ansible入门七(实战)
Ansible实战:部署分布式日志系统
本节内容:
- 背景
- 分布式日志系统架构图
- 创建和使用roles
- JDK 7 role
- JDK 8 role
- Zookeeper role
- Kafka role
- Elasticsearch role
- MySQL role
- Nginx role
- Redis role
- Hadoop role
- Spark role
一、背景
产品组在开发一个分布式日志系统,用的组件较多,单独手工部署一各个个软件比较繁琐,花的时间比较长,于是就想到了使用ansible playbook + roles进行部署,效率大大提高。
二、分布式日志系统架构图
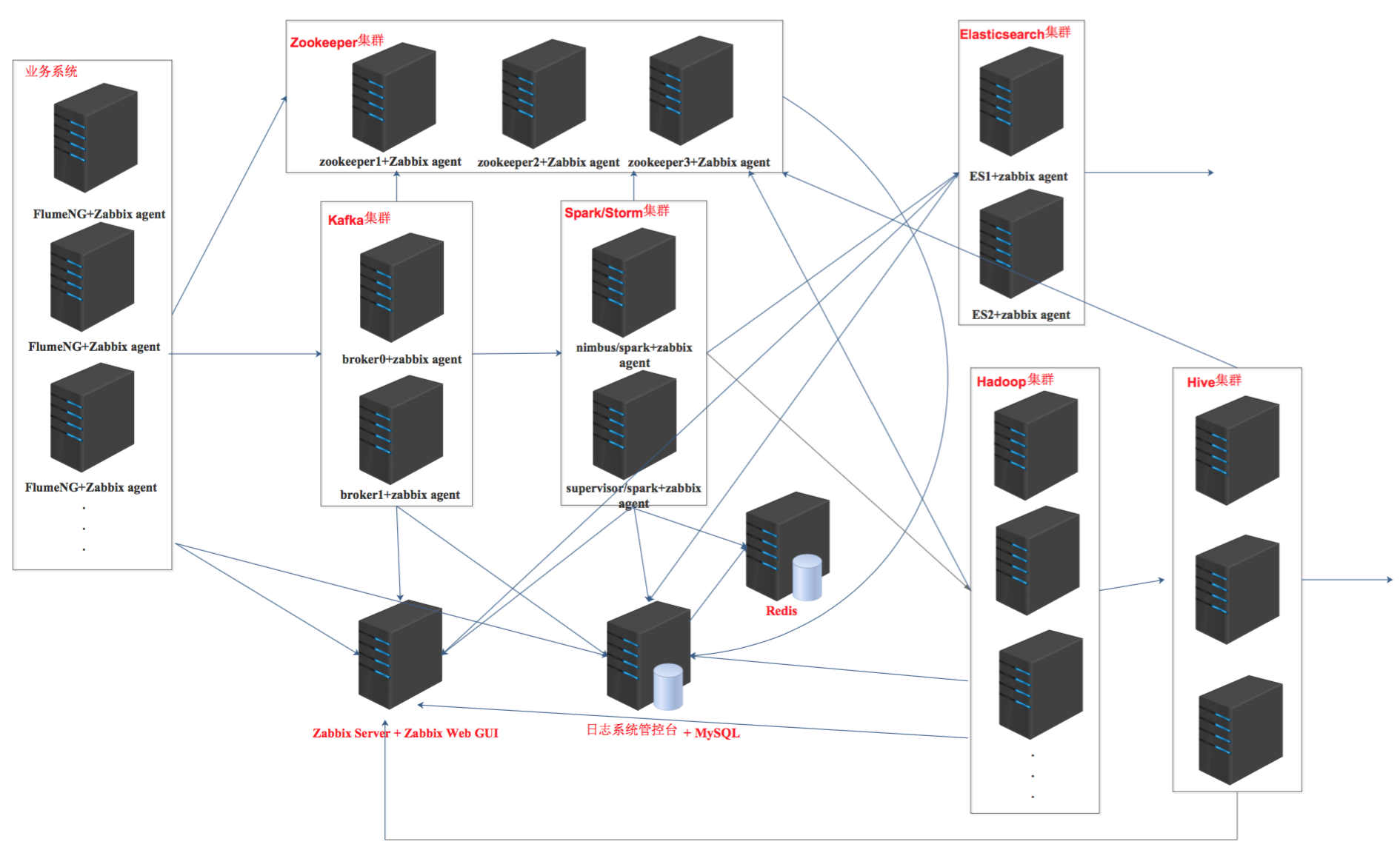
三、创建和使用roles
每一个软件或集群都创建一个单独的角色。
[root@node1 ~]# mkdir -pv ansible_playbooks/roles/{db_server,web_server,redis_server,zk_server,kafka_server,es_server,tomcat_server,flume_agent,hadoop,spark,hbase,hive,jdk7,jdk8}/{tasks,files,templates,meta,handlers,vars}

3.1. JDK7 role
[root@node1 jdk7]# pwd
/root/ansible_playbooks/roles/jdk7
[root@node1 jdk7]# ls
files handlers meta tasks templates vars
1. 上传软件包
将jdk-7u80-linux-x64.gz上传到files目录下。
2. 编写tasks
3. 编写vars
[root@node1 jdk7]# vim vars/main.yml
jdk_package_name: jdk-7u80-linux-x64.gz
env_file: /etc/profile
jdk_version: jdk1.7.0_80
4. 使用角色
在roles同级目录,创建一个jdk.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim jdk.yml
- hosts: jdk
remote_user: root
roles:
- jdk7
运行playbook安装JDK7:
[root@node1 ansible_playbooks]# ansible-playbook jdk.yml
使用jdk7 role可以需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
3.2 JDK8 role
[root@node1 jdk8]# pwd
/root/ansible_playbooks/roles/jdk8
[root@node1 jdk8]# ls
files handlers meta tasks templates vars
1. 上传安装包
将jdk-8u73-linux-x64.gz上传到files目录下。
2. 编写tasks
3. 编写vars
[root@node1 jdk8]# vim vars/main.yml
jdk_package_name: jdk-8u73-linux-x64.gz
env_file: /etc/profile
jdk_version: jdk1.8.0_73
4. 使用角色
在roles同级目录,创建一个jdk.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim jdk.yml
- hosts: jdk
remote_user: root
roles:
- jdk8
运行playbook安装JDK8:
[root@node1 ansible_playbooks]# ansible-playbook jdk.yml
使用jdk8 role可以需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
3.3 Zookeeper role
Zookeeper集群节点配置好/etc/hosts文件,配置集群各节点主机名和ip地址的对应关系。
[root@node1 zk_server]# pwd
/root/ansible_playbooks/roles/zk_server
[root@node1 zk_server]# ls
files handlers meta tasks templates vars
1. 上传安装包
将zookeeper-3.4.6.tar.gz和clean_zklog.sh上传到files目录。clean_zklog.sh是清理Zookeeper日志的脚本。
2. 编写tasks
3. 编写templates
