文本相似性计算总结(余弦定理,simhash)及代码
最近在工作中要处理好多文本文档,要求找出和每个文档的相识的文档。通过查找资料总结如下几个计算方法:
1、余弦相似性
我举一个例子来说明,什么是"余弦相似性"。
为了简单起见,我们先从句子着手。

请问怎样才能计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。

第二步,列出所有的词。

第三步,计算词频。

第四步,写出词频向量。

到这里,问题就变成了如何计算这两个向量的相似程度。
我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,
意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
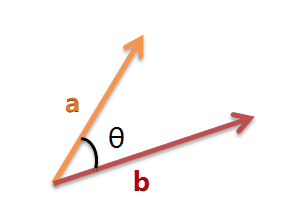
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:
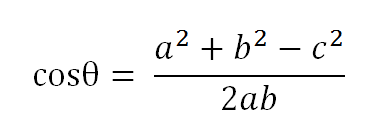
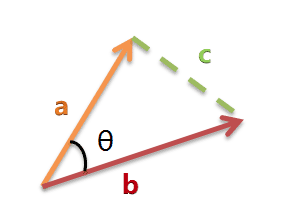
假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:
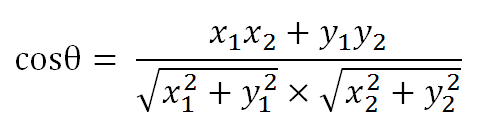

数学家已经证明,余弦的这种计算方法对n维向量也成立。假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:

使用这个公式,我们就可以得到,句子A与句子B的夹角的余弦。
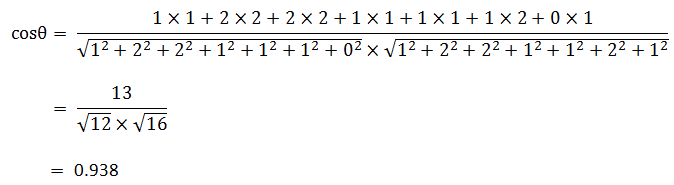
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。
由此,我们就得到了"找出相似文章"的一种算法:
1、使用TF-IDF算法,找出两篇文章的关键词;
2、每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
3、生成两篇文章各自的词频向量;
4、计算两个向量的余弦相似度,值越大就表示越相似。
"余弦相似度"是一种非常有用的算法,只要是计算两个向量的相似程度,都可以采用它。
应用场景及优缺点
本文目前将该算法应用于网页标题合并和标题聚类中,目前仍在尝试应用于其它场景中。
优点:计算结果准确,适合对短文本进行处理。
缺点:需要逐个进行向量化,并进行余弦计算,比较消耗CPU处理时间,因此不适合长文本,如网页正文、文档等。
java实现代码
package main.java;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.corpus.tag.Nature;
import com.hankcs.hanlp.seg.common.Term; import java.util.*;
/**
* @Author:sks
* @Description:
* @Date:Created in 16:04 2018/6/1
* @Modified by:
**/
public class CosineSimilarity { public static void main(String[] args) { ComputeTxtSimilar(); } private static void ComputeTxtSimilar(){
String txtLeft = CommonClass.getDocFileText("D:/work/Solr/ImportData-1/160926 进击的直播:细数各路媒体的入场“姿势”(完整版).doc");
String txtRight = CommonClass.getDocFileText("D:/work/Solr/ImportData-1/160926 刘庆振 直播经济:全民网红时代的内容创业与流量变现.doc");
//所有文档的总词库
List<String> totalWordList = new ArrayList<String>();
//计算文档的词频
Map<String, Integer> leftWordCountMap = getWordCountMap(txtLeft, totalWordList);
Map<String, Float> leftWordTfMap = calculateWordTf(leftWordCountMap); Map<String, Integer> rightWordCountMap = getWordCountMap(txtRight, totalWordList);
Map<String, Float> rightWordTfMap = calculateWordTf(rightWordCountMap); //获取文档的特征值
List<Float> leftFeature = getTxtFeature(totalWordList,leftWordTfMap);
List<Float> rightFeature = getTxtFeature(totalWordList,rightWordTfMap); //计算文档对应特征值的平方和的平方根
float leftVectorSqrt = calculateVectorSqrt(leftWordTfMap);
float rightVectorSqrt = calculateVectorSqrt(rightWordTfMap); //根据余弦定理公司,计算余弦公式中的分子
