OCR技术浅探: 光学识别(3)
经过前面的文字定位和文本切割,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别。
模型选择
在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了单字的识别模型。
卷积神经网络是人工神经网络的一种,已成为当前图像识别领域的主流模型。 它通过局部感知野和权值共享方法,降低了网络模型的复杂度,减少了权值的数量,在网络结构上更类似于生物神经网络,这也预示着它必然具有更优秀的效果。 事实上,我们选择卷积神经网络的主要原因有:
1、对原始图像自动提取特征 卷积神经网络模型可以直接将原始图像进行输入,免除了传统模型的人工提取特征这一比较困难的核心部分;
2、比传统模型更高的精度 比如在MNIST手写数字识别任务中,可以达到99%以上的精度,这远高于传统模型的精度;
3、 比传统模型更好的泛化能力 这意味着图像本身的形变(伸缩、旋转)以及图像上的噪音对识别的结果影响不明显,这正是一个良好的OCR系统所必需的。
训练数据
为了训练一个良好的模型,必须有足够多的训练数据。幸运的是,虽然没有现成的数据可以用,但是由于我们只是做印刷字体的识别,因此,我们可以使用计算机自动生成一批训练数据。通过以下步骤,我们构建了一批比较充分的训练数据:
1。 更多细节 由于汉字的结构比数字和英文都要复杂,因此,为了体现更多的细节信息,我使用48×48的灰度图像构建样本,作为模型的输入;
2。 常见汉字 为了保证模型的实用性,我们从网络爬取了数十万篇微信公众平台上的文章,然后合并起来统计各自的频率,最后选出了频率最高的3000个汉字(在本文中我们只考虑简体字),并且加上26个字母(大小写)和10个数字,共3062字作为模型的输出;
3。 数据充分 我们人工收集了45种不同的字体,从正规的宋体、黑体、楷体到不规范的手写体都有,基本上能够比较全面地覆盖各种印刷字体;
4。 人工噪音 每种字体都构建了5种不同字号(46到50)的图片,每种字号2张,并且为了增强模型的泛化能力,将每个样本都加上5%的随机噪音。
模型结构
在模型结构方面,有一些前人的工作可以参考的。一个类似的例子是MNIST手写数字的识别——它往往作为一个新的图像识别模型的“试金石”——是要将六万多张大小为28×28像素的手写数字图像进行识别,这个案例跟我们实现汉字的识别系统具有一定的相似性,因此在模型的结构方面可以借鉴。一个常见的通过卷积神经网络对MNIST手写数字进行识别的模型结构如图
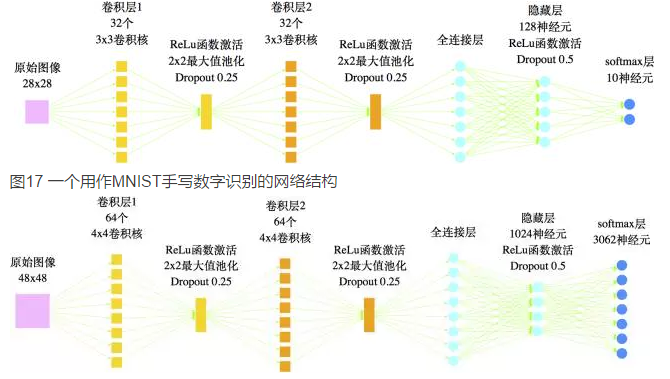
图18 本文用来识别印刷汉字的网络结构
经过充分训练后,如图17的网络结构可以达到99%以上的精确度,说明这种结构确实是可取的。但是很显然,手写数字不过只有10个,而常用汉字具有数千个,在本文的分类任务中,就共有3062个目标。也就是说,汉字具有更为复杂和精细的结构,因此模型的各方面都要进行调整。首先,在模型的输入方面,我们已经将图像的大小从28x28提高为48x48,这能保留更多的细节,其次,在模型结构上要复杂化调整,包括:增加卷积核的数目,增加隐藏节点的数目、调整权重等。最终我们的网络结构如图18。
在激活函数方面,我们选取了RuLe函数为激活函数

实验表明,它相比于传统的sigmoid、tanh等激活函数,能够大大地提升模型效果[3][4];在防止过拟合方面,我们使用了深度学习网络中最常用的Dropout方式[5],即随机地让部分神经元休眠,这等价于同时训练多个不同网络,从而防止了部分节点可能出现的过拟合现象。
需要指出的是,在模型结构方面,我们事实上做了大量的筛选工作。比如隐藏层神经元的数目,我们就耗费了若干天时间,尝试了512、1024、2048、4096、8192等数目,最终得到1024这个比较适合的值。数目太多则导致模型太庞大,而且容易过拟合;太少则容易欠拟合,效果不好。我们的测试发现,从512到1024,效果有明显提升;而再增加节点效果没有明显提升,有时还会有明显下降。
模型实现
我们的模型在操作系统为CentOS 7的服务器(24核CPU+96G内存+GTX960显卡)下完成,使用Python 2。7编写代码,并且使用Keras作为深度学习库,用Theano作为GPU加速库(Tensorflow一直提示内存溢出,配置不成功。 )。
在训练算法方面,使用了Adam优化方法进行训练,batch size为1024,迭代30次,迭代一次大约需要700秒。
如果出现形近字时,应该是高频字更有可能,最典型的例子就是“日”、“曰”了,这两个的特征是很相似的,但是“日”出现的频率远高于“曰”,因此,应当优先考虑“日”。 因此,在训练模型的时候,我们还对模型最终的损失函数进行了调整,使得高频字的权重更大,这样能够提升模型的预测性能。
经过多次调试,最终得到了一个比较可靠的模型。 模型的收敛过程如下图。

