Nginx 原理篇
前言
在学习 Nginx 之前,我们首先有必要搞清楚下面几个问题:
1. Web服务器是怎么工作的?
2. Apache 与 Nginx 有何异同?
3. Nginx 工作模式是怎样的?
下面就围绕这几个问题,进行解释(内容来自网络及个人理解)
常见 Web 服务器服务方式
三种工作模式比较:
Web 服务器主要为用户提供服务,必须以某种方式,工作在某个套接字上,一般Web服务器在处理用户请求时,一般有如下三种方式:
(1)多进程
(2)多线程
(3)异步
1. 多进程
为每个请求分配一个进程来处理。由于操作系统中,生成进程、销毁进程、进程间切换都很消耗CPU和内存,当负载高时,性能会明显下降。
优点:采用独立进程处理进程的方式,进程之间是独立的,单个进程的异常不会影响到其他进程的工作,因此稳定性最好
缺点:在高负载的时候,操作系统不可能无限制的为用户请求创建进程,CPU在众多进程之间切换的开销也会增加,而且进程之间的独立性,资源无法共享,造成内存的重复利用
2. 多线程
一个进程中生成多个线程来响应用户请求。由于线程开销相对进程来说小的多,而且线程共享进程的部分资源,因此线程比进程更轻量级,更高效。
优点:线程比较进程来说,更轻量级,使用一个进程多个线程的方式,而且多个线程可以共享进程的资源,可以支持更多的请求。
缺点:高负载时,多线程之间频繁的切换会造成线程的抖动,如果某个进程中的某个线程异常,则会造成整个进程内的线程都无法正常工作,因此稳定性较差。
3. 异步
异步是开发中采用的一种编程方式(比如 Python 中的 协程)是三种方式中开销最小的,但是这种方式对编程要求较高,因此多任务之间的调度如果出现问题,一般都是整体故障。
优点:性能最好。一个进程或线程响应用户请求,不需要额外的开销,资源占用较低
缺点:某个进程或线程出错,会造成整个程序异常,甚至服务宕机,稳定性在三者中最差
一个 Web 请求的处理过程

(1)客户发起请求到服务器网卡
(2)服务器网卡接受到请求后交给内核处理
(3)内核根据请求对应的套接字,将请求交给工作在用户空间中web服务器进程
(4)web服务器进程根据用户请求,向内核进程系统调用,申请获取响应资源,如用户访问 index.html
(5)内核发现web服务器进程请求的是一个存放在硬盘上的资源,因此通过驱动程序连接磁盘
(6)内核调度磁盘,获取需要的资源
(7)内核将资源存放在自己的缓冲区中,并通知web服务器进程
(8)web服务器进程通过系统调用获取资源,并将其复制到进程自己的缓冲区中
(9)web服务器进程形成响应,通过系统调用再次发给内核以响应用户请求
(10)内核将响应发送至网卡
(11)网卡发送响应给用户
通过这样的一个复杂过程,一次请求就完成了。
简单来讲:用户请求 -> 送达至用户空间 -> 系统调用 -> 内核空间 -> 内核到磁盘上读取网页资源 -> 返回用户空间 -> 响应给用户
在这个过程中,有两次 I/O调用:
(1)客户端请求的网络I/O
(2)web服务器请求页面的磁盘I/O
各种I/O模型详解
通过上面对连接的处理分析,我们知道工作在用户空间的web服务器进程是无法直接操作IO的,需要通过系统调用进行,其关系如下:

用户空间中的web服务器进程向内核进行系统调用申请IO,内核将资源从IO调度到内核的buffer中(wait阶段),内核还需将数据从内核buffer中复制(copy阶段)到web服务器进程所在的用户空间,才算完成一次IO调度。这几个阶段都是需要时间的。根据wait和copy阶段处理等待的机制不同,可将I/O动作分为如下五种模式:
(1)阻塞
(2)非阻塞
(3)IO复用(select、poll)
(4)事件驱动的 IO
(5)异步 IO
I/O模式简介
首先,需要解释下:同步和异步、阻塞和非阻塞的概念。
同步:
发出一个功能调用时,在没有得到结果之前,该调用就不返回。也就是必须一件一件事做,等前一件做完了才能做下一件事。
异步:
异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立即得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者
阻塞:
阻塞调用是指调用结果返回之前,当前线程会被挂起(线程进入非可执行状态,在这个状态下,cpu不会给线程分配时间片,即线程暂停运行),函数只有得到结果之后才会返回。
阻塞调用和同步调用是不同的,对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回,它还会抢占cpu去执行其他逻辑,也会主动监测IO是否准备好
非阻塞:
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立即返回。
再简单点理解就是:
1. 同步,就是调用一个功能,功能没有结束前,死等结果;
2. 异步,我调用一个功能,不需要知道该功能结果,该功能有结果后通知我;
3. 阻塞,就是调用函数,函数没有接收完数据或没有得到结果之前,函数不会返回;
4. 非阻塞,就是调用函数,函数立即返回,等到处理结果后通过select通知调用者
网络上有一个很好例子:
老张爱喝茶,废话不说,煮开水。
出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
1 老张把水壶放到火上,立等水开。(同步阻塞)
老张觉得自己有点傻
2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)
老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀~~~~的噪音。
3 老张把响水壶放到火上,立等水开。(异步阻塞)
老张觉得这样傻等意义不大
4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
