spark 图文详解:资源调度和任务调度
讲说spark的资源调度和任务调度,基本的spark术语,这里不再多说,懂的人都懂了。。。
按照数字顺序阅读,逐渐深入理解:以下所有截图均为个人上传,不知道为什么总是显示别人的QQ,好尴尬,无所谓啦,开始吧~~
1 宽窄依赖与Stage划分:
上熟悉的图:
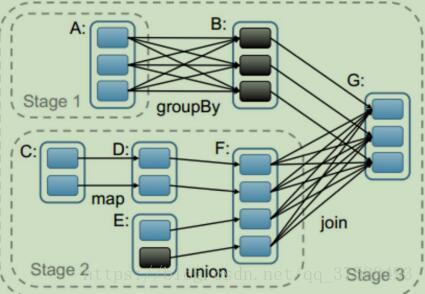
在 Spark 里每一个操作生成一个 RDD,RDD 之间连一条边,最后这些 RDD 和他们之间的边组成一个有向无环图,这个就是 DAG,Spark 内核会在需要计算发生的时刻绘制一张关于计算路径的有向无环图,也就是 DAG。有了DAG 图,Spark 内核下一步的任务就是根据 DAG 图将计算划分成 Stage,
上图:G 与 F 之间是宽依赖,所以把 G 和 F 分为两个 Stage,而 C 、D 到 F,E 到 F 都是窄依赖,所以 CDEF 最终划分为一个 Stage2,A 与 B 之间是宽依赖,B 与 G 之间是窄依赖,所以最终,A 被划分为一个 Stage1,因为 BG 的 stage 依赖于 stage1 和 stage2,所以最终把整个DAG 划分为一个 stage3,所以说,宽窄依赖的作用就是切割 job,划分 stage。
Stage:由一组可以并行计算的 task 组成。
Stage 的并行度:就是其中的 task 的数量。
与互联网业界的概念有些差异:在互联网的概念中,并行度是指可同时开辟的线程数,并发数是指每个线程中可处理的最大数据量,比如: 4 个线程,每个线程可处理的数据为 100 万条,那么并行度就是 4,并发量是 100 万;而对于 stage 而言,即使其中的 task是分批进行执行的,也都算在并行度中,比如,stage 中有 100 个 task,而这 100 个 task 分4 批次才能执行完,那么该 stage 的并行度也为 100。Stage 的并行度是由最后一个 RDD 的分区决定的。
2 资源调度 (有人喜欢那standalone client方式举例,那我这把cluster 模式和client模式都说下得了~)
Cluster模式:
源码位置如图master.scala:
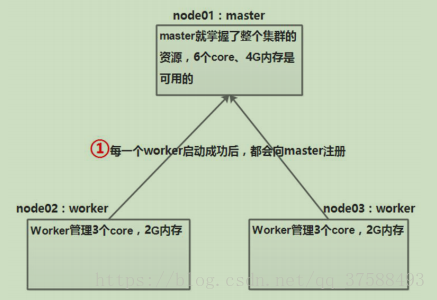
a)Worker 启动后向 Master 注册
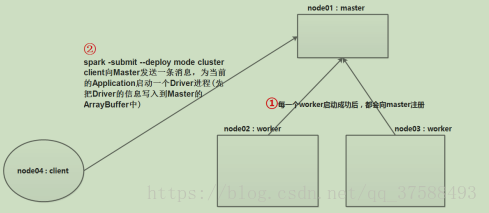
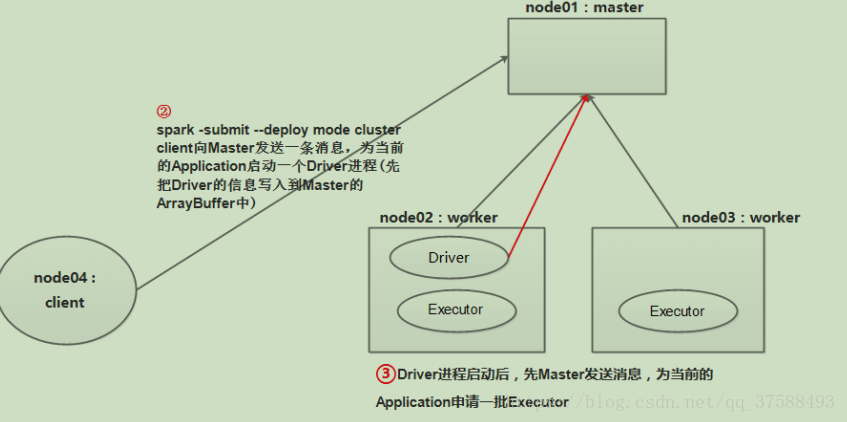
b) client 向 Master 发送一条消息,为当前的 Application 启动一个 Driver 进程