将zookeeper-3.4.6.tar.gz包中的默认配置文件上传到../roles/zk_server/templates/目录下,重命名为zoo.cfg.j2,并修改其中的内容。
[root@node1 ansible_playbooks]# vim roles/zk_server/templates/zoo.cfg.j2
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不在解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 zk_server]# vim vars/main.yml
server1_hostname: hadoop27
server2_hostname: hadoop28
server3_hostname: hadoop29
另外在tasks中还使用了个变量{{myid}},该变量每台主机的值是不一样的,所以定义在了/etc/ansible/hosts文件中:
[zk_servers]
172.16.206.27 myid=1
172.16.206.28 myid=2
172.16.206.29 myid=3
5. 设置主机组
/etc/ansible/hosts文件:
[zk_servers]
172.16.206.27 myid=1
172.16.206.28 myid=2
172.16.206.29 myid=3
6. 使用角色
在roles同级目录,创建一个zk.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim zk.yml
- hosts: zk_servers
remote_user: root
roles:
- zk_server
运行playbook安装Zookeeper集群:
[root@node1 ansible_playbooks]# ansible-playbook zk.yml
使用zk_server role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
3.4 Kafka role
[root@node1 kafka_server]# pwd
/root/ansible_playbooks/roles/kafka_server
[root@node1 kafka_server]# ls
files handlers meta tasks templates vars
1. 上传安装包
将kafka_2.11-0.9.0.1.tar.gz、kafka-manager-1.3.0.6.zip和clean_kafkalog.sh上传到files目录。clean_kafkalog.sh是清理kafka日志的脚本。
2. 编写tasks
3. 编写templates
[root@node1 kafka_server]# vim templates/server.properties.j2
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不再解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 kafka_server]# vim vars/main.yml
zk_cluster: 172.16.7.151:2181,172.16.7.152:2181,172.16.7.153:2181
kafka_manager_ip: 172.16.7.151
另外在template的文件中还使用了个变量{{broker_id}},该变量每台主机的值是不一样的,所以定义在了/etc/ansible/hosts文件中:
[kafka_servers]
172.16.206.17 broker_id=0
172.16.206.31 broker_id=1
172.16.206.32 broker_id=2
5. 设置主机组
/etc/ansible/hosts文件:
[kafka_servers]
172.16.206.17 broker_id=0
172.16.206.31 broker_id=1
172.16.206.32 broker_id=2
6. 使用角色
在roles同级目录,创建一个kafka.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim kafka.yml
- hosts: kafka_servers
remote_user: root
roles:
- kafka_server
运行playbook安装kafka集群:
[root@node1 ansible_playbooks]# ansible-playbook kafka.yml
使用kafka_server role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
3.5 Elasticsearch role
[root@node1 es_server]# pwd
/root/ansible_playbooks/roles/es_server
