SPA路由机制详解(看不懂不要钱~~)
前言
总所周知,随着前端应用的业务功能起来越复杂,用户对于使用体验的要求越来越高,单面(SPA)成为前端应用的主流形式。而大型单页应用最显著特点之一就是采用的前端路由跳转子页面系统,通过改变页面的URL,在不重新请求页面的情况下,更新页面视图。
更新视图但是浏览器不重新渲染整个页面,只是重新渲染部分子页面,加载速度快,页面反应灵活,这是 SPA 的优势,这也是前端路由原理的核心,这会给人一种仿佛在操作 APP 一样的感觉,目前在浏览器环境中实现这一功能的方式主要有两种:
- 利用
URL的hash(#) - 利用
H5新增方法History interface
利用URL的Hash(#)
在 H5 还没有流行开来时,一般 SPA 都采用 url 的 hash(#) 作为锚点,获取到 # 之后的值,并监听其改变,再进行渲染对应的子页面。网易云音乐官网就是利用的此技术。
例如,你的地址为http://localhost:8888/#/abc 那么利用 location.hash 输出的内容就为 #/abc。
那么我就先从 location 这个对象说起。
先来看看location的官方属性有哪些
| 属性 | 描述 |
|---|---|
| hash | 设置或返回从 # 开始的 URL (锚) |
| host | 设置或返回主机名和当前 URL 的端口号 |
| hostname | 设置或返回当前 URL 的主机名 |
| href | 设置或返回完整的 URL |
| pathname | 设置或返回当前 URL 的路径部分 |
| port | 设置或返回当前 URL 的端口号 |
| protocol | 设置或返回当前 URL 的协议 |
| search | 设置或返回从 ? 开始的 URL 部分 |
由上表格可以知道,我们可以轻易的获取到 # 之后的部分,那么拿到这个部分我们怎么监听其变化以及对应的子页面进行改变呢?
window 对象中有一个事件是专门监听hash的变化,那就是onhashchange,首先我们需要监听此事件:
<body>
<h1 id="id"></h1>
<a href="#/id1">id1</a>
<a href="#/id2">id2</a>
<a href="#/id3">id3</a>
</body>
<script>
window.addEventListener('hashchange', e => {
e.preventDefault()
document.querySelector('#id').innerHTML = location.hash
})
</script>
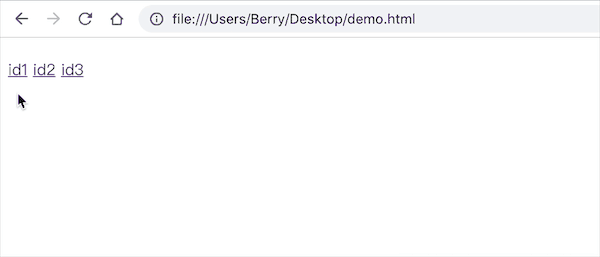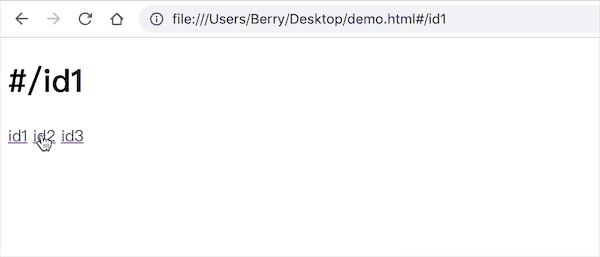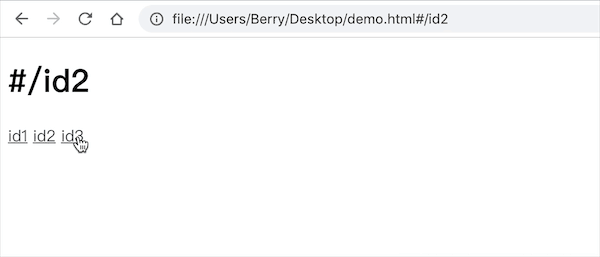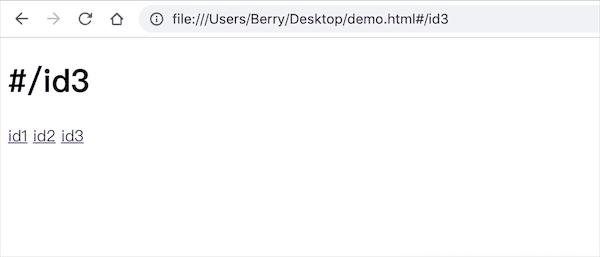