启动Driver源码如下图:
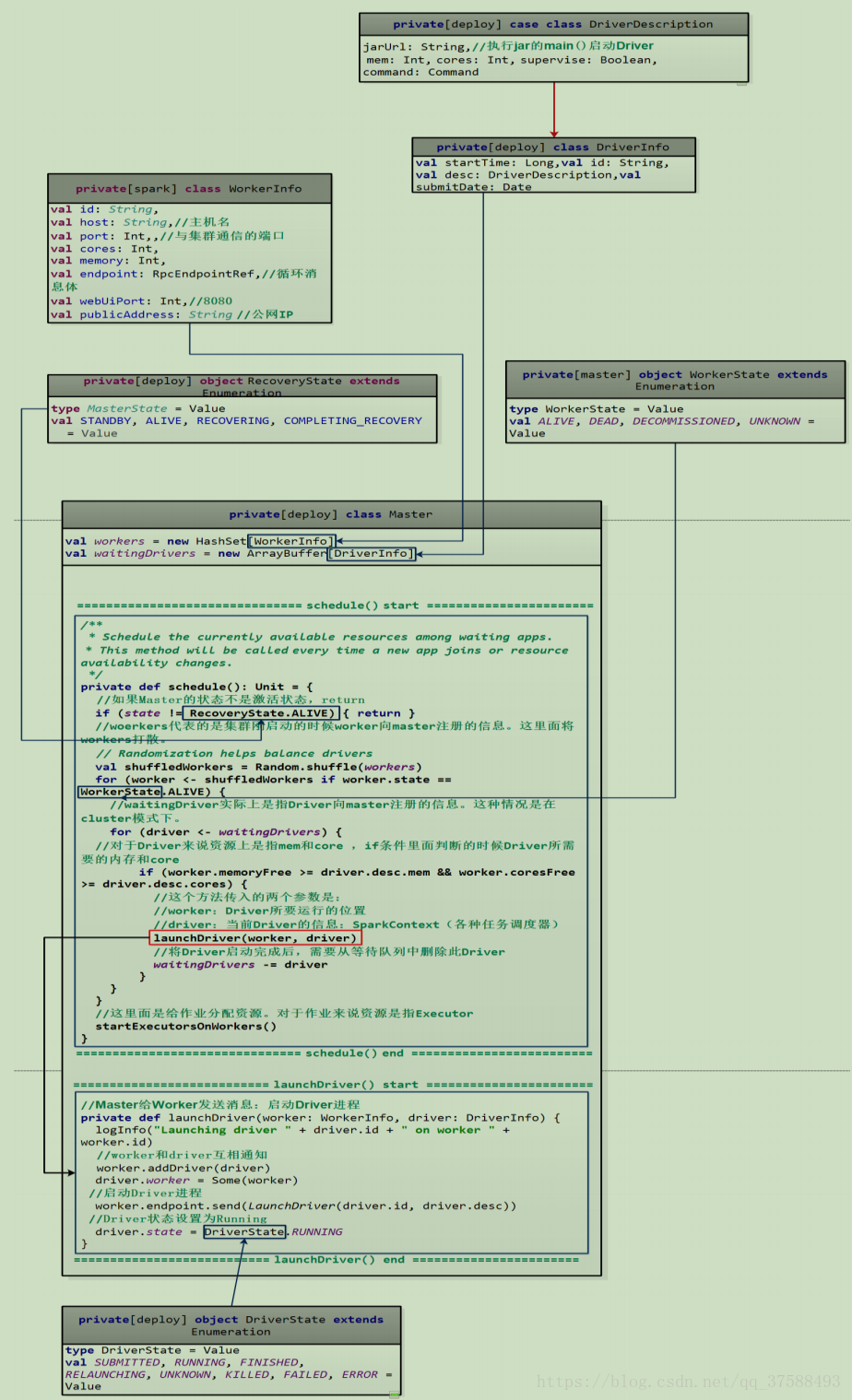
c)Driver 进程向 Master 发送消息:为当前的 Application 申请一批 Executor:
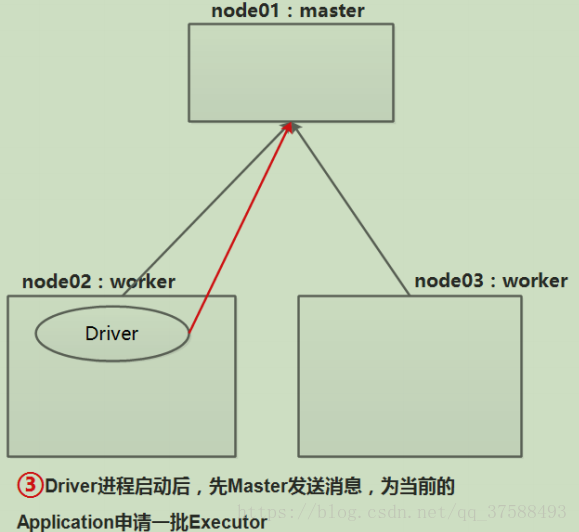
EXECUTOR创建的过程如图:

上图的过程,展示了Executor进程被启动的过程。那么下面的是简图:
总结资源调度:
1) 在默认情况下(没有使用--executor --cores 这个选项)时,每一个 Worker 节点为当前的 Application 只启动一个 Executor,这个 Executor 会使用这个 Worker 管理的所有的cores。(原因:assignedCores(pos) += minCoresPerExecutor);
2) 默认情况下,每个 Executor 使用 1G 内存;
3) 如果想要在一个 Worker 节点启动多个 Executor,需要使--executor --cores 这个选项;
4) spreadOutApps 这个参数可以决定 Executor 的启动方式,默认轮询方式启动,这样有利于数据的本地化。
Client模式(standalone):
实际上我们的代码会先在Driver这个进程(我们写的spark程序,打成jar包,用spark-submit来提交,local模式当我们的程序提交到集群上时,会加载并执行我们的jar包,并找到jar包中的main函数执行一遍,执行main所启动的这个进程名就是SparkSubmit,这个进程就是我们所说的Driver进程; cluster模式会在集群中找一台node,会启动一个进程执行一遍我们提交的代码,这个进程就是Driver,Driver启动之后将其信息注册到Master中,存储在ArrayBuffer中)中执行一遍,Driver这个进程中有SparkContext这个对象。代码从main函数开始执行,new SparkConf()设置我们运行Spark时的环境参数(还可以通过spark-submit -- 加上参数来设置),new SparkContext()(在源码的700多行左右),创建DAGScheduler和TaskScheduler,TaskScheduler另启动一个线程将Application注册到Master中【 是放到Master中的ArrayBuffer的数据结构中,当ArrayBuffer中有信息之后,Master会调用自己的schedule()方法,schedule会为当前的Application申请资源,此时master会找一些空闲的Worker,并在Worker上启动Executor进程,Executor启动完成之后会反向注册给TaskScheduler(在driver)】 。
