Part of defining a topology is specifying for each bolt which streams it should receive as input
http://storm.apache.org/
【doing for realtime processing what Hadoop did for batch processing 】
Apache Storm is a free and open source distributed realtime computation system. Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Storm is simple, can be used with any programming language, and is a lot of fun to use!
Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
Storm integrates with the queueing and database technologies you already use. A Storm topology consumes streams of data and processes those streams in arbitrarily complex ways, repartitioning the streams between each stage of the computation however needed.
http://storm.apache.org/releases/2.0.0-SNAPSHOT/Concepts.html
【是什么 怎么做】
Trident是Storm的上层抽象;
Trident 按照是什么而不是怎么做表达拓扑,storm反之。
Topologies
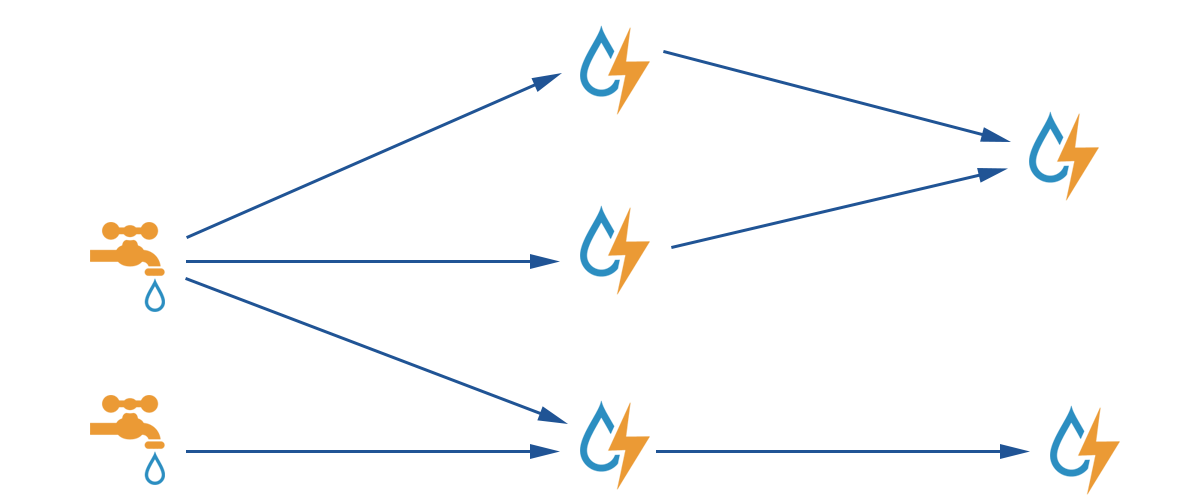
The logic for a realtime application is packaged into a Storm topology. A Storm topology is analogous to a MapReduce job. One key difference is that a MapReduce job eventually finishes, whereas a topology runs forever (or until you kill it, of course). A topology is a graph of spouts and bolts that are connected with stream groupings. These concepts are described below.
Resources:
- TopologyBuilder: use this class to construct topologies in Java
- Running topologies on a production cluster
- Local mode: Read this to learn how to develop and test topologies in local mode.
Streams
The stream is the core abstraction in Storm. A stream is an unbounded sequence of tuples that is processed and created in parallel in a distributed fashion. Streams are defined with a schema that names the fields in the stream's tuples. By default, tuples can contain integers, longs, shorts, bytes, strings, doubles, floats, booleans, and byte arrays. You can also define your own serializers so that custom types can be used natively within tuples.
Every stream is given an id when declared. Since single-stream spouts and bolts are so common, OutputFieldsDeclarer has convenience methods for declaring a single stream without specifying an id. In this case, the stream is given the default id of "default".
Resources:
- Tuple: streams are composed of tuples
- OutputFieldsDeclarer: used to declare streams and their schemas
- Serialization: Information about Storm's dynamic typing of tuples and declaring custom serializations
Spouts
A spout is a source of streams in a topology. Generally spouts will read tuples from an external source and emit them into the topology (e.g. a Kestrel queue or the Twitter API). Spouts can either be reliableor unreliable. A reliable spout is capable of replaying a tuple if it failed to be processed by Storm, whereas an unreliable spout forgets about the tuple as soon as it is emitted.
Spouts can emit more than one stream. To do so, declare multiple streams using the declareStream method of OutputFieldsDeclarer and specify the stream to emit to when using the emit method on SpoutOutputCollector.
The main method on spouts is nextTuple. nextTuple either emits a new tuple into the topology or simply returns if there are no new tuples to emit. It is imperative that nextTuple does not block for any spout implementation, because Storm calls all the spout methods on the same thread.
The other main methods on spouts are ack and fail. These are called when Storm detects that a tuple emitted from the spout either successfully completed through the topology or failed to be completed. ack and fail are only called for reliable spouts. See the Javadoc for more information.
Resources:
- IRichSpout: this is the interface that spouts must implement.
