Flask-数据与路由
数据
图书数据库的地址
# 基地址
http://t.yushu.im
# 关键字搜索
http://t.yushu.im/v2/book/search?q={}&start={}&count={}
# isbn搜索
http://t.yushu.im/v2/book/search/isbn/{isbn}
# 豆瓣api
https://api.douban.com/v2/book/1003078
搜索关键字
- 根据上面的地址可以知道搜索的时候有两种方式,而对于isbn搜索,又分为两种
isbn13 由13个0-9在数字组成,isbn10 由10表0-9表数字组组成,中间可能包含' - ' ,所以要分开来判断 - 在函数中要注意:
isdigit()可以判断是否为数字 ,replace()用来替换,
@app.route("/search/<q>/<page>")
def search(q,page):
"""
搜索书籍路由
:param q: 关键字 OR isbn
:param page: 页码
"""
isbn_or_key = 'key'
# 1. 判断长度是否为13且是否为数字
if len(q) == 13 and q.isdigit():
isbn_or_key = 'isbn'
# 2. 把-替换掉,判断是否为纯数字
short_q = q.replace('-', '')
if '-' in q and len(short_q) == 10 and short_q.isdigit():
isbn_or_key = 'isbn'
pass
- 多逻辑判断的时候,应该把结果看着为假的放到前面,对数据库操作的放到后面,这样有利于节约资源
简单的重构
- 上面的代码都写到视图中这样不妥,体现不了封装性,看起来不好,应该把一个实现的功能封装起来,建立一个函数,方便日后的管理
- 在目录下建立一个
helper.py文件,这个文件主要就是提供一些方法,把上面的内容放到这里,只需要返回一个值就可以了
# -*- coding: utf-8 -*-
def is_isbn_or_key(word):
isbn_or_key = 'key'
if len(word) == 13 and word.isdigit():
isbn_or_key = 'isbn'
short_word = word.replace('-', '')
if '-' in word and len(short_word) == 10 and short_word.isdigit():
isbn_or_key = 'isbn'
return isbn_or_key
- 在主文件中调用这个方法就可以了,记得传值,和接收返回的值
# -*- coding: utf-8 -*-
from flask import Flask,make_response
# 1. 这里要导入
from helper import is_isbn_or_key
app = Flask(__name__)
app.config.from_object('config')
@app.route('/book/search/<q>/<page>')
def search(q,page):
# 2. 调用方法即可
is_or_key = is_isbn_or_key(q)
pass
if __name__ == '__main__':
app.rundebug=app.config['DEBUG'])
requests请求
- 因为这个项目要访问不同的网址,所以在目录下新建一个
http.py文件,专门用来提供访问网址 - 这里使用的requests,要先进行安装,注意:代码写的时候一定要简洁,千万不要使用python的关键字,以免与Python的模块冲突并导致此错误,把这个类名http改为别的名称
# -*- coding: utf-8 -*-
import requests
class aaa:
# 传入url和是否返回的是json数据,这里是静态方法
@staticmethod
def get(url,return_json=True):
# 发送get请求
r = requests.get(url)
# 因为有的url返回的json数据,但是有的并不是,所以加一个判断,不是的话返回文本
# 还要判断状态码,200的话就是访问成功有数据
if r.status_code != 200:
return {} if return_json else ''
return r.json() if return_json else r.text
# 下面的写法太low
# if r.status_code == 200:
# if return_json:
# return r.json()
# else:
# return r.text
# else:
# if return_json:
# return {}
# else:
# return ''
从API中获取数据
- 首先在目录下定义一个类,用于用于获取数据,
ShanqiuBook,
# -*- coding: utf-8 -*-
from http import aaa
class ShanqiuBook:
isbn_url = 'http://t.yushu.im/v2/book/search/isbn/{}'
keyword_url = 'http://t.yushu.im/v2/book/search?q={}&count={}&start={}'
# 根据isbn进行搜索,这里使用这个静态装饰器,调用类变量更加的方便
@classmethod
def search_by_isbn(cls,isbn):
# 调用类变量,
url = cls.isbn_url.format(isbn)
# 调用上面的方法用于请求网址
result = aaa.get(url)
# 这里返回的是json数据,但是在py中就是字典了
return result
# 根据关键字进行搜索
@classmethod
def search_by_keyword(cls,keyword,count=15,start=0):
url = cls.keyword_url.format(keyword,count,start)