可见此时我们已经完全监听到了 URL 的变化,页面上的内容也对应改变了。
那么,该如何载入不同的页面呢,目前来说有三种方式:
- 寻找节点内容并改变(也就是上面我们演示的内容)
import一个JS文件,文件内部export模版字符串- 利用
AJAX加载对应的HTML模版
第一种方式已经演示过,不过这种方式局限性太大,下面我会演示另外两种方式加载页面。
import 方式
定义一个 JS 文件,名为 demo1.js,在里面输入内容:
const str = `
<div>
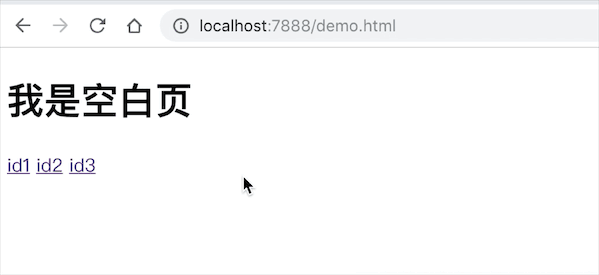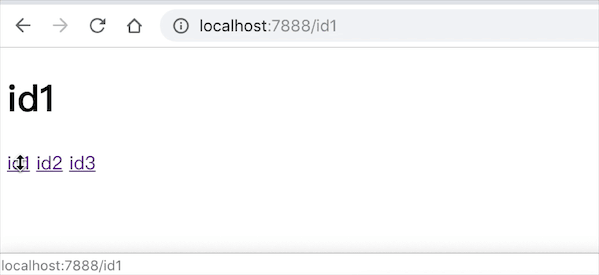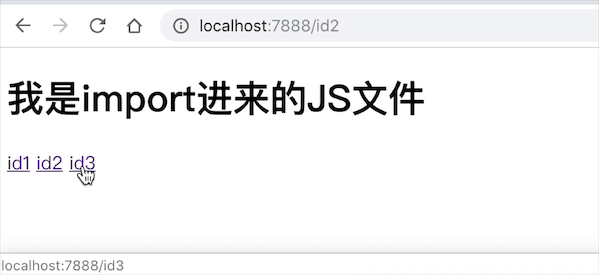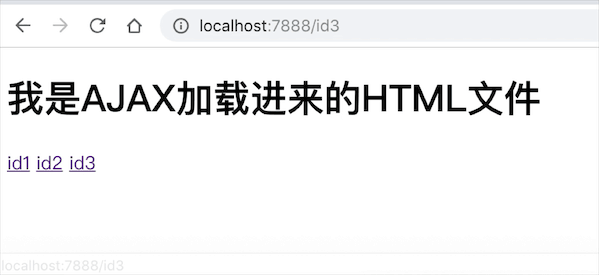
我是import进来的JS文件
</div>
`
export default str
在主文件里 import 进来,并进行测试(使用 Chrome 一定要使用服务器开启,或者直接用火狐打开):
<body>
<h1 id="id"></h1>
<a href="#/id1">id1</a>
<a href="#/id2">id2</a>
<a href="#/id3">id3</a>
</body>
<!-- 在 HTML 导入文件记得要加上 type="module" -->
<script type="module">
import demo1 from './demo1.js'
document.querySelector('#id').innerHTML = demo1
window.addEventListener('hashchange', e => {
e.preventDefault()
document.querySelector('#id').innerHTML = location.hash
})
</script>
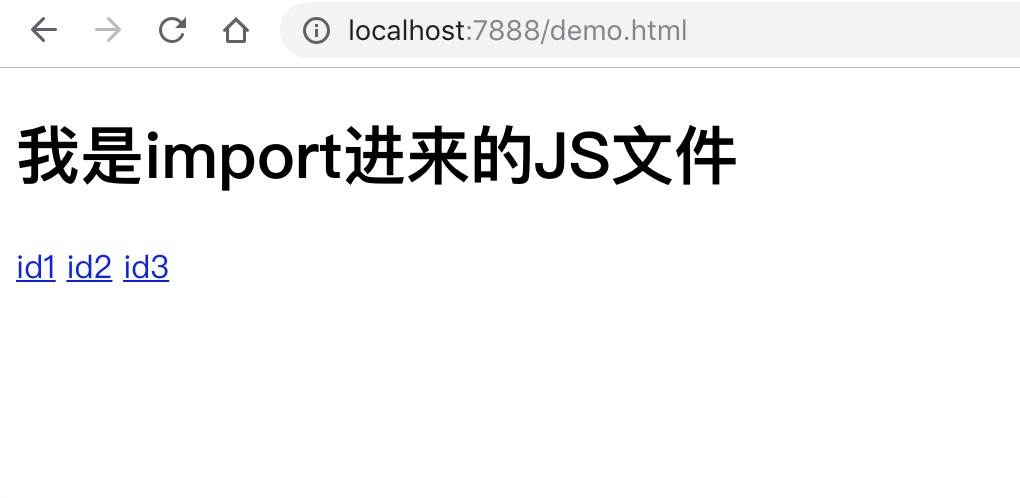
可见导入文件已经生效,目前大部分框架编译过后是采用类似此种方式处理。
例如,vue 框架,.vue 文件是一个自定义的文件类型,用类 HTML 语法描述一个 Vue 组件。每个 .vue 文件包含三种类型的顶级语言块 <template>, <script> 和 <style>,vue-loader 会解析文件,提取每个语言块,如有必要会通过其它 loader 处理,最后将他们组装成一个 CommonJS 模块,module.exports 出一个 Vue.js 组件对象。。
AJAX 方式
