python爬虫之解析库正则表达式
上次说到了requests库的获取,然而这只是开始,你获取了网页的源代码,但是这并不是我们的目的,我们的目的是解析链接里面的信息,比如各种属性 @href @class span 抑或是p节点里面的文本内容,但是我们需要一种工具来帮我们寻找出这些节点,总不能让我们自己一个一个复制粘贴来完成吧,那样的话,还要程序员干嘛>>计算机是为了方便人们才被发明出来的.
这次我们使用一个非常好用的工具>>正则表达式,可能有的大佬已经听说过了,哦,就是那么一个东西,并说,不是用css选择器或者xpath,beautifulsoup来解析不是更好吗?当然,我开始的时候也是听大佬们这么说的,但是再一些简单的提取信息里,正则表达式的速度确实是最快的,而且有相同的结构的话,构造的表达式更快,关于正则表达式详解大家可以去百度一下>>正则表达式详解<<那里有更多的使用方法,我只是总结利用了一些我个人认为比较好用的正则表达式用法.
例如我们获取了以下的一个网页源代码:
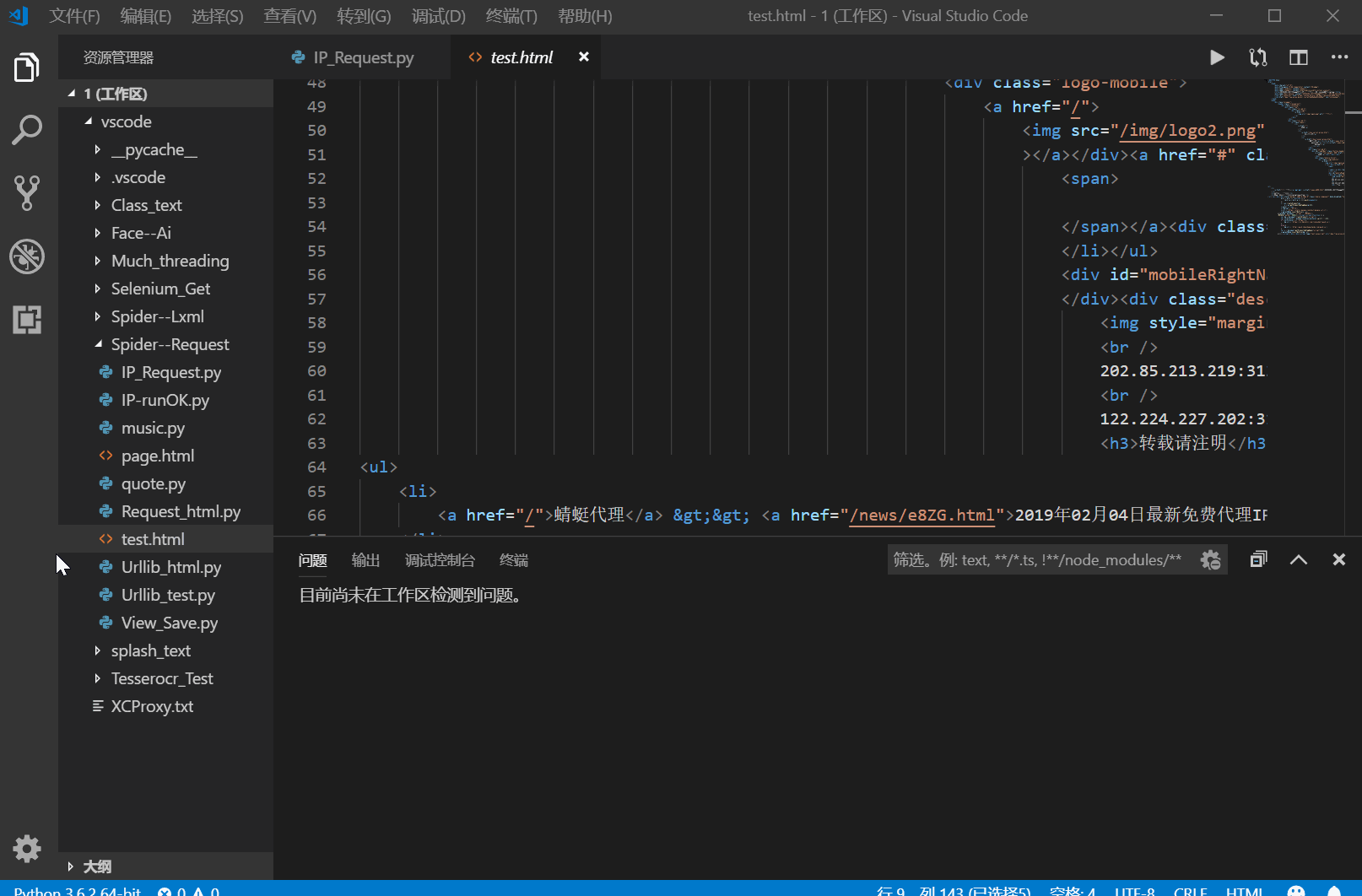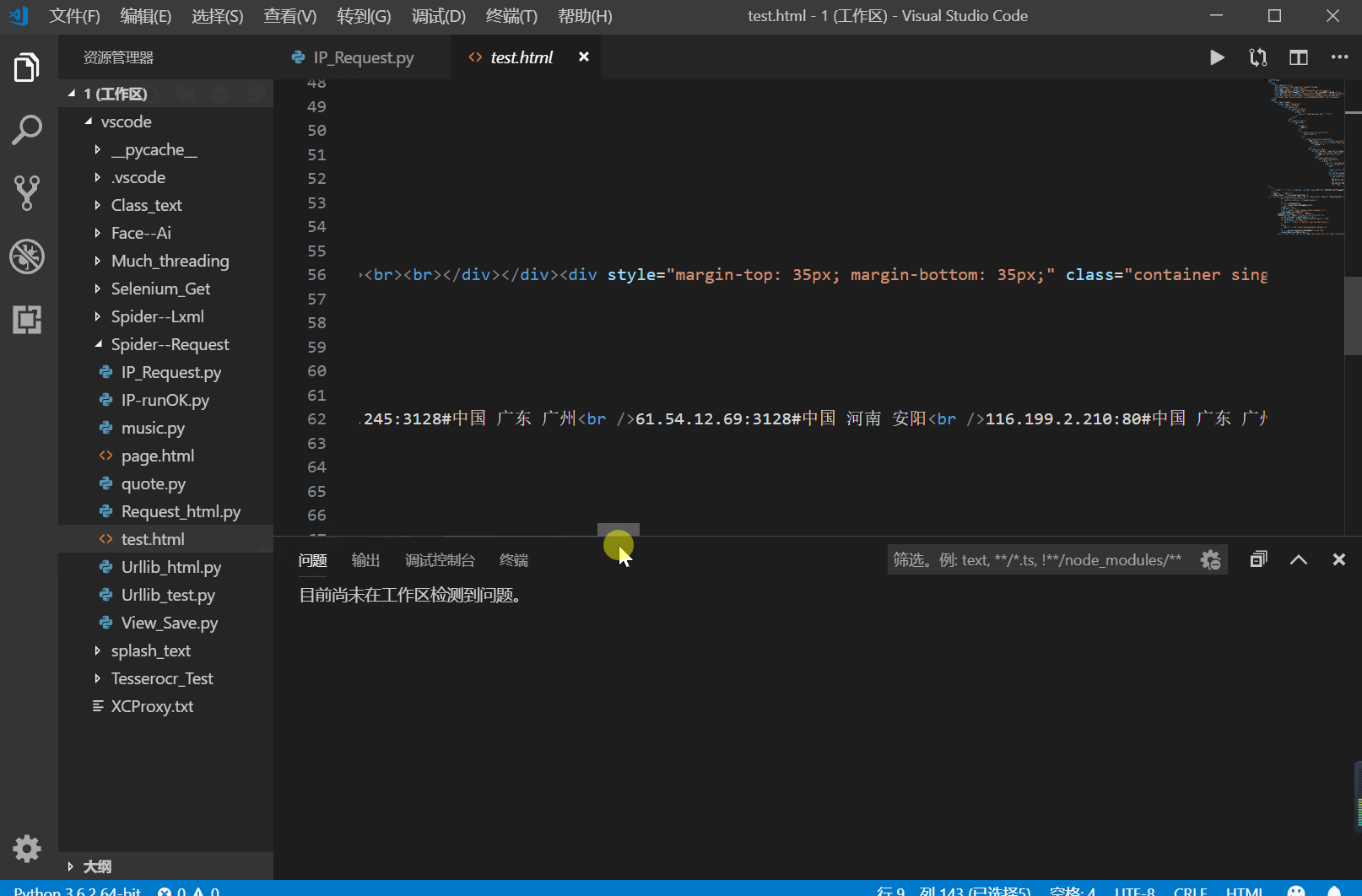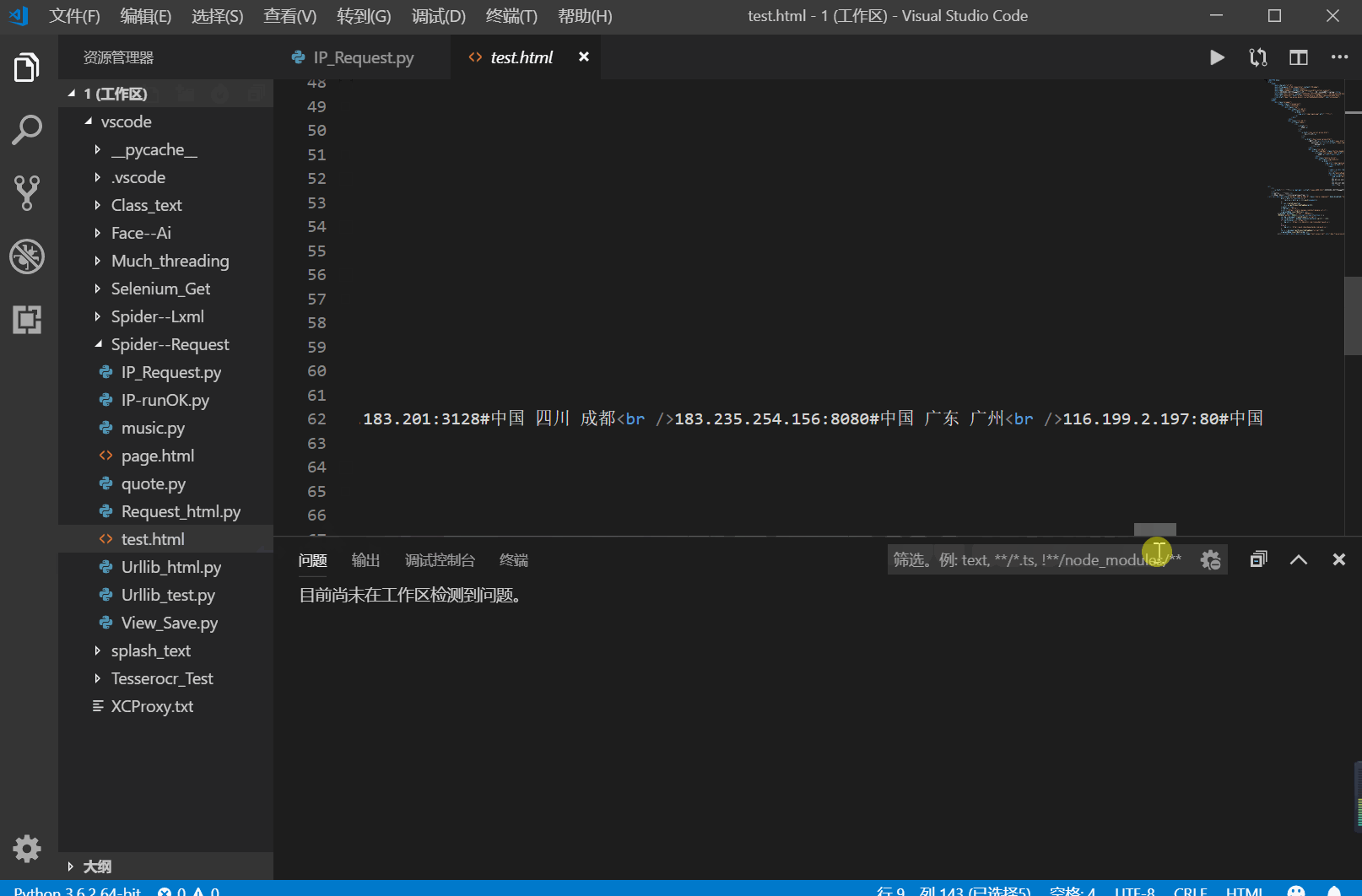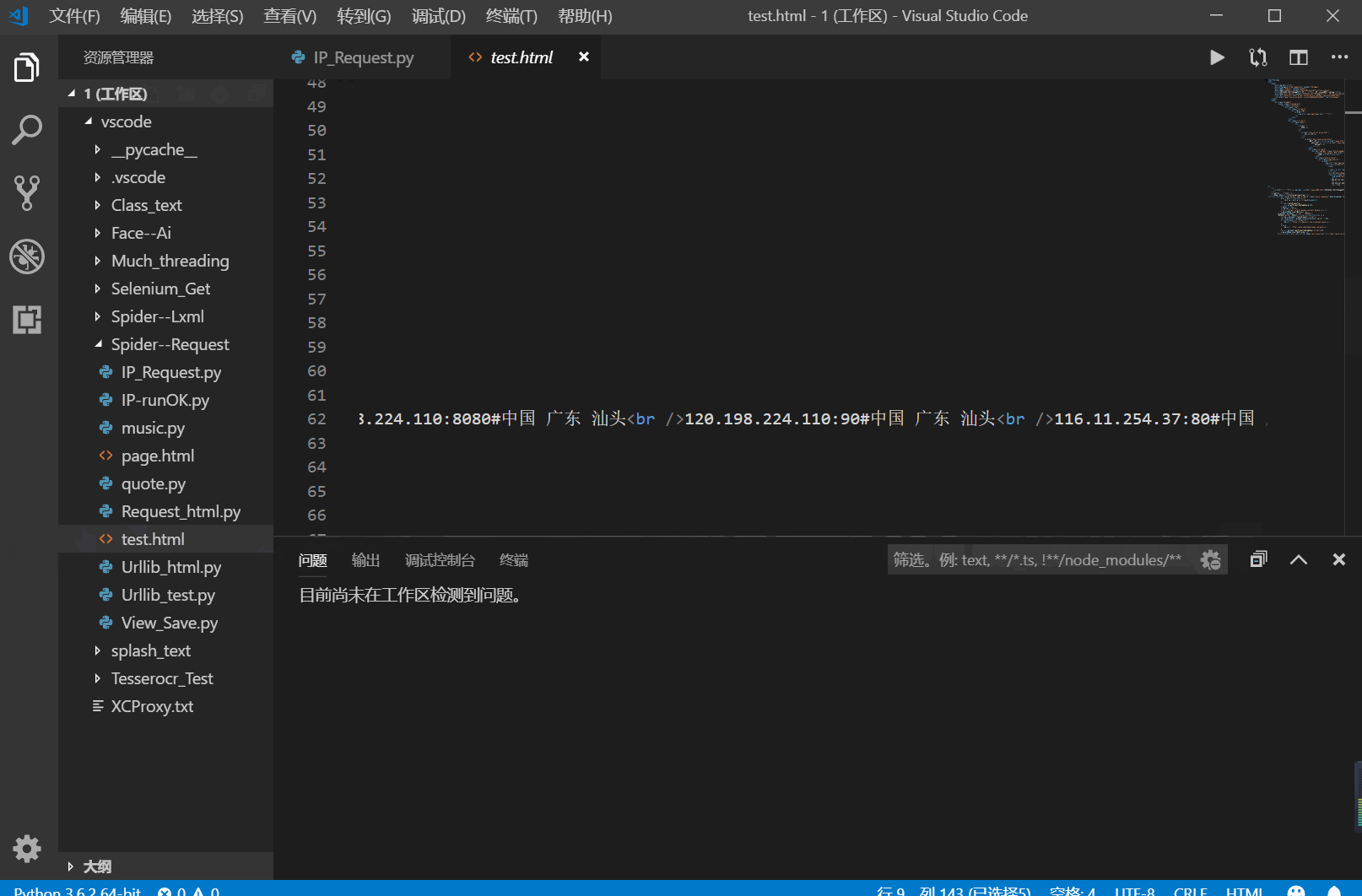
我们想要获取br节点里面的IP地址,怎么办呢/我们可以构造表达式 首先我们得了解一下元字符:
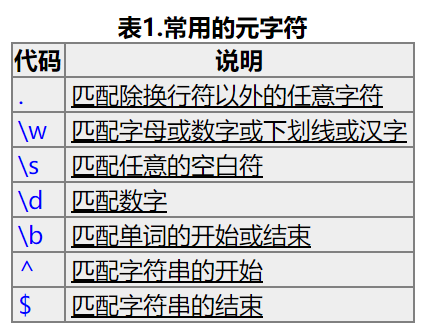
这里说明了匹配得用法,\w就是匹配除了非字符的,例如空格 , $%^.!@#这些全部别省略而过,因为不符合匹配规则,想要匹配空格,就要换成\s 这里我们再了解一下限定符的概念:
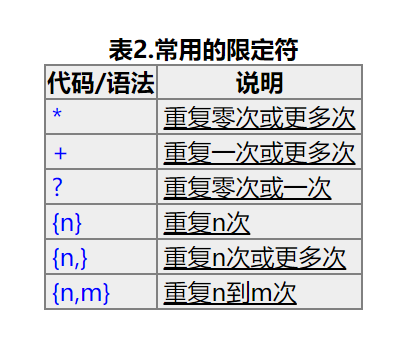
限定符的意思根据我的理解是匹配该符合匹配规则的次数,如果没有要求,它可能匹配出全部给你,也可能只匹配第一个结果给你,限定符就起到了匹配次数的效果,让你做到想使用匹配规则多少次就多少次.下面是一些常用的正则表达式:

可能大家看的有些疑惑,那是因为你之前没有接触过表达式,但是你参照一下上面的规则,再参悟一下,多尝试匹配,看看错在哪里,大概坚持一两天,你就会有一种豁然开朗的感觉,哦,原来是这么一回事啊,我理解一下一个规则用法,比如用户名的匹配规则:<< /^是匹配的开始 然后到[a-z0-9 是说匹配从a到z和0到9的所有字符,然后是_-,,它说明在里面可以匹配下划线_和字符- ,{3,16}是匹配从3次到16次,意思是说该用户可能限制在3到16字节,超过就没有意义了,多了就会导致提取信息的不纯洁性了>> 