[root@node1 es_server]# ls
files handlers meta tasks templates vars
1. 上传安装包
将elasticsearch-2.3.3.tar.gz elasticsearch-analysis-ik-1.9.3.zip上传到files目录。
2. 编写tasks
3. 编写templates
将模板elasticsearch.in.sh.j2和elasticsearch.yml.j2放入templates目录下
注意模板里的变量名中间不能用.。比如:{{node.name}}这样的变量名是不合法的。
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不再解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 es_server]# vim vars/main.yml
ES_MEM: 2g
cluster_name: wisedu
master_ip: 172.16.7.151
另外在template的文件中还使用了个变量{{node_master}},该变量每台主机的值是不一样的,所以定义在了/etc/ansible/hosts文件中:
[es_servers]
172.16.7.151 node_master=true
172.16.7.152 node_master=false
172.16.7.153 node_master=false
5. 设置主机组
/etc/ansible/hosts文件:
[es_servers]
172.16.7.151 node_master=true
172.16.7.152 node_master=false
172.16.7.153 node_master=false
6. 使用角色
在roles同级目录,创建一个es.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim es.yml
- hosts: es_servers
remote_user: root
roles:
- es_server
运行playbook安装Elasticsearch集群:
[root@node1 ansible_playbooks]# ansible-playbook es.yml
使用es_server role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
3.6 MySQL role
[root@node1 db_server]# pwd
/root/ansible_playbooks/roles/db_server
[root@node1 db_server]# ls
files handlers meta tasks templates vars
1. 上传安装包
将制作好的rpm包mysql-5.6.27-1.x86_64.rpm放到/root/ansible_playbooks/roles/db_server/files/目录下。
【注意】:这个rpm包是自己打包制作的,打包成rpm会使得部署的效率提高。关于如何打包成rpm见之前的博客《速成RPM包制作》。
2. 编写tasks
mysql tasks
3. 设置主机组
# vim /etc/ansible/hosts
[db_servers]
172.16.7.152
4. 使用角色
在roles同级目录,创建一个db.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim db.yml
- hosts: mysql_server
remote_user: root
roles:
- db_server
运行playbook安装MySQL:
[root@node1 ansible_playbooks]# ansible-playbook db.yml
使用db_server role需要根据实际环境修改/etc/ansible/hosts文件里定义的主机。
3.7 Nginx role
[root@node1 web_server]# pwd
/root/ansible_playbooks/roles/web_server
[root@node1 web_server]# ls
files handlers meta tasks templates vars
1. 上传安装包
将制作好的rpm包openresty-for-godseye-1.9.7.3-1.x86_64.rpm放到/root/ansible_playbooks/roles/web_server/files/目录下。
【注意】:做成rpm包,在安装时省去了编译nginx的过程,提升了部署效率。这个包里面打包了很多与我们系统相关的文件。
2. 编写tasks
Nginx tasks
3. 编写templates
将模板nginx.conf.j2放入templates目录下.
