HadoopMR-Spark-HBase-Hive

YARN资源调度:
三种
FIFO
大任务独占 一堆小任务独占
capacity 弹性分配 :计算任务较少时候可以利用全部的计算资源,当队列的任务多的时候会按照比例进行资源平衡。
容量保证:保证队列可以获取到资源利用。
安全:ACL访问控制限制 用户只能向自己的队列提交任务。
Fair
Yarn资源调度模型:
当向yarn提交任务之后,ResourceManager会启动NodeManager。
NodeManager会启动APPManager。
APPManager向ResourceManager申请资源,目的领取用于任务计算的container。(心跳发送请求)
(第一层资源调度)ResourceManager作为响应会把container发送给 APPManager ( 但是这个过程不是push那么简单,而是container被放到一个缓存池,下次AM心跳的时候会将资源pull走)
(第二层资源调度)AppManager拿到container之后会分配给task
资源抢占:正常合理的抢占,是由于某个小队列存在空闲资源,会被调度器临时分配给负载较重的队列,但是如果那个小队列突然需要资源进行处理任务,会向那个大队列收回资源,要求物归原主,但是这部分资源还在使用中,此时小队列会等待一段时间,稍后资源如果还没释放,那么小队列就会抢占那部分资源。非常合理。
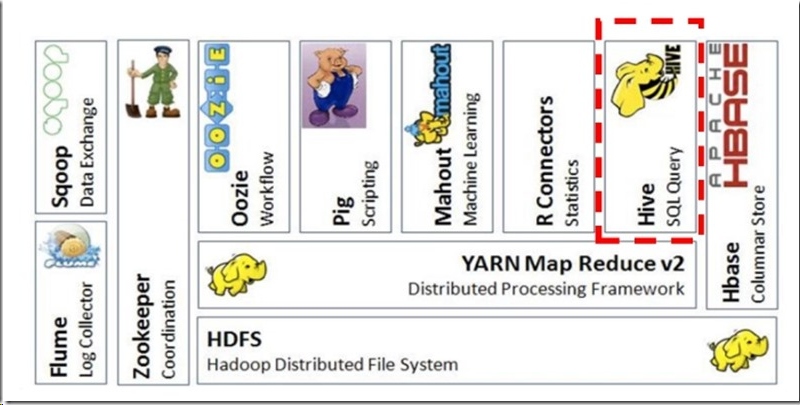
关于Hive的了解:
基本架构
用户接口,可以直接操作的接口。CLI(命令行界面)JDBC/ODBC(java访问hive)WEBUI(浏览器访问Hive)
元数据:表所属的数据库,表名,表的字段,表的拥有者等等
Hadoop 使用HDFS进行数据存储,使用MapReduce进行计算。(可以使用tez)进行计算,测试环境下比MapReduce查询效果较好。但是相比于HBase。那接着下文……
对比一下HBase和Hive
HBase的构建是用于海量数据的查询,是一种NoSQL数据库,在存储结构的设计上便是优于查询。Hive用于设计数据仓库,使用类SQL的操作方式来存储结构化数据,主要目的是用于存储,以及离线的批量数据计算。Hive会将SQL翻译成对应的MR任务提交给Yarn进行计算。在实际的生产环境中,可以把HBase和Hive看作是协作关系。(参考知乎https://www.zhihu.com/question/21677041)通过ETL(extract-transform-load)的方式将数据存在HDFS中,Hive对数据进行清洗处理计算。可以将最终的数据存入HBase中,用于查询。
对比一下MapReduce\Tez\Storm\Spark四个框架
MapReduce:是一种离线的计算型框架,将算法抽象成Map和Reduce两个阶段,适合密集型数据计算。不适合迭代计算和交互式计算。缺点是,就只有Map和Reduce操作,需要大量IO,无法利用内存资源,几乎全是磁盘开销。Spark内存计算:适合迭代计算,可以把MR理解为一种磁盘计算框架,而Spark是一种内存型计算框架,将数据放在内存中计算可以提高计算效率,但这对计算的硬件的要求较高。使用scala进行编程更为出色。DAG执行引擎。所以在数据规模和时效性要求两个方面考量是用MR计算还是用Spark计算。Storm:往往跟实时流计算关联。Storm更加擅长对流式计算、实时分析等这种实时计算。实时性能远好于MapReduce。Tez:本质上是对MapReduce进行的优化,用于提高MapReduce的运行效率。依赖DAG作为核心算法模型,可以将MR任务拆分成多个子过程计算,也可以将多个MR任务合并成一个较大的DAG(下面有介绍)任务(可以省去好多存储时间,更专注于计算)。多用于Hive查询优化,用来替代原来的低效MR。
DAG在Hadoop中的应用场景
定义:有向图,从某一点出发无法回到原点。
- Tez
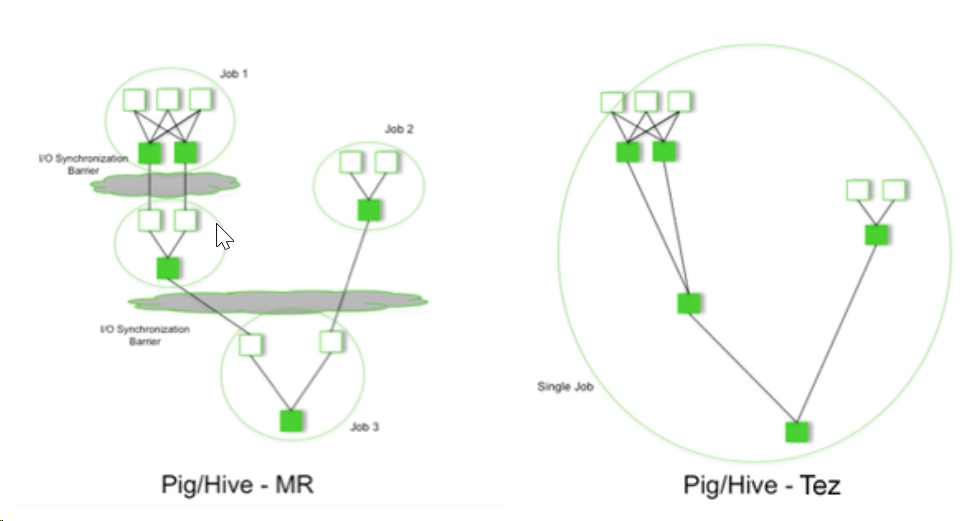