老张觉得自己聪明了。 所谓同步异步,只是对于水壶而言。
普通水壶,同步;响水壶,异步。
虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。这是普通水壶所不能及的。
同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。 所谓阻塞非阻塞,仅仅对于老张而言。
立等的老张,阻塞;看电视的老张,非阻塞。
情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
同步IO 和 异步IO 的区别在于:数据拷贝的时候进程是否阻塞;
阻塞IO 和 非阻塞IO 的区别在于:应用程序的调用是否立即返回。
五种 I/O 模型
(1)阻塞IO
(2)非阻塞IO
(3)IO复用
(4)事件驱动IO
(5)异步IO
其中前 4 种都是同步,最后一种异步。
(1)阻塞IO
应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。如果数据没有准备好,一直等待数据准备好了,从内核拷贝到用户空间,IO函数返回成功指示。
阻塞IO模型图:在调用recv()/recvfrom()函数时,发生在内核中等待数据和复制数据的过程。

当调用 recvfrom 函数时,系统首先检查是否有准备好的数据。如果数据没有准备好,那么系统就处于等待状态。当数据准备好后,将数据冲系统缓冲区复制到用户空间,然后该函数返回。在应用程序中,调用 recvfrom 函数时,未必用户空间就已经存在数据,那么此时 recvfrom 函数就会处于等待状态。
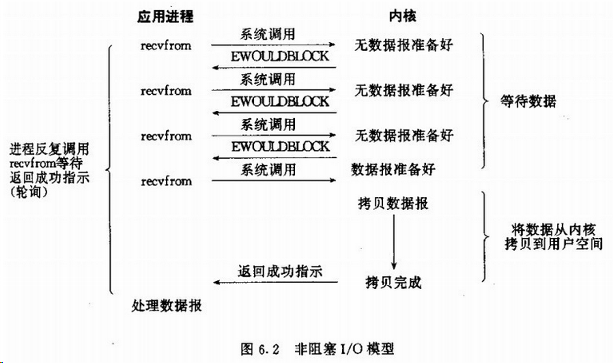
(2)非阻塞IO
非阻塞IO通过进程反复调用IO(多次系统调用,并马上返回);在数据拷贝的过程中,进程是阻塞的。
我们把一个socket接口设置为非阻塞就是告诉内核,当所请求的I/O操作无法完成时,不要将进程睡眠,而是返回一个错误。这样我们的I/O操作函数将不断的检测数据是否准备好,如果没有准备好,继续检查,直到数据准备好为止。在这个不断检查的过程中,会大量的占用 CPU 的时间。因此一般的 WEB 服务器不会再用这种I/O 模式。
(3)I/O复用
主要模式是 select 和 epoll ; 对一个IO端口,两次调用,两次返回,比阻塞io并没有什么优越性;关键是能实现同时对多个IO端口进行监听;IO复用模型会用到 select、poll、epoll 函数,这几个函数也会使进程阻塞,但是和阻塞IO所不同的是,这三个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的IO函数进行检测,直到有数据可读或可写,才真正调用I/O操作函数。

(4)信号驱动I/O
首先我们运行套接字进行信号驱动IO,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。
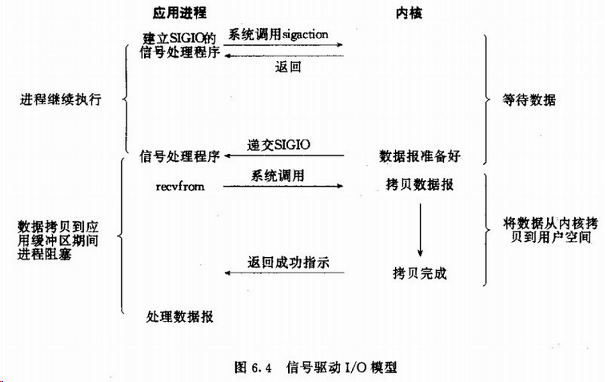
在 wait 阶段不阻塞,在 copy 阶段阻塞。
(5)异步I/O
当一个异步过程调用发出后,调用者不能立即得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者的输入输出操作。
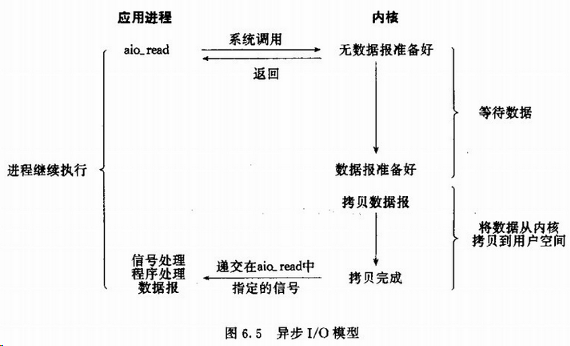
在 wait 和 copy 阶段都不会阻塞。
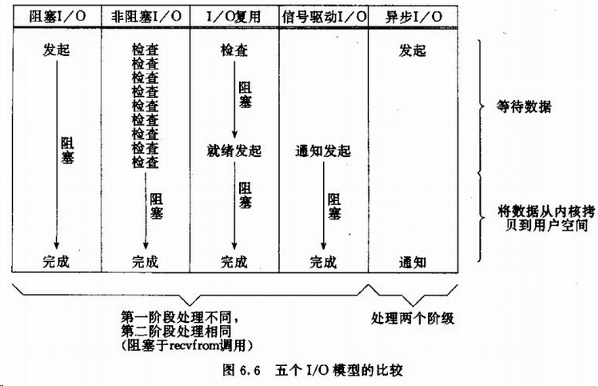
最后,总结比较五种IO模型:
Linux I/O模型的具体实现
主要实现方式有以下几种:
- select
- poll
- epoll
- kqueue
- /dev/poll
- iocp
select、poll、epoll 是 Linux 实现的,kqueue是FreeBSD实现的,/dev/poll 是SUN是Solaris实现的,iocp是windows 实现的。
select、poll 对应第三种(IO复用)模型
iocp对应第五种(异步IO)模型
epoll、kqueue、/dev/poll 其实也同select属于同一种模型,只是更高级些,可以看做有了第4种(信号驱动IO)模型的某些特性,如callback机制
select、poll、epoll 简介
epoll 和 select
都是能提供IO多路复用的解决方案。在现在的Linux内核里都能够支持,其中 epoll 是 Linux 所特有的,而 select 则应该是 POSIX 所规定,一般操作系统均有实现。
select:
select 本质上是通过设置或者检查存放fd(文件描述符)标志位的数据结构来进行下一步处理。这样所带来的缺点是:
1. 单个进程可监视的fd数量被限制,即能监听端口的大小有限
一般来说这个数目和系统内存大小有关系,具体数目可以 cat /proc/sys/fs/file-max 查看。
2. 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低
当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这 正是epoll与kqueue做的。
3. 需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大
poll:
poll 本质上和 select 没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次重复的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:
1. 大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义
2. poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
epoll:
epoll 是 nginx 采用的默认模式
epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。LT模式下,只要这个fd还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作,而在ET(边缘触发)模式中,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无论fd中是否还有数据可读。所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者 遇到EAGAIN错误。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
上面所说的 LT模式 和 ET 模式,就是 水平触发 和 边缘触发
水平触发(LT模式):只要fd可读,每次select 轮询的时候,都会读取。第一次轮询没有读取完成,第二次轮询还会提示
边缘触发(ET模式):只提示1次,不管有没有读完数据。从性能上来说,边缘触发的性能要好于水平触发
epoll为什么要有EPOLLET触发模式?
如果采用EPOLLLT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率。而采用EPOLLET这种边沿触发模式的话,当被监控的文件描述符 上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知 你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。
epoll 的优点:
1. 没有最大并发连接的限制,能打开FD的上限大于1024(1G的内存上能监听约10万个端口);
2. 效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,epoll的效率就会远远高于select和poll
3. 内存拷贝,利用mmap() 文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
select、poll、epoll 区别总结:
1. 支持一个进程所能打开的最大连接数
select
单个进程所能打开的最大连接数有 FD_SETSIZE 宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一 步的测试。
poll
poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的。
epoll
虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接
2. FD剧增后带来的IO效率问题
select
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。
poll
poll 同 select 是一致的。
epoll
因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
3. 消息传递方式
select
内核需要将消息传递到用户空间,都需要内核拷贝动作
poll
poll 同 select 是一致的。
epoll
epoll通过内核和用户空间共享一块内存来实现的。
总结:
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1. 表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调
2. select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
Apache Httpd的工作模式
apache三种工作模式
我们都知道Apache有三种工作模块,分别为prefork、worker、event。
- prefork:多进程,每个请求用一个进程响应,这个过程会用到select机制来通知。
- worker:多线程,一个进程可以生成多个线程,每个线程响应一个请求,但通知机制还是select不过可以接受更多的请求。
- event:基于异步I/O模型,一个进程或线程,每个进程或线程响应多个用户请求,它是基于事件驱动(也就是epoll机制)实现的。
prefork的工作原理
如果不用“--with-mpm”显式指定某种MPM,prefork就是Unix平台上缺省的MPM.它所采用的预派生子进程方式也是Apache1.3中采用的模式。prefork本身并没有使用到线程,2.0版使用它是为了与1.3版保持兼容性;另一方面,prefork用单独的子进程来 处理不同的请求,进程之间是彼此独立的,这也使其成为最稳定的MPM之一。
worker的工作原理
相对于prefork,worker是2.0版中全新的支持多线程和多进程混合模型的MPM。由于使用线程来处理,所以可以处理相对海量的请求,而系统资源的开销要小于基于进程的服务器。但是,worker也使用了多进程,每个进程又生成多个线程,以获得基于 进程服务器的稳定性,这种MPM的工作方式将是Apache2.0的发展趋势。
event 基于事件机制的特性
一个进程响应多个用户请求,利用callback机制,让套接字复用,请求过来后进程并不处理请求,而是直接交由其他机制来处理,通过epoll机制来通知请求是否完成;在这个过程中,进程本身一直处于空闲状态,可以一直接收用户请求。可以实现一个 进程程响应多个用户请求。支持持海量并发连接数,消耗更少的资源。
如何提高Web服务器的并发连接处理能力?
