储,key-value方式,在Redis中字符串类型的Value最多可以容纳的数据长度是512M 官方信息: A String value can be at max 512 M ...
- chart.js 使用方法 特别说明不是中文的
以上是一个饼图的案例,其他统计类型查看文档 http://www.chartjs.org/docs/latest/charts/doughnut.html 注意看域名 chartjs.org 不是 ...
- ArcSDE空间数据库中SDE用户使用探讨 (转载)
ArcSDE作为空间数据库解决方案,应用非常广泛,本短文将尝试描述SDE的工作机制,简要说明空间数据库中SDE用户的使用方法.ArcSDE如何工作ArcSDE属于中间件技术,其本身并不能够存储空间数据 ...
- JSON.parse() 和 JSON.stringify()的简单介绍
参考地址: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse ht ...
- Callable的简单使用
说起java的线程操作,都会想到Thread和Runable这两个, 这两个类可以实现异步和同步. 在大多数的java开发中, 这两个都是实现异步的线程来使用, 但是现在考虑一种情况: 发出一条线程, ...
- iOS中UIWebview中网页宽度自适应的问题
有的网页中会使用"<meta name="viewport" content="width=device-width, initial-scale=1.0 ...