从图中可以看到MR好Tez的区别。比较明显,MR产生中间结果,需要一步步进行。而Tez不产生中间结果,是一气呵成,将多个任务连接成single job,中间的值是直接传递而来,不涉及存取过程。 - Spark
对,就是RDD,一提及Spark的DAG,很快就会联想到Spark的RDD,学 Spark的时候了解到 RDD的两种操作, transform和 action, 其中 transform是一种延时性操作,只有当发生action动作的时候,前面的transform才会执行。理解理解吧,这就是DAG设计啊。 - Oozie
还没使用过,做个了解。是Apache的顶级项目。
主要用于创建工作流,将多个MR/Spark/Pig……任务串在一起,专门针对大规模复杂工作流程和数据管道设计。这个工作流就是DAG图。
WordCount流程详解-描述MR原理
链接-这篇博客讲解的很好
Map执行之前:数据文件是存在多个dataNode上的,hadoop将多个文件块进行分片,得到多个split。每一个split都在各自节点的mapper进行读取。然后每一个节点都把split切割成一行一行的键值对,键是每一行在split中的偏移量,值是每一行的字符串。
Map方法:读取键值对,对值进行切割(一般按空格)。然后以切割后的值为键,key设置为1组成新的键值对。
Map-Shuffle:
partition分组-将一类的键值对分到一组
sort-组内进行排序
combine-组内合并(类似于reduce)
此时,每个map上都有多个分组,每个分组内的键唯一(因为已经进行了combine操作)
Reduce-Shuffle:
reduce节点依照它所需要的键,从不同的map的一个partition(组)里拉取键值对。
reduce内对键值对进行merge,把相同键的键值对合并,比如说<boot,2>和<boot,1>合并为<boot,List(2,1)>,merge之后再进行sort排序
reduce:
<boot,List(2,1)>变成<boot,3>
<black,2>变成<black,2>
然后将生成的结果写在每个reduce节点的文件块上。对外查询表现为一个完整的结果文件(分块存储)。
总之:读数据->split-><偏移,字符串>-> map -> <单词,1> ->partition->sort->combine->reduce-shuffle从map节点拉取->merge->sort->reduce->存储
hadoop调度器,列举简要说明工作方法,优缺点
- FIFO 先到先服务。不设优先级。简单明了,但是忽略了不同作业的需求差异。
- Capacity 计算能力调度,支持多个队列,队列内采用FIFO调度。选择占用最小优先级高的先执行。实际的调度情况是,选队列:队列任务数/队列资源数,比值最小的队列会被选择。选队列中的作业:考虑优先级和提交顺序。
- Fair 支持多队列多用户。几乎每个作业都能公平分到等量的资源。
MapReduce 自己动手实现一个数据类型(类似Text,LongWritable..)
可以通过WritableComparable接口来实现
public class FlowBean implements WritableComparable<FlowBean> {
private String phoneNbr;
private long up_flow;
private long d_flow;
private long sum_flow;
public void set(String phoneNbr, long up_flow, long d_flow){
this.phoneNbr = phoneNbr;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.sum_flow = up_flow + d_flow;
}
……以下重写方法略去 需要添加每个变量的getter, setter方法
}
MapReduce 自己动手实现一个分区partitioner
