day32 Python与金融量化分析(二)
第一部分:金融与量化投资
股票:
- 股票是股份公司发给出资人的一种凭证,股票的持有者就是股份公司的股东。
股票的面值与市值
- 面值表示票面金额
- 市值表示市场价值
上市/IPO:
- 企业通过证券交易所公开向社会增发股票以募集资金
股票的作用:
- 出资证明、证明股东身份、对公司经营发表意见
- 公司分红、交易获利
股票的分类
股票按业绩分类:
- 蓝筹股:资本雄厚、信誉优良的公司的股票
- 绩优股:业绩优良公司的股票
- ST股:特别处理股票,连续两年亏损或每股净资产低于股票面值
股票按上市地区分类:
- A股:中国大陆上市,人民币认购买卖(T+1,涨跌幅10%)
- B股:中国大陆上市,外币认购买卖(T+1,T+3)
- H股:中国香港上市(T+0,涨跌幅不设限制)
- N股:美国纽约上市
- S股:新加坡上市
股票市场的构成
- 上市公司
- 投资者(包括机构投资者)
- 证监会、证券业协会、交易所
- 证券中介机构
交易所
- 上海证券交易所:只有一个主板(沪指)
- 深圳证券交易所:
- 主板:大型成熟企业(深成指)
- 中小板:经营规模较小
- 创业板:尚处于成长期的创业企业
影响股价的因素
- 公司自身因素:股票自身价值是决定股价最基本的因素,而这主要取决于发行公司的经营业绩、资信水平以及连带而来的股息红利派发状况、发展前景、股票预期收益水平等。
- 行业因素:行业在国民经济中地位的变更,行业的发展前景和发展潜力,新兴行业引来的冲击等,以及上市公司在行业中所处的位置,经营业绩,经营状况,资金组合的改变及领导层人事变动等都会影响相关股票的价格。
- 市场因素:投资者的动向,大户的意向和操纵,公司间的合作或相互持股,信用交易和期货交易的增减,投机者的套利行为,公司的增资方式和增资额度等,均可能对股价形成较大影响。
- 心理因素:情绪波动,判断失误,盲目追随大户、狂抛抢购
- 经济因素:经济周期,国家的财政状况,金融环境,国际收支状况,行业经济地位的变化,国家汇率的调整等
- 政治因素
股票买卖(A股)
- 委托买卖股票 : 个人不能直接买卖,需要在券商开户,进行委托购买
- 股票交易日:周一到周五(非法定节假日和交易所休市日)
- 股票交易时间:
- 9:15-9:25 开盘集合竞价时间
- 9:30-11:30 前市,连续竞价时间
- 13:00-15:00 后市,连续竞价时间
- 14:57-15:00 深交所收盘集合竞价时间
- T+1交易制度:股票买入后当天不能卖出,要在买入后的下一个交易日才能卖出
- 涨停、跌停限制
金融分析
基本面分析
- 宏观经济面分析:国家的财政政策、货币政策等
- 行业分析
- 公司分析:财务数据、业绩报告等
技术面分析:各项技术指标
- K线
- MA(均线)
- KDJ(随机指标)
- MACD(指数平滑移动平均线)
- ……
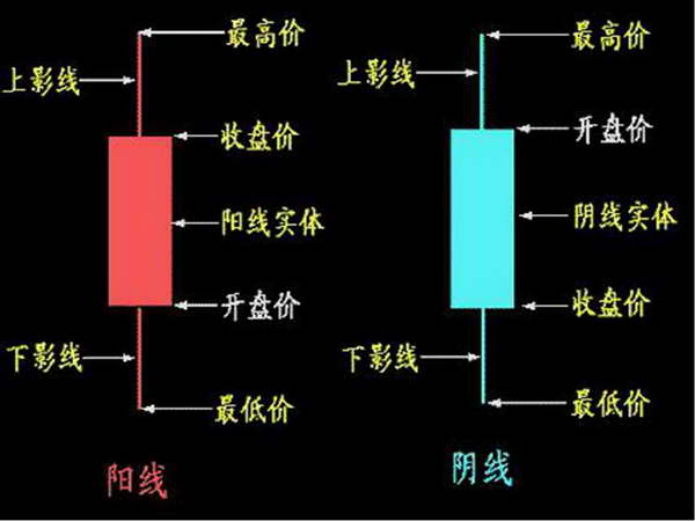
K线
金融量化投资
- 量化投资:利用计算机技术并且采用一定的数学模型去实践投资理念,实现投资策略的过程。
- 量化投资的优势:
- 避免主观情绪、人性弱点和认知偏差,选择更加客观
- 能同时包括多角度的观察和多层次的模型
- 及时跟踪市场变化,不断发现新的统计模型,寻找交易机会
- 在决定投资策略后,能通过回测验证其效果
量化策略
- 量化策略:通过一套固定的逻辑来分析、判断和决策,自动化地进行股票交易。
- 核心内容
- 选股
- 择时
- 仓位管理
- 止盈止损
- 策略的周期
- 产生想法/学习知识
- 实现策略:Python
- 检验策略:回测/模拟交易
- 实盘交易
- 优化策略/放弃策略
第二部分:量化投资与Python
量化投资与Python
- 为什么选择Python?