训练曲线图:Loss(损失函数)和Acc(精度)
模型检验
我们将从以下三个方面对模型进行检验。 实验结果表明,对于单字的识别效果,我们的模型优于Google开源的OCR系统Tesseract。
训练集检验
最终训练出来的模型,在训练集的检验报告如表1。

从表1可以看到,即便在加入了随机噪音的样本中,模型的正确率仍然有99。7%,因此,我们有把握地说,单纯从单字识别这部分来看,我们的结果已经达到了state of the art级别,而且在黑体、宋体等正规字体中(正规字体样本是指所有训练样本中,字体为黑体、宋体、楷体、微软雅黑和Arial unicode MS的训练样本,这几种字体常见于印刷体中。),正确率更加高!
测试集检验
我们另外挑选了5种字体,根据同样的方法生成了一批测试样本(每种字体30620张,共153100张),用来对模型进行测试,得到模型测试正确率为92。11%。 五种字体的测试结果如表2。

从表中可以看出,即便是对于训练集之外的样本,模型效果也相当不错。接着,我们将随机噪音增大到15%(这对于一张48×48的文字图片来说已经相当糟糕了),得到的测试结果如表3。

平均的正确率为87。59%,也就是说,噪音的影响并不明显,模型能够保持90%左右的正确率。 这说明该模型已经完全达到了实用的程度。
OCR技术浅探: 光学识别(3)的更多相关文章
- OCR技术浅探:基于深度学习和语言模型的印刷文字OCR系统
作者: 苏剑林 系列博文: 科学空间 OCR技术浅探:1. 全文简述 OCR技术浅探:2. 背景与假设 OCR技术浅探:3. 特征提取(1) OCR技术浅探:3. 特征提取(2) OCR技术浅探:4. ...
- OCR技术浅探(转)
网址:https://spaces.ac.cn/archives/3785 OCR技术浅探 作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行 ...
- OCR技术浅探:特征提取(1)
研究背景 关于光学字符识别(Optical Character Recognition, 下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不 ...
- OCR技术浅探: 语言模型和综合评估(4)
语言模型 由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方 ...
- OCR技术浅探: 语言模型(4)
由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方法之一. ...
- OCR技术浅探:Python示例(5)
文件说明: 1. image.py——图像处理函数,主要是特征提取: 2. model_training.py——训练CNN单字识别模型(需要较高性能的服务器,最好有GPU加速,否则真是慢得要死): ...
- OCR技术浅探 : 文字定位和文本切割(2)
文字定位 经过前面的特征提取,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步: 1.邻近搜索,目的是圈出单行文字: 2.文本切割,目的是将单行文本切割为单字. 邻近搜索 我们可 ...
- 你知道现在有一种新的OCR技术叫“移动端车牌识别”吗?
核心内容:车牌识别.OCR识别技术.移动端车牌识别.手机端车牌识别.安卓车牌识别.Android车牌识别.iOS车牌识别 一.移动端车牌识别OCR技术研发原理 移动端车牌识别是基于OCR识别的一种应用 ...
- OCR技术(光学字符识别)
什么是OCR? OCR英文全称是optical character recognition,中文叫光学字符识别.它是利用光学技术和计算机技术把印在或者写在纸上的 文字读取出来,并转换成一种计算机能够接 ...
随机推荐
- linux socket can测试
1. Overview / What is Socket CAN -------------------------------- The socketcan package is an implem ...
- JVM系统性能监控总结
(1) uptime 查看系统运行时间.连接数(终端连接数).平均负载 (2) top 查看CPU.内存.交换空间使用情况,可以看到当前系统性能进程消耗资源情况 (3) vmstat 统计系统CPU. ...
- svn:ignore 的用处
用svn管理代码,一直以来都受到一件不爽事情的困扰: 1)有些文件或文件夹不想在commit的时候看到,虽然他们是non-versioned,比如*.bak.*.class,*.scc(vss文件), ...
- golang Time to String
golang Time to String allenhaozi · 2016-09-02 09:00:00 · 2447 次点击 · 预计阅读时间 1 分钟 · 19分钟之前 开始浏览 这是一个创建 ...
- 打印-print.js
//打印开始// strPrintName 打印任务名// printDatagrid 要打印的datagridfunction CreateFormPage(ctx,strPrintName, pr ...
- css样式整理
字体属性:(font) 大小 {font-size: x-large;}(特大) xx-small;(极小) 一般中文用不到,只要用数值就可以,单位:PX.PD 样式 {font-style: obl ...
- Javascript事件监听
FireFox : addEventListener()方法 IE : attachEvent()方法 为HTML元素添加一个事件监听, 而不是直接对元素的事件属性(如:onclick.onmouse ...
- selenium运行火狐报错FirefoxDriver : Unable to connect to host 127.0.0.1 on port 7055
摘要: 这是个常见的启动firefoxdriver的问题,具体的错误日志如下,其实原因很简单,就是你的Selenium版本和firefox 不兼容了. Firefox 版本太高了, 请及时查看你安装的 ...
- Spring MVC属于SpringFrameWork的后续产品
Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面.Spring MVC 分离了控制器.模型对象.分派器以及处理程序对象的角色,这种分离让它 ...
- leetcode -- Permutations II TODO
Given a collection of numbers that might contain duplicates, return all possible unique permutations ...