float fenzi = getCosValue(leftFeature,rightFeature); //根据余弦定理计算两个文档的余弦值
double cosValue = 0;
if (fenzi > 0) {
cosValue = fenzi / (leftVectorSqrt * rightVectorSqrt);
}
cosValue = Double.parseDouble(String.format("%.4f",cosValue));
System.out.println(cosValue); } /**
* @Author:sks
* @Description:获取词及词频键值对,并将词保存到词库中
* @Date:
*/
public static Map<String,Integer> getWordCountMap(String text,List<String> totalWordList){
Map<String,Integer> wordCountMap = new HashMap<String,Integer>();
List<Term> words= HanLP.segment(text);
int count = 0;
for(Term tm:words){
//取字数为两个字或两个字以上名词或动名词作为关键词
if(tm.word.length()>1 && (tm.nature== Nature.n||tm.nature== Nature.vn)){
count = 1;
if(wordCountMap.containsKey(tm.word))
{
count = wordCountMap.get(tm.word) + 1;
wordCountMap.remove(tm.word);
}
wordCountMap.put(tm.word,count);
if(!totalWordList.contains(tm.word)){
totalWordList.add(tm.word);
}
}
}
return wordCountMap;
} //计算关键词词频
private static Map<String, Float> calculateWordTf(Map<String, Integer> wordCountMap) {
Map<String, Float> wordTfMap =new HashMap<String, Float>();
int totalWordsCount = 0;
Collection<Integer> cv = wordCountMap.values();
for (Integer count : cv) {
totalWordsCount += count;
} wordTfMap = new HashMap<String, Float>();
Set<String> keys = wordCountMap.keySet();
for (String key : keys) {
wordTfMap.put(key, wordCountMap.get(key) / (float) totalWordsCount);
}
return wordTfMap;
} //计算文档对应特征值的平方和的平方根
private static float calculateVectorSqrt(Map<String, Float> wordTfMap) {
float result = 0;
Collection<Float> cols = wordTfMap.values();
for(Float temp : cols){
if (temp > 0) {
result += temp * temp;
}
}
return (float) Math.sqrt(result);
} private static List<Float> getTxtFeature(List<String> totalWordList,Map<String, Float> wordCountMap){
List<Float> list =new ArrayList<Float>();
for(String word :totalWordList){
float tf = 0;
if(wordCountMap.containsKey(word)){
tf = wordCountMap.get(word);
}
list.add(tf);
}
return list;
} /**
* @Author:sks
* @Description:根据两个向量计算余弦值
* @Date:
*/
private static float getCosValue(List<Float> leftFeature, List<Float> rightFeature) {
float fenzi = 0;
float tempX = 0;
float tempY = 0;
for (int i = 0; i < leftFeature.size(); i++) {
tempX = leftFeature.get(i);
tempY = rightFeature.get(i);
if (tempX > 0 && tempY > 0) {
fenzi += tempX * tempY;
}
}
return fenzi;
} }
2、SimHash
SimHash为Google处理海量网页的采用的文本相似判定方法。该方法的主要目的是降维,即将高维的特征向量映射成f-bit的指纹,通过比较两篇文档指纹的汉明距离来表征文档重复或相似性。