result = aaa.get(url)
return result
- 然后在视图中获取返回的数据
# -*- coding: utf-8 -*-
from flask import Flask
from helper import is_isbn_or_key
from flask import jsonify
# 实例化
from shanqiu_book import ShanQiuBook
app = Flask(__name__)
# 载入这个配置文件
app.config.from_object('config')
@app.route('/book/search/<q>/<page>')
def search(q,page):
is_or_key = is_isbn_or_key(q)
if is_or_key == 'isbn':
# 这里直接使用使用类名调用就可以
result = ShanQiuBook.search_by_isbn(q)
else:
result = ShanQiuBook.search_by_keyword(q)
# 因为返回的是json数据,要手动的进行解析,这样写的话非常麻烦
# return json.dumps(result), 200, {'content-type': 'application/json'}
# 这里使用flask自带的jsonify替换麻烦的json.dumps和元组
return jsonify(result)
if __name__ == '__main__':
app.run(debug=app.config['DEBUG'])
将视图函数拆分到单独的文件中
- 如果视图函数都写在主文件中,不利于维护,而是应该把他们放入到一个文件中,每一个模块就是一个试图,用的时候直接引用,这样有利于维护
- 在根目录下建立一个app/web文件夹,在这个文件夹下面建立一个book.py文件,专门用来存放book模块,然后在主文件中引用这个模块就可以了,
book.py
# -*- coding: utf-8 -*-
from flask import jsonify
from helper import is_isbn_key
from ShanqiuBook import ShanqiuBook
# 为了让book.py模块可以使用app对象
from demo import app
@app.route('/book/search/<q>/<page>')
def hello(q,page):
# 调用方法判断用户是根据什么查的
is_or_key = is_isbn_key(q)
if is_or_key == 'isbn':
result = ShanqiuBook.search_by_isbn(q)
else:
result = ShanqiuBook.search_by_keyword(q)
return jsonify(result)
- 此时的主文件中
# -*- coding: utf-8 -*-
from flask import Flask
# 为了可以注册book.py中的路由
from app.web import book
app = Flask(__name__)
app.config.from_object('config')
if __name__ == '__main__':
app.run(debug=app.config['DEBUG'])
- 但是这样写的话,会出现404,因为出现了循环引用
循环引入流程分析
- 因为在整个的流程中,app两次初始化,如图
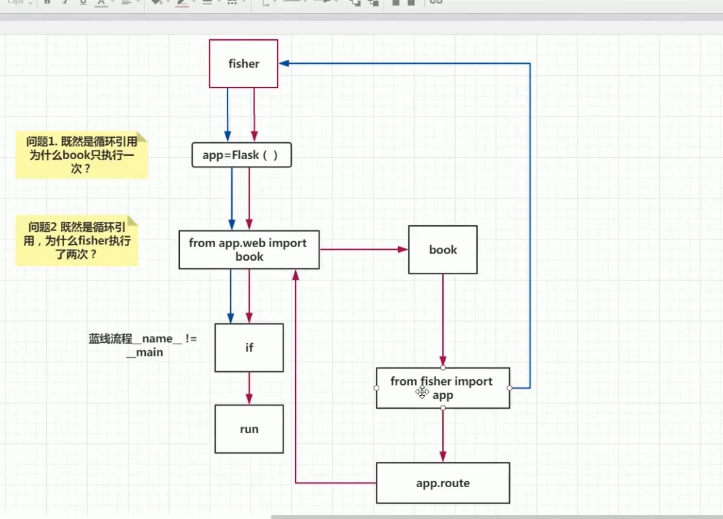
- 整个流程中,出现了两次核心app对象的初始化,注册路由是在蓝色流程中初始化的app注册的。但是启动服务是红色流程中的app启动的
- book中注册路由所使用的app对象,是他自己所导入fisher模块的app对象(蓝色流程中),而不是红色主流程中所实例化的app对象
- 问题1:因为都是由fisher引入book,一个模块只会引入另一个模块一次,所以只执行了一次book
- 问题2:由于一次是主流程执行fisher文件;一次是由book模块导入 fisher
- 为了验证我们的结论,我们在app实例化,启动,注册路由是哪个地方加入日志信息,
print("id为"+str(id(app))+"的app注册路由")
@app.route("/book/search/<q>/<page>")
def search(q, page):
isbn_or_key = is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YuShuBook.search_by_isbn(q)
else:
result = YuShuBook.search_by_key(q)
return jsonify(result)
- 主文件
app = Flask(__name__)
print("id为"+str(id(app))+"的app实例化")
app.config.from_object("config")
# 为了可以注册book.py中的路由
from app.web import book
if __name__ == '__main__':
print("id为" + str(id(app)) + "的app启动")
app.run(debug=app.config['DEBUG'])
- 结果如下
id为92323280的app实例化
id为107142192的app实例化
id为107142192的app注册路由
id为92323280的app启动
可以看到注册路由的app,和启动服务的app不是同一个app。并且最后启动的app是最先实例化的app,也就是红色主流程的app;而注册路由的app是后实例化的app,也就是由book导入fisher模块的蓝色流程的app
Flask-数据与路由的更多相关文章
- flask模板,路由,消息提示,异常处理
1.flask的路由与反向路由 from flask import Flask, request, url_for app = Flask(__name__) @app.route('/') def ...
