I01-通过查询资料库方式来监控Informatica调度情况
--登陆INFA资料库,运行下面的SQL
--想要更加个性化查询的话注意看SQL倒数第二第三行的备注
SELECT
RUN_DATE,
START_TIME ,
END_TIME,
FOLIDER ,
WORKFLOW,
WORKLET_LVL3,
WORKLET_LVL2,
WORKLET_LVL1,
SESSION_NAME,
MAPPING_NAME,
RUN_STATUS,
SUSSESSFUL_SOURC_ROWS,
FAILED_SOURCE_ROWS,
SUCCCESSFUL_ROWS,
FAILED_ROWS,
RUN_ERR_CODE,
RUN_ERR_MSG,
FIRST_ERROR_CODE,
FIRST_ERROR_MSG,
LAST_ERROR_CODE,
LAST_ERROR,
SESSION_LOG_FILE,
BAD_FILE_LOCATION
FROM (SELECT
TRUNC(T1.START_TIME) AS RUN_DATE, --跑数日期
T1.START_TIME AS START_TIME, --开始时间
T1.END_TIME AS END_TIME, --结束时间
T.SUBJECT_AREA AS FOLIDER, --FOLDER
T.WORKFLOW_NAME AS WORKFLOW, --WORKFLOW
T4.INSTANCE_NAME AS WORKLET_LVL3, --大爷级WORKLET
T3.INSTANCE_NAME AS WORKLET_LVL2, --爷爷级WORKLET
T2.INSTANCE_NAME AS WORKLET_LVL1, --父级WORKLET
T1.INSTANCE_NAME AS SESSION_NAME, --SESSION
decode(T1.RUN_STATUS_CODE,
1,'Succeeded',
2,'Disabled',
3,'Failed',
4,'Stopped',
5,'Aborted',
6,'Running',
7,'Suspending',
8,'Suspended',
9,'Stopping',
10,'Aborting',
11,'Waiting',
12,'Scheduled',
13,'Unscheduled',
14,'Unknown',
15,'Terminated'
) as RUN_STATUS, --运行状态
T1.RUN_ERR_CODE RUN_ERR_CODE, --错误代码
T1.RUN_ERR_MSG RUN_ERR_MSG, --错误信息
T.FIRST_ERROR_CODE, --第一次发生错误的代码
T.FIRST_ERROR_MSG, --第一次发生错误的信息
T.LAST_ERROR_CODE, --最后发生错误的代码
T.LAST_ERROR, --最后发生错误的信息
T.SESSION_LOG_FILE, --SESSION LOG路径
T.BAD_FILE_LOCATION, --BAD_FILE路径
T.MAPPING_NAME MAPPING_NAME, --MAPPING
T.SUCCESSFUL_SOURCE_ROWS SUSSESSFUL_SOURC_ROWS, --读取源成功条数
T.FAILED_SOURCE_ROWS FAILED_SOURCE_ROWS, --读取源失败条数
T.SUCCESSFUL_ROWS SUCCCESSFUL_ROWS, --插入目标成功条数
T.FAILED_ROWS FAILED_ROWS --插入目标失败条数
FROM REP_SESS_LOG T
INNER JOIN REP_TASK_INST_RUN T1 --返回session状态信息
ON T.SUBJECT_ID = T1.SUBJECT_ID
AND T.WORKFLOW_ID = T1.WORKFLOW_ID
AND T.WORKFLOW_RUN_ID = T1.WORKFLOW_RUN_ID
AND T.WORKLET_RUN_ID = T1.WORKLET_RUN_ID
AND T.SESSION_ID = T1.TASK_ID
AND T.INSTANCE_ID = T1.INSTANCE_ID
AND T1.TASK_TYPE_NAME = 'Session' LEFT JOIN REP_TASK_INST_RUN T2 --返回父级WKL
ON T1.SUBJECT_ID = T2.SUBJECT_ID
AND T1.WORKFLOW_ID = T2.WORKFLOW_ID
AND T1.WORKFLOW_RUN_ID = T2.WORKFLOW_RUN_ID
AND T1.WORKLET_RUN_ID = T2.CHILD_RUN_ID
AND T2.TASK_TYPE_NAME = 'Worklet' LEFT JOIN REP_TASK_INST_RUN T3 --返回爷爷级WKL,到这一级其实就可以看到session是属于哪个电厂的了
ON T2.SUBJECT_ID = T3.SUBJECT_ID
AND T2.WORKFLOW_ID = T3.WORKFLOW_ID
AND T2.WORKFLOW_RUN_ID = T3.WORKFLOW_RUN_ID
AND T2.WORKLET_RUN_ID = T3.CHILD_RUN_ID
AND T3.TASK_TYPE_NAME = 'Worklet' LEFT JOIN REP_TASK_INST_RUN T4 --返回老大爷级WKL
ON T3.SUBJECT_ID = T4.SUBJECT_ID
AND T3.WORKFLOW_ID = T4.WORKFLOW_ID
AND T3.WORKFLOW_RUN_ID = T4.WORKFLOW_RUN_ID
AND T3.WORKLET_RUN_ID = T4.CHILD_RUN_ID
AND T4.TASK_TYPE_NAME = 'Worklet'
) WHERE
START_TIME > TRUNC(SYSDATE-1) ------筛选时间