备注:此处f-bit指纹,可以根据应用需求,定制为16位、32位、64位或者128位数等。
simhash算法分为5个步骤:分词、hash、加权、合并、降维,具体过程如下所述:
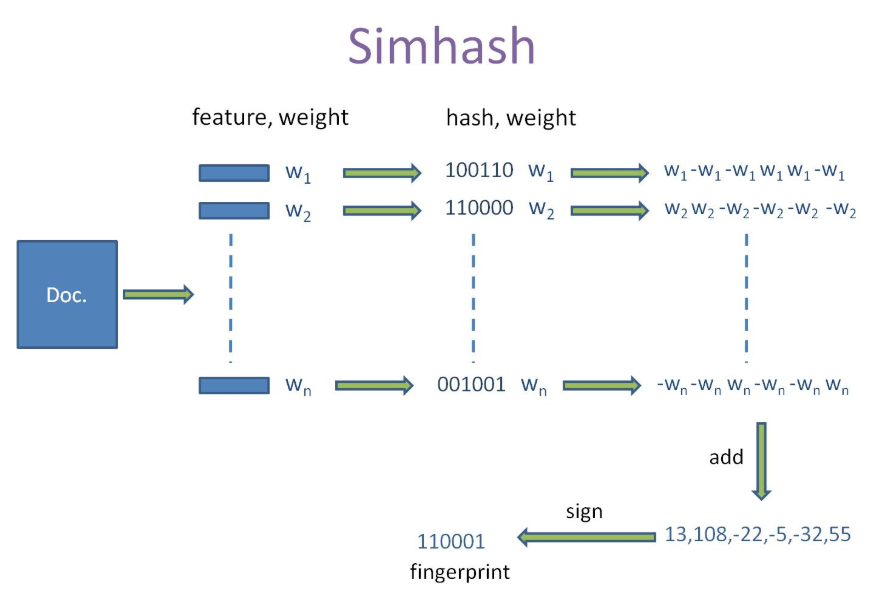
1、分词
这一步和上面的余弦相似性介绍的一到四步骤类似。
2、hash
通过hash函数计算各个特征向量的hash值,hash值为二进制数01组成的n-bit签名。比如比如句子 A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0中的hash值Hash(喜欢)为100101,
“电视”的hash值Hash(电视)为“101011”(当然实际的值要比这个复杂,hash串比这要长)就这样,字符串就变成了一系列数字。
3、加权
通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“喜欢”的hash值为“100101”,把hash值从左到右与权重相乘,如果为1则乘以1 ,如果是0则曾以-1 ,喜欢的权重是2 计算为“2 -2 -2 2 -2 2”;
“电视”的hash值为“101011”,通过加权计算为 “ 1 -1 1 -1 1 1”,其余特征向量类似此般操作。
4、合并
把上面所有各个单词算出来的序列值累加,变成只有一个序列串。比如 “喜欢”的“2 -2 -2 2 -2 2”,“电视”的 “ 1 -1 1 -1 1 1”, 把每一位进行累加, (2+1)+(-2-1)+(-2+1)+(2-1)+(-2+1)+(2+1)=3 -3 -1 1 -1 3
这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维
把4步算出来的 “3 -3 -1 1 -1 3” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 0 1 0 1”。这样就得到了每篇文档的SimHash签名值
6、海明距离
海明距离的求法:异或时,只有在两个比较的位不同时其结果是1 ,否则结果为0,两个二进制“异或”后得到1的个数即为海明距离的大小。
根据经验值,对64位的 SimHash值,海明距离在3以内的可认为相似度比较高。
比如:
A:我喜欢看电视,不喜欢看电影 其hash值为 1 0 0 1 0 1
B:我也很喜欢看电视,但不喜欢看电影 其hash值为 1 0 1 1 0 1
两者 hash 异或运算结果 001000,统计结果中1的个数是1,那么两者的海明距离就是1,说明两者比较相似。
7、 python代码和java实现代码
# coding=utf-8
class simhash:
# 构造函数
def __init__(self, tokens='', hashbits=128):
self.hashbits = hashbits
self.hash = self.simhash(tokens) # 生成simhash值
def simhash(self, tokens):
# v是长度128的列表
v = [0] * self.hashbits
tokens_hash = [self.string_hash(x) for x in tokens]
for t in tokens_hash: # t为token的普通hash值
for i in range(self.hashbits):
bitmask = 1 << i
if t & bitmask:
v[i] += 1 # 查看当前bit位是否为1,是的话将该位+1
else:
v[i] -= 1 # 否则的话,该位-1
fingerprint = 0
for i in range(self.hashbits):
if v[i] >= 0:
fingerprint += 1 << i
return fingerprint # 整个文档的fingerprint为最终各个位>=0的和 # 求海明距离
def hamming_distance(self, other):
# 异或结果
xorResult = (self.hash ^ other.hash)
# 128个1的二进制串
hashbit128 = ((1 << self.hashbits) - 1)
x = xorResult & hashbit128
count = 0
while x:
count += 1
x &= x - 1
return count # 求相似度
def similarity(self, other):
a = float(self.hash)
b = float(other.hash)
if a > b:
return b / a
else:
return a / b # 针对source生成hash值
def string_hash(self, source):
if source == "":
return 0
else:
result = ord(source[0]) << 7
m = 1000003
hashbit128 = ((1 << self.hashbits) - 1) for c in source:
temp = (result * m) ^ ord(c)
result = temp & hashbit128 result ^= len(source)
if result == -1:
result = -2 return result if __name__ == '__main__': s = '你 知道 里约 奥运会,媒体 玩出了 哪些 新花样?'