可以通过继承Partitioner<KEY, VALUE>来实现
public class AreaPartitioner<KEY, VALUE> extends Partitioner<KEY, VALUE>{
private static HashMap<String, Integer> areaMap = new HashMap<>();
//指定分区
static {
areaMap.put("136", 0);
areaMap.put("137", 1);
areaMap.put("138", 2);
areaMap.put("139", 3);
}
//需要重写getPartiotion方法
@Override
public int getPartition(KEY key, VALUE value, int numPartitions) {
Integer provinceCode = areaMap.get(key.toString().substring(0,3));
return provinceCode==null?4:provinceCode;
}
}
MapReduce:实现join的几种简单方法
理解为 有两份数据data1,data2(或者两个table1,table2 ,两份文件file1,file2),都是大数据,要通过mapreduce的方式进行关键词连接。两份数据无外乎三种情况。数据量一样都很小,或者一大一小,或者一样都很大。三种情况分别对应以下三种比较合适的操作。
以下为个人见解
- reduce join
join操作发生在reduce阶段,这种比较容易理解,简单明了。map阶段,对数据进行贴标签,每一个<key,value>,key不变,在value中增加tag用来标记数据来自哪份文件,与原value值组合构成新的value。也即<key,<tag,value>>。在Reduce阶段,对相同key的键值对进行判断数据来源,对同key不同源的value进行笛卡尔积操作。
占个坑,有空画操作流程图
- map join
reduce进行join操作,如果数据很大,内存就吃不消,而且shuffle阶段本来就非常耗费网络资源,现在还要多一个标签数据。
数据一大一小的情况下,可以考虑将小数据加载到内存中,并且将数据复制到各个map端,map端独自扫描分到的那份大数据,与内存中的小数据进行比较,如果有相同的key则可以进行连接。 - SemiJoin(半连接)
操作方式是,在map端将不参与连接的数据进行过滤,节省内存和网络资源。只将其中一份数据的key列(可能也会包含其他需要连接的数据列,一般都是只有一列key)数据加载到内存中,map端分到的数据与内存中的key进行比对,删除不与内存中key的对应的数据。接下来就是类似reduce join的操作。这种方式是比较好的,就是稍微麻烦了一些。但是,如果遇到了超级超级大的数据,提取一列key加载到内存中还是无法避免出现OOM的情况。
wordcount详解shuffle机制
放个链接在这儿。迄今见到的讲得最好的了。wordcount详解shuffle机制
HadoopMR-Spark-HBase-Hive的更多相关文章
- Docker搭建大数据集群 Hadoop Spark HBase Hive Zookeeper Scala
Docker搭建大数据集群 给出一个完全分布式hadoop+spark集群搭建完整文档,从环境准备(包括机器名,ip映射步骤,ssh免密,Java等)开始,包括zookeeper,hadoop,hiv ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- Spark访问Hive表
知识点1:Spark访问HIVE上面的数据 配置注意点:. 1.拷贝mysql-connector-java-5.1.38-bin.jar等相关的jar包到你${spark_home}/lib中(sp ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