本篇文章是详解路由机制,AJAX 就直接采用 JQuery 这个轮子。
定义一个 HTML 文件,名为 demo2.html,在里面写入一些内容(由于主页面已经有head,body等根标签,此文件只需写入需要替换的标签):
<div>
我是AJAX加载进来的HTML文件
</div>
我们在主文件里写入,并进行测试:
<body>
<h1 id="id"></h1>
<a href="#/id1">id1</a>
<a href="#/id2">id2</a>
<a href="#/id3">id3</a>
</body>
<script src="https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js"></script>
<script type="module">
// import demo1 from './demo1.js'
// document.querySelector('#id').innerHTML = demo1
$.ajax({
url: './demo2.html',
success: (res) => {
document.querySelector('#id').innerHTML = res
}
})
window.addEventListener('hashchange', e => {
e.preventDefault()
document.querySelector('#id').innerHTML = location.hash
})
</script>
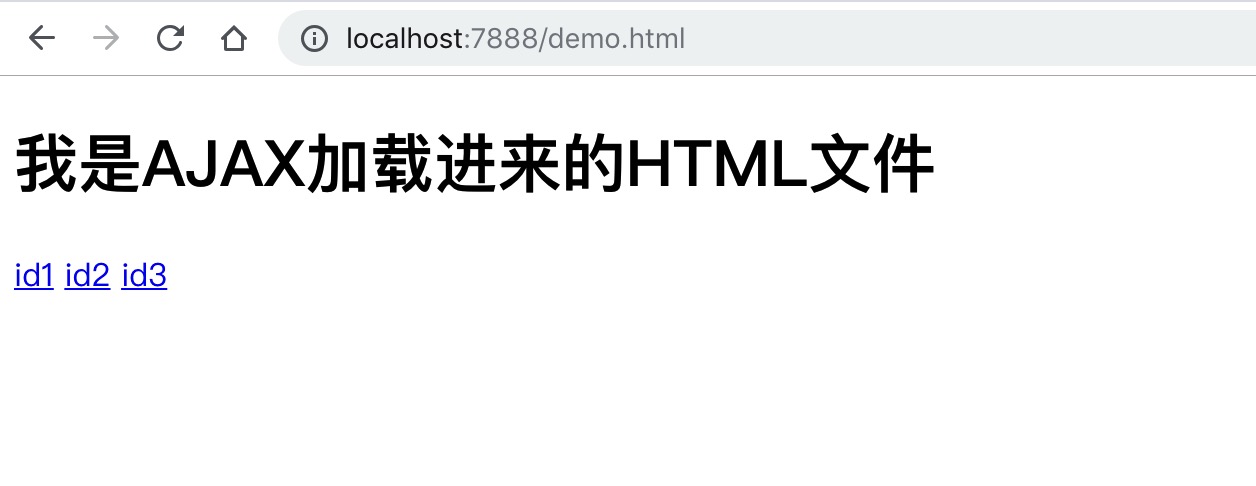
可见,利用 AJAX 加载进来的文件也已经生效。
既然加载不同页面的内容都已经生效,那么只需要包装一下我们的监听,利用观察者模式封装路由的变化:
<body>
<h1 id="id">我是空白页</h1>
<a href="#/id1">id1</a>
<a href="#/id2">id2</a>
<a href="#/id3">id3</a>
</body>
<script type="module">
import demo1 from './demo1.js'
// 创建一个 newRouter 类
class newRouter {
// 初始化路由信息
constructor() {
this.routes = {};
this.currentUrl = '';
}
// 传入 URL 以及 根据 URL 对应的回调函数
route(path, callback = () => {}) {
this.routes[path] = callback;
}
// 切割 hash,渲染页面
refresh() {
this.currentUrl = location.hash.slice(1) || '/';
