hash+链表
简单的hash就是用数组加链表的组合来实现,这种hash很简单,但hash的思想在那。
#ifndef _HASH_H_
#define _HASH_H_ typedef struct _ListNode
{
struct _ListNode *prev;
struct _ListNode *next;
void *data;
}ListNode; typedef ListNode *List;
typedef ListNode *Position; typedef struct _HashTbl
{
int TableSize;
List *Thelists;
}HashTbl; int Hash( void *key, int TableSize );
HashTbl *InitHash( int TableSize );
void Insert( void *key, HashTbl *HashTable );
Position Find( void *key, HashTbl *HashTable );
void Destory( HashTbl *HashTable );
void *Retrieve( Position P ); #endif
#include <stdio.h>
#include <stdlib.h>
#include "hash.h" int Hash( void *key, int TableSize )
{
char c;
int i;
int hval = 0; for( i = 1;(c = *(char *)key++) != 0; i++)
hval += c*i;
return (hval%TableSize);
} HashTbl *InitHash( int TableSize )
{
int i;
HashTbl *HashTable;
HashTable = malloc(sizeof(HashTbl));
if( NULL == HashTable )
{
printf("HashTable malloc error\n");
return;
} HashTable->TableSize = TableSize; HashTable->Thelists = malloc(sizeof(List)*TableSize);
if( NULL == HashTable->Thelists )
{
printf("HashTable malloc error\n");
return;
} for( i = 0; i < TableSize; i++)
{
HashTable->Thelists[i] = malloc(sizeof(ListNode));
if( NULL == HashTable->Thelists[i] )
{
printf("HashTable malloc error\n");
return;
}
else
{
HashTable->Thelists[i]->next = NULL;
HashTable->Thelists[i]->prev = NULL;
}
} return HashTable;
} Position Find( void *key, HashTbl *HashTable )
{
int i,j;
List L;
Position P;
i = Hash(key,HashTable->TableSize);
L = HashTable->Thelists[i];
P = L->next;
while( P != NULL && P->data != key )
P = P->next; return P;
} void Insert( void *key, HashTbl *HashTable )
{
Position P,tmp;
List L;
P = Find(key,HashTable); if( NULL == P )
{
tmp = malloc(sizeof(ListNode));
if( NULL == tmp )
{
printf("malloc error\n");
return;
}
L = HashTable->Thelists[Hash(key,HashTable->TableSize)];
tmp->data = key;
tmp->next = L->next;
if(L->next != NULL)
L->next->prev = tmp;
tmp->prev = L;
L->next = tmp;
}
else
printf("the key already exist\n");
} void *Retrieve( Position P )
{
return P->data;
} void Destory( HashTbl *HashTable )
{
int i;
List L;
Position tmp,tmp2;
for( i = 0; i < HashTable->TableSize; i++)
{
L = HashTable->Thelists[i];
tmp = L->next;
while(tmp->next != NULL)
{
tmp2 = tmp->next;
free(tmp);
tmp = tmp2;
}
free(L);
}
free(HashTable);
} void main( void )
{
HashTbl *HashTable;
HashTable = InitHash(31);
Insert("a",HashTable);
Insert("b",HashTable);
Insert("b",HashTable);
Position P;
P = Find("a",HashTable);
printf("%s\n",Retrieve(P));
}
http://blog.csdn.net/dndxhej/article/details/7396841
哈希表(hash table)是从一个集合A到另一个集合B的映射(mapping)。映射是一种对应关系,而且集合A的某个元素只能对应集合B中的一个元素。但反过来,集合B中的一个元素可能对应多个集合A中的元素。如果B中的元素只能对应A中的一个元素,这样的映射被称为一一映射。这样的对应关系在现实生活中很常见,比如:
A -> B
人 -> 身份证号
日期 -> 星座
上面两个映射中,人 -> 身份证号是一一映射的关系。在哈希表中,上述对应过程称为hashing。A中元素a对应B中元素b,a被称为键值(key),b被称为a的hash值(hash value)。

韦小宝的hash值
映射在数学上相当于一个函数f(x):A->B。比如 f(x) = 3x + 2。哈希表的核心是一个哈希函数(hash function),这个函数规定了集合A中的元素如何对应到集合B中的元素。比如:
A: 三位整数 hash(x) = x % 10 B: 一位整数
104 4
876 6
192 2
上述对应中,哈希函数表示为hash(x) = x % 10。也就是说,给一个三位数,我们取它的最后一位作为该三位数的hash值。
哈希表在计算机科学中应用广泛。比如:
Ethernet中的FCS:参看小喇叭开始广播 (以太网与WiFi协议)
IP协议中的checksum:参看我尽力 (IP协议详解)
git中的hash值:参看版本管理三国志
上述应用中,我们用一个hash值来代表键值。比如在git中,文件内容为键值,并用SHA算法作为hash function,将文件内容对应为固定长度的字符串(hash值)。如果文件内容发生变化,那么所对应的字符串就会发生变化。git通过比较较短的hash值,就可以知道文件内容是否发生变动。
再比如计算机的登陆密码,一般是一串字符。然而,为了安全起见,计算机不会直接保存该字符串,而是保存该字符串的hash值(使用MD5、SHA或者其他算法作为hash函数)。当用户下次登陆的时候,输入密码字符串。如果该密码字符串的hash值与保存的hash值一致,那么就认为用户输入了正确的密码。这样,就算黑客闯入了数据库中的密码记录,他能看到的也只是密码的hash值。上面所使用的hash函数有很好的单向性:很难从hash值去推测键值。因此,黑客无法获知用户的密码。
(之前有报道多家网站用户密码泄露的时间,就是因为这些网站存储明文密码,而不是hash值,见多家网站卷入CSDN泄密事件 明文密码成争议焦点)
注意,hash只要求从A到B的对应为一个映射,它并没有限定该对应关系为一一映射。因此会有这样的可能:两个不同的键值对应同一个hash值。这种情况叫做hash碰撞(hash collision)。比如网络协议中的checksum就可能出现这种状况,即所要校验的内容与原文并不同,但与原文生成的checksum(hash值)相同。再比如,MD5算法常用来计算密码的hash值。已经有实验表明,MD5算法有可能发生碰撞,也就是不同的明文密码生成相同的hash值,这将给系统带来很大的安全漏洞。(参考hash collision)
HASH与搜索
hash表被广泛的用于搜索。设定集合A为搜索对象,集合B为存储位置,利用hash函数将搜索对象与存储位置对应起来。这样,我们就可以通过一次hash,将对象所在位置找到。一种常见的情形是,将集合B设定在数组下标。由于数组可以根据数组下标进行随机存取(random access,算法复杂度为1),所以搜索操作将取决于hash函数的复杂程度。
比如我们以人名(字符串)为键值,以数组下标为hash值。每个数组元素中存储有一个指针,指向记录 (有人名和电话号码)。
下面是一个简单的hash函数:
#define HASHSIZE 1007
/* By Vamei * hash function */
int hash(char *p)
{
int value=0;
while((*p) != '\0') {
value = value + (int) (*p); // convert char to int, and sum
p++;
}
return (value % HASHSIZE); // won's exceed HASHSIZE
}
hash value of "Vamei": 498
hash value of "Obama": 480
我们可以建立一个HASHSIZE大小的数组records,用于储存记录。HASHSIZE被选择为质数,以便hash值能更加均匀的分布。在搜索"Vamei"的记录时,可以经过hash,得到hash值498,再直接读取records[498],就可以读取记录了。
(666666是Obama的电话号码,111111是Vamei的电话号码。纯属杜撰,请勿当真)
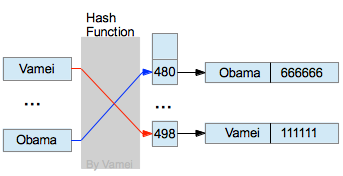
hash搜索
如果不采用hash,而只是在一个数组中搜索的话,我们需要依次访问每个记录,直到找到目标记录,算法复杂度为n。我们可以考虑一下为什么会有这样的差别。数组虽然可以随机读取,但数组下标是随机的,它与元素值没有任何关系,所以我们要逐次访问各个元素。通过hash函数,我们限定了每个下标位置可能存储的元素。这样,我们利用键值和hash函数,就可以具备相当的先验知识,来选择适当的下标进行搜索。在没有hash碰撞的前提下,我们只需要选择一次,就可以保证该下标指向的元素是我们想要的元素。
冲突
hash函数需要解决hash冲突的问题。比如,上面的hash函数中,"Obama"和"Oaamb"有相同的hash值,发生冲突。我们如何解决呢?
一个方案是将发生冲突的记录用链表储存起来,让hash值指向该链表,这叫做open hashing:
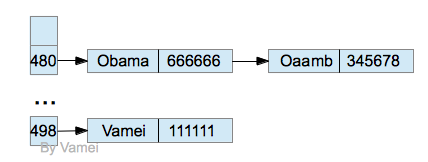
open hashing
我们在搜索的时候,先根据hash值找到链表,再根据key值遍历搜索链表,直到找到记录。我们可以用其他数据结构代替链表。
open hashing需要使用指针。我们有时候想要避免使用指针,以保持随机存储的优势,所以采用closed hashing的方式来解决冲突。
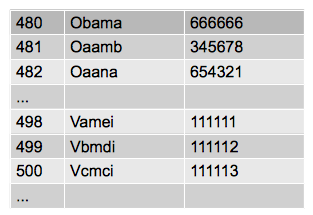
closed hashing
这种情况下,我们将记录放入数组。当有冲突出现的时候,我们将冲突记录放在数组中依然闲置的位置,比如图中Obama被插入后,随后的Oaamb也被hash到480位置。但由于480被占据,Oaamb探测到下一个闲置位置(通过将hash值加1),并记录。
closed hashing的关键在如何探测下一个位置。上面是将hash值加1。但也可以有其它的方式。概括的说,在第i次的时候,我们应该探测POSITION(i)=(h(x) + f(i)) % HASHSIZE的位置。上面将hash值加1的方式,就相当于设定f(i) = 1。当我们在搜索的时候,就可以利用POSITION(i),依次探测记录可能出现的位置,直到找到记录。
(f(i)的选择会带来不同的结果,这里不再深入)
如果数组比较满,那么closed hashing需要进行许多次探测才能找到空位。这样将大大减小插入和搜索的效率。这种情况下,需要增大HASHSIZE,并将原来的记录放入到新的比较大的数组中。这样的操作称为rehashing。
http://www.cnblogs.com/vamei/archive/2013/03/24/2970339.html
hash+链表的更多相关文章
- Hash链表
<?php /* +------------------------------------------------------------------------------ | dateti ...