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不再解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 web_server]# vim vars/main.yml
elasticsearch_cluster: server 172.16.7.151:9200;server 172.16.7.152:9200;server 172.16.7.153:9200;
kafka_server1: 172.16.7.151
kafka_server2: 172.16.7.152
kafka_server3: 172.16.7.153
经过测试,变量里面不能有逗号。
5. 设置主机组
/etc/ansible/hosts文件:
# vim /etc/ansible/hosts
[nginx_servers]
172.16.7.153
6. 使用角色
在roles同级目录,创建一个nginx.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim nginx.yml
- hosts: nginx_servers
remote_user: root
roles:
- web_server
运行playbook安装Nginx:
[root@node1 ansible_playbooks]# ansible-playbook nginx.yml
使用web_server role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
3.8 Redis role
[root@node1 redis_server]# pwd
/root/ansible_playbooks/roles/redis_server
[root@node1 redis_server]# ls
files handlers meta tasks templates vars
1. 上传安装包
将制作好的rpm包redis-3.2.2-1.x86_64.rpm放到/root/ansible_playbooks/roles/redis_server/files/目录下。
2. 编写tasks
3. 设置主机组
/etc/ansible/hosts文件:
# vim /etc/ansible/hosts
[redis_servers]
172.16.7.152
4. 使用角色
在roles同级目录,创建一个redis.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim redis.yml
- hosts: redis_servers
remote_user: root
roles:
- redis_server
运行playbook安装redis:
[root@node1 ansible_playbooks]# ansible-playbook redis.yml
使用redis_server role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
3.9 Hadoop role
完全分布式集群部署,NameNode和ResourceManager高可用。
提前配置集群节点的/etc/hosts文件、节点时间同步、某些集群主节点登录其他节点不需要输入密码。
[root@node1 hadoop]# pwd
/root/ansible_playbooks/roles/hadoop
[root@node1 hadoop]# ls
files handlers meta tasks templates vars
1. 上传安装包
将hadoop-2.7.2.tar.gz放到/root/ansible_playbooks/roles/hadoop/files/目录下。
2. 编写tasks
3. 编写templates
将模板core-site.xml.j2、hadoop-daemon.sh.j2、hadoop-env.sh.j2、hdfs-site.xml.j2、mapred-site.xml.j2、slaves.j2、yarn-daemon.sh.j2、yarn-site.xml.j2放入templates目录下。
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不再解释,在前面博客中的文章中都已写明。
4. 编写vars

