小数据池,bytes
- '''
python2 python3- '''
#python2
#print() print 'abc'
#range() xrange() 生成器
# raw_input()- #python3
#print('abc')
#range()
# input()- # = 赋值 == 比较值是否相等 is 比较,比较的是内存地址 id(内容)
# li1 = [1,2,3]
# li2 = li1
# li3 = li2
# print(id(li1),id(li2))
- # id函数:获取的是对象在内存中的地址
- # is :比对2个变量的对象引用(对象在内存中的地址,即id() 获得的值)是否相同。如果相同则返回True,否则返回False。换句话说,就是比对2个变量的对象引用是否指向同一个对象
- # ==:比对2个变量指向的对象的内容是否相同。
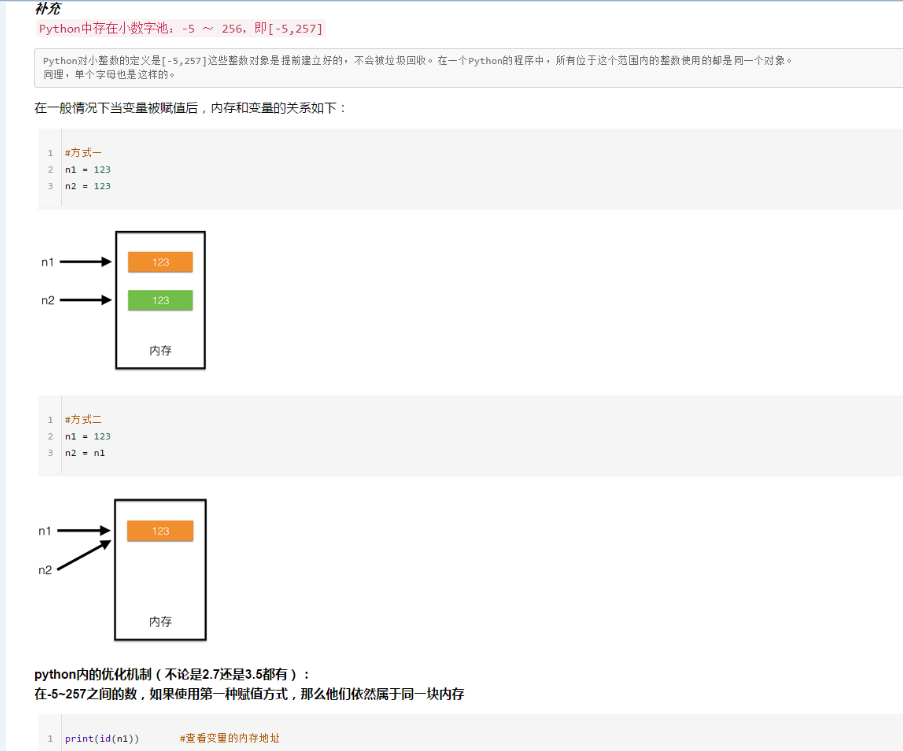
- #数字,字符串 小数据池
#数字的范围 -5 -- 256
#字符串:1,不能有特殊字符
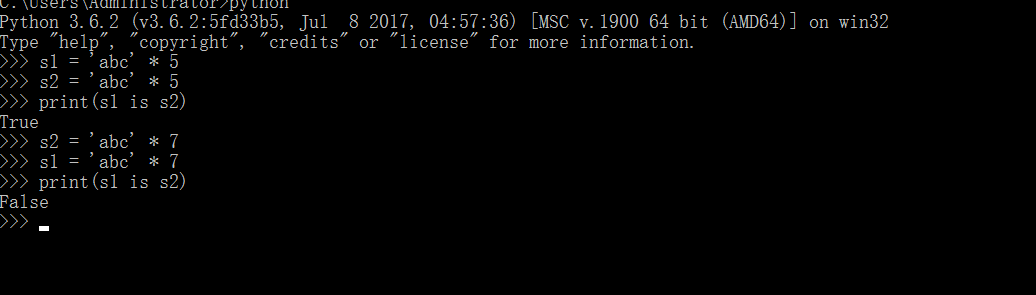
# 2,s*20 还是同一个地址,s*21以后都是两个地址
# i1 = 6
# i2 = 6
# print(id(i1),id(i2))
# i1 = 300
# i2 = 300
# print(id(i1),id(i2))- #剩下的 list dict tuple set
# l1 = [1,]
# l2 = [1,]
# print(l1 is l2)
列表,字典,元祖,无序不重复元素集,这些新建的都是一个新的内存地址。- # s = 'alex'
# s1 = b'alex'
# print(s,type(s))
# print(s1,type(s1))- # s = '中国'
# print(s,type(s))
# s1 = b'中国'
# print(s1,type(s1))- s1 = 'alex'
# encode 编码,如何将str --> bytes, ()
s11 = s1.encode('utf-8')
s11 = s1.encode('gbk')
print(s11)
s2 = '中国'
s22 = s2.encode('utf-8')
s22 = s2.encode('gbk')
print(s22)
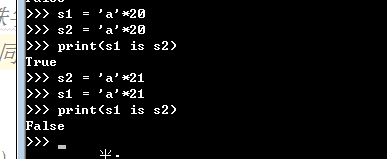
- 相关链接:
https://www.cnblogs.com/chownjy/p/6625299.html
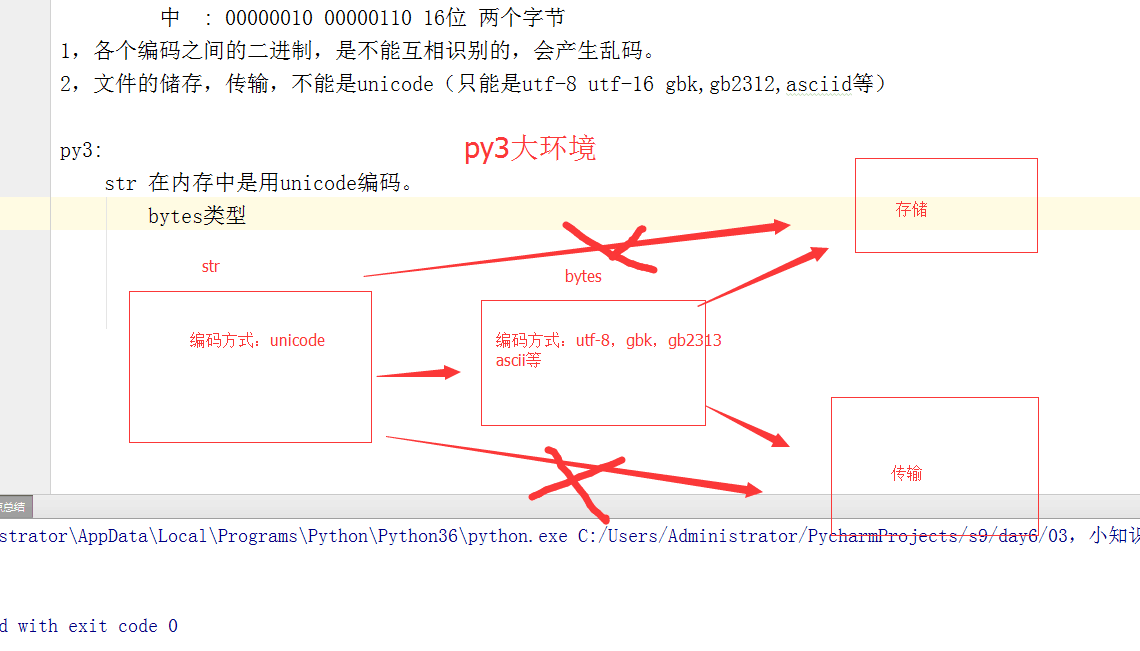
Python 3最重要的新特性之一是对字符串和二进制数据流做了明确的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,你不能拼接字符串和字节流,也无法在字节流里搜索字符串(反之亦然),也不能将字符串传入参数为字节流的函数(反之亦然)。
