【分类】AlexNet论文总结
目录
@
0. 论文链接
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
1. 概述
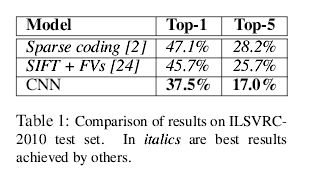
AlexNet算是第一个把CNN应用到计算机视觉领域并且十分成功。从这开始之后,开启了深度学习的浪潮,计算机视觉的主要方向也是利用深度学习来解决一系列问题,本文提出了一种5个卷积层(某些层跟着池化层),3个全连接层最后跟着1000-way的softmax,共6kw个参数650000个神经元。在imagenet lsvrc-2010中,此模型Top-1的错误率为37.5%,Top-5错误率为17%,远好于过去所用的算法水平,网络有四个亮点使用1,RELU,2利用多个GPU,3.使用LRN(Local Response Normalization)4.Overlapping Pooling,也使用了一些减少过拟合的方法。
2. 对数据集的处理
ImageNet数据集的图片分辨率各有不同。我们对图像统一下采样到256*256分辨率。除了把每个像素减去均值,没有做别的预处理,采用原生RGB像素值作为输入。
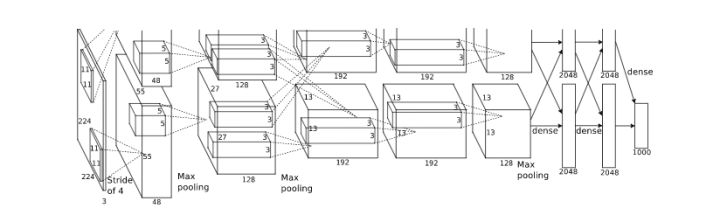
3. 网络模型
网络包含8个学习模型,其中包括5个卷积层与3个全连接层,下图为网络结构模型图。
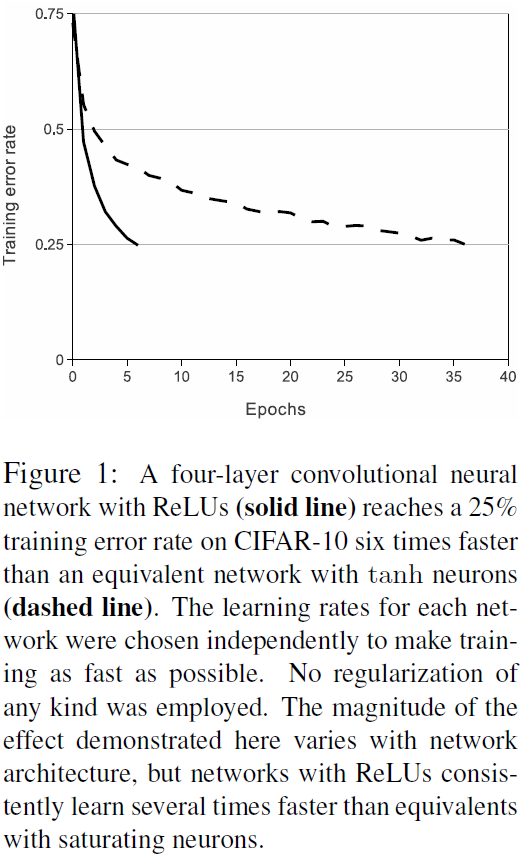
3.1 ReLU Nonlinearity
以往的激活函数通常用的是sigmod或者tanh,他们有一个问题就是就算做了标准化,还是很容易“饱和”(saturating),即数值过大,斜率便不会再增长了。 因此作者使用了ReLU函数,即Rectified Linear Units,使用ReLU作为深度神经网络的激活函数是训练速度是远远快于tanh的,下图是文章给的在CART两者的配图:
3.2 Training on multiple GPUs
一个 GTX 580 GPU 只有 3GB内存, 这限制了可训练神经网络的最大容量。所以作者把网络放在两个GPU中训练。当前的GPU很适合跨GP并行,它们可以互相直接读写不必经过主机内存。作者采取的并行化方式是 每个GPU放一半的核,另外还有一个小技巧:GPU只在特定层之间通信。例如 第三层的核以全部第二层的的特征图作为输入,第四层的核仅以第三层中同一GPU的特征图作为输入。选择这种链接方式不利于交叉验证,但是可以精确的调整通信的数量直到达到可接受的计算量。
3.3 Local Response Normalization
ReLU 不需要输入归一化解决饱和问题。只要ReLU的输入大于0就可以学习。但是 LRN( local normalization scheme )有利于增加泛化能力。局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制),响应比较大的值变得更大,抑制其他反馈比较小的神经元,增强了模型的泛化能力。
\[
b_{x,y}^{i} = a_{x, y}^{i} / (k + \alpha \sum_{j = max(0, i-n/2)}^{min(N-1,i+n/2)} (a_{x, y}^{j})^{2})^{\beta}