当然有时候我们想偷懒怎么办,这些规则有太复杂了,光是构造就得花费很多时间了,这时候,我最喜欢得懒惰限定符出现了,先看规则:

这里可以这样理解 (.*)是匹配尽可能多的字符串,(.*?)是匹配尽可能匹配少的字符 在python中()表示返回匹配得内容,内容为()里面得字符,如果你想获取@href的属性,直接构造为('.*?href="(.*?)" ,h.*?')就可以获取href的属性了,不过要记住,它返回的是一个列表的形式,所以你想要实现分行显示,还要对列表进行遍历,输入到文本中,继而实现简单的爬取信息.演示如下:
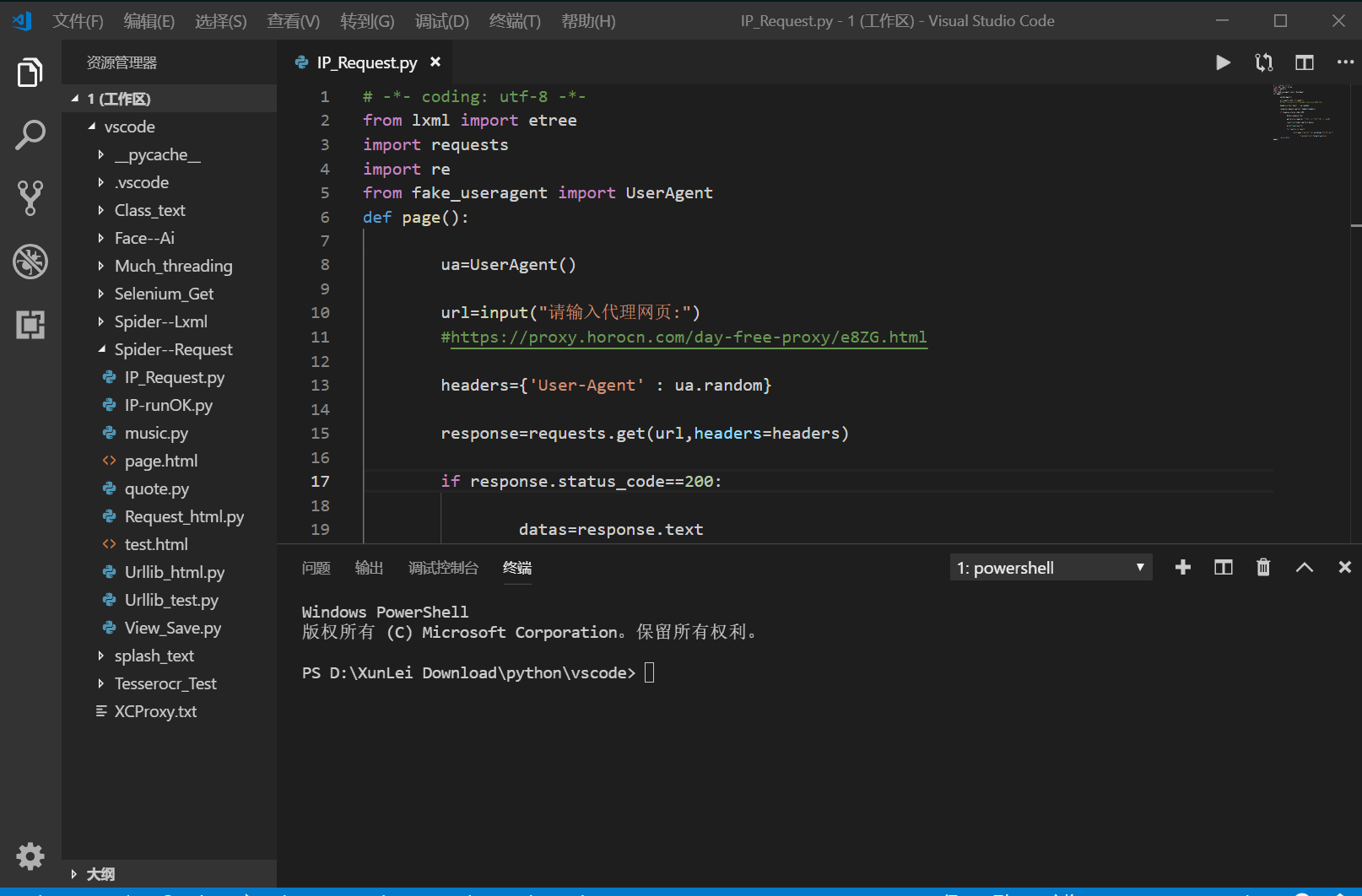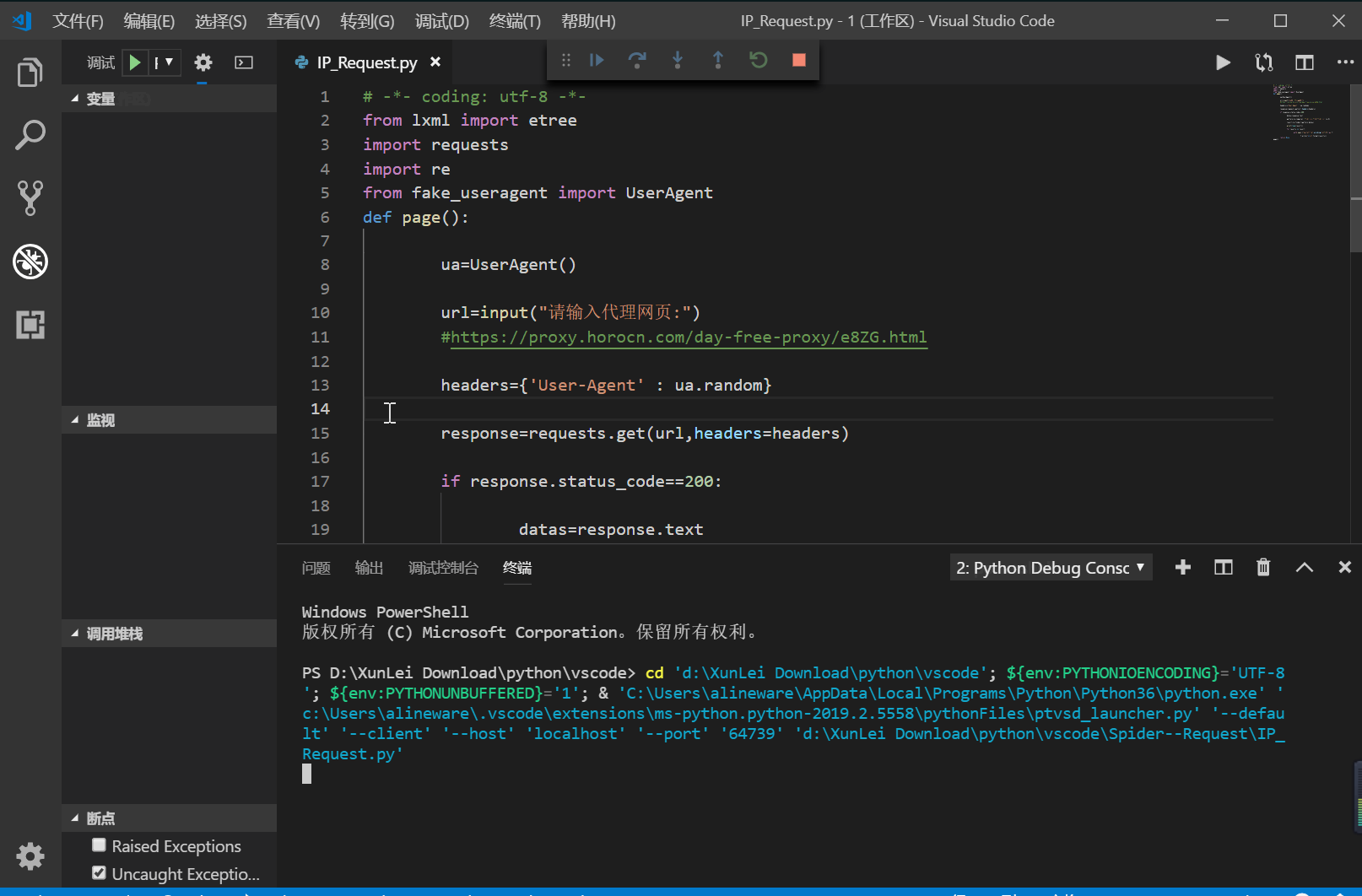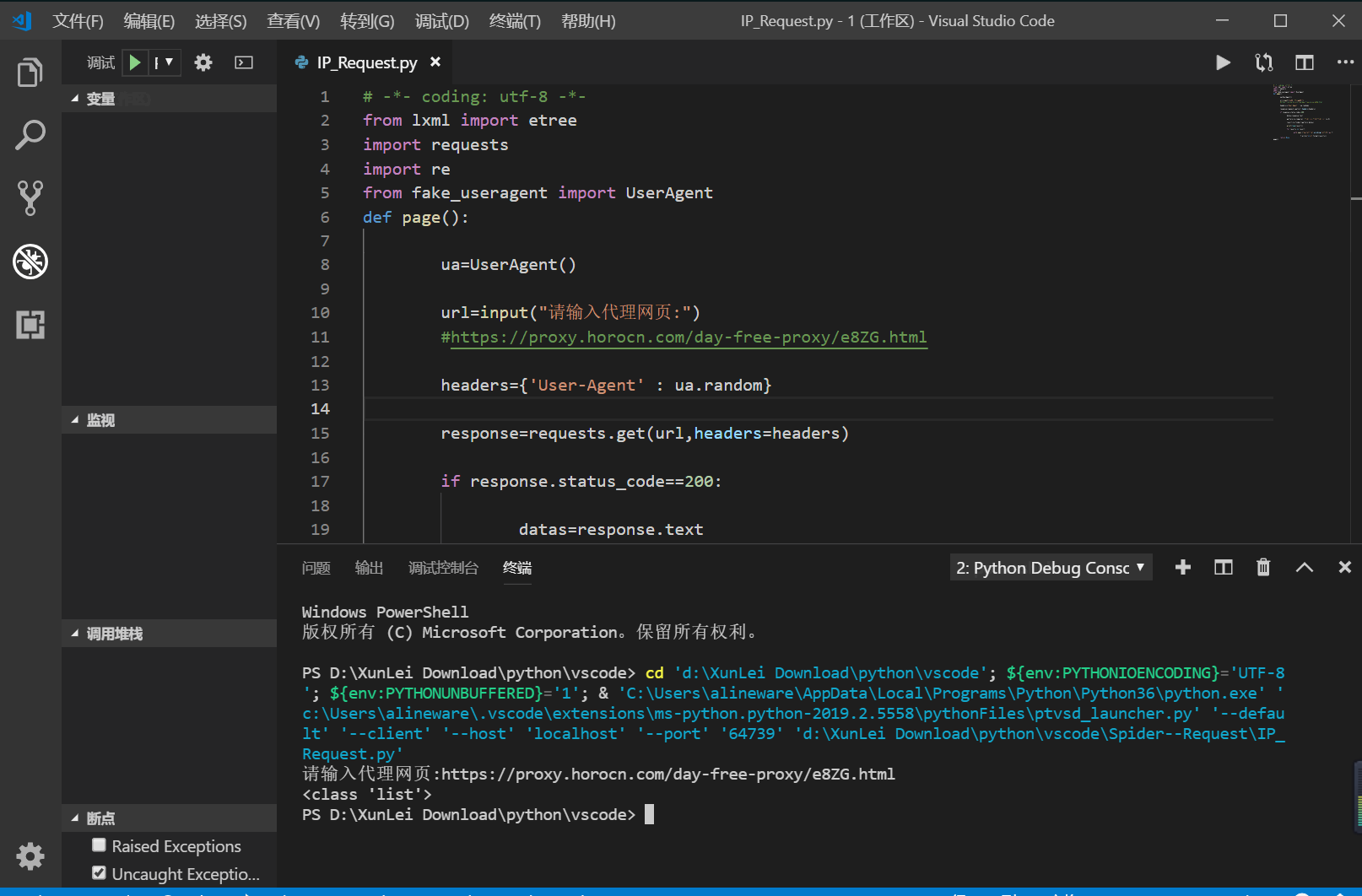