有几个基本条件:
- 基于线程,即一个进程生成多个线程,每个线程响应用户的每个请求。
- 基于事件的模型,一个进程处理多个请求,并且通过epoll机制来通知用户请求完成。
- 基于磁盘的AIO(异步I/O)
- 支持mmap内存映射,mmap传统的web服务器,进行页面输入时,都是将磁盘的页面先输入到内核缓存中,再由内核缓存中复制一份到web服务器上,mmap机制就是让内核缓存与磁盘进行映射,web服务器,直接复制页面内容即可。不需要先把磁盘的上的页面先输入到内核缓存去。
刚好,Nginx 支持以上所有特性。所以Nginx官网上说,Nginx支持50000并发,是有依据的。
Nginx优异之处
简介
nginx的主要着眼点就是其高性能以及对物理计算资源的高密度利用,因此其采用了不同的架构模型。受启发于多种操作系统设计中基于“事件”的高级处理机制,nginx采用了模块化、事件驱动、文件异步、单线程及非阻塞的架构,并大量采用了多路复用及事件通知机制。在nginx中,连接请求由为数不多的几个仅包含一个线程的进程worker以高效的回环(run-loop)机制进行处理,而每个worker可以并行处理数千个的并发连接及请求。
Nginx 工作原理
Nginx会按需同时运行多个进程:一个主进程(master)和几个工作进程(worker),配置了缓存时还会有缓存加载器进程(cache loader)和缓存管理器进程(cache manager)等。所有进程均是仅含有一个线程,并主要通过“共享内存”的机制实现进程间通信。主进程以root用户身份运行,而worker、 cache loader和cache manager均应以非特权用户身份运行。
Nginx 架构
Nginx 的整体架构图:
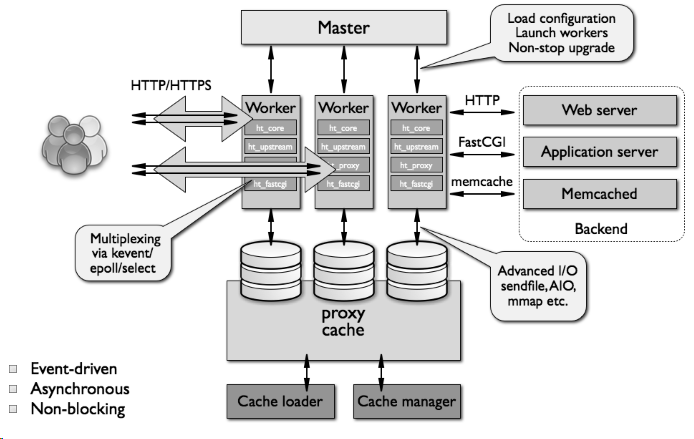
主进程(Master)主要完成如下工作:
- 读取并验正配置信息
- 创建、绑定及关闭套接字
- 启动、终止及维护worker进程的个数
- 无须中止服务而重新配置工作特性
- 控制非中断式程序升级,启用新的二进制程序并在需要时回滚至老版本
- 重新打开日志文件
- 编译嵌入式perl脚本
worker进程主要完成的任务包括:
- 接收、传入并处理来自客户端的连接;
- 提供反向代理及过滤功能;
- nginx任何能完成的其它任务;
注:如果负载以CPU密集型应用为主,如SSL或压缩应用,则worker数应与CPU数相同;如果负载以IO密集型为主,如响应大量内容给客户端,则worker数应该为CPU个数的1.5或2倍。
为了更好地理解设计,你需要了解NGINX是如何工作的。NGINX之所以能在性能上如此优越,是由于其背后的设计。许多web服务器和应用服务器使用简单的线程的(threaded)、或基于流程的(process-based)架构, NGINX则以一种复杂的事件驱动(event-driven)的架构脱颖而出,这种架构能支持现代硬件上成千上万的并发连接。
设置场景——NGINX进程模型
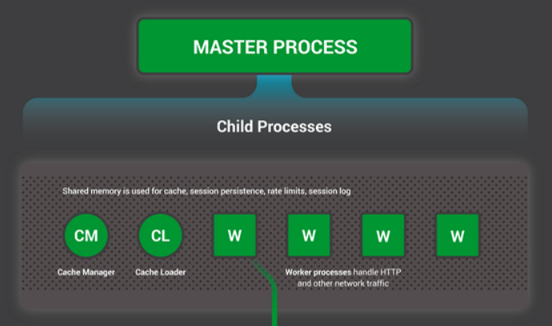
为了更好的理解设计,你需要了解Nginx是如何工作的。NGINX有一个主线程(master process)(执行特权操作,如读取配置、绑定端口)和一系列工作进程(worker process)和辅助进程(helper process)。
任何Unix应用程序的根本基础都是线程或进程(从Linux操作系统的角度看,线程和进程基本上是相同的,主要区别是他们共享内存的程度)。进程或线程,是一组操作系统可调度的、运行在CPU内核上的独立指令集。大多数复杂的应用程序都并行运行多个线程或进程,原因有两个:
- 可以同时使用更多的计算机内核
- 线程和进程使并行操作很容易实现(例如,同时处理多个连接)。