- 其他选择:Excel、SAS/SPSS、R
- 量化投资第三方相关模块
- NumPy:数值计算
- pandas:数据分析
- Matplotlib:图标绘制
- 如何使用Python进行量化投资
- 自己编写:NumPy+pandas+Matplotlib+……
- 在线平台:聚宽、优矿、米筐、Quantopian、……
- 开源框架:RQAlpha、QUANTAXIS、……
Ipython:交互式的Python命令行
- IPython:安装:pip install ipython
- TAB键自动完成
- ?命令(内省、命名空间搜索)
- 执行系统命令(!)
- %run命令执行文件代码
- %paste %cpaste命令执行剪贴板代码
- 与编辑器和IDE交互
- 魔术命令:%timeit %pdb …
- 使用命令历史
- 输入与输出变量(_, __, _2, _i2)
- 目录书签系统 %bookmark
- Ipython Notebook
Ipython常用的魔术命令


Python调试器命令


Ipython快捷键

NumPy:数组计算
- NumPy是高性能科学计算和数据分析的基础包。它是pandas等其他各种工具的基础。
- NumPy的主要功能:
- ndarray,一个多维数组结构,高效且节省空间
- 无需循环对整组数据进行快速运算的数学函数
- *读写磁盘数据的工具以及用于操作内存映射文件的工具
- *线性代数、随机数生成和傅里叶变换功能
- *用于集成C、C++等代码的工具
- 安装方法:pip install numpy
- 引用方式:import numpy as np
NumPy:ndarray-多维数组对象
- 创建ndarray:np.array()
- 为什么要使用ndarray:
- 例1:已知若干家跨国公司的市值(美元),将其换算为人民币
- 例2:已知购物车中每件商品的价格与商品件数,求总金额
- ndarray还可以是多维数组,但元素类型必须相同
- 常用属性:
- T 数组的转置(对高维数组而言)
- dtype 数组元素的数据类型
- size 数组元素的个数
- ndim 数组的维数
- shape 数组的维度大小(以元组形式)
NumPy:ndarray-多维数组对象
- dtype:
- bool_, int(8,16,32,64), uint(8,16,32,64), float(16,32,64)
- 类型转换:astype()
- 创建ndarray:
- array() 将列表转换为数组,可选择显式指定dtype
- arange() range的numpy版,支持浮点数
- linspace() 类似arange(),第三个参数为数组长度
- zeros() 根据指定形状和dtype创建全0数组
- ones() 根据指定形状和dtype创建全1数组
- empty() 根据指定形状和dtype创建空数组(随机值)
- eye() 根据指定边长和dtype创建单位矩阵
NumPy:索引和切片
- 数组和标量之间的运算
- a+1 a*3 1//a a**0.5
- 同样大小数组之间的运算
- a+b
- a/b
- a**b
- 数组的索引
- a[5]
- a2[2][3]
- a2[2,3]
- 数组的切片
- a[5:8]
- a[:3] = 1
- a2[1:2, :4]
- a2[:,:1]
- a2[:,1]
- 与列表不同,数组切片时并不会自动复制,在切片数组上的修改会影响原数组。
- b = a[:4]
- b[-1] = 250
- 解决方法:
- copy()】 b = a[:4] b[-1] = 250
NumPy:布尔型索引
- 问题:给一个数组,选出数组中所有大于5的数。
- 答案:a[a>5]
- 原理: a>5会对a中的每一个元素进行判断,返回一个布尔数组 布尔型索引:将同样大小的布尔数组传进索引,会返回一个由所有True对应位置的元素的数组
- 问题2:给一个数组,选出数组中所有大于5的偶数。
- 问题3:给一个数组,选出数组中所有大于5的数和偶数。
- 答案: a[(a>5) & (a%2==0)] a[(a>5) | (a%2==0)]
NumPy:花式索引*
- 问题1:对于一个数组,选出其第1,3,4,6,7个元素,组成新的二维数组。
- 答案:a[[1,3,4,6,7]]
- 问题2:对一个二维数组,选出其第一列和第三列,组成新的二维数组。
- 答案:a[:,[1,3]]
NumPy:通用函数
- 通用函数:能同时对数组中所有元素进行运算的函数
- 常见通用函数:
- 一元函数:abs, sqrt, exp, log, ceil, floor, rint, trunc, modf, isnan, isinf, cos, sin, tan
- 二元函数:add, substract, multiply, divide, power, mod, maximum, mininum,
NumPy:数学和统计方法
- 常用函数:
- sum 求和
- mean 求平均数
- std 求标准差 v
- ar 求方差
- min 求最小值
- max 求最大值
- argmin 求最小值索引
- argmax 求最大值索引
NumPy:随机数生成
- 常用函数
- rand 给定形状产生随机数组(0到1之间的数)
- randint 给定形状产生随机整数
- choice 给定形状产生随机选择