this.routes[this.currentUrl] && this.routes[this.currentUrl]();
}
// 初始化
init() {
window.addEventListener('load', this.refresh.bind(this), false);
window.addEventListener('hashchange', this.refresh.bind(this), false);
}
}
// new 一个 Router 实例
window.Router = new newRouter();
// 路由实例初始化
window.Router.init();
// 获取关键节点
var content = document.querySelector('#id');
Router.route('/id1', () => {
content.innerHTML = 'id1'
});
Router.route('/id2', () => {
content.innerHTML = demo1
});
Router.route('/id3', () => {
$.ajax({
url: './demo2.html',
success: (res) => {
content.innerHTML = res
}
})
});
</script>
效果如下:
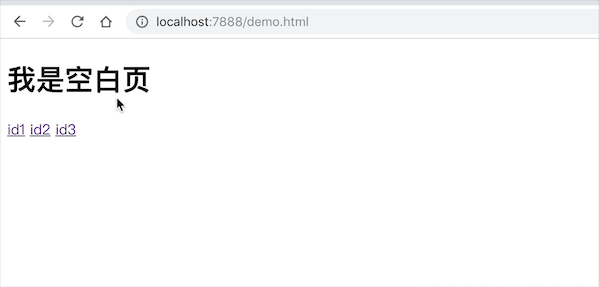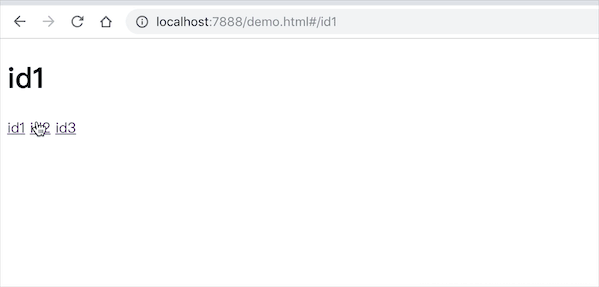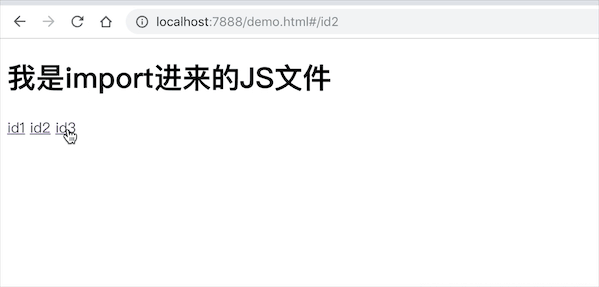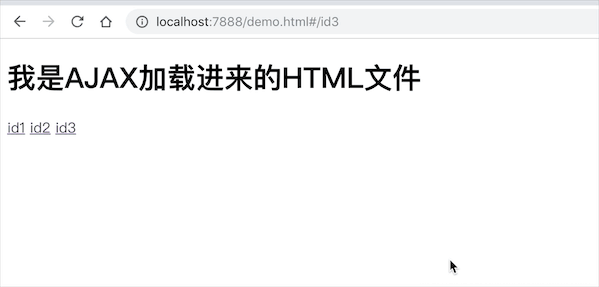
至此,利用 hash(#) 进行前端路由管理都已实现。
利用 H5 新增方法 History interface
上面使用的 hash 法实现路由固然不错,但是问题就是实在太丑~ 如果在微信或者其他不显示 URL 的 APP 中使用,倒也无所谓,但是如果在一般的浏览器中使用就会遇到问题了。
由此,H5 的 History 模式,解决了这一问题。
在 H5 之前, History 仅仅只有一下几个 API:
| API | 说明 |
|---|---|
back() |
回退到上次访问的 URL (与浏览器点击后退按钮相同) |
forward() |
前进到回退之前的 URL (与浏览器点击向前按钮相同) |
go(n) |
n 接收一个整数,移动到该整数指定的页面,比如go(1)相当于forward(),go(-1) 相当于 back(),go(0)相当于刷新当前页面 |
如果移动的位置超出了访问历史的边界,以上三个方法并不报错,而是静默失败。
然而,到了 H5 的时代,新的 H5 则赋予了其更多的新特性:
往返缓存