进程和线程都消耗资源。它们都使用内存和其他OS资源,导致内核频繁切换(被称作上下文切换(context switch)的操作)。大多数现代服务器可以同时处理数百个小的、活跃的(active)线程或进程,但一旦内存耗尽,或高I/O负载导致大量的上下文切换时,服务器的性能就会严重下降。
对于网络应用,通常会为每个连接(connection)分配一个线程或进程。这种架构易于实现,但是当应用程序需要处理成千上万的并发连接时,这种架构的扩展性就会出现问题。
NGINX是如何工作的?
NGINX使用一个了可预见式的(predictable)进程模型,调度可用的硬件资源:
主进程执行特权操作,如读取配置和绑定端口,还负责创建子进程(下面的三种类型)。
- 缓存加载进程(cache loader process)在启动时运行,把基于磁盘的缓存(disk-based cache)加载到内存中,然后退出。对它的调度很谨慎,所以其资源需求很低。
- 缓存管理进程(cache manager process)周期性运行,并削减磁盘缓存(prunes entries from the disk caches),以使其保持在配置范围内。
- 工作进程(worker processes)才是执行所有实际任务的进程:处理网络连接、读取和写入内容到磁盘,与上游服务器通信等。
多数情况下,NGINX建议每1个CPU核心都运行1个工作进程,使硬件资源得到最有效的利用。你可以在配置中设置如下指令: worker_processes auto,当NGINX服务器在运行时,只有工作进程在忙碌。每个工作进程都以非阻塞的方式处理多个连接,以削减上下文切换的开销。每个工作进程都是单线程且独立运行的,抓取并处理新的连接。进程间通过共享内存的方式,来共享缓存数据、会话持久性数据(session persistence data)和其他共享资源。
NGINX内部的工作进程
每一个NGINX的工作进程都是NGINX配置(NGINX configuration)初始化的,并被主进程设置了一组监听套接字(listen sockets)。
NGINX工作进程会监听套接字上的事件(accept_mutex和kernel socketsharding),来决定什么时候开始工作。事件是由新的连接初始化的。这些连接被会分配给状态机(statemachine)—— HTTP状态机是最常用的,但NGINX还为流(原生TCP)和大量的邮件协议(SMTP,IMAP和POP3)实现了状态机。
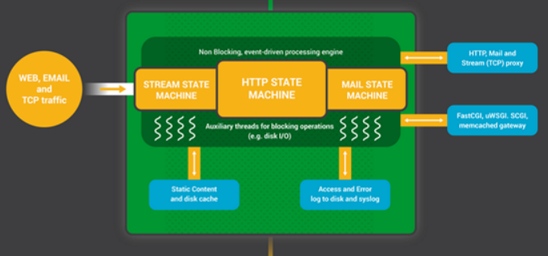
状态机本质上是一组告知NGINX如何处理请求的指令。大多数和NGINX具有相同功能的web服务器也使用类似的状态机——只是实现不同。
调度状态机
把状态机想象成国际象棋的规则。每个HTTP事务(HTTP transaction)都是一局象棋比赛。棋盘的一边是web服务器——坐着一位可以迅速做出决定的大师级棋手。另一边是远程客户端——在相对较慢的网络中,访问站点或应用程序的web浏览器。 然而,比赛的规则可能会很复杂。例如,web服务器可能需要与各方沟通(代理一个上游的应用程序),或者和认证服务器交流。web服务器的第三方模块也可以拓展比赛规则。
阻塞状态机
回忆一下我们之前对进程和线程的描述:是一组操作系统可调度的、运行在CPU内核上的独立指令集。大多数web服务器和web应用都使用一个连接/一个进程或一个连接/一个线程的模型来进行这局国际象棋比赛。每个进程或线程都包含一个将比赛玩到最后的指令。在这个过程中,进程是由服务器来运行的,它的大部分时间都花在“阻塞(blocked)”上,等待客户端完成其下一个动作。

- web服务器进程(web server process)在监听套接字上,监听新的连接(客户端发起的新比赛)
- 一局新的比赛发起后,进程就开始工作,每一步棋下完后都进入阻塞状态,等待客户端走下一步棋
- 一旦比赛结束,web服务器进程会看看客户是否想开始新的比赛(这相当于一个存活的连接)。如果连接被关闭(客户端离开或者超时),web服务器进程会回到监听状态,等待全新的比赛。