- Guaranteeing message processing
Bolts
All processing in topologies is done in bolts. Bolts can do anything from filtering, functions, aggregations, joins, talking to databases, and more.
Bolts can do simple stream transformations. Doing complex stream transformations often requires multiple steps and thus multiple bolts. For example, transforming a stream of tweets into a stream of trending images requires at least two steps: a bolt to do a rolling count of retweets for each image, and one or more bolts to stream out the top X images (you can do this particular stream transformation in a more scalable way with three bolts than with two).
Bolts can emit more than one stream. To do so, declare multiple streams using the declareStream method of OutputFieldsDeclarer and specify the stream to emit to when using the emit method on OutputCollector.
When you declare a bolt's input streams, you always subscribe to specific streams of another component. If you want to subscribe to all the streams of another component, you have to subscribe to each one individually. InputDeclarer has syntactic sugar for subscribing to streams declared on the default stream id. Saying declarer.shuffleGrouping("1") subscribes to the default stream on component "1" and is equivalent to declarer.shuffleGrouping("1", DEFAULT_STREAM_ID).
The main method in bolts is the execute method which takes in as input a new tuple. Bolts emit new tuples using the OutputCollector object. Bolts must call the ack method on the OutputCollector for every tuple they process so that Storm knows when tuples are completed (and can eventually determine that its safe to ack the original spout tuples). For the common case of processing an input tuple, emitting 0 or more tuples based on that tuple, and then acking the input tuple, Storm provides an IBasicBolt interface which does the acking automatically.
Its perfectly fine to launch new threads in bolts that do processing asynchronously. OutputCollector is thread-safe and can be called at any time.
Resources:
- IRichBolt: this is general interface for bolts.
- IBasicBolt: this is a convenience interface for defining bolts that do filtering or simple functions.
- OutputCollector: bolts emit tuples to their output streams using an instance of this class
- Guaranteeing message processing
Stream groupings
Part of defining a topology is specifying for each bolt which streams it should receive as input. A stream grouping defines how that stream should be partitioned among the bolt's tasks.
There are eight built-in stream groupings in Storm, and you can implement a custom stream grouping by implementing the CustomStreamGrouping interface:
- Shuffle grouping: Tuples are randomly distributed across the bolt's tasks in a way such that each bolt is guaranteed to get an equal number of tuples.
- Fields grouping: The stream is partitioned by the fields specified in the grouping. For example, if the stream is grouped by the "user-id" field, tuples with the same "user-id" will always go to the same task, but tuples with different "user-id"'s may go to different tasks.
- Partial Key grouping: The stream is partitioned by the fields specified in the grouping, like the Fields grouping, but are load balanced between two downstream bolts, which provides better utilization of resources when the incoming data is skewed. This paper provides a good explanation of how it works and the advantages it provides.
- All grouping: The stream is replicated across all the bolt's tasks. Use this grouping with care.
- Global grouping: The entire stream goes to a single one of the bolt's tasks. Specifically, it goes to the task with the lowest id.
- None grouping: This grouping specifies that you don't care how the stream is grouped. Currently, none groupings are equivalent to shuffle groupings. Eventually though, Storm will push down bolts with none groupings to execute in the same thread as the bolt or spout they subscribe from (when possible).
- Direct grouping: This is a special kind of grouping. A stream grouped this way means that the producer of the tuple decides which task of the consumer will receive this tuple. Direct groupings can only be declared on streams that have been declared as direct streams. Tuples emitted to a direct stream must be emitted using one of the [emitDirect](javadocs/org/apache/storm/task/OutputCollector.html#emitDirect(int, int, java.util.List) methods. A bolt can get the task ids of its consumers by either using the provided TopologyContext or by keeping track of the output of the
emitmethod in OutputCollector (which returns the task ids that the tuple was sent to). - Local or shuffle grouping: If the target bolt has one or more tasks in the same worker process, tuples will be shuffled to just those in-process tasks. Otherwise, this acts like a normal shuffle grouping.
Resources:
- TopologyBuilder: use this class to define topologies
- InputDeclarer: this object is returned whenever
setBoltis called onTopologyBuilderand is used for declaring a bolt's input streams and how those streams should be grouped
Reliability
Storm guarantees that every spout tuple will be fully processed by the topology. It does this by tracking the tree of tuples triggered by every spout tuple and determining when that tree of tuples has been successfully completed. Every topology has a "message timeout" associated with it. If Storm fails to detect that a spout tuple has been completed within that timeout, then it fails the tuple and replays it later.
To take advantage of Storm's reliability capabilities, you must tell Storm when new edges in a tuple tree are being created and tell Storm whenever you've finished processing an individual tuple. These are done using the OutputCollector object that bolts use to emit tuples. Anchoring is done in the emit method, and you declare that you're finished with a tuple using the ack method.
This is all explained in much more detail in Guaranteeing message processing.