3 任务调度
Cluster模式:
源码位置:core/src/main/scala/rdd/RDD.scala。
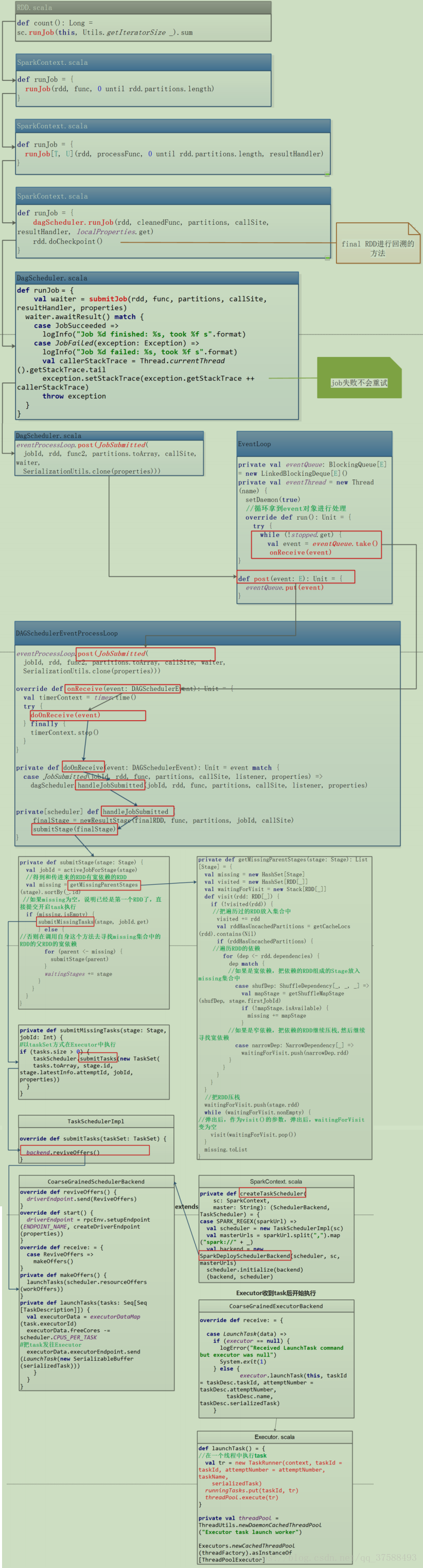
上图是任务调度源码,不在文字叙述,可以参考client模式的部分叙述。
注意:2点:
【a:提交时的容错能力】
TaskScheduler提交task如果发生了失败,默认会重试三次,如果依然失败,那么则认为这个task就失败了,这时会进行stage重试,DAGScheduler会重新发送TaskSet给TaskScheduler,默认会重试四次,如果四次后依然失败,则认为job失败。因此一个task默认情况下重试3*4=12次
如果task失败是由于shuffle file not find造成的,那么TaskScheduler是不负责重试的,直接进行stage重试。
【b:重试机制的问题】
如果:Task的逻辑是将处理的数据结果放入到数据库中,
如果一个Task提交到百分之七十五,然后失败了,这时候会重试,那么有执行了一次task,这时候就会有脏数据的产生。
以上问题如何去解决?
【1.关闭重试机制。
2.在数据库中设置主键,这时候如果重复提交,那么会失败,也就避免了脏数据的产生。
】
Client 模式(接2 资源调度中的Client模式):
任务调度: (此时代码的第二行(new SparkContext(conf))已经执行完毕)
a).Action类型的算子触发job的执行。源码中调用了SparkContext的runJob()方法,跟进源码发现底层调用的是DAGScheduler的runJob()方法。
DAGScheduler会将我们的job按照宽窄依赖划分为一个个stage,每个stage中有一组并行计算的task,每一个task都可以看做是一个”pipeline”,,这个管道里面数据是一条一条被计算的,每经过一个RDD会经过一次处理,RDD是一个抽象的概念里面存储的是一些计算的逻辑,每一条数据计算完成之后会在shuffle write过程中将数据落地写入到我们的磁盘中。
b).stage划分完之后会以TaskSet的形式提交给我们的TaskScheduler。
源码中TaskScheduler.submit.tasks(new TaskSet())只是一个调用方法的过程而已。我们口述说是发送到TaskScheduler。TaskScheduler接收到TaskSet之后会进行遍历,每遍历一条调用launchTask()方法,launchTask()根据数据本地化的算法发送task到指定的Executor中执行。task在发送到Executor之前首先进行序列化,Executor中有ThreadPool,ThreadPool中有很多线程,在这里面来具体执行我们的task。