记住重要的一点:每一个活跃的HTTP连接(每局象棋比赛)都需要一个专用的进程或线程(一位大师级棋手)。这种架构非常易于扩展第三方模块(“新规则”)。然而,这里存在着一个巨大的不平衡:一个以文件描述符(file descriptor)和少量内存为代表的轻量级HTTP连接,会映射到一个单独的进程或线程——它们是非常重量级的操作系统对象。这在编程上是方便的,但它造成了巨大的浪费。
NGINX是真正的大师
也许你听说过车轮表演赛,在比赛中一个象棋大师要在同一时间对付几十个对手。

这就是NGINX工作进程玩“国际象棋”的方式。每一个工作进程都是一位大师(记住:通常情况下,每个工作进程占用一个CPU内核),能够同时对战上百棋手(实际上是成千上万)。
1. 工作进程在监听套接字和连接套接字上等待事件。
2. 事件发生在套接字上,工作进程会处理这些事件。
监听套接字上的事件意味着:客户端开始了一局新的游戏。工作进程创建了一个新的连接套接字。
连接套接字上的事件意味着:客户端移动了棋子。工作进程会迅速响应。
工作进程从不会在网络上停止,它时时刻刻都在等待其“对手”(客户端)做出回应。当它已经移动了这局比赛的棋子,它会立即去处理下一局比赛,或者迎接新的对手。
为什么它会比阻塞式多进程的架构更快?
NGINX的规模可以很好地支持每个工作进程上数以万计的连接。每个新连接都会创建另一个文件描述符,并消耗工作进程中少量的额外内存。每一个连接的额外消耗都很少。NGINX进程可以保持固定的CPU占用率。当没有工作时,上下文切换也较少。
在阻塞式的、一个连接/一个进程的模式中,每个连接需要大量的额外资源和开销,并且上下文切换(从一个进程到另一个进程)非常频繁。通过适当的系统调优,NGINX能大规模地处理每个工作进程数十万并发的HTTP连接,并且能在流量高峰期间不丢失任何信息(新比赛开始)。
Nginx 模块化设计
高度模块化的设计是 Nginx 的架构基础。Nginx 服务器被分解为多个模块,每个模块就是一个功能模块,只负责自身的功能,模块之间严格遵循“高内聚,低耦合”的原则。
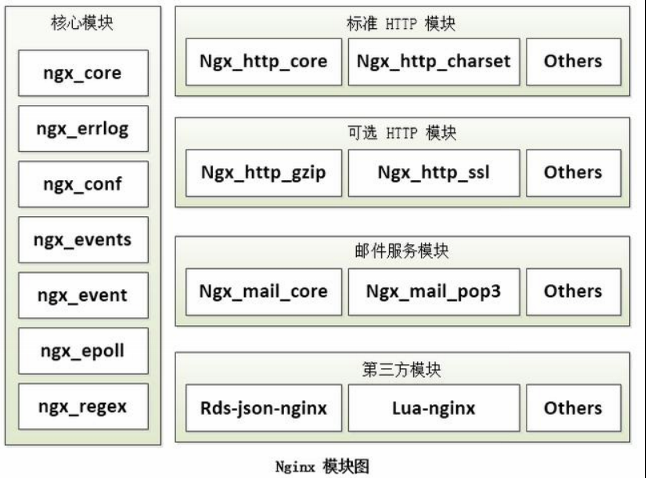
核心模块
核心模块是 Nginx 服务器正常运行必不可少的模块,提供错误日志记录、配置文件解析、事件驱动机制、进程管理等核心功能。
标准 HTTP 模块
标准 HTTP 模块提供 HTTP 协议解析相关的功能,如:端口配置、网页编码设置、HTTP 响应头设置等。
可选 HTTP 模块
可选 HTTP 模块主要用于扩展标准的 HTTP 功能,让 Nginx 能处理一些特殊的服务,如:Flash 多媒体传输、解析 GeoIP 请求、SSL 支持等。
邮件服务模块
邮件服务模块主要用于支持 Nginx 的邮件服务,包括对 POP3 协议、IMAP 协议和 SMTP 协议的支持。
第三方模块
第三方模块是为了扩展 Nginx 服务器应用,完成开发者自定义功能,如:Json 支持、Lua 支持等。
Nginx的请求方式处理
Nginx 是一个 高性能 的 Web 服务器,能够同时处理 大量的并发请求 。它结合 多进程机制和 异步机制 ,异步机制使用的是 异步非阻塞方式。
多进程机制
服务器每当收到一个客户端时,就有 服务器主进程 ( master process )生成一个 子进程( worker process )出来和客户端建立连接进行交互,直到连接断开,该子进程就结束了。
使用 进程 的好处是 各个进程之间相互独立 , 不需要加锁 ,减少了使用锁对性能造成影响,同时降低编程的复杂度,降低开发成本。其次,采用独立的进程,可以让 进程互相之间不会影响 ,如果一个进程发生异常退出时,其它进程正常工作, master 进程则很快启动新的 worker 进程,确保服务不会中断,从而将风险降到最低。
缺点是操作系统生成一个 子进程 需要进行 内存复制 等操作,在 资源 和 时间 上会产生一定的开销。当有 大量请求 时,会导致 系统性能下降 。