默认情况下,浏览器会缓存当前会话页面,这样当下一个页面点击后退按钮,或前一个页面点击前进按钮,浏览器便会从缓存中提取并加载此页面,这个特性被称为“往返缓存”。
PS: 此缓存会保留页面数据、DOM和js状态,实际上是将整个页面完好无缺地保留。
往历史记录栈中添加记录:pushState(state, title, url)
浏览器支持度: IE10+
- state: 一个
JS对象(不大于640kB),主要用于在popstate事件中作为参数被获取。如果不需要这个对象,此处可以填null - title: 新页面的标题,部分浏览器(比如 Firefox )忽略此参数,因此一般为
null - url: 新历史记录的地址,可为页面地址,也可为一个锚点值,新
url必须与当前url处于同一个域,否则将抛出异常,此参数若没有特别标注,会被设为当前文档url
栗子:
// 现在是 localhost/1.html
const stateObj = { foo: 'bar' };
history.pushState(stateObj, 'page 2', '2.html');
// 浏览器地址栏将立即变成 localhost/2.html
// 但!!!
// 不会跳转到 2.html
// 不会检查 2.html 是否存在
// 不会在 popstate 事件中获取
// 不会触发页面刷新
// 这个方法仅仅是添加了一条最新记录
除此之外,仍有几点需要注意:
- 将
url设为锚点值时不会触发hashchange - 根据同源策略,如果设置不同域名地址,会报错,这样做的目的是:防止用户以为它们是同一个网站,若没有此限制,将很容易进行
XSS、CSRF等攻击方式
改变当前的历史记录:replaceState(state, title, url)
浏览器支持度: IE10+
- 参数含义同
pushstate - 改变当前的历史记录而不是添加新的记录
- 同样不会触发
popstate
history.state
浏览器支持度: IE10+
- 返回当前历史记录的
state。
popstate
定义:每当同一个文档的浏览历史(即 history 对象)出现变化时,就会触发 popstate 事件。
注意:若仅仅调用 pushState 方法或 replaceState 方法 ,并不会触发该事件,只有用户点击浏览器倒退按钮和前进按钮,或者使用 JavaScript 调用 back 、 forward 、 go 方法时才会触发。另外,该事件只针对同一个文档,如果浏览历史的切换,导致加载不同的文档,该事件也不会触发。
栗子:
window.onpopstate= (event) => {
console.log(event.state) //当前历史记录的state对象
}
实现
了解了这么多内容,那么就让我们开始实现 History 模式的路由吧!