- shuffle 与random.shuffle相同
- uniform 给定形状产生随机数组
pandas:数据分析
- pandas是一个强大的Python数据分析的工具包。
- pandas是基于NumPy构建的。
- pandas的主要功能
- 具备对其功能的数据结构DataFrame、Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
- 安装方法:pip install pandas
- 引用方法:import pandas as pd
pandas:Series
- Series是一种类似于一位数组的对象,由一组数据和一组与之相关的数据标签(索引)组成。
- Series比较像列表(数组)和字典的结合体
- 创建方式:
- pd.Series([4,7,-5,3])
- pd.Series([4,7,-5,3],index=['a','b','c','d'])
- pd.Series({'a':1, 'b':2})
- pd.Series(0, index=['a','b','c','d'])
- 获取值数组和索引数组:
- values属性
- index属性
pandas:Series特性
- Series支持NumPy模块的特性(下标):
- 从ndarray创建Series:Series(arr)
- 与标量运算:sr*2
- 两个Series运算:sr1+sr2
- 索引:sr[0], sr[[1,2,4]]
- 切片:sr[0:2](切片依然是视图形式)
- 通用函数:np.abs(sr)
- 布尔值过滤:sr[sr>0]
- 统计函数:mean() sum() cumsum()
pandas:整数索引
- 整数索引的pandas对象往往会使新手抓狂。
- 例:
- sr = np.Series(np.arange(4.))
- sr[-1]
- 如果索引是整数类型,则根据整数进行数据操作时总是面向标签的。
- loc属性 以标签解释
- iloc属性 以下标解释
pandas:Series数据对齐
- pandas在运算时,会按索引进行对齐然后计算。如果存在不同的索引,则结果的索引是两个操作数索引的并集。
- 例:
- sr1 = pd.Series([12,23,34], index=['c','a','d'])
- sr2 = pd.Series([11,20,10], index=['d','c','a',])
- sr1+sr2
- sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
- sr1+sr3
- 如何在两个Series对象相加时将缺失值设为0?
- sr1.add(sr2, fill_value=0)
- 灵活的算术方法:add, sub, div, mul
pandas:Series缺失数据
- 缺失数据:使用NaN(Not a Number)来表示缺失数据。其值等于np.nan。内置的None值也会被当做NaN处理。
- 处理缺失数据的相关方法:
- dropna() 过滤掉值为NaN的行
- fillna() 填充缺失数据
- isnull() 返回布尔数组,缺失值对应为True
- notnull() 返回布尔数组,缺失值对应为False
- 过滤缺失数据:
- sr.dropna()
- sr[data.notnull()]
- 填充缺失数据:fillna(0)
pandas:DataFrame
- DataFrame是一个表格型的数据结构,含有一组有序的列。
- DataFrame可以被看做是由Series组成的字典,并且共用一个索引。
- 创建方式:
- pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
- pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']), 'two':pd.Series([1,2,3,4],index=['b','a','c','d'])})
- ……
- csv文件读取与写入:
- df.read_csv('filename.csv')
- df.to_csv()
pandas:DataFrame查看数据
- 查看数据常用属性及方法:
- index 获取索引
- T 转置
- columns 获取列索引
- values 获取值数组
- describe() 获取快速统计
- DataFrame各列name属性:列名
- rename(columns={})
pandas:DataFrame索引和切片
- DataFrame有行索引和列索引。
- 通过标签获取:
- df['A']
- df[['A', 'B']]
- df['A'][0]
- df[0:10][['A', 'C']]
- df.loc[:,['A','B']]
- df.loc[:,'A':'C']
- df.loc[0,'A']
- df.loc[0:10,['A','C']]
- 通过位置获取:
- df.iloc[3]
- df.iloc[3,3]
- df.iloc[0:3,4:6]
- df.iloc[1:5,:]
- df.iloc[[1,2,4],[0,3]]
- 通过布尔值过滤:
- df[df['A']>0]
- df[df['A'].isin([1,3,5])]
- df[df<0] = 0
pandas:DataFrame数据对齐与缺失数据