Nginx事件驱动模型
在 Nginx 的异步非阻塞机制中, 工作进程在调用 IO 后,就去处理其他的请求,当 IO 调用返回后,会通知该工作进程 。对于这样的系统调用,主要使用 Nginx 服务器的事件驱动模型来实现。

如上图所示, Nginx 的 事件驱动模型 由 事件收集器 、 事件发送器 和 事件处理器 三部分基本单元组成。
- 事件收集器:负责收集 worker 进程的各种 IO 请求;
- 事件发送器:负责将 IO 事件发送到 事件处理器 ;
- 事件处理器:负责各种事件的 响应工作 。
事件发送器将每个请求放入一个 待处理事件列表 ,使用非阻塞 I/O 方式调用 事件处理器 来处理该请求。其处理方式称为 “多路 IO 复用方法” ,常见的包括以下三种: select 模型、 poll模型、 epoll 模型。
Nginx进程处理模型
Nginx 服务器使用 master/worker 多进程模式 。多线程启动和执行的流程如下:
- 主程序 Master process 启动后,通过一个 for 循环来 接收 和 处理外部信号 ;
- 主进程通过 fork() 函数产生 worker 子进程 ,每个 子进程 执行一个 for 循环来实现 Nginx 服务器 对事件的接收 和 处理 。
一般推荐 worker 进程数 与 CPU 内核数 一致,这样一来不存在 大量的子进程 生成和管理任务,避免了进程之间 竞争 CPU 资源 和 进程切换 的开销。而且 Nginx 为了更好的利用 多核特性 ,提供了 CPU 亲缘性 的绑定选项,我们可以将某 一个进程绑定在某一个核 上,这样就不会因为 进程的切换 带来 Cache 的失效。
对于每个请求,有且只有一个 工作进程 对其处理。首先,每个 worker 进程都是从 master进程 fork 过来。在 master 进程里面,先建立好需要 listen 的 socket(listenfd) 之后,然后再 fork 出多个 worker 进程。
所有 worker 进程的 listenfd 会在 新连接 到来时变得 可读 ,为保证只有一个进程处理该连接,所有 worker 进程在注册 listenfd 读事件 前 抢占 accept_mutex ,抢到 互斥锁 的那个进程 注册 listenfd 读事件 ,在 读事件 里调用 accept 接受该连接。
当一个 worker 进程在 accept 这个连接之后,就开始 读取请求 , 解析请求 , 处理请求 ,产生数据后,再 返回给客户端 ,最后才 断开连接 ,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由 worker 进程来处理,而且只在一个 worker 进程中处理。
在 Nginx 服务器的运行过程中, 主进程 和 工作进程 需要进程交互。交互依赖于 Socket 实现的 管道 来实现。
主进程与工作进程交互
这条管道与普通的管道不同,它是由 主进程 指向 工作进程 的 单向管道 ,包含主进程向工作进程发出的 指令 , 工作进程 ID 等;同时 主进程 与外界通过 信号通信 ;每个 子进程 具备 接收信号 ,并处理相应的事件的能力。
工作进程与工作进程交互
这种交互是和 主进程-工作进程 交互是基本一致的,但是会通过 主进程 间接完成。 工作进程之间是 相互隔离 的,所以当工作进程 W1 需要向工作进程 W2 发指令时,首先找到 W2 的 进程ID ,然后将正确的指令写入指向 W2 的 通道 。 W2 收到信号采取相应的措施。
Nginx 原理篇的更多相关文章
- 【如何快速的开发一个完整的iOS直播app】(原理篇)
原文转自:袁峥Seemygo 感谢分享.自我学习 目录 [如何快速的开发一个完整的iOS直播app](原理篇) [如何快速的开发一个完整的iOS直播app](播放篇) [如何快速的开发一个完整的 ...