- PAT 1032 Sharing[hash][链表][一般上]
1032 Sharing (25)(25 分) To store English words, one method is to use linked lists and store a word l ...
- Hash链表转换为红黑树,和树转换为链表的条件
链表转换位红黑树 两个条件,必须同时满足两个条件才能进行转换 条件1:单个链表长度大于等于8 条件2:hashMap的总长度大于64个.且树化的节点位置不能为空 从源码看 条件一: 在putVal() ...
- Redis通用操作(适用于String,Hash,链表等)
keys pattern 查询相应的key 在redis里,允许模糊查询key 有3个通配符 *, ? ,[] *: 通配任意多个字符 ?: 通配单个字符 []: 通配括号内的某1个字符 redis ...
- 深度剖析linux内核万能--双向链表,Hash链表模版
我们都知道,链表是数据结构中用得最广泛的一种数据结构,对于数据结构,有顺序存储,数组就是一种.有链式存储,链表算一种.当然还有索引式的,散列式的,各种风格的说法,叫法层出不穷,但是万变不离其中,只要知 ...
- 深入分析 Linux 内核链表--转
引用地址:http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/index.html 一. 链表数据结构简介 链表是一种常用的组织有序数据 ...
- 深入分析 Linux 内核链表
转载:http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/ 一. 链表数据结构简介 链表是一种常用的组织有序数据的数据结构,它通过指 ...
- 字符串经典的hash算法
1 概述 链表查找的时间效率为O(N),二分法为log2N,B+ Tree为log2N,但Hash链表查找的时间效率为O(1). 设计高效算法往往需要使用Hash链表,常数级的查找速度是任何别的算法无 ...
- linux2.6内核链表
一. 链表数据结构简介 链表是一种常用的组织有序数据的数据结构,它通过指针将一系列数据节点连接成一条数据链,是线性表的一种重要实现方式.相对于数组,链表具有更好的动态性,建立链 ...
随机推荐
- 算法提高 P1001【大数乘法】
当两个比较大的整数相乘时,可能会出现数据溢出的情形.为避免溢出,可以采用字符串的方法来实现两个大数之间的乘法.具体来说,首先以字符串的形式输入两个整数,每个整数的长度不会超过8位,然后把它们相乘的结果 ...
- flv 解封装
#include <stdio.h> #include <stdlib.h> #include <string.h> #define DEBUG_INFO type ...
- java结构
package com.hanqi;// 包名,必须在第一行,和namespace类似 //import java.io.*;//引用,和using类似 //import java.lang.*;// ...
- 1106 Lowest Price in Supply Chain
题意:略 思路:寻找树的叶结点中深度最低的,记录最低深度minDepth和具有相同最低深度的结点个数cnt. 代码: #include <cstdio> #include <cmat ...
- Linux系统 Centos6 安装
centos系统ios镜像下载 下载地址:https://mirrors.aliyun.com/centos/,选择对应的版本,然后下载32位,64位,一般的生产环境都是64位DVD格式,iso扩展名 ...
- 【洛谷】P3908 异或之和(异或)
题目描述 求1 \bigoplus 2 \bigoplus\cdots\bigoplus N1⨁2⨁⋯⨁N 的值. A \bigoplus BA⨁B 即AA , BB 按位异或. 输入输出格式 输入格 ...
- RAC环境TNS-12541报错处理
按照前文所述搭建好RAC环境后,发现在rac2上面无法查看到listener的状态,如下: [oracle@rac2 ~]$ lsnrctl status LSNRCTL for Linux: Ver ...
- 谷歌强制厂商升级KitKat 仍无法改善安卓碎片化
据一份泄露的内部文档显示,谷歌计划推出新的Android版本及设备审批条例,限制硬件制造商推出Android 4.4 KitKat以下的旧版本硬件,来改变平台碎片化现象.如果厂商一意孤行,继续推出搭载 ...
- jmeter4.0脚本录制
Jmeter录制脚本有两种方式.1.通过第三方工具录制比如:Badboy,然后转化为jmeter可用的脚本:2.使用jmeter本身自带的录制脚本功能. 本次使用jmeter本身自带的录制脚本功能 ...
- C++ primer plus
给cout指针,默认打印指针地址,但如果指针的类型的char*,将打印指向的字符串,如果要显示的是字符串的地址,将指针强制转换为另一种类型 char* animal cout << ani ...