- DataFrame对象在运算时,同样会进行数据对其,结果的行索引与列索引分别为两个操作数的行索引与列索引的并集。
- DataFrame处理缺失数据的方法:
- dropna(axis=0,how='any',…)
- fillna()
- isnull()
- notnull()
pandas:其他常用方法
- pandas常用方法(适用Series和DataFrame):
- mean(axis=0,skipna=False)
- sum(axis=1)
- sort_index(axis, …, ascending) 按行或列索引排序
- sort_values(by, axis, ascending) 按值排序
- NumPy的通用函数同样适用于pandas
- apply(func, axis=0) 将自定义函数应用在各行或者各列上 ,func可返回标量或者Series
- applymap(func) 将函数应用在DataFrame各个元素上
- map(func) 将函数应用在Series各个元素上
*pandas:层次化索引
- 层次化索引是Pandas的一项重要功能,它使我们能够在一个轴上拥有多个索引级别。
- 例:data=pd.Series(np.random.rand(9), index=[['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c'], [1,2,3,1,2,3,1,2,3]])
pandas:时间对象处理
- 时间序列类型:
- 时间戳:特定时刻
- 固定时期:如2017年7月
- 时间间隔:起始时间-结束时间
- Python标准库:datetime
- date time datetime timedelta
- dt.strftime()
- strptime()
- 第三方包:dateutil
- dateutil.parser.parse()
- 成组处理日期:pandas
- pd.to_datetime(['2001-01-01', '2002-02-02'])
- 产生时间对象数组:date_range
- start 开始时间
- end 结束时间
- periods 时间长度
- freq 时间频率,默认为'D',可选H(our),W(eek),B(usiness),S(emi-)M(onth),(min)T(es), S(econd), A(year),…
pandas:时间序列
- 时间序列就是以时间对象为索引的Series或DataFrame。
- datetime对象作为索引时是存储在DatetimeIndex对象中的。
- 时间序列特殊功能:
- 传入“年”或“年月”作为切片方式
- 传入日期范围作为切片方式
pandas:从文件读取
- 读取文件:从文件名、URL、文件对象中加载数据
- read_csv 默认分隔符为csv
- read_table 默认分隔符为\t
- read_excel 读取excel文件
- 读取文件函数主要参数:
- sep 指定分隔符,可用正则表达式如'\s+'
- header=None 指定文件无列名
- names 指定列名
- index_col 指定某列作为索引
- skip_row 指定跳过某些行
- na_values 指定某些字符串表示缺失值
- parse_dates 指定某些列是否被解析为日期,布尔值或列表
pandas:写入到文件
- 写入到文件: to_csv
- 写入文件函数的主要参数:
- sep
- na_rep 指定缺失值转换的字符串,默认为空字符串
- header=False 不输出列名一行
- index=False 不输出行索引一列
- cols 指定输出的列,传入列表
- 其他文件类型:json, XML, HTML, 数据库
- pandas转换为二进制文件格式(pickle):
- save
- load
Matplotlib:绘图和可视化
- Matplotlib是一个强大的Python绘图和数据可视化的工具包。
- 安装方法:pip install matplotlib
- 引用方法:import matplotlib.pyplot as plt
- 绘图函数:plt.plot()
- 显示图像:plt.show()
Matplotlib:plot函数
- plot函数:
- 线型linestyle(-,-.,--,..)
- 点型marker(v,^,s,*,H,+,x,D,o,…)
- 颜色color(b,g,r,y,k,w,…)
- plot函数绘制多条曲线
- 标题:title
- x轴:xlabel
- y轴:ylabel
- 其他类型图像:
- hist 频数直方图
*Matplotlib:画布与图
- 画布:figure
- fig = plt.figure()
- 图:subplot
- ax1 = fig.add_subplot(2,2,1)
- 调节子图间距:
- subplots_adjust(left, bottom, right, top, wspace, hspace)
day32 Python与金融量化分析(二)的更多相关文章
- day31 堡垒机尾声 + Python与金融量化分析(一)
堡垒机尾声: 代码案例:https://github.com/liyongsan/git_class/tree/master/day31 课堂笔记:file send: 1.选择本地文件 2.远程路径 ...
