DataFrame数据批量做线性回归
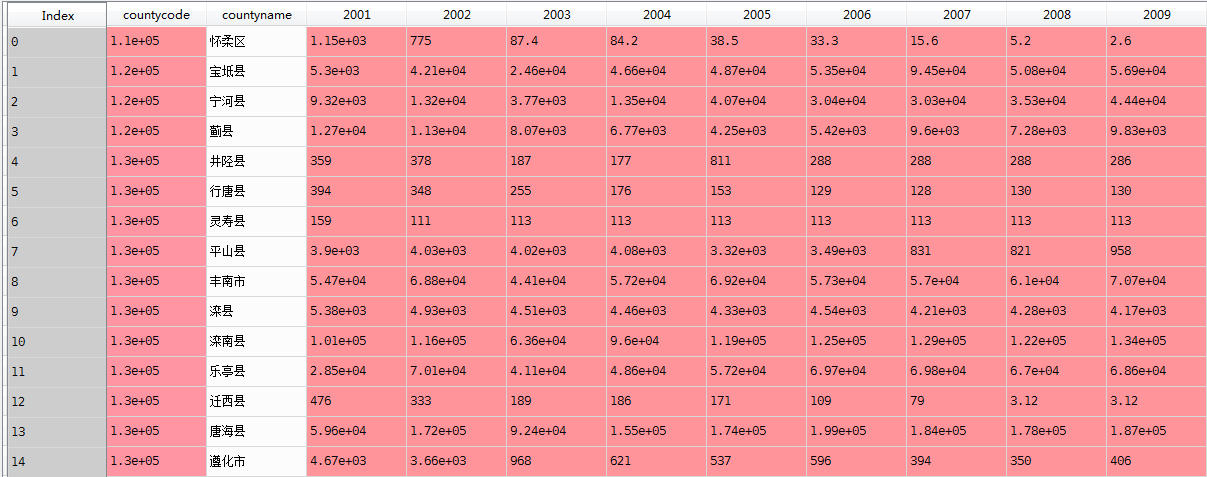
我们通常用pandas读取csv文件为DataFrame数据格式,如下图,是部分县2001年到2009年的某种作物的产量数据。我们希望求得9年的增长趋势,即求一个一元线性回归模型的斜率,这个时候便可以调用python的sklearn包中的线性回归模型计算。
思路:
将2001-2009年作为自变量X,需要注意的是sklearn的模型输入的变量是矩阵,因此要用numpy将list转化为矩阵,然后用ix方法定位每行数据为因变量y。pandas数据索引可参考博文点击打开链接。当然,最后输出的斜率的形式也是矩阵的数组,用简单的嵌套循环将其转为列表就可以了。
具体代码如下:
from pandas import DataFrame,Seriesimport pandas as pdfrom sklearn import linear_modelimport numpy as np
def trend()crop = pd.read_csv('....')X = np.array([[2001,2002,2003,2004,2005,2006,2007,2008,2009]]).Tregr = linear_model.LinearRegression()trend = []for i in range(0,1271):y = rice.ix[i,2:11]regr.fit(X,y)trend.append(regr.coef_)# list in list, we need to change data structiontrend1 = []for i in trend:for j in i:trend1.append(j)trend2 = Series(trend1)rice_trend = pd.concat([rice,trend2],axis=1)return rice_trendrice_trend.to_csv('rice_trend.csv', index=False)
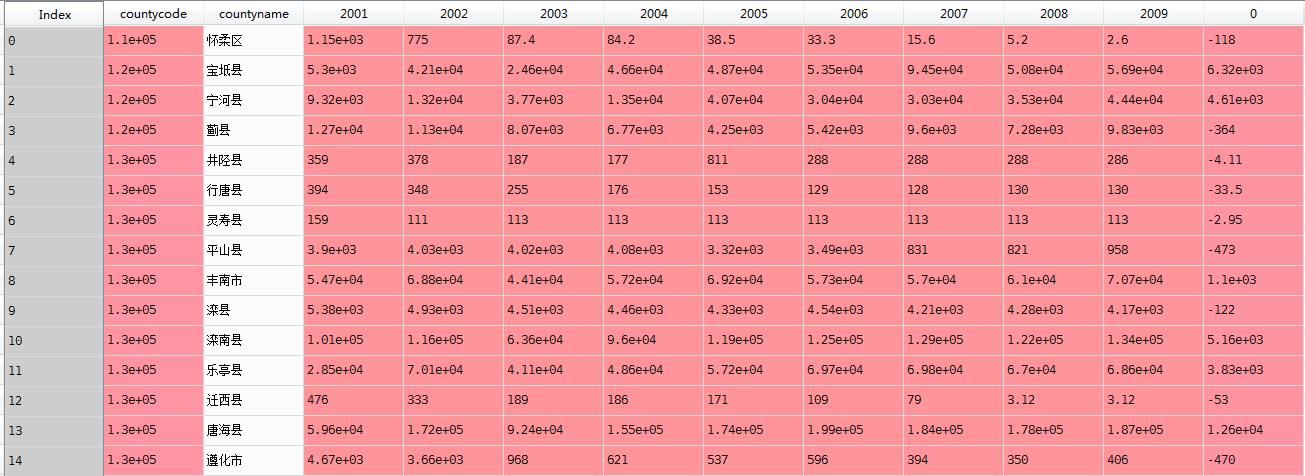
最后效果如下:
DataFrame数据批量做线性回归的更多相关文章
- SharePoint自动化系列——通过PowerShell在SharePoint中批量做数据
转载请注明出自天外归云的博客园:http://www.cnblogs.com/LanTianYou/ PowerShell是基于.NET的一门脚本语言,对于SharePoint一些日常操作支持的很好. ...