我们将上面的 HTML 稍稍改造下,请大家耐心分析:
<body>
<h1 id="id">我是空白页</h1>
<a class="route" href="/id1">id1</a>
<a class="route" href="/id2">id2</a>
<a class="route" href="/id3">id3</a>
</body>
import demo1 from './demo1.js'
// 创建一个 newRouter 类
class newRouter {
// 初始化路由信息
constructor() {
this.routes = {};
this.currentUrl = '';
}
route(path, callback) {
this.routes[path] = (type) => {
if (type === 1) history.pushState( { path }, path, path );
if (type === 2) history.replaceState( { path }, path, path );
callback()
};
}
refresh(path, type) {
this.routes[this.currentUrl] && this.routes[this.currentUrl](type);
}
init() {
window.addEventListener('load', () => {
// 获取当前 URL 路径
this.currentUrl = location.href.slice(location.href.indexOf('/', 8))
this.refresh(this.currentUrl, 2)
}, false);
window.addEventListener('popstate', () => {
this.currentUrl = history.state.path
this.refresh(this.currentUrl, 2)
}, false);
const links = document.querySelectorAll('.route')
links.forEach((item) => {
// 覆盖 a 标签的 click 事件,防止默认跳转行为
item.onclick = (e) => {
e.preventDefault()
// 获取修改之后的 URL
this.currentUrl = e.target.getAttribute('href')
// 渲染
this.refresh(this.currentUrl, 2)
}
})
}
}
// new 一个 Router 实例
window.Router = new newRouter();
// 实例初始化
window.Router.init();
// 获取关键节点
var content = document.querySelector('#id');
Router.route('/id1', () => {
content.innerHTML = 'id1'
});
Router.route('/id2', () => {
content.innerHTML = demo1
});
Router.route('/id3', () => {
$.ajax({
url: './demo2.html',
success: (res) => {
content.innerHTML = res
}
})
});
演示图如下所示:
总结
一般场景下,hash 和 history 都可以,除非你更在意颜值,# 符号夹杂在 URL 里看起来确实有些不太美丽。
另外,根据 Mozilla Develop Network 的介绍,调用 history.pushState() 相比于直接修改 hash,存在以下优势:
pushState()设置的新URL可以是与当前URL同源的任意URL;而hash只可修改#后面的部分,因此只能设置与当前URL同文档的URLpushState()设置的新URL可以与当前URL一模一样,这样也会把记录添加到栈中;而hash设置的新值必须与原来不一样才会触发动作将记录添加到栈中pushState()通过stateObject参数可以添加任意类型的数据到记录中;而hash只可添加短字符串;pushState()可额外设置title属性供后续使用。
这么一看 history 模式充满了 happy,感觉完全可以替代 hash 模式,但其实 history 也不是样样都好,虽然在浏览器里游刃有余,但真要通过 URL 向后端发起 HTTP 请求时,两者的差异就来了。尤其在用户手动输入 URL 后回车,或者刷新(重启)浏览器的时候。
hash模式下,仅hash符号之前的内容会被包含在请求中,如http://www.qqq.com,因此对于后端来说,即使没有做到对路由的全覆盖,也不会返回404错误。history模式下,前端的URL必须和实际向后端发起请求的URL一致,如http://www.qqq.com/book/id。如果后端缺少对/book/id的路由处理,将返回404错误。Vue-Router官网里如此描述:“不过这种模式要玩好,还需要后台配置支持……所以呢,你要在服务端增加一个覆盖所有情况的候选资源:如果URL匹配不到任何静态资源,则应该返回同一个index.html页面,这个页面就是你app依赖的页面。”- 需在后端(
Apache或Nginx)进行简单的路由配置,同时搭配前端路由的404页面支持。
SPA路由机制详解(看不懂不要钱~~)的更多相关文章
- typecho路由机制详解
本文介绍的是typecho的路由机制,引自 不烦恼路由机制是typecho的核心,有很多功能都是基于路由功能设计的,理解并熟悉TE的路由机制将非常有助于插件的开发. 完整的路由表如下: array ( ...
- WebApi路由机制详解
随着前后端分离的大热,WebApi在项目中的作用也是越来越重要,由于公司的原因我之前一直没有机会参与前后端分离的项目,但WebApi还是要学的呀,因为这东西确实很有用,可单独部署.与前端和App交互都 ...