[root@node1 hadoop]# vim vars/main.yml
env_file: /etc/profile
# hadoop-env.sh.j2 file variables.
JAVA_HOME: /usr/java/jdk1.8.0_73
# core-site.xml.j2 file variables.
ZK_NODE1: node1:2181
ZK_NODE2: node2:2181
ZK_NODE3: node3:2181
# hdfs-site.xml.j2 file variables.
NAMENODE1_HOSTNAME: node1
NAMENODE2_HOSTNAME: node2
DATANODE1_HOSTNAME: node3
DATANODE2_HOSTNAME: node4
DATANODE3_HOSTNAME: node5
# mapred-site.xml.j2 file variables.
MR_MODE: yarn
# yarn-site.xml.j2 file variables.
RM1_HOSTNAME: node1
RM2_HOSTNAME: node2
5. 设置主机组
/etc/ansible/hosts文件:
# vim /etc/ansible/hosts
[hadoop]
172.16.7.151 namenode_active=true namenode_standby=false datanode=false
172.16.7.152 namenode_active=false namenode_standby=true datanode=false
172.16.7.153 namenode_active=false namenode_standby=false datanode=true
172.16.7.154 namenode_active=false namenode_standby=false datanode=true
172.16.7.155 namenode_active=false namenode_standby=false datanode=true
6. 使用角色
在roles同级目录,创建一个hadoop.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim hadoop.yml
- hosts: hadoop
remote_user: root
roles:
- jdk8
- hadoop
运行playbook安装hadoop集群:
[root@node1 ansible_playbooks]# ansible-playbook hadoop.yml
使用hadoop role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
3.10 Spark role
Standalone模式部署spark (无HA)
[root@node1 spark]# pwd
/root/ansible_playbooks/roles/spark
[root@node1 spark]# ls
files handlers meta tasks templates vars
1. 上传安装包
将scala-2.10.6.tgz和spark-1.6.1-bin-hadoop2.6.tgz放到/root/ansible_playbooks/roles/hadoop/files/目录下。
2. 编写tasks
3. 编写templates
将模板slaves.j2和spark-env.sh.j2放到/root/ansible_playbooks/roles/spark/templates/目录下。
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不再解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 spark]# vim vars/main.yml
env_file: /etc/profile
# spark-env.sh.j2 file variables
JAVA_HOME: /usr/java/jdk1.8.0_73
SCALA_HOME: /usr/local/scala-2.10.6
SPARK_MASTER_HOSTNAME: node1
SPARK_HOME: /usr/local/spark-1.6.1
SPARK_WORKER_MEMORY: 256M
HIVE_HOME: /usr/local/apache-hive-2.1.0-bin
HADOOP_CONF_DIR: /usr/local/hadoop/etc/hadoop/
# slave.j2 file variables
SLAVE1_HOSTNAME: node2
SLAVE2_HOSTNAME: node3
5. 设置主机组
/etc/ansible/hosts文件:
# vim /etc/ansible/hosts
[spark]
172.16.7.151
172.16.7.152
172.16.7.153
6. 使用角色
在roles同级目录,创建一个spark.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim spark.yml
- hosts: spark
remote_user: root
roles:
- spark
运行playbook安装spark集群:
[root@node1 ansible_playbooks]# ansible-playbook spark.yml
使用spark role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
【注】:所有的文件都在github上,https://github.com/jkzhao/ansible-godseye。
ansible入门七(实战)的更多相关文章
- .NET分布式缓存Redis从入门到实战
一.课程介绍 今天阿笨给大家带来一堂NOSQL的课程,本期的主角是Redis.希望大家学完本次分享课程后对redis有一个基本的了解和认识,并且熟悉和掌握 Redis在.NET中的使用. 本次分享课程 ...
- 《Angular4从入门到实战》学习笔记
<Angular4从入门到实战>学习笔记 腾讯课堂:米斯特吴 视频讲座 二〇一九年二月十三日星期三14时14分 What Is Angular?(简介) 前端最流行的主流JavaScrip ...
- Python爬虫入门七之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- Nginx入门到实战
location 语法 location 有”定位”的意思, 根据Uri来进行不同的定位. 在虚拟主机的配置中,是必不可少的,location可以把网站的不同部分,定位到不同的处理方式上. 比如, 碰 ...