c).TaskScheduler和Executor之间有通信(Executor有一个邮箱(消息循环体CoresExecutorGraintedBackend)),Executor接收到task
Executor接收到task后首先将task反序列化,反序列化后将这个task变为taskRunner(new taskRunner),并不是TaskScheduler直接向Executor发送了一个线程,这个线程是在Executor中变成的。然后这个线程就可以在Executor中的ThreadPool中执行了。
d).Executor接收到的task分为maptask 和 reducetask
map task 和 reduce task,比如这里有三个stage,先从stage1到stage2再到stage3,针对于stage2来说,stage1中的task就是map task ,stage2中的task就是reduce task,针对stage3来说...map task 是一个管道,管道的计算结果会在shuffle write阶段数据落地,数据落地会根据我们的分区策略写入到不同的磁盘小文件中,注意相同的key一定写入到相同的磁盘小文件中),map端执行完成之后,会向Driver中的DAGScheduler对象里面的MapOutputTracker发送了一个map task的执行状态(成功还是失败还有每一个小文件的地址)。然后reduce task开始执行,reduce端的输入数据就是map端的输出数据。那么如何拿到map端的输出数据呢?reduce task会先向Driver中MapOutPutTracker请求这一批磁盘小文件的地址,拿到地址后,由reduce task所在的Executor里面的BlockManager向Map task 所在的Executor先建立连接,连接是由ConnectionManager负责的,然后由BlockTransformService去拉取数据,拉取到的数据作为reduce task的输入数据(如果使用到了广播变量,reduce task 或者map task 它会先向它所在的Executor中的BlockManager要广播变量,没有的话,本地的BlockManager会去连接Driver中的BlockManagerMaster,连接完成之后由BlockTransformService将广播变量拉取过来)Executor中有了广播变量了,task就可以正常执行了。
只说实用,不举理论!