- ThreadPoolExecutor运转机制详解
ThreadPoolExecutor运转机制详解 - 走向架构师之路 - 博客频道 - CSDN.NET 最近发现几起对ThreadPoolExecutor的误用,其中包括自己,发现都是因为没有仔细看 ...
- Java 反射 设计模式 动态代理机制详解 [ 转载 ]
Java 反射 设计模式 动态代理机制详解 [ 转载 ] @author 亦山 原文链接:http://blog.csdn.net/luanlouis/article/details/24589193 ...
- Android Binder机制详解:手写IPC通信
想要掌握一样东西,最好的方式就是阅读理解它的源码.想要掌握Android Binder,最好的方式就是写一个AIDL文件,然后查看其生成的代码.本文的思路也是来自于此. 简介 Binder是Andro ...
- iOS的消息转发机制详解
iOS开发过程中,有一类的错误会经常遇到,就是找不到所调用的方法,当然这类问题比较好解决,给当前对象或其父类对象添加该方法即可,使得编译器在编译时能正确找到该方法:或者,还有另外的方法,由于Objec ...
- Android事件传递机制详解及最新源码分析——ViewGroup篇
版权声明:本文出自汪磊的博客,转载请务必注明出处. 在上一篇<Android事件传递机制详解及最新源码分析--View篇>中,详细讲解了View事件的传递机制,没掌握或者掌握不扎实的小伙伴 ...
- 【转】Cookie/Session机制详解
Cookie/Session机制详解 会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话.常用的会话跟踪技术是Cookie与Session.Cookie通过在客户端记录信息 ...
- 转 Java虚拟机5:Java垃圾回收(GC)机制详解
转 Java虚拟机5:Java垃圾回收(GC)机制详解 Java虚拟机5:Java垃圾回收(GC)机制详解 哪些内存需要回收? 哪些内存需要回收是垃圾回收机制第一个要考虑的问题,所谓“要回收的垃圾”无 ...
随机推荐
- 模块(二)——简单的log日志
简单的log日志 鉴于任何功能模块或系统在调试时都需要日志打印,这里随便写了一下,作为以后代码调试之用,只实现了不同等级的日志输出功能,其他的调试功能以后再行添加:使用方法简单,只需要在头文件里事先按 ...
- Codeforces Round #363 (Div. 2) B 暴力
Description You are given a description of a depot. It is a rectangular checkered field of n × m siz ...
- Http 请求头 Range
HTTP 请求头 Range 请求资源的部分内容(不包括响应头的大小),单位是byte,即字节,从0开始. 如果服务器能够正常响应的话,服务器会返回 206 Partial Content 的状态码及 ...
- sql语句中的[]中括号(转)
下面有关sql语句中[]的信息适用于Sql Server.Access等多种数据库. 1.sql语句中加[]是为了防止歧义,避免与系统保留关键字冲突,使计算机能识别.sql语句中有些字段可能是关键字, ...
- linux多线程学习笔记五--线程安全【转】
转自:http://blog.csdn.net/kkxgx/article/details/7506085 版权声明:本文为博主原创文章,未经博主允许不得转载. 一,线程安全基础 一个函数被称为线程安 ...
- Linux/Unix编程中的线程安全问题【转】
转自:http://blog.csdn.net/zhengzhoudaxue2/article/details/6432984 在目前的计算机科学中,线程是操作系统调度的最小单元,进程是资源分配的最小 ...
- 《Linux命令行与shell脚本编程大全 第3版》Linux命令行---47
以下为阅读<Linux命令行与shell脚本编程大全 第3版>的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:
- Swift Perfect 基础项目
brew install mysql@5.7 && brew link mysql@5.7 --force Package.swift import PackageDescriptio ...
- wxPython中文教程 简单入门加实例
wx.Window 是一个基类,许多构件从它继承.包括 wx.Frame 构件.技术上这意味着,我们可以在所有的 子类中使用 wx.Window 的方法.我们这里介绍它的几种方法: * SetTitl ...
- Bitmap类
一.Bitmap类 Bitmap对象封装了GDI+中的一个位图,此位图由图形图像及其属性的像素数据组成.因此Bitmap是用于处理由像素数据定义的图像的对象.该类的主要方法和属性如下: 1. GetP ...