- 赞一个 kindle电子书有最新的计算机图书可买了【Docker技术入门与实战】
最近对docker这个比较感兴趣,找一个比较完整的书籍看看,在z.cn上找到了电子书,jd dangdang看来要加油啊 Docker技术入门与实战 [Kindle电子书] ~ 杨保华 戴王剑 曹亚仑 ...
- docker-9 supervisord 参考docker从入门到实战
参考docker从入门到实战 使用 Supervisor 来管理进程 Docker 容器在启动的时候开启单个进程,比如,一个 ssh 或者 apache 的 daemon 服务.但我们经常需要在一个机 ...
- webpack入门和实战(一):webpack配置及技巧
一.全面理解webpack 1.什么是 webpack? webpack是近期最火的一款模块加载器兼打包工具,它能把各种资源,例如JS(含JSX).coffee.样式(含less/sass).图片等都 ...
- CMake快速入门教程-实战
http://www.ibm.com/developerworks/cn/linux/l-cn-cmake/ http://blog.csdn.net/dbzhang800/article/detai ...
- Sping Boot入门到实战之入门篇(三):Spring Boot属性配置
该篇为Sping Boot入门到实战系列入门篇的第三篇.介绍Spring Boot的属性配置. 传统的Spring Web应用自定义属性一般是通过添加一个demo.properties配置文件(文 ...
随机推荐
- 06 swap命令,进程管理,rmp命令与yum命令,源码安装python
作业一: 1)开启Linux系统前添加一块大小为15G的SCSI硬盘 2)开启系统,右击桌面,打开终端 3)为新加的硬盘分区,一个主分区大小为5G,剩余空间给扩展分区,在扩展分区上划分1个逻辑分区,大 ...
- mysql时间戳转换成可读时间格式
代码: SELECT FROM_UNIXTIME(1234567890, '%Y-%m-%d %H:%i:%S') 附:在mysql中,一个时间字段的存储类型是int(11),怎么转化成字符类型,比方 ...
- android studio 模拟器中文乱码
这是因为编码格式不统一导致的,在android studio的build.gradle加入默认编码声明就可以了 compileOptions.encoding = "GBK" 参考
- netty10---分包粘包
客户端:根据 长度+数据 方式发送 package com.server; import java.net.Socket; import java.nio.ByteBuffer; public cla ...
- java之继承中的构造方法
继承中的构造方法 1.子类的构造过程中必须调用其基类的构造方法. 2.子类可以在自己的构造方法中使用super(argument_list)调用基类的构造方法. 2.1.使用this(argumen ...
- MVC分层处理
MVC和三层其实是八竿子打不着的,MVC是一种全新的开发方式,传统的三层,其实是模块划分,为了结构清晰.而MVC就是MVC,是通过URL路由到控制器,然后到模型,处理完数据然后将结果返回给视图.是与三 ...
- 手写一款符合Promise/A+规范的Promise
手写一款符合Promise/A+规范的Promise 长篇预警!有点长,可以选择性观看.如果对Promise源码不是很清楚,还是推荐从头看,相信你认真从头看到尾,并且去实际操作了,肯定会有收获的.主要 ...
- MyBatis如何返回自增的ID
<insert id="insertTable" parameterType="com.infohold.city.map.model.CheckTemplateM ...
- Maven取消编译自动测试
Maven取消编译自动测试 <build> <plugins> <plugin> <groupId>org.apache.maven.plugins&l ...
- Linux crontab命令 定时任务 用法详解以及no crontab for root解决办法
最近系统服务器进行搬迁,又恰好需要使用定时任务运行程序,而我的程序主要使用PHP写的,然后总结了下定时任务的用法,但是在这里主要写的是关于crontab命令的用法,使用过程中遇到不少问题,例如no c ...