hash1 = simhash(s.split())
print hash1.__str__()
s = '我不知道 里约 奥运会,媒体 玩出了 哪些 新花样'
hash2 = simhash(s.split())
print hash2.__str__()
s = '视频 直播 全球 知名 媒体 的 战略 转移'
hash3 = simhash(s.split()) print(hash1.hamming_distance(hash2), " ", hash1.similarity(hash2))
print(hash1.hamming_distance(hash3), " ", hash1.similarity(hash3))
print(hash2.hamming_distance(hash3), " ", hash2.similarity(hash3))
package main.java;
import java.math.BigInteger;
import java.util.StringTokenizer;
public class SimHash
{
private String tokens;
private BigInteger strSimHash;
private int hashbits = 128; /**
* @Author:sks
* @Description 构造函数:
* @tokens: 特征值字符串,括号内的数值是权重,媒体(56),发展(31),技术(15),传播(12),新闻(11),用户(10),信息(10),生产(9)
*/
public SimHash(String tokens)
{
this.tokens = tokens;
this.strSimHash = this.simHash();
}
public SimHash(String tokens, int hashbits)
{
this.tokens = tokens;
this.hashbits = hashbits;
this.strSimHash = this.simHash();
} public String getSimHash(){
return this.strSimHash.toString();
}
private BigInteger simHash() {
int[] v = new int[this.hashbits];
StringTokenizer stringTokens = new StringTokenizer(this.tokens,",");
while (stringTokens.hasMoreTokens()) {
//媒体(56)
String temp = stringTokens.nextToken();
String token = temp.substring(0,temp.indexOf("("));
int weight = Integer.parseInt(temp.substring(temp.indexOf("(")+1,temp.indexOf(")")));
BigInteger t = this.hash(token);
for (int i = 0; i < this.hashbits; i++){
BigInteger bitmask = new BigInteger("1").shiftLeft(i);
if (t.and(bitmask).signum() != 0) {
v[i] += 1 * weight;//加权
}
else {
v[i] -= 1 * weight;
}
}
}
BigInteger fingerprint = new BigInteger("0");
for (int i = 0; i < this.hashbits; i++) {
if (v[i] >= 0) {
fingerprint = fingerprint.add(new BigInteger("1").shiftLeft(i));
}
}
return fingerprint;
} private BigInteger hash(String source) {
if (source == null || source.length() == 0) {
return new BigInteger("0");
}
else {
char[] sourceArray = source.toCharArray();
BigInteger x = BigInteger.valueOf(((long) sourceArray[0]) << 7);
BigInteger m = new BigInteger("1000003");
BigInteger mask = new BigInteger("2").pow(this.hashbits).subtract(
new BigInteger("1"));
for (char item : sourceArray) {
BigInteger temp = BigInteger.valueOf((long) item);
x = x.multiply(m).xor(temp).and(mask);
}
x = x.xor(new BigInteger(String.valueOf(source.length())));
if (x.equals(new BigInteger("-1"))) {
x = new BigInteger("-2");
}
return x;
}
}
/**
* @Author:sks
* @Description:计算海明距离
* @leftSimHash,rightSimHash:要比较的信息指纹
* @hashbits:128
*/
public static int hammingDistance(String leftSimHash,String rightSimHash,int hashbits){
BigInteger m = new BigInteger("1").shiftLeft(hashbits).subtract(
new BigInteger("1"));
BigInteger left = new BigInteger(leftSimHash);
BigInteger right = new BigInteger(rightSimHash);
BigInteger x = left.xor(right).and(m);
int count = 0;
while (x.signum() != 0) {
count += 1;
x = x.and(x.subtract(new BigInteger("1")));
}
return count;
} public static void main(String[] args)
{ String s = "你,知道,里约,奥运会,媒体,玩出,了,哪些,新,花样";
SimHash hash1 = new SimHash(s, 128);
System.out.println(hash1.getSimHash() + " " + hash1.getSimHash().bitCount());
s = "我,不,知道,里约,奥运会,媒体,玩出,了,哪些,新,花样";
SimHash hash2 = new SimHash(s, 128);
System.out.println(hash2.getSimHash() + " " + hash2.getSimHash().bitCount());
s = "视频,直播,全球,知名,媒体,的,战略,转移";
SimHash hash3 = new SimHash(s, 128);
System.out.println(hash3.getSimHash() + " " + hash3.getSimHash().bitCount());
System.out.println("============================");
System.out.println(SimHash.hammingDistance(hash1.getSimHash(),hash2.getSimHash(),128)); System.out.println(SimHash.hammingDistance(hash1.getSimHash(),hash3.getSimHash(),128)); System.out.println(SimHash.hammingDistance(hash2.getSimHash(),hash3.getSimHash(),128)); }
}
参考资料:
1、http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
2、数学之美
3、https://blog.csdn.net/u011630575/article/details/52164688
4、https://blog.csdn.net/chenguolinblog/article/details/50830948
文本相似性计算总结(余弦定理,simhash)及代码的更多相关文章
- 文本相似性计算--MinHash和LSH算法
给定N个集合,从中找到相似的集合对,如何实现呢?直观的方法是比较任意两个集合.那么可以十分精确的找到每一对相似的集合,但是时间复杂度是O(n2).此外,假如,N个集合中只有少数几对集合相似,绝大多数集 ...