AND RUN_STATUS = 'Failed' --session运行状态的筛选,若只想看失败的session信息,则令RUN_STATUS = 'Failed';否则去掉该条件,此时可以看到所有session运行状态 ORDER BY RUN_DATE DESC, WORKFLOW, WORKLET_LVL3, WORKLET_LVL2, WORKLET_LVL1, SESSION_NAME --排序以更好的形式展示出来
查询得到的结果示例如下:

拿第一条举例,由RUN_STATUS这个字段内容(Failed)可以看出,ETL0_ODS这个folder下的WKF_ETL0这个workflow下的WKL_FMIS_GJXNY worklet下的WKL_T07 worklet 下的WKL_FMIS_APPLSYS worklet下的s_m_ods_fmis_applsys_fnd_flex_value_sets这个session调度出错了,出错原因是无法连接上数据库。
如果想让该SQL每天自动运行,然后将查数结果发送到邮箱的话,我的做法需要下面几个步骤:
(1)将该sql保存到Informatica服务器上的一个文件中(base_sql.txt),有可能需要去掉上面SQL里的中文注释。
(2)Informatica服务器上写一个shell脚本(workflow_dispatch.sh),脚本中调用sqluldr2命令来远程到Informatica资料库上执行base_sql.txt文件中的SQL语句,结果保存到一个文件中。命令如下:
sqluldr2 user=${conn_str} sql=${py_file_dir}${sql_file} fast=yes field="," head=yes file=${result_dir}${result_file} escape='\' escf=0x0a esct=n
其中escape='\' escf=0x0a esct=n等参数设定是为了去掉sql执行结果中有的数据里面存在换行。
(3)执行完第二步之后,查数结果已经保存到某个文件中( sqluldr2命令中file参数指定的文件)了,接下来只需在shell中调用相应的邮件服务命令将结果文件发送到邮件即可。至于Informatica服务器上的邮件服务,使用msmtp+mutt或者写python脚本或者其他的都行,我采用的python脚本的方式(sendmail.py)。若是想使用msmtp+mutt的方式,可参考以下链接进行配置:http://www.cnblogs.com/suhaha/p/8655033.html。
(4)虽然存放查数结果的文件占用空间不多,也应该在shell中定时删除太久之前的文件,比如每次都固定删除一个月之前的文件。
完整的workflow_dispatch.sh脚本示例如下:
#!/bin/bash check_date=$(date +%Y%m%d_%H%M) base_dir="/data/ODS_TO_EDW_DATACHECK/"
result_dir=${base_dir}"result_file/"
py_file_dir=${base_dir}"py_file/" #conn_str="repdb01/infa@10.xxx.xxx.182:1521/test" #DEV environment
conn_str="repdb/oracle@10.xxx.xxx.165:1521/appdb" #PRD environment result_file="dispatch_result_"${check_date}".csv"
sql_file="base_sql.txt"
tar_file="dispatch_result_"${check_date}".tar.gz"
mail_file="sendmail.py" echo "execute sqluldr2..."
echo -e "\n" sqluldr2 user=${conn_str} sql=${py_file_dir}${sql_file} fast=yes field="," head=yes file=${result_dir}${result_file} escape='\' escf=0x0a esct=n if [ $? -eq ]; then
echo -e "\n"
echo "sqluldr2 run successful!"
echo -e "\n" echo "check the count of error session..."
cd ${result_dir}
cnt=`cat ${result_file} | wc -l`
cnt=`expr ${cnt} - `
echo "[cnt of error sessions ]: "${cnt}
echo -e "\n" #echo "compress the result file into : "${tar_file}
#tar -czvf ${tar_file} ${result_file} && rm -rf ${result_file} echo -e "\n"
echo "Send mail..."
if [ ${cnt} -gt ]; then
python ${py_file_dir}${mail_file} "Result of Informatica Dispatch (PRD)" \
"Infamatica Dispatch finish. "${cnt}" error sessions. Check the attachment for more details." ${result_dir}${result_file} $@
else
python ${py_file_dir}${mail_file} "Result of Informatica Dispatch (PRD)" "Infamatica Dispatch finish. No error." ${result_dir}${result_file} $@
fi else
echo "sqluldr2 run failed!"