spark 图文详解:资源调度和任务调度的更多相关文章
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- 对于maven创建spark项目的pom.xml配置文件(图文详解)
不多说,直接上干货! http://mvnrepository.com/ 这里,怎么创建,见 Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版 ...
- Spark Mllib里决策树回归分析使用.rootMeanSquaredError方法计算出以RMSE来评估模型的准确率(图文详解)
不多说,直接上干货! Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率和决策树多元分类使用.precision方法以precision来评估模型 ...
- Spark Mllib里决策树回归分析如何对numClasses无控制和将部分参数设置为variance(图文详解)
不多说,直接上干货! 在决策树二元或决策树多元分类参数设置中: 使用DecisionTree.trainClassifier 见 Spark Mllib里如何对决策树二元分类和决策树多元分类的分类 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 如何在IDEA里给大数据项目导入该项目的相关源码(博主推荐)(类似eclipse里同一个workspace下单个子项目存在)(图文详解)
不多说,直接上干货! 如果在一个界面里,可以是单个项目 注意:本文是以gradle项目的方式来做的! 如何在IDEA里正确导入从Github上下载的Gradle项目(含相关源码)(博主推荐)(图文详解 ...
- SPSS学习系列之SPSS Modeler的功能特性(图文详解)
不多说,直接上干货! Win7/8/10里如何下载并安装最新稳定版本官网IBM SPSS Modeler 18.0 X64(简体中文 / 英文版)(破解永久使用)(图文详解) 我这里,是以SPSS ...
- Scala IDEA for Eclipse里用maven来创建scala和java项目代码环境(图文详解)
这篇博客 是在Scala IDEA for Eclipse里手动创建scala代码编写环境. Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群模式) ...
随机推荐
- codeforces 703B B. Mishka and trip(数学)
题目链接: B. Mishka and trip time limit per test 1 second memory limit per test 256 megabytes input stan ...
- wingide 显示中文 及 配色方案
http://lihuipeng.blog.51cto.com/3064864/923231 网上收集的方法: 显示中文: 任意文本编辑器打开:x:\Wing IDE\bin\gtk-bin\etc\ ...
- EntityFramework Code First 构建外键关系,数据库不生成外键约束
创建 ExtendedSqlGenerator类 public class ExtendedSqlGenerator : SqlServerMigrationSqlGenerator { #regio ...
- [转]Javascript高性能动画与页面渲染
No setTimeout, No setInterval 作者 李光毅 发布于 2014年4月30日 如果你不得不使用setTimeout或者setInterval来实现动画,那么原因只能是你需要精 ...
- poj3784Running Median——堆维护中间值
题目:http://poj.org/problem?id=3784 将较小的数放入大根堆,较大的数放入小根堆,控制较小数堆大小比较大数堆小1,则较大数堆堆顶即为中位数. 代码如下: #include& ...
- 梯度算子(普通的+Robert + sobel + Laplace)
1.水平垂直差分法: 2.Robert 算子梯度 3.sobel算子 4.拉普拉斯算子
- XML常用操作
C#操作XML非常简单 一是写入: 生明一个xelment 再在它的父节点Add就可以,也可以用生明的节点.SetAttribute("节点名称","节点对应的值&quo ...
- TripAdvisor architecture 2011/06
http://highscalability.com/blog/2011/6/27/tripadvisor-architecture-40m-visitors-200m-dynamic-page-vi ...
- Centos 6.5 下Nginx安装部署https服务器
一般我们都需要先装pcre, zlib,前者为了重写rewrite,后者为了gzip压缩.1.选定源码目录选定目录 /usr/local/cd /usr/local/2.安装PCRE库cd /usr/ ...
- ASP.NET web application中的redirect
在开发ASP.NET MVC web application过程中,开发上线了新系统后,需要把老系统的url redirect新系统下 其中在项目系统目录下有一个文件 301RedirectsPage ...