- Flask(2)- 装饰器的坑及解决办法、flask中的路由/实例化配置/对象配置/蓝图/特殊装饰器(中间件、重定义错误页面)
一.装饰器的坑以及解决方法 1.使用装饰器装饰两个视图函数,代码如下 from flask import Flask, redirect, render_template, request, sess ...
- Flask中的路由、实例化参数和config配置文件
Flask中的路由 endpoint 别名不能重复,对应的视图函数,默认是视图函数名.endpoint 才是路由的核心.视图函数与路由的对应关系.可以通过url_for 反向创建url # metho ...
- Linux数据包路由原理、Iptables/netfilter入门学习
相关学习资料 https://www.frozentux.net/iptables-tutorial/cn/iptables-tutorial-cn-1.1.19.html http://zh.wik ...
- AngularJS路由系列(5)-- UI-Router的路由约束、Resolve属性、路由附加数据、路由进入退出事件
本系列探寻AngularJS的路由机制,在WebStorm下开发.主要包括: ● UI-Router约束路由参数● UI-Router的Resolve属性● UI-Router给路由附加数据● UI- ...
- flask简单的路由分发
flask简单的路由分发 from flask import Flask, request app = Flask(__name__) @app.route('/hello') def index() ...
- 第六篇 Flask中的路由系统
Flask中的路由系统其实我们并不陌生了,从一开始到现在都一直在应用 @app.route("/",methods=["GET","POST" ...
- Flask:网页路由及请求方式的设定
1.Flask路由的实现 Flask的路由是由route装饰器来实现的 @app.route("/index/") def index(): return "hello ...
- Flask 蓝图进行路由分发.md
Flask 蓝图进行路由分发 Flask虽然说是一个轻型web框架,但也总不能用一个py文件写完全部view吧,所以我们要把路由分到不同的py文件中.这就需要用到蓝图了. 一 创建一个py文件 用于处 ...
- flask(一)之路由和视图
01-介绍 Flask 是一个 Python 实现的 Web 开发微框架,同时具有很强的扩展能力. 02-第一个flask程序 # 初始化 from flask import Flask, url_f ...
随机推荐
- Django-Rest-Framework的解析器和渲染器
Django-Rest-Framework的解析器和渲染器 restful framework 解析器 解析器的作用就是服务端接收客户端传来的数据,把数据解析成自己想要的数据类型的过程 本质就是对请 ...
- HDU-2119-Matrix(最大匹配)
链接:https://vjudge.net/problem/HDU-2119#author=Smilencer 题意: 众所周知,tyz是一个写bug小能手,以至于如果没有队友的帮助,就ac不了程序. ...
- java.sql.SQLException: No suitable driver found for jdbc:hive://localhost:10000/default
error: java.sql.SQLException: No suitable driver found for jdbc:hive://localhost:10000/default at ja ...
- NET Core 2.1 Global Tools
微软工程师Nate McMaster的博文.NET Core 2.1 Global Tools https://natemcmaster.com/blog/2018/05/12/dotnet-glob ...
- (转)linux dumpe2fs命令
linux dumpe2fs命令 命令名称 dumpe2fs - 显示ext2/ext3/ext4文件系统信息. dumpe2fs命令语法 dumpe2fs [ -bfhixV ] [ -o supe ...
- LCA 离线做法tarjan
tarjan(int u) { int v; for(int i=h[u];i;i=nex[i])//搜索边的 { v=to[i]; tarjan(v); marge(u,v); vis[v]=; } ...
- (wp8.1)样式资源
在开发wp的时候,难免要设置好多属性.但是有好多属性是重复的,我们可不可统一 设置样式呢,答案是肯定的 代码如下 <Page x:Class="Blue.MainPage" ...
- 现阶段github上的emysql编译无法通过的问题
最近在写db引擎,今天用到了emysql,找到https://github.com/Eonblast/Emysql,拽下来,然后发现竟然编译不通过~~去网上找了下资料,在 http://erlang. ...
- springboot集成shiro实现权限认证
github:https://github.com/peterowang/shiro 基于上一篇:springboot集成shiro实现身份认证 1.加入UserController package ...
- html的文档设置标记上(格式标记)4-5
<html> <head> <title>第四课的标题及第五课的标题</title> <meta charset="utf-8" ...