exit
fi
完整的sendmail.py脚本示例如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*- import sys
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
from email.utils import formataddr """
该脚本调用格式: python /data/ODS_TO_EDW_DATACHECK/py_file/sendmail.py +theme +body +attachment +recipient1 +recipient2 + ... +recipients
调用示例:python sendmail.py "Result of DataCheck" "23333..This is body..." /data/ODS_TO_EDW_DATACHECK/py_file/sendmail.py 983523649@qq.com 备注:添加的附件必须是全路径的,比如:/data/ODS_TO_EDW_DATACHECK/py_file/sendmail.py
""" def sendmail( theme, body, attachment, recipients ): mail_host="smtp.163.com"
mail_user="182xxxx7782@163.com"
mail_pass="wysxxx9527" subject = theme
text = body
file = attachment
receivers = recipients
sender = "182xxx7782@163.com" message = MIMEMultipart()
message["From"] = formataddr(["INFA SERVER", sender])
message["To"] = Header("ETL Engineer", "utf-8")
message["Subject"] = Header(subject, "utf-8")
message.attach(MIMEText(text, "plain", "utf-8"))
name = file[ file.rindex(r"/")+1 : len(file) ]
att = MIMEText(open(file, "r").read(), "base64", "utf-8")
att["Content-Type"] = "application/octet-stream"
att["Content-Disposition"] = 'attachment; filename=' + '"' + name + '"'
message.attach(att) try:
smtpObj = smtplib.SMTP()
smtpObj.connect(mail_host, 25)
smtpObj.login(mail_user,mail_pass)
smtpObj.sendmail(sender, receivers, message.as_string())
print "\nSend Mail Successfully!"
except smtplib.SMTPException:
print "\nError: Send Mail Failed!"
print str(smtplib.SMTPException) #*********************************************************************************************
if __name__ == '__main__': theme = sys.argv[1]
body = sys.argv[2]
attachment = sys.argv[3]
recipients = sys.argv[4: len(sys.argv)] print "theme: ", theme
print "body: ", body
print "attachment: ", attachment
print "recipients: ", recipients sendmail( theme, body, attachment, recipients )
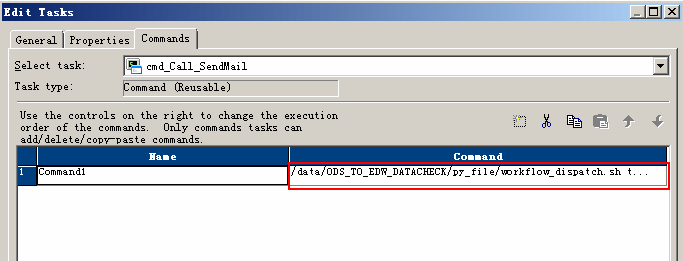
(5)在Informatica中新建一个Task,Task中调用shell脚本。如下图。然后在INFA每日调度的最后一个session或者最后一个workflow末尾加上该Task即可。
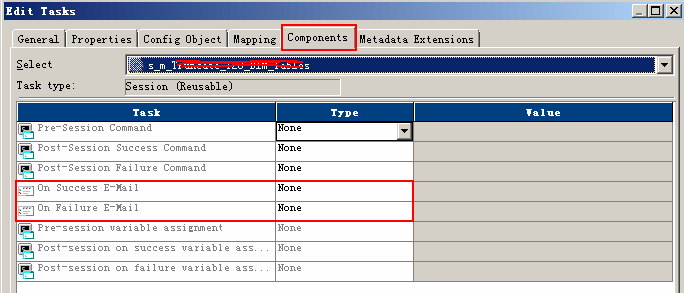
最后,当然INFA自身也能配置邮件服务,并且配置之后它的报错也能详细到session级别,如下图。说实话我没用过。
不过在项目的实施过程中,开发的session数量一般都是上几百个的,每个session都配置的话会比较麻烦;再者,假设真的每个session都配置了,然后每个session跑成功或者失败了都给你发一封邮件,一般INFA的调度还都在半夜,会疯掉的~
我之所采用上面描述的方法是因为:项目开发之初压根没考虑到调度的监控问题,都项目后期了前台数据对不上之后往前溯源了才发现是某个session挂掉好久了,因此才想起配置这么个东西。
另外,我觉得这种方式比INFA自身的邮件设置方式要相对好一点吧~INFA调度完成之后统一查询,速度快,效率也高,最重要的是每天只给你发一封邮件。。。
I01-通过查询资料库方式来监控Informatica调度情况的更多相关文章
- MySQL重构查询的方式
在优化有问题的查询时,目标应该是找到一个更优的方法获得实际需要的结果--而不一定总要从MySQL获取一模一样的结果集.有时候可以查询转换一种写法让其返回一样的结果,但是性能更好.但也可以通过修改应用代 ...