Tasks
Each spout or bolt executes as many tasks across the cluster. Each task corresponds to one thread of execution, and stream groupings define how to send tuples from one set of tasks to another set of tasks. You set the parallelism for each spout or bolt in the setSpout and setBolt methods of TopologyBuilder.
Workers
Topologies execute across one or more worker processes. Each worker process is a physical JVM and executes a subset of all the tasks for the topology. For example, if the combined parallelism of the topology is 300 and 50 workers are allocated, then each worker will execute 6 tasks (as threads within the worker). Storm tries to spread the tasks evenly across all the workers.
Resources:
- Config.TOPOLOGY_WORKERS: this config sets the number of workers to allocate for executing the topology.
Part of defining a topology is specifying for each bolt which streams it should receive as input的更多相关文章
- 分布式流式处理框架:storm简介 + Storm术语解释
简介: Storm是一个免费开源.分布式.高容错的实时计算系统.它与其他大数据解决方案的不同之处在于它的处理方式.Hadoop 在本质上是一个批处理系统,数据被引入 Hadoop 文件系统 (HDFS ...
- Storm实践(一):基础知识
storm简介 Storm是一个分布式实时流式计算平台,支持水平扩展,通过追加机器就能提供并发数进而提高处理能力:同时具备自动容错机制,能自动处理进程.机器.网络等异常. 它可以很方便地对流式数据进行 ...
- storm源码分析之topology提交过程
storm集群上运行的是一个个topology,一个topology是spouts和bolts组成的图.当我们开发完topology程序后将其打成jar包,然后在shell中执行storm jar x ...
- Storm概念学习系列之Topology拓扑
不多说,直接上干货! Hadoop 上运行的是 MapReduce 作业,而在 Storm 上运行的是拓扑 Topology,这两者之间是非常不同的.一个关键的区别是:一个MapReduce 作业 ...
- Java性能提示(全)
http://www.onjava.com/pub/a/onjava/2001/05/30/optimization.htmlComparing the performance of LinkedLi ...
- Storm笔记——技术点汇总
目录 概况 手工搭建集群 引言 安装Python 配置文件 启动与测试 应用部署 参数配置 Storm命令 原理 Storm架构 Storm组件 Stream Grouping 守护进程容错性(Dae ...
- Smart internet of things services
A method and apparatus enable Internet of Things (IoT) services based on a SMART IoT architecture by ...
- storm 入门原理介绍
1.hadoop有master与slave,Storm与之对应的节点是什么? 2.Storm控制节点上面运行一个后台程序被称之为什么? 3.Supervisor的作用是什么? 4.Topology与W ...
- MPI Maelstrom - POJ1502最短路
Time Limit: 1000MS Memory Limit: 10000K Description BIT has recently taken delivery of their new sup ...
随机推荐
- Javascript的函数直接量定义
在Javascript中允许函数通过直接量来定义.一般情况下,我们定义函数时,最常见的方式是通过function语句进行定义,例如: function sum(a,b){ return a+b ...
- declaration specifier, declarator, type specifier
static struct abc * b; static struct abc : declaration specifier * b : declarator struct abc : type ...
- 使用 IntelliJ IDEA 开发 Android 应用程序时配置 Allatori 进行代码混淆
IntelliJ IDEA 提供了非常强大的 Android 开发支持,就连 Google 官方推荐的 Android Studio 其实也是 IntelliJ IDEA 的一个 Android 开发 ...
- 让网站永久拥有HTTPS - 申请免费SSL证书并自动续期
https://blog.csdn.net/xs18952904/article/details/79262646 https://freessl.org/
- Codeforces 23E Tree(树型DP)
题目链接 Tree $dp[x][i]$表示以x为根的子树中x所属的连通快大小为i的时候 答案最大值 用$dp[x][j]$ * $dp[y][k]$ 来更新$dp[x][j + k]$. (听高手说 ...
- [__NSCFConstantString size]: unrecognized selector sent to instance 错误
因为使用时候的类型和初始化的对象类型不匹配造成的,例如 - (NSMutableDictionary *)getMenuItems{ NSArray *defaultTmp = [NSArray ...
- DevExpress打印功能介绍 z
一.打印功能说明: 打印功能,我们有多种实现方式,可以根据需要自行选择,我简单的总结下两种方法. (1).使用微软.net框架自带的PrintDocument,这种方式是直接借助Graphics,自行 ...
- Sublime Text 2搭建Go开发环境
Sublime Text 2搭建Go开发环境,代码提示+补全+调试 cceevv · 2014-10-11 00:00:06 · 10496 次点击 · 预计阅读时间 3 分钟 · 5分钟之前 开始浏 ...
- TDDL-剖析淘宝TDDL
TDDL-剖析淘宝TDDL 学习了:https://blog.csdn.net/sumj7011/article/details/78286741 Taobao Distribute Data Lay ...
- Windows10系统修复
sfc /scannow 命令将扫描所有受保护的系统文件,并用位于 %WinDir%\System32\dllcache 的压缩文件夹中的缓存副本替换损坏的文件. %WinDir% 占位符代表Wind ...