下面让我们深入分析一下二者的区别和联系。
编码发展的历史
在谈bytes和str之前,需要先说说关于编码是如何发展的。。
在计算机历史的早期,美国为代表的英语系国家主导了整个计算机行业,26个英文字母组成了多样的英语单词、语句、文章。因此,最早的字符编码规范是ASCII码,一种8位即1个字节的编码规范,它可以涵盖整个英语系的编码需要。
编码是什么?编码就是把一个字符用一个二进制来表示。我们都知道,所有的东西,不管是英文、中文还是符号等等,最终存储在磁盘上都是01010101这类东西。在计算机内部,读取和存储数据归根结底,处理的都是0和1组成的比特流。问题来了,人类看不懂这些比特流,如何让这些010101对人类变得可读呢?于是出现了字符编码,它是个翻译机,在计算机内部某个地方,透明的帮我们将比特流翻译成人类可以直接理解的文字。对于一般用户,不需要知道这个过程是什么原理,是怎么执行的。但是对于程序员却是个必须搞清楚的问题。
以ASCII编码为例,它规定1个字节8个比特位代表1个字符的编码,也就是“00000000”这么宽,一个一个字节的解读。例如:01000001表示大写字母A,有时我们会“偷懒"的用65这个十进制来表示A在ASCII中的编码。8个比特位,可以没有重复的最多表示2的8次方(255)个字符。
后来,计算机得到普及,中文、日文、韩文等等国家的文字需要在计算机内表示,ASCII的255位远远不够,于是标准组织制定出了叫做UNICODE的万国码,它规定任何一个字符(不管哪国的)至少以2个字节表示,可以更多。其中,英文字母就是用2个字节,而汉字是3个字节。这个编码虽然很好,满足了所有人的要求,但是它不兼容ASCII,同时还占用较多的空间和内存。因为,在计算机世界更多的字符是英文字母,明明可以1个字节就能够表示,非要用2个。
于是UTF-8编码应运而生,它规定英文字母系列用1个字节表示,汉字用3个字节表示等等。因此,它兼容ASCII,可以解码早期的文档。UTF-8很快就得到了广泛的应用。
在编码的发展历程中,我国还创造了自己的编码方式,例如GBK,GB2312,BIG5。他们只局限于在国内使用,不被国外认可。在GBK编码中,中文汉字占2个字节。
bytes和str之间的异同
回到bytes和str的身上。bytes是一种比特流,它的存在形式是01010001110这种。我们无论是在写代码,还是阅读文章的过程中,肯定不会有人直接阅读这种比特流,它必须有一个编码方式,使得它变成有意义的比特流,而不是一堆晦涩难懂的01组合。因为编码方式的不同,对这个比特流的解读也会不同,对实际使用造成了很大的困扰。下面让我们看看Python是如何处理这一系列编码问题的:
>>> s = "中文">>> s'中文'>>> type(s)<class 'str'>>>> b = bytes(s, encoding='utf-8')>>> bb'\xe4\xb8\xad\xe6\x96\x87'>>> type(b)<class 'bytes'>