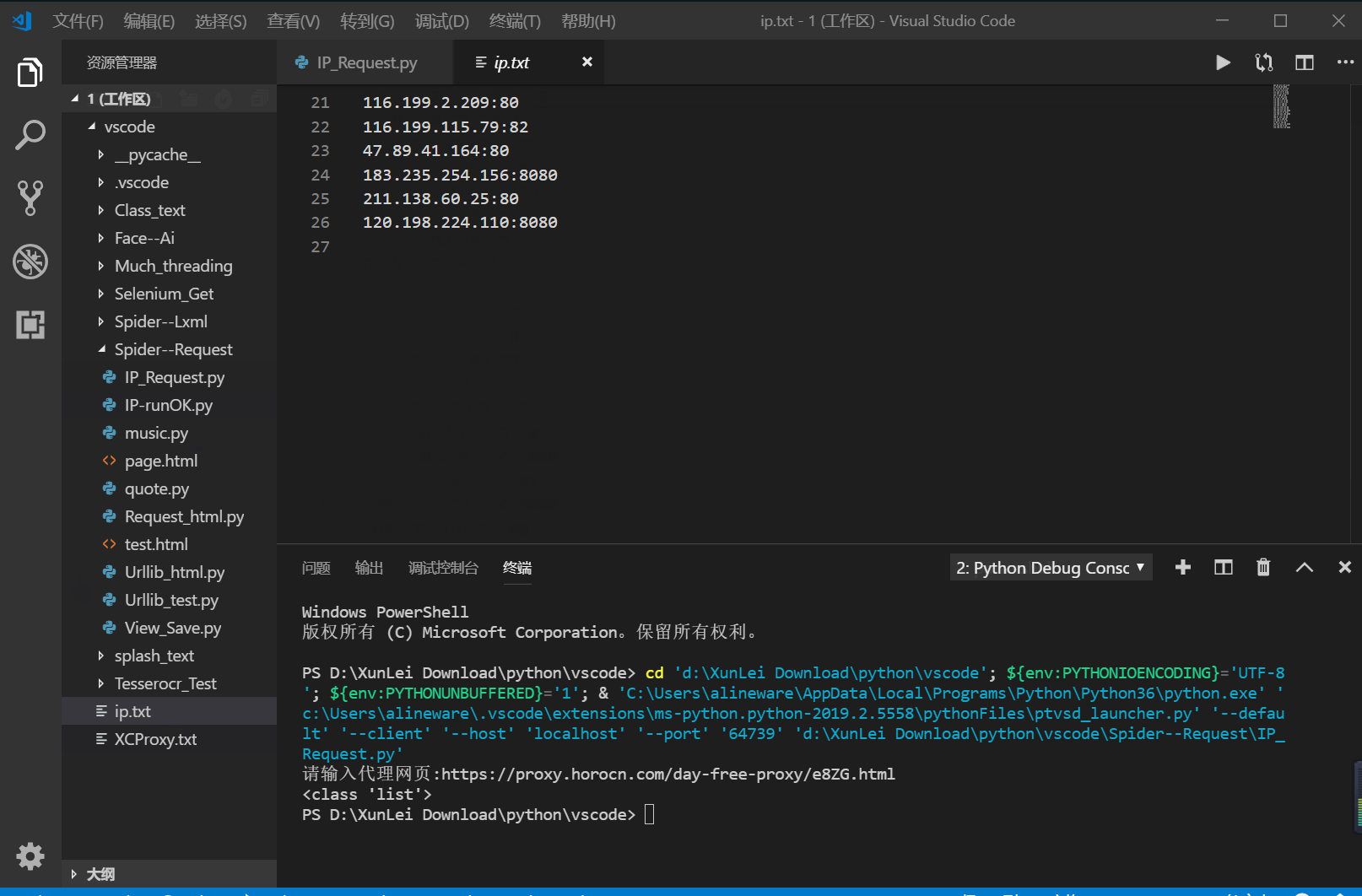
我把我自己写的源代码贴出来,可能不是很完善,只是一个很简单的函数,哪里有缺陷大佬们指出一下
# -*- coding: utf-8 -*-
# author :HXM
from lxml import etree
import requests
import re
from fake_useragent import UserAgent
def page(): ua=UserAgent() url=input("请输入代理网页:")
#https://proxy.horocn.com/day-free-proxy/e8ZG.html headers={'User-Agent' : ua.random} response=requests.get(url,headers=headers) if