\]
\(a_{x, y}^{i}\)是把第\(i\)个核用在\((x,y)\)位置,\(b\)是归一化以后的值。 上述公式中的和是\(n\)个相邻的核映射(卷积完之后的特征)到同一个地方的值之和。 \(N\)是在这一层的核的总个数。
核映射的顺序是随意的并且是在训练前就确定的。 常数\(k,n,α,β\)是超参数,用验证集得到的,文中用的是\(k = 2, n = 5, \alpha = 10^{-4}, \beta = 0.75\)。
为什么可以响应比较大的值变得更大,抑制其他反馈比较小的神经元:待推理
3.4 Overlapping Pooling
相比于正常池化(步长s=2,窗口z=2) 重叠池化(步长s=2,窗口z=3) 可以减少top-1, top-5分别为0.4% 和0.3%。重叠池化可以比避免过拟合。
3.5 Overall Architecture
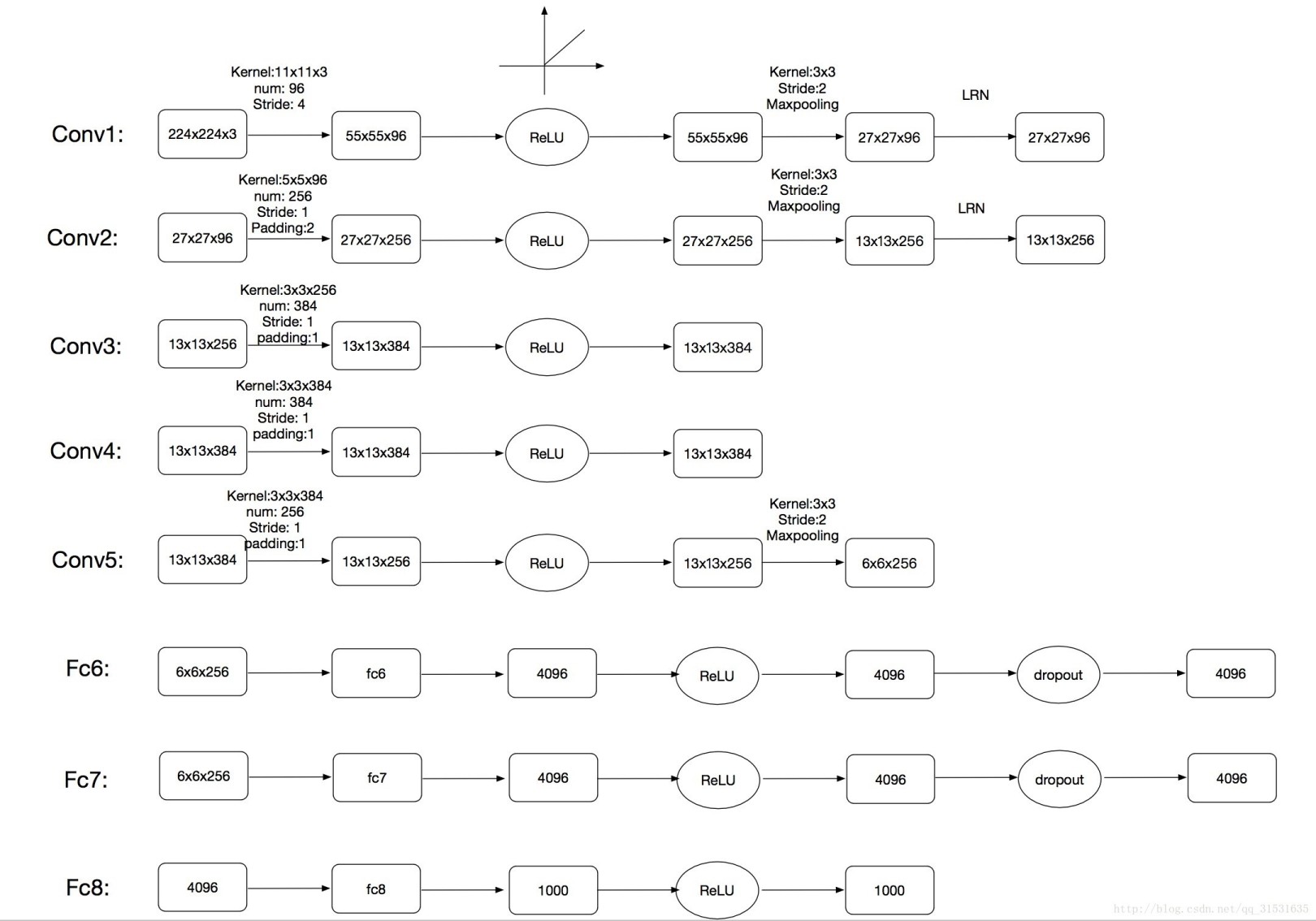
AlexNet网络包含8个带权重的层,前五层是卷积层,后三层是全连接层。最后的全连接层的输出是1000维softmax的输入,对应着1000个类别。
第2,4,5卷积层的核只与位于同一GPU上的前一层的核映射相连接。第3卷积层的核与第2层的所有核映射相连。全连接层的神经元与前一层的所有神经元相连。第1,2卷积层之后是响应归一化层。最大池化层在响应归一化层和第5卷积层之后。ReLU非线性应用在每个卷积层和全连接层的输出上
第1卷积层使用96个核对224 × 224 × 3的输入图像进行滤波,核大小为11 × 11 × 3,步长是4个像素(核映射中相邻神经元感受野中心之间的距离)。第2卷积层使用用第1卷积层的输出(响应归一化和池化)作为输入,并使用256个核进行滤波,核大小为5 × 5 × 48。第3,4,5卷积层互相连接,中间没有接入池化层或归一化层。第3卷积层有384个核,核大小为3 × 3 × 256,与第2卷积层的输出(归一化的,池化的)相连。第4卷积层有384个核,核大小为3 × 3 × 192,第5卷积层有256个核,核大小为3 × 3 × 192。每个全连接层有4096个神经元。
4. 减少过拟合
AlexNet共6kw个参数650000个神经元,所以肯定是需要控制过拟合的。
4.1 Data Augmentation
图像数据上最简单常用的用来减少过拟合的方法是使用标签保留变换来人工增大数据集,我们使用了两种在cpu上通过小型的计算完成的图像变换,当gpu在进行训练时cpu就可以进行这种变换,因此并不会对整体带来负担。
第一种是在256256上随机取224224的部分和他们的水平翻转,虽然这些增加的部分有比较高的相关性,但是没有这些的话alexnet就会有很高的过拟合,也会逼迫我们使用更小的网络,在测试的时候,我们在四角和中心取五个224*224的部分和他们的水平翻转也就是一共10个部分,然后计算他们的softmax平均值。
第二种方式是改变训练图集中的rgb通道的强度,我们在Imagenet的训练集上做pca,对每张图片我们加上主成分的倍数,即大小成正比的对应特征值乘以一个随机变量,随机变量通过均值为0,标准差为0.1的高斯分布得到。因此对于每幅RGB图像像素Ixy=