从例子可以看出,s是个字符串类型。Python有个内置函数bytes()可以将字符串str类型转换成bytes类型,b实际上是一串01的组合,但为了在ide环境中让我们相对直观的观察,它被表现成了b'\xe4\xb8\xad\xe6\x96\x87'这种形式,开头的b表示这是一个bytes类型。\xe4是十六进制的表示方式,它占用1个字节的长度,因此”中文“被编码成utf-8后,我们可以数得出一共用了6个字节,每个汉字占用3个,这印证了上面的论述。在使用内置函数bytes()的时候,必须明确encoding的参数,不可省略。
我们都知道,字符串类str里有一个encode()方法,它是从字符串向比特流的编码过程。而bytes类型恰好有个decode()方法,它是从比特流向字符串解码的过程。除此之外,我们查看Python源码会发现bytes和str拥有几乎一模一样的方法列表,最大的区别就是encode和decode。
从实质上来说,字符串在磁盘上的保存形式也是01的组合,也需要编码解码。
如果,上面的阐述还不能让你搞清楚两者的区别,那么记住下面两几句话:
在将字符串存入磁盘和从磁盘读取字符串的过程中,Python自动地帮你完成了编码和解码的工作,你不需要关心它的过程。
使用
bytes类型,实质上是告诉Python,不需要它帮你自动地完成编码和解码的工作,而是用户自己手动进行,并指定编码格式。Python已经严格区分了
bytes和str两种数据类型,你不能在需要bytes类型参数的时候使用str参数,反之亦然。这点在读写磁盘文件时容易碰到。
在bytes和str的互相转换过程中,实际就是编码解码的过程,必须显式地指定编码格式。
>>> bb'\xe4\xb8\xad\xe6\x96\x87'>>> type(b)<class 'bytes'>>>> s1 = str(b)>>> s1"b'\\xe4\\xb8\\xad\\xe6\\x96\\x87'">>> type(s1)<class 'str'>>>> s1 = str(b, encoding='utf-8')>>> s1'中文'>>> type(s1)<class 'str'>
我们再把字符串s1,转换成gbk编码的bytes类型:
>>> s1'中文'>>> type(s1)<class 'str'>>>> b = bytes(s1, encoding='gbk')>>> bb'\xd6\xd0\xce\xc4'

小数据池,bytes的更多相关文章
- python2与python3的区别 ,小数据池 bytes 类型
一.python2和3的区别 在python3中 在python2中 print('ab')方式打印内容()括号是必须要有的. print 'ab' 可以加可以不加. 只有range 有ran ...