- 利用sklearn计算文本相似性
利用sklearn计算文本相似性,并将文本之间的相似度矩阵保存到文件当中.这里提取文本TF-IDF特征值进行文本的相似性计算. #!/usr/bin/python # -*- coding: utf- ...
- Solr In Action 笔记(2) 之 评分机制(相似性计算)
Solr In Action 笔记(2) 之评分机制(相似性计算) 1 简述 我们对搜索引擎进行查询时候,很少会有人进行翻页操作.这就要求我们对索引的内容提取具有高度的匹配性,这就搜索引擎文档的相似性 ...
- 文本相似性热度统计(python版)
0. 写在前面 节后第一篇,疫情还没结束,黎明前的黑暗,中国加油,武汉加油,看了很多报道,发现只有中国人才会帮助中国人,谁说中国人一盘散沙?也许是年龄大了,看到全国各地的医务人员源源不断的告别家人去支 ...
- 小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现
小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现 上一章我们聊了聊通过一致性正则的半监督方案,使用大量的未标注样本来提升小样本模型的泛化能力.这一章我们结合FG ...
- 计算KS值的标准代码
计算KS值的标准代码 from scipy.stats import ks_2samp get_ks = lambda y_pred,y_true: ks_2samp(y_pred[y_true==1 ...
- 余弦相似性计算及python代码实现
A:西米喜欢健身 B:超超不爱健身,喜欢打游戏 step1:分词 A:西米/喜欢/健身 B:超超/不/喜欢/健身,喜欢/打/游戏 step2:列出两个句子的并集 西米/喜欢/健身/超超/不/打/游戏 ...
- opencv8-GPU之相似性计算
Opencv支持GPU计算,并且包含成一个gpu类用来方便调用,所以不需要去加上什么__global__什么的很方便,不过同时这个类还是有不足的,待opencv小组的更新和完善. 这里先介绍在之前的& ...
- java实现 比较两个文本相似度-- java 中文版 simHash 实现 ,
比较两个文本的相似度 这里采用 simHash 算法 ; 分词是 基于 http://hanlp.linrunsoft.com/ 的开源 中文分词包 来实现分词 ; 实现效果图: 直接上源码: htt ...
随机推荐
- Redis Cluster集群的搭建与实践
Redis Cluster集群 一.redis-cluster设计 Redis集群搭建的方式有多种,例如使用zookeeper等,但从redis 3.0之后版本支持redis-cluster集群,Re ...
- thinkphp5.0配置加载
ThinkPHP支持多种格式的配置格式,但最终都是解析为PHP数组的方式. PHP数组定义 返回PHP数组的方式是默认的配置定义格式,例如: //项目配置文件 return [ // 默认模块名 'd ...
- Java 继承内部类
大家有没有想过内部类究竟能不能被继承呢? public class Main { public static void main(String[] args){ Outer outer = new O ...
- PHP包管理
前言 在nodejs中,存在npm,python中也存在pip,而php之前不存在类似的东西,导致想要安装一个包,只能去复制代码,但是现在,使用composer可以简单的安装一个包(但是compose ...
- Android Service AIDL
http://blog.csdn.net/liuhe688/article/details/6400385 在Android中,如果我们需要在不同进程间实现通信,就需要用到AIDL技术去完成. AID ...
- poj 2096Collecting Bugs
题目链接 poj 2096Collecting Bugs 题解 dp[i][j]表示已经找到i种bug,并存在于j个子系统中,要达到目标状态的天数的期望. 显然,dp[n][s]=0,因为已经达到目标 ...
- [BZOJ4521][CQOI2016]手机号码(数位DP)
4521: [Cqoi2016]手机号码 Time Limit: 10 Sec Memory Limit: 512 MBSubmit: 875 Solved: 507[Submit][Status ...
- noip2011初赛提高组 试题详解
转载自:https://blog.csdn.net/Eirlys_North/article/details/52889993 一.单项选择题(共20题,每题1.5分,共计30分,每题有且仅有一个正确 ...
- 2015 UESTC 数据结构专题C题 秋实大哥与快餐店 字典树
C - 秋实大哥与快餐店 Time Limit: 1 Sec Memory Limit: 256 MB 题目连接 http://acm.uestc.edu.cn/#/contest/show/59 ...
- Shell基础学习(二) Shell变量
1.数据类型: 字符串 数组 2.变量的命名规范: 只能以a-z或A-Z开头 中间不能有空格,可以使用_ 不能使用标点符号 不能使用shell的关键字 3.变量类型: 环境变量 局部变量 shell变 ...