\[[I_{xy}^{R}, I_{x,y}^{G}, I_{x,y}^{B}]^{T}\]
,我们加上
\[[p_{1},p_{2},p_{3}][\alpha_{1}\lambda_{1},\alpha_{2}\lambda_{2},\alpha_{3}\lambda_{3}]^{T}\]
\(p_i\),\(λ_i\)分别是RGB像素值3 × 3协方差矩阵的第i个特征向量和特征值,\(α_i\)是前面提到的随机变量。对于某个训练图像的所有像素,每个\(α_i\)只获取一次,直到图像进行下一次训练时才重新获取。这个方案近似抓住了自然图像的一个重要特性,即降低了光照和颜色和灯光对结果的影响。这个方案减少了top 1错误率1%以上。
4.2 dropout
dropout会以0.5的概率对每个隐层神经元的输出设为0。那些“失活的”的神经元不再进行前向传播并且不参与反向传播。因此每次输入时,神经网络会采样一个不同的架构,但所有架构共享权重。这个技术减少了复杂的神经元互适应,因为一个神经元不能依赖特定的其它神经元的存在。因此,神经元被强迫学习更鲁棒的特征,它在与许多不同的其它神经元的随机子集结合时是有用的。在测试时,我们使用所有的神经元但它们的输出乘以0.5.相当于多个模型集成学习,可以很有效的抑制过拟合。
5. details of learning
使用能动随机梯度下降,batch大小128,momentum0.9 权重衰减0.0005 少量的权重衰减对于模型的学习是重要的。换句话说,权重衰减不仅仅是一个正则项:它减少了模型的训练误差。权重w的更新规则是
\[
v_{i+1} := 0.9 * v_i - 0.0005 * \epsilon * w_i - \epsilon *<\frac{\partial L}{\partial w}|_{w_i}>_{D_i}
\]
\[
w_{i+1} := w_i +v_{i+1}
\]
其中\(i\)为迭代次数的下标,\(v\)为能动值,\(\epsilon\)为学习率,\(<\frac{\partial L}{\partial w}|_{w_i}>_{D_i}\)是第i个batch上关于\(w_i\)的偏导数的均值
我们使用均值为0,标准差为0.01的高斯分布对每一层的权重进行初始化。我们在第2,4,5卷积层和全连接隐层将神经元偏置初始化为常量1。这个初始化通过为ReLU提供正输入加速了学习的早期阶段。我们在剩下的层将神经元偏置初始化为0。
我们对所有的层使用相等的学习率,这个是在整个训练过程中我们手动调整得到的。当验证误差在当前的学习率下停止提供时,我们遵循启发式的方法将学习率除以10。学习率初始化为0.01,在训练停止之前降低三次。我们在120万图像的训练数据集上训练神经网络大约90个循环,在两个NVIDIA GTX 580 3GB GPU上花费了五到六天。
效果
【分类】AlexNet论文总结的更多相关文章
- < AlexNet - 论文研读个人笔记 >
Alexnet - 论文研读个人笔记 一.论文架构 摘要: 简要说明了获得成绩.网络架构.技巧特点 1.introduction 领域方向概述 前人模型成绩 本文具体贡献 2.The Dataset ...