- iOS:app直播---原理篇
[如何快速的开发一个完整的iOS直播app](原理篇) 转载自简书@袁峥Seemygo:http://www.jianshu.com/p/7b2f1df74420 一.个人见解(直播难与易) 直播 ...
- 如何快速的开发一个完整的iOS直播app(原理篇)
目录 [如何快速的开发一个完整的iOS直播app](原理篇) [如何快速的开发一个完整的iOS直播app](播放篇) [如何快速的开发一个完整的iOS直播app](采集篇) 前言 大半年没写博客了,但 ...
- Cesium原理篇:5最长的一帧之影像
如果把地球比做一个人,地形就相当于这个人的骨骼,而影像就相当于这个人的外表了.之前的几个系列,我们全面的介绍了Cesium的地形内容,详见: Cesium原理篇:1最长的一帧之渲染调度 Cesium原 ...
- Cesium原理篇:3最长的一帧之地形(2:高度图)
这一篇,接着上一篇,内容集中在高度图方式构建地球网格的细节方面. 此时,Globe对每一个切片(GlobeSurfaceTile)创建对应的TileTerrain类,用来维 ...
- Cesium原理篇:7最长的一帧之Entity(下)
上一篇,我们介绍了当我们添加一个Entity时,通过Graphics封装其对应参数,通过EntityCollection.Add方法,将EntityCollection的Entity传递到DataSo ...
- Esfog_UnityShader教程_遮挡描边(原理篇)
咳咳,有段时间没有更新了,最近有点懒!把不少精力都放在C++身上了.闲言少叙,今天要讲的可和之前的几篇有所不同了,这次是一个次综合应用.这篇内容中与之前不同主要体现在下面几点上. 1.之前我们写的都是 ...
- nginx 原理&知识
2015年6月4日 17:04:20 星期四 发现两个关于nginx原理的系列文章, 非常好 http://blog.sina.com.cn/s/blog_6d579ff40100wi7p.html ...
- Tomcat 原理篇
TOMCAT 原理篇一.Tomcat 组成(Tomcat 由以下组件组成) 1.server a) Server是一个Catalina Servlet容器: b) Server 可以包含一个或多个se ...
随机推荐
- [AT2172] [agc007_e] Shik and Travel
题目链接 AtCoder:https://agc007.contest.atcoder.jp/tasks/agc007_e 洛谷:https://www.luogu.org/problemnew/sh ...
- NAT网络地址转换模拟过程
原理图,如图1 图1 以下为配置NAT网络地址转换的实验: eNSP模拟图,如图2 图2 Step1.给路由器的每个接口赋予一个地址,如图3,图4 图3 图4 AR1和AR2中添加路由表项,如图5,图 ...
- 最小生成树-----Prim算法与Kruskal算法(未完
生成树(spanning tree):无向联通图的某个子图中,任意两个顶点互相都联通并且形成了一棵树,那么这棵树就叫做生成树. 最小生成树(MST,minimum spanning tree):如果为 ...
- JAVA本地TXT文件解决中文乱码问题
import java.io.*; public class ReadFile { public static void main(String[] args) { try { File file = ...
- MySQL 语句中执行优先级——and比or高
转: MySQL 语句中执行优先级——and比or高 2017年04月20日 13:33:03 十步行 阅读数:7381 版权声明:本文为博主原创文章,未经博主允许不得转载. https://bl ...
- git 列出两个 commit 之间变更的文件列表
git diff <commit1> <commit2> --stat 如: git diff 74ecf17dc 1ee25ed3c --stat src/assets 上面 ...
- python学习(九) 网络编程学习--简易网站服务器
python `网络编程`和其他语言都是一样的,服务器这块步骤为:`1. 创建套接字``2. 绑定地址``3. 监听该描述符的所有请求``4. 有新的请求到了调用accept处理请求` Python ...
- 手动搭建高可用的kubernetes 集群
之前按照和我一步步部署 kubernetes 集群的步骤一步一步的成功的使用二进制的方式安装了kubernetes集群,在该文档的基础上重新部署了最新的v1.8.2版本,实现了kube-apiserv ...
- tomcat maven插件启动报错tomcat-users.xml cannot be read
tomcat maven插件启动报错tomcat-users.xml cannot be read [ERROR] Failed to execute goal org.codehaus.mojo:t ...
- 前端PHP入门-002-安装WAMP的集成环境md
> 第一次讲PHP,让我感觉还是满好玩的,一种新的知识的学习,需要我们努力! > 这次PHP课程计划是15天快速入门的课程! 只是单独的讲PHP语言,不涉及很深的内容,只是想让web前端的 ...