- 使用事务操作SQLite数据批量插入,提高数据批量写入速度,源码讲解
SQLite数据库作为一般单机版软件的数据库,是非常优秀的,我目前单机版的软件产品线基本上全部替换Access作为优选的数据库了,在开发过程中,有时候需要批量写入数据的情况,发现传统的插入数据模式非常 ...
- c#数据批量插入
由于之前面试中经常被问到有关EF的数据批量插入问题,今天以Sqlserver数据库为例,对.net中处理数据批量处理的方案进行了测试对比. 1.四种测试方案 (1)普通的EF数据批量插入:即调用DbS ...
- 批量插入数据, 将DataTable里的数据批量写入数据库的方法
大量数据导入操作, 也就是直接将DataTable里的内容写入到数据库 通用方法: 拼接Insert语句, 好土鳖 1. MS Sql Server: 使用SqlBulkCopy 2. MySql ...
- 学习《精通数据科学从线性回归到深度学习》PDF+代码分析
数据科学内容广泛,涉及到统计分析.机器学习以及计算机科学三方面的知识和技能.学习数据科学,推荐学习<精通数据科学从线性回归到深度学习>. 针对技术书籍,最好的阅读方法是对照每一章的示例代码 ...
- oracle 批量更新之将一个表的数据批量更新至另一个表
oracle 批量更新之将一个表的数据批量更新至另一个表 CreationTime--2018年7月3日17点38分 Author:Marydon Oracle 将一个表的指定字段的值更新至另一个 ...
- Django model中数据批量导入bulk_create()
在Django中需要向数据库中插入多条数据(list).使用如下方法,每次save()的时候都会访问一次数据库.导致性能问题: for i in resultlist: p = Account(nam ...
- Java实现Excel数据批量导入数据库
Java实现Excel数据批量导入数据库 概述: 这个小工具类是工作中的一个小插曲哦,因为提数的时候需要跨数据库导数... 有的是需要从oracle导入mysql ,有的是从mysql导入oracle ...
- 数据批量插入MSSQL
MSSQL数据批量插入优化详细 序言 现在有一个需求是将10w条数据插入到MSSQL数据库中,表结构如下,你会怎么做,你感觉插入10W条数据插入到MSSQL如下的表中需要多久呢? 或者你的批量数据 ...
随机推荐
- Java -D命令对应的代码中获取-D后面的参数 和 多个参数时-D命令的使用
1. Java代码: public class TestDPara { public static void main(String[] args) { String flag = System.ge ...
- 防止XSS攻击的方式
主要有三种请求方式,进行过滤替换非法符号 1.普通的GET请求数据: 2.FORM表单提交数据: 3.Json格式数据提交: 把下面5个文件放入项目中即可 package com.joppay.adm ...
- [BZOJ2599]Race
Description 给一棵树,每条边有权.求一条简单路径,权值和等于K,且边的数量最小.N <= 200000, K <= 1000000 Input 第一行 两个整数 n, k 第二 ...
- [BZOJ1912]巡逻
Description Input 第一行包含两个整数 n, K(1 ≤ K ≤ 2).接下来 n – 1行,每行两个整数 a, b, 表示村庄a与b之间有一条道路(1 ≤ a, b ≤ n). Ou ...
- 永久更改hostname主机名
vim /etc/sysconfig/network NETWORKING=yesHOSTNAME=keepalived-nginx1GATEWAY=192.168.33.2 vim /etc/hos ...
- Axis.Labels.CustomSize
tChart1.Axes.Bottom.Labels.CustomSize = ; //Changes spacing occupied by the axis labels between the ...
- 二进制转化 - bitset
2017-08-28 10:55:17 writer:pprp 在之前写了一个关于bitset用法的贴之后,这是第一次运用,不得不说如果不用的话还是一头雾水 以后写代码要标记开始时间,和结束时间了,我 ...
- class.getResource()和getResourceAsStream的用法
转自:http://blog.csdn.net/lcj8/article/details/3502849 class.getResource()的用法 用JAVA获取文件,听似简单,但对于很多像我这样 ...
- location的部分属性
http://www.w3school.com.cn/jsref/dom_obj_location.asp location.host 可以设置或返回主机名和当前url的端口 www.w3sch ...
- Mysql数据库实用语句集
mysql实用语句 (1).从第0行开始取,取3行(一般用于分页)select * from student limit 0,3 (2).查看当前数据库编码 show variables like ' ...