- Jstatd方式远程监控Linux下 JVM运行情况
前言 最近一个项目部署在服务器上运行时出现了问题,经过排查发现是java内存溢出的问题,所以为了实时监控服务器java内存的情况,需要远程查看服务器上JVM内存的一些情况.另外服务器系统是CentOS ...
- springdata 查询思路:基本的单表查询方法(id,sort) ---->较复杂的单表查询(注解方式,原生sql)--->实现继承类---->复杂的多表联合查询 onetomany
springdata 查询思路:基本的单表查询方法(id,sort) ---->较复杂的单表查询(注解方式,原生sql)--->实现继承类---->复杂的多表联合查询 onetoma ...
- 当页面是动态时 如果后台存储id可以通过查询后台方式获取对象;当后台没有存储时候 只有通过前端标记了 例如标记数量为10 我们根据传递过来的10循环取值
当页面是动态时 如果后台存储id可以通过查询后台方式获取对象;当后台没有存储时候 只有通过前端标记了 例如标记数量为10 我们根据传递过来的10循环取值
- SQL-30 使用子查询的方式找出属于Action分类的所有电影对应的title,description
题目描述 film表 字段 说明 film_id 电影id title 电影名称 description 电影描述信息 CREATE TABLE IF NOT EXISTS film ( film_i ...
- MySql 缓存查询原理与缓存监控 和 索引监控
MySql缓存查询原理与缓存监控 And 索引监控 by:授客 QQ:1033553122 查询缓存 1.查询缓存操作原理 mysql执行查询语句之前,把查询语句同查询缓存中的语句进行比较,且是按字节 ...
- Hibernate的查询的方式
Hibernate的查询的方式 在Hibernate中提供了很多种的查询的方式.Hibernate共提供了五种查询方式. Hibernate的查询方式:OID查询 OID检索:Hibernate根据对 ...
- Django之ORM优化查询的方式
ORM优化查询的方式 一.假设有三张表 Room id 1 2 .. 1000 User: id 1 .. 10000 Booking: user_id room_id time_id date 1 ...
- 为什么要监控sql语句,以及如何监控,都有哪几种方式可以监控。
快速阅读 为什么要监控sql语句,以及如何监控,都有哪几种方式可以监控. 我们知道sql server 中有个工具叫sql profile ,可以实时监控sql server中 执行的sql 语句,以 ...
随机推荐
- jdk+Tomcat环境
1.Tomcat概述 Tomcat服务器由Apache提供,开源免费.安装Tomcat之前需要先安装JDK,其实无论哪一种Javaweb服务器都需要先安装JDK. Tomcat6支持Servlet2. ...
- zookeeper 阿里滴滴 有点用 zookeeper主从选举方式
面试也经常问kafka的原理,以及zookeeper与kafka原理的区别:kafka 数据一致性-leader,follower机制与zookeeper的区别: zookeeper是如何实现负载均衡 ...
- Java线程同步的方法
如果向一个变量写值,而这个变量接下来可能会被另一个线程所读取,或者从一个变量读值,而它的值可能是前面由另一个线程写入的,此时就必须使用同步. sychronized Java语言的关键字,当它用来修饰 ...
- g2o的使用
相关文献 1.论文 Grisetti, Giorgio, et al. “A tutorial on graph-based SLAM.” IEEE Intelligent Transportatio ...
- left join、right join、inner join、full join
转自:某一网友 left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录 right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录inner join ...
- javascript总结系列49:javaScript教程:原型链不可变
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8& ...
- unity小记
1.window下的Occlusion Culling是实现遮挡剔除效果,即不再摄像机里出现的物体使其不被渲染. 这样做要使物体为静态的,而且效果在设计时只在Occlusion面板下有效 2.wind ...
- ubuntun16.0 登陆密码忘记
1. 开机,如下图所示(没有装虚拟机,手机拍的图片凑合这看把): 2. 此时会有一个选项:Advanced Options for Ubuntu, 选中直接回车 ,如下图: 3. 看到里面有很多选项, ...
- Android-原生对话框
package liudeli.ui.all; import android.app.Activity; import android.app.AlertDialog; import android. ...
- Android-ListView-ArrayAdapter
我在上一篇博客中Android-动态添加控件到ScrollView,写到可以用Java动态添加控件到Scrollview的孩子LinearLayout里面去,这种方式是不合理的,因为这种方式是一次性把 ...