Goole Search Auto Complete
这个项目就九章算法大数据课程的一个项目。主要分为两步:
第一步是 offline 建立 数据库 我们用两个map reduce 的data pipline 来实现。
第二步是 online显示把数据里面数据读出来显示。
如果实际运用中 第一步 mapreduce 一般数据一天之内更新不会太多 所以mapredcue 一天跑一次。
第二步 online 显示 like 数据大了会比较慢 。 然后可以优化系统版讲的trie树就是其中一种。
Map-Reduce 实现搜索自动补全。这项功能可以用在搜索的自动补全和拼写纠错。
search auto complete是基于N-Gram model实现的,下面首先介绍N-Gram model
一、模型基础
N-Gram model
N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念,通常在NLP中,人们基于一定的语料库,可以利用N-Gram来预计或者评估一个句子是否合理。
关于N-Gram的一个介绍,参见博客http://blog.csdn.net/baimafujinji/article/details/51281816
简单来说,N-Gram是一个句子的长度为n的连续子序列
例如:
I love big data
4-gram i love big data
3-gram l love big, love big data
2-gram l love, love big, big data
language model
A statistical language model is a probability distribution over sequences of words. Given such a sequence, say of length m, it assigns a probability

to the whole sequence. https://en.wikipedia.org/wiki/Language_model
简单来说就是根据已有的数据集,不同的字符串序列在这个数据集上有一个概率分布,据此可以得到一个字符串序列出现的概率大小。
本文所述的就是N-gram model.一句前边出现的字符串序列去预测后边出现某字符串的概率大小。
这里又Predict N-Gram based on N-Gram 和 Predict N-Gram based on 1-Gram,当然第一种方式要准确得多,但是也相对更复杂。
所以本文采用首先基于1-Gram预测N-Gram,然后再数据库上做文章,实现基于N-Gram预测N-Gram。
二、系统框架
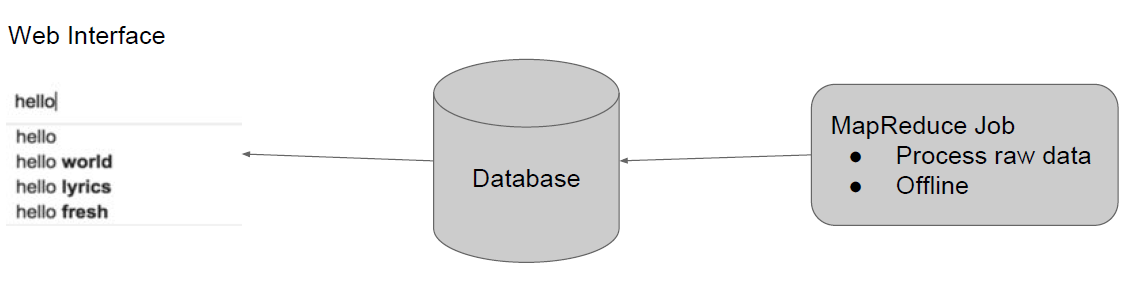
图1
基本架构如图一所示,主要分为三个模块:
Web接口模块:基于LAMP实现的一个简单的测试接口(LAMP集成了Apache, Php, Mysql)
数据库模块:存放我们建立好了的1-Gram model
Map-Reduce模块:离线处理我们的训练数据。
三、具体步骤

图2
如图2所示,具体步骤如下:
- 读取文件数据
- 建立N-Gram library
- 计算概率获得language model
- web接口展示
3.1读取文件数据
按句子读入数据,预处理删除所有的非字母字符
3.2建立N-Gram library

使用Map-Reduce实现。
- Mapper
划分句子,取出1-gram,...,N-gram
- Reducer
统计各个phrase出现的次数。
3.3计算概率获得language model
基于概率计算公式:

来计算概率。但是考虑到我们的目的是得到phrase之后应该取哪一个word,分母都一样,所以就省去除以分母这一步骤。
这样,我们对于一个N-Gram:提取Starting word/phrase为key,最后一个字符串为value。然后对同一个key,选取value最大的几个value存入数据库。
最后,我们获得了一个最后的数据库,但是回过头来分析,我们得到的只是基于一个单词去预测的模型,所以这里在数据库中选择数据的时候做了一个小操作,下文详述。
- Mapper

由于一些出现次数特别少的字符串,我们并不希望它们出现在结果中,所以在Mapper阶段需要设定易于阈值,只有出现次数大于这个阈值的时候,才让它进入Reducer。
- Reducer
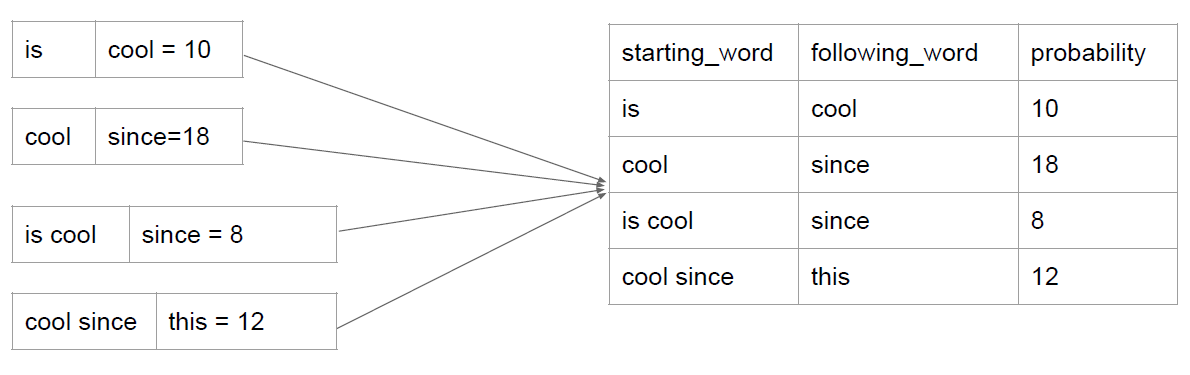
我们并不需要存储所有数据进入数据库,存储的大小和我们设定的需要提示的数量是有关系的,假如我们需要自动补全的提示框有k条,那么我们是需要选择出TopK存储进入数据库就可以了。
最后得到的数据库中存储结果如下图所示:

呼应之前提到的,我们现在得到的只是基于1-gram的预测,怎么得到N-Gram呢?在从数据库中提取数据的时候,我们选择这样操作:

这样就可以由N-Gram预测N-Gram。
这里之前也有一个疑惑,既然这样操作的话,那么你前边还把language model的Mapper的拆分还有什么必要?
这里是必要的,举个例子:
a man 264
a little 90
a great 83
a apple 50
a beautiful girl 45
a wonderful game 40
假如我们不进行拆分的话,那么意思就是找TopK的时候就按照‘a’打头的分组来找TopK。那么一般2-Gram的都会比较大,直接就选择了 a man 264、a little 90、a great 83 、a apple 50。后边的都没有机会进去,但实际分析我们希望的是a beautiful girl 45、a wonderful game 40能够入选。
Goole Search Auto Complete的更多相关文章
- mapReduce编程之auto complete
1 n-gram模型与auto complete n-gram模型是假设文本中一个词出现的概率只与它前面的N-1个词相关.auto complete的原理就是,根据用户输入的词,将后续出现概率较大的词 ...
- Atitit.auto complete 自动完成控件的实现总结
Atitit.auto complete 自动完成控件的实现总结 1. 框架选型 1 2. 自动完成控件的ioc设置 1 3. Liger 自动完成控件问题 1 4. 官网上的code有问题,不能 ...
- 如何开发auto complete 智能提示功能
目录(?)[+] 如何开发auto complete 智能提示功能 最近网上好像流传用redis实现,其实智能提示和用什么存储关系不大 07年,我过一个类似的项目 我有几千个名字,随着用户在输入框中不 ...
- Atitit.auto complete 自己主动完毕控件的实现总结
Atitit.auto complete 自己主动完毕控件的实现总结 1. 框架选型 1 2. 自己主动完毕控件的ioc设置 1 3. Liger 自己主动完毕控件问题 1 4. 官网上的code ...
- kubectl alias auto complete
平时kubectl命令管理kubernetes,敲久了就觉得比较麻烦,想着使用alias k来代替kubectl,可是当输入k时没有了自动补全的功能 这里在 ~/.bashrc 添加如下配置后,可以自 ...
- terminal下历史命令自动完成功能history auto complete
CentOS下,有一个很智能的功能,就是只输入一条历史命令的前几个字母,再按PageUp和PageDown键,就可以在以此字母为前缀的历史命令中上下切换.这个功能非常实用,而且比CTRL+R使用起来更 ...
- soapui not supported the auto complete
http://forum.soapui.org/viewtopic.php?t=19850 syntax highlighting or content assist inside soapUI? t ...
- WIP 004 - Quote/Policy Search
Please create the search form Auto complete for first name and last name Related tables System_LOBs ...
- Community Cloud零基础学习(二)信誉等级设置 & Global Search设定
当我们创建了Community以后,我们需要对他进行定制页面来使community用户更好的使用.此篇主要描述两点,信誉等级设定以及Global Search 设定.其他的内容后期再慢慢描述. 一. ...
随机推荐
- Protocol Buffer学习教程之类库应用(四)
Protocol Buffer学习教程之类库应用(四) 此教程是通过一个简单的示例,给C++开发者介绍一下如何使用protocol buffers编程,主要包括以下几部分: 定义一个.proto文件 ...
- 百倍性能的PL/SQL优化案例(r11笔记第13天)
我相信你是被百倍性能的字样吸引了,不过我所想侧重的是优化的思路,这个比优化技巧更重要,而结果嘛,其实我不希望说成是百倍提升,“”自黑“”一下. 有一个真实想法和大家讨论一下,就是一个SQL语句如果原本 ...
- java Vamei快速教程08 继承
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 继承(inheritance)是面向对象的重要概念.继承是除组合(composit ...
- cesium加载shp格式数据
方法一: shp格式转换为GeoJson格式并加载 首先注意shp的坐标系,要转换为WGS84,使用arcgis或QGIS 工具:http://mapshaper.org/: 注意:export时,输 ...
- [VC]线程
是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其它线程共 享进程所拥有的全部资源.一个线程可以创建和撤消另一个线 ...
- 如何解决EXCEL中的科学计数法
EXCEL虽然能够有效的处理数据,尤其是数字的计算.但是,在单元格中输入数字的时候,很多时候都会受到科学计算法的困扰. 当单元格中输入的数字,超过11位时,就会自动变成科学计数法.无论您怎么调整列的宽 ...
- python 补缺收集
[http://www.cnblogs.com/happyframework/p/3255962.html] 1. 高效code 与 不常用的函数用法: #带索引的遍历 , )): print(ind ...
- 2018.6.12 Oracle问题
ORA-01950: 对表空间 'USERS' 无权限 创建新的用户时,要指定default tablespace,否则它会把system表空间当成自己的缺省表空间.这样做是不提倡的.估计原来创建某个 ...
- Python-Boolean operation
一.布尔运算符 1.x and y: if x is false, then x, else y 2.x or y: if x is false, then y, else x 3.not x: if ...
- C# 接口慨述
接口(interface)用来定义一种程序的协定.实现接口的类或者结构要与接口的定义严格一致.有了这个协定,就可以抛开编程语言的限制(理论上).接口可以从多个基接口继承,而类或结构可以实现多个接口.接 ...