- python之路day06--python2/3小区别,小数据池的概念,编码的进阶str转为bytes类型,编码和解码
python2#print() print'abc'#range() xrange()生成器#raw_input() python3# print('abc')# range()# input() = ...
- python基础之小数据池、代码块、编码和字节之间换算
一.代码块.if True: print(333) print(666) while 1: a = 1 b = 2 print(a+b) for i in '12324354': print(i) 虽 ...
- python -- 小数据池 is和 == 再谈编码
1.小数据池 python程序是由代码块构成的,一个代码块的文本作为python程序的执行单元. 代码块:一个模块,一个函数,一个类,甚至一个command命令都是一个代码块,一个文件也是一个代码块, ...
- python 浅谈小数据池和编码
⼀. ⼩数据池 在说⼩数据池之前. 我们先看⼀个概念. 什么是代码块: 根据提示我们从官⽅⽂档找到了这样的说法: A Python program is constructed from code b ...
- python之路--小数据池,再谈编码,is和 == 的区别
一 . 小数据池 # 小数据池针对的是: int, str, bool 在py文件中几乎所有的字符串都会缓存. # id() 查看变量的内存地址 s = 'attila' print(id(s)) 二 ...
- python 小数据池 is和 == 编码解码
########################总结######################### 今日主要内容 1. 小数据池, id() 小数据池针对的是: int, str, bool 在p ...
- python 小数据池,is and "==",decode ,encode
一:小数据池 1.python运行中的缓存: 2.目的:缓存我们字符串,整数,布尔值.在使用的时候不需要创建过多的对象 3.python 缓存数据:缓存:int, str, bool. ...
- python:id与小数据池与编码
一.id与小数据池 id:查的是内存地址 a = 100 b = 100 print(a == b)#比较的数值 print(a is b)#比较的是id print(id(a),id(b))#id相 ...
随机推荐
- JAVA多线程提高二:传统线程的互斥与同步&传统线程通信机制
本文主要是回顾线程之间互斥和同步,以及线程之间通信,在最开始没有juc并发包情况下,如何实现的,也就是我们传统的方式如何来实现的,回顾知识是为了后面的提高作准备. 一.线程的互斥 为什么会有线程的互斥 ...
- PHP与数据库
连接数据库 Connect 访问数据库的数据之前,先要与数据库建立连接,使用mysql_connect()方法与数据库建立连接. mysql_connect()参数 <?php //server ...
- 你必须了解Spring的生态
Spring不止是提供了IOC.AOP的功能,还提供了大量的基于Spring的项目,拿来用就行了,用于一站式开发,大大降低了开发的难度. 下面列举下主要的一些Spring的生态项目: Spring B ...
- 【洛谷 P4166】 [SCOI2007]最大土地面积(凸包,旋转卡壳)
题目链接 又调了我两个多小时巨亏 直接\(O(n^4)\)枚举4个点显然不行. 数据范围提示我们需要一个\(O(n^2)\)的算法. 于是\(O(n^2)\)枚举对角线,然后在这两个点两边各找一个点使 ...
- iphone6设置企业qq
1.首先要确定foxmail的账户服务器信息,右上角-账户账户管理-服务器设置 2.iphone端:
- 【IDEA】与Eclipse "Link with Editor"等价功能设置
Link With Editor是Eclipse内置功能中十分小巧,但却异常实用的一个功能.这个开关按钮 (Toggle Button) 出现在各式导航器视图 ( 例如 Resource Explor ...
- fileIO和OS操作文件和目录
1.FileIO操作文件 # 文件IO,读取文件和创建文件 # 1.读取键盘输入 x=input("please input number") print("您输入的是& ...
- Machine Learning系列--隐马尔可夫模型的三大问题及求解方法
本文主要介绍隐马尔可夫模型以及该模型中的三大问题的解决方法. 隐马尔可夫模型的是处理序列问题的统计学模型,描述的过程为:由隐马尔科夫链随机生成不可观测的状态随机序列,然后各个状态分别生成一个观测,从而 ...
- UOJ#58/BZOJ 3052【WC2013】糖果公园
好写好调的莫队算法,就算上树了仍然好写好调. 传送门 http://uoj.ac/problem/58 简要做法 将树按照dfs序分块,然后将询问按照(u所在块,v所在块,时间)作为关键字进行排序,依 ...
- python继承问题
python构造函数:__init__(): 如果子类定义了自己的__init__构造方法函数,当子类的实例对象被创建时,子类只会执行自己的__init__方法函数,如果子类未定义自己的构造方法函数, ...