- spark集成hive遭遇mysql check失败的问题
问题: spark集成hive,启动spark-shell或者spark-sql的时候,报错: INFO MetaStoreDirectSql: MySQL check failed, assumin ...
- java+hadoop+spark+hbase+scala+kafka+zookeeper配置环境变量记录备忘
java+hadoop+spark+hbase+scala 在/etc/profile 下面加上如下环境变量 export JAVA_HOME=/usr/java/jdk1.8.0_102 expor ...
- 使用spark对hive表中的多列数据判重
本文处理的场景如下,hive表中的数据,对其中的多列进行判重deduplicate. 1.先解决依赖,spark相关的所有包,pom.xml spark-hive是我们进行hive表spark处理的关 ...
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
随机推荐
- win7 64位环境下配置汇编环境和程序设计
下载dosbox,并解压安装 下载地址: http://pan.baidu.com/s/1eRJbJAq 默认安装到C:\Program Files (x86)\DOSBox-0.74 安装成功后,双 ...
- python使用pwd和grp操作unix用户及用户组
1.pwd模块 pwd模块提供了一个unix密码数据库即/etc/passwd的操作接口,这个数据库包含本地机器用户帐户信息 常用操作如下: pwd.getpwuid(uid):返回对应uid的示例信 ...
- webpack中Module build failed: Unknown word (2:1)
在新建的webpack.config.js文件中配置好style-loader和css-loader,注意顺序为:style-loader,css-loader,less-loader,postcss ...
- C语言 结构体作为参数和返回值使用
方案一:结构体变量作为参数,进行传值. 编译器需要拷贝,不影响origin value,使用成员操作符(.)直接访问 /**************************************** ...
- 怎样把一个DIV放到另一个div右下角
怎样把一个DIV放到另一个div右下角??? 借助CSS定位来实现,你将右下角的那个DIV放在另一个DIV里面,参考代码如下示: <div id="box1"> < ...
- NOIP模拟7
期望得分:100+100+20=220 实际得分:100+95+20=215 T1 洛谷 P1306 斐波那契公约数 #include<cstdio> #include<cstrin ...
- jQuery面向对象的写法
定义的写法 //构造函数 function test(){ //construct code } //初始化方法 test.prototype.init = function(){ //init co ...
- CSS居中之美
关于居中,你会想到什么? div{margin: auto;} 常见的居中方法 水平居中 .demo{ text-align: center; margin: auto; position: abso ...
- ASP.Net中表单POST到其他页面的方法
在ASP中,我们通常把表单提交到另外一个页面(接受数据页面).但是在ASP.NET中,服务端表单通常都是提交到本页面的,如果我设置 form1.action="test.aspx" ...
- mysql数据库单表增删改查命令
数据库DB-database-mysql 课程安排 第一天: 1.数据库定义以及设计 2.mysql服务端的安装 3.mysql-dos操作 库的操作 表的操作 4.mysql客户端navicate工 ...