response.status_code==200: datas=response.text pattern=re.compile('.*?<br />(.*?)#.*?<br />',re.S)#re.S表示换行匹配,不受行数限制,python常用pattern来封装表达式规则,极大方便了调用 result=re.findall(pattern,datas) print(type(result)) for results in result: with open ("ip.txt","a",encoding="utf-8") as f: f.write("{}\n".format(results))
return None
page()
这里还要说一个重要的匹配方式,是python中独有的
import re #表示导入正则表达式
re.match表示是从第一字符开始匹配,如果规则没有从第一个字符开始表示,尽管你想要的信息就在HTML里面,你也匹配不出来
re.search表示只匹配符合规则的第一字符并返回结果,对匹配限定符规则是无效的,即不遵守限定匹配次数
re.findall表示匹配所有符合规则的字符,遵守限定次数规则,最常用的匹配re库函数
好了,正则表达式就介绍到这里,不过这只是皮毛而已,不过对我们目前应该是够用的,后面还有零断宽言等,大家有兴趣可以了解一下>
python爬虫之解析库正则表达式的更多相关文章
- python爬虫数据解析之正则表达式
爬虫的一般分为四步,第二个步骤就是对爬取的数据进行解析. python爬虫一般使用三种解析方式,一正则表达式,二xpath,三BeautifulSoup. 这篇博客主要记录下正则表达式的使用. 正则表 ...