- Python与金融量化分析----金融与量化投资
一:金融了解 金融:就是对现有资源进行重新的整合之后,进行价值和利润的等效流通. 金融工具: 股票 期货 黄金 外汇 基金 ............. 股票: 股票是股份公司发给出资人多的一种凭证,股 ...
- day33 Python与金融量化分析(三)
第三部分 实现简单的量化框架 框架内容: 开始时间.结束时间.现金.持仓数据 获取历史数据 交易函数 计算并绘制收益曲线 回测主体框架 计算各项指标 用户待写代码:初始化.每日处理函数 第四部分 在线 ...
- 金融量化分析-python量化分析系列之---使用python获取股票历史数据和实时分笔数据
财经数据接口包tushare的使用(一) Tushare是一款开源免费的金融数据接口包,可以用于获取股票的历史数据.年度季度报表数据.实时分笔数据.历史分笔数据,本文对tushare的用法,已经存在的 ...
- 金融量化分析【day110】:金融基础知识
一.股票 股票: 股票是股份公司发给出资人的一种凭证,股票的持有者就是股份公司的股东. 股票的面值与市值 面值表示票面金额 市值表示市场价值 上市/IPO: 企业通过证券交易所公开向社会增发股票以募集 ...
- 金融量化分析【day112】:初识量化交易
一.摘要 为什么需要量化交易? 量化交易是做什么? 量化交易的价值何在? 做量化交易需要什么? 聚宽是什么? 零基础如何快速入门量化交易? 自测与自学 二.量化交易比传统交易强多少? 它能让你的交易效 ...
- 金融量化分析【day111】:Matplotib-绘制K线图
一.绘制k线图 1.使用金融包出错解决 1.错误代码 ImportError: No module named finance 2.解决办法 https://github.com/matplotlib ...
- 金融量化分析【day112】:股票数据分析Tushare1
目录 1.使用tushare包获取某股票的历史行情数据 2.输出该股票所有收盘比开盘上涨3%以上的日期 3.输出该股票所有开盘比前日收盘跌幅超过2%的日期 4.假如我从2010年1月1日开始,每月第一 ...
- 金融量化分析【day112】:量化交易策略基本框架
摘要 策略编写的基本框架及其实现 回测的含义及其实现 初步学习解决代码错误 周期循环的开始时间 自测与自学 通过前文对量化交易有了一个基本认识之后,我们开始学习做量化交易.毕竟就像学游泳,有些东西讲是 ...
随机推荐
- android 带CheckBox对话框
package com.example.dialog4; import android.os.Bundle;import android.app.Activity;import android.app ...
- jQuery HTML操作学习笔记
学习资料 jQuery教程 获取 1.获取.设置元素的内容 1.1获取或设置目标元素的文本内容 语法 $(selector).text(); 获取元素文本内容 $(selector).text(con ...
- kubenetes 应用更新
一.Deployment类型: 1.更新: 1).命令方式更新镜像: kubectl set image deployment nginx-deployment nginx=nginx:1.9.1 k ...
- mycat 指定mycat节点
mycat 指定节点: /*!mycat:dataNode=order1*/select seq_nextval('APPOINTMENT_NO'); 指定节点创建存储过程或建表: /*!mycat: ...
- ruby中的可调用对象--方法
上一篇讲了ruby中的可调用对象proc和lambda,他们都是块转换成的对象.ruby中的可调用对象还有方法.通过使用method方法,并且以方法名作为参数(字符串或者符号),就可以得到一个方法对象 ...
- Hive环境安装
说明: (Hbase依赖于Hadoop,同时需要把元数据存放在mysql中),mysql自行安装 Hadoop2.0安装参考我的博客: https://www.cnblogs.com/654wangz ...
- Cloudera Manager安装之时间服务器和时间客户端(二)
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- STS,MyEclipse中Maven配置
本文以STS的环境做讲解,MyEclipse环境和STS差别不大,配置过程相似. STS是解压版的,启动后,可以看到已经有了Maven插件,, 但是,STS也同时给你了一个Maven,但是通常不建议使 ...
- ubuntu18.04安装ssh服务
1.安装openssh-server sudo apt-get install openssh-server 2.启动ssh服务 sudo service ssh start 3.检测是否启动了ssh ...
- OGNL与ValueStack(VS)-N语法top语法(转)
N语法[0]:<s:property value="[0]"/><br> N语法[1]:<s:property value="[1]&quo ...