- AlexNet论文翻译-ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 深度卷积神经网络的ImageNet分类 Alex Krizhevsky ...
- AlexNet论文总结
论文链接:https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf Q1:解决了什么? 目前主 ...
- 【深度学习 论文篇 01-1 】AlexNet论文翻译
前言:本文是我对照原论文逐字逐句翻译而来,英文水平有限,不影响阅读即可.翻译论文的确能很大程度加深我们对文章的理解,但太过耗时,不建议采用.我翻译的另一个目的就是想重拾英文,所以就硬着头皮啃了.本文只 ...
- AlexNet—论文分析及复现
AlexNet卷积神经网络是由Alex Krizhevsky等人在2012年的ImagNet图像识别大赛获得冠军的一个卷积神经网络,该网络放到现在相对简单,但也是深度学习不错的卷积神经网络.论文:&l ...
- 论文笔记:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
2014 ICLR 纽约大学 LeCun团队 Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann ...
- tensorflow学习笔记——AlexNet
1,AlexNet网络的创新点 AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中.AlexNet主要使用到的新技术点如下: (1)成功使用ReLU作为CNN的激活函 ...
- 深入理解AlexNet网络
原文地址:https://blog.csdn.net/luoluonuoyasuolong/article/details/81750190 AlexNet论文:<ImageNet Classi ...
- CNN 文本分类
谈到文本分类,就不得不谈谈CNN(Convolutional Neural Networks).这个经典的结构在文本分类中取得了不俗的结果,而运用在这里的卷积可以分为1d .2d甚至是3d的. 下面 ...
随机推荐
- 微信公众号获取用户openId How to use cURL to get jSON data and decode the data?
w http://stackoverflow.com/questions/16700960/how-to-use-curl-to-get-json-data-and-decode-the-data
- 剑指Offer——连续子数组的最大和
题目描述: HZ偶尔会拿些专业问题来忽悠那些非计算机专业的同学.今天测试组开完会后,他又发话了:在古老的一维模式识别中,常常需要计算连续子向量的最大和,当向量全为正数的时候,问题很好解决.但是,如果向 ...
- LeetCode_Isomorphic Strings
Isomorphic Strings Given two strings s and t, determine if they are isomorphic. Two strings are isom ...
- LeetCode_Search Insert Position
Given a sorted array and a target value, return the index if the target is found. If not, return the ...
- Linux的概念与体系(转)
学linux就用它了 http://www.cnblogs.com/vamei/archive/2012/10/10/2718229.html
- 前端 javascript 写代码方式
javascript 和python一样可以用终端写代码 写Js代码: - html文件中编写 - 临时,浏览器的终端 console
- PAT 1033 To Fill or Not to Fill[dp]
1033 To Fill or Not to Fill(25 分) With highways available, driving a car from Hangzhou to any other ...
- oracle的统计信息的查看与收集
查看某个表的统计信息 SQL> alter session set NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'; Session altered. SQL&g ...
- Oracle 性能调优 SQL_TRACE
思维导图 Oracle优化10-SQL_TRACE解读 Oracle优化11-10046事件 概述 当我们想了解一条SQL或者是PL/SQL包的运行情况时,特别是当他们的性能非常差时,比如有的时候看起 ...
- PHP实现excel导出
首先去下载PHPExcel类,地址http://phpexcel.codeplex.com/ 方法如下第一步引入这个扩展类 Vendor('PHPExcel'); 第二部就是方法了,下面简单的实现方法 ...