- Python爬虫【解析库之beautifulsoup】
解析库的安装 pip3 install beautifulsoup4 初始化 BeautifulSoup(str,"解析库") from bs4 import BeautifulS ...
- python爬虫三大解析库之XPath解析库通俗易懂详讲
目录 使用XPath解析库 @(这里写自定义目录标题) 使用XPath解析库 1.简介 XPath(全称XML Path Languang),即XML路径语言,是一种在XML文档中查找信息的语言. ...
- Python爬虫【解析库之pyquery】
该库跟jQuery的使用方法基本一样 http://pyquery.readthedocs.io/ 官方文档 解析库的安装 pip3 install pyquery 初始化 1.字符串初始化 htm ...
- python爬虫之解析库Beautiful Soup
为何要用Beautiful Soup Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式, 是一个 ...
- python爬虫数据解析之BeautifulSoup
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. BeautfulSoup是python爬虫三 ...
- Mac os 下 python爬虫相关的库和软件的安装
由于最近正在放暑假,所以就自己开始学习python中有关爬虫的技术,因为发现其中需要安装许多库与软件所以就在这里记录一下以避免大家在安装时遇到一些不必要的坑. 一. 相关软件的安装: 1. h ...
- Python爬虫入门七之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
随机推荐
- 团队作业—预则立&&他山之石(改)
首先特别感谢刘乾学长腾出他宝贵的时间接受我的采访,为我们提出宝贵的建议,深表感谢. 1.他山之石,可以攻玉.借鉴前人的经验可以使我们减少很多走弯路的地方,这也是本次采访的目的,参考历届学长的经验,让我 ...
- HBase的常用Java API
1. 创建HBase表的对象 HBase表的对项名字叫HTable,创建它的方法有很多,常见的有如下: org.apache.hadoop.hbase.client.HTable hTable = n ...
- tomcat6 集群配置
1. 概要 web容器在做集群配置时,有3点需要注意: 1.1. 负载均衡配置: 1.2. session共享: 1.3. 若做的是单机集群(多个tomcat安装在同一台机器上),需要注意端口冲突问题 ...
- vue-cli项目打包优化(webpack3.0)
1.修改source-map配置:此配置能大大减少打包后文件体积. a.首先修改 /config/index.js 文件: // /config/index.js dev环境:devtool: 'ev ...
- python第十九课——random模块中的常用函数
1.random():返回一个[0,1)的随机浮点数(双精度浮点数) 2.uniform(a,b): 返回[a,b]之间的一个随机浮点数(双精度浮点数) [注意]a和b接受的数据大小随意 例如:3.r ...
- logstash.conf 根据不同地址创建索引
input { http { host => "0.0.0.0" port => 9700 type => "from_ys" }}input ...
- BZOJ2729:[HNOI2012]排队(组合数学)
Description 某中学有 n 名男同学,m 名女同学和两名老师要排队参加体检.他们排成一条直线,并且任意两名女同学不能相邻,两名老师也不能相邻,那么一共有多少种排法呢?(注意:任意两个人都是不 ...
- ZooKeeper学习之路 (十)Hadoop的HA集群的机架感知
一.背景 Hadoop 的设计目的:解决海量大文件的处理问题,主要指大数据的存储和计算问题,其中, HDFS 解决数据的存储问题:MapReduce 解决数据的计算问题 Hadoop 的设计考虑:设计 ...
- Error: Couldn't find preset "env" relative to directory "/Users/user/ethereumjs-vm"
运行npm run build时遇见这个问题,解决办法是安装: npm install --save-dev babel-preset-env 就解决了
- django自带的登录验证功能
django自带的验证机制 from django.shortcuts import render, redirect from django.contrib.auth import authenti ...