SqlServer 在查询结果中如何过滤掉重复数据
问题背景

- SELECT *
- FROM (
- SELECT ROW_NUMBER() OVER ( ORDER BY T.USERID asc )AS Row
- ,T.USERID
- ,T.CreateTime
- FROM UserInfo T
- LEFT JOIN DiseaseInfo i ON i.UserID=T.UserID
- ) TT WHERE TT.Row between 0 AND 20 ORDER BY UserID DESC
- SELECT DISTINCT ROW ,*
- FROM (
- SELECT ROW_NUMBER() OVER (PARTITION BY T.USERID ORDER BY T.USERID asc )AS Row
- ,T.USERID
- ,T.CreateTime
- FROM UserInfo T
- LEFT JOIN DiseaseInfo i ON i.UserID=T.UserID
- ) TT WHERE TT.Row between 0 AND 12 ORDER BY UserID DESC


- SELECT *
- FROM (
- SELECT ROW_NUMBER() OVER ( order by T.USERID asc )AS Row
- ,T.USERID
- ,LEFT(T.Patient_Tel1,5)+'' AS Tel
- ,T.CreateTime
- ,h.HName
- ,h.HID
- fromUserInfo T
- LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
- LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
- AND t.UserID>=17867 AND T.UserID<=17875
- --(T.Patient_Tel1 like '%13800000000%')
- ) TT WHERE
- TT.Row between 0and20

- SELECT DISTINCT row,*
- FROM (
- SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
- ,T.USERID
- ,LEFT(T.Patient_Tel1,5)+'' AS Tel
- ,T.CreateTime
- ,h.HName
- ,h.HID
- fromUserInfo T
- LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
- LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
- AND t.UserID>=17867 AND T.UserID<=17875
- --(T.Patient_Tel1 like '%13800000000%')
- ) TT WHERE
- --row=1 AND
- TT.Row between 0 and 20

- SELECT *
- FROM (
- --partition by T.USERID 以UserID对结果集进行分区
- SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
- ,T.USERID
- ,LEFT(T.Patient_Tel1,5)+'' AS Tel
- ,T.CreateTime
- ,h.HName
- ,h.HID
- fromUserInfo T
- LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
- LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
- AND t.UserID>=17867 AND T.UserID<=17875
- --(T.Patient_Tel1 like '%13800000000%')
- ) TT WHERE
- --因为之前已经以UserID对结果集进行分区,所以如果存在重复的字段则row的值会不相同
- --row=1 AND
- TT.Row between 0 and 20
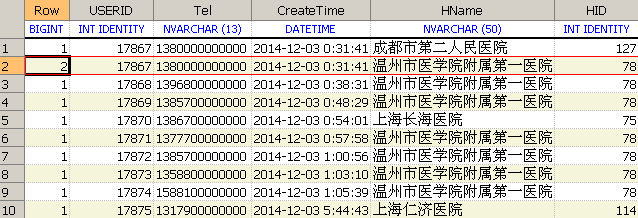

- -- 新增一层查询解决过滤掉重复数据后无法分页的问题
- SELECT * FROM (
- SELECT ROW_NUMBER() OVER (ORDER BY userid) AS RowNum,*
- FROM (
- --partition by T.USERID 以UserID对结果集进行分区
- SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
- ,T.USERID
- ,LEFT(T.Patient_Tel1,5)+'' AS Tel
- ,T.CreateTime
- ,h.HName
- ,h.HID
- fromUserInfo T
- LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1
- LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1
- AND t.UserID>=17867 AND T.UserID<=20875
- --(T.Patient_Tel1 like '%13800000000%')
- ) TT
- )AS T
- WHERE
- --过滤重复数据
- Row=1
- --对结果进行分页
- AND RowNum between 13 and 24

SqlServer 在查询结果中如何过滤掉重复数据的更多相关文章
- MySQL查询表中某个字段的重复数据
1. 查询SQL表中某个字段的重复数据 SELECT user_name,COUNT(*) AS count FROM db_user_info GROUP BY user_name HAVING c ...
- mysql去重, 把url重复且区为空的中去掉、统计重复数据、、结果集去重合并成一行
delete from 表名 where id not in (select d.id from (SELECT id FROM 表名 GROUP BY c1,c2,c3,c4)as d) #去重复, ...
- Mysql中查找并删除重复数据的方法
(一)单个字段 1.查找表中多余的重复记录,根据(question_title)字段来判断 代码如下 复制代码 select * from questions where question_title ...
- 查询Oracle中字段名带"."的数据
SDE中的TT_L线层会有SHAPE.LEN这样的字段,使用: SQL>select shape.len from tt_l; 或 SQL>select t.shape.len from ...
- SQL-游标-查询数据库中的所有表的数据个数
--sql语句-游标等使用 ) ) declare @i INT ) declare @cstucount INT --上方设置变量 --初始值 declare mCursor cursor --设置 ...
- 用java查询HBase中某表的一批数据
java代码如下: package db.query; import java.io.IOException; import org.apache.hadoop.conf.Configuration; ...
- 【SQL】查询数据库中某个字段有重复值出现的信息
select name,mobile from [GeneShop].[dbo].[xx_member] where mobile in ( SELECT mobile FROM [GeneShop] ...
- mysql查询sql中检索条件为大批量数据时处理
当userIdArr数组值为大批量时,应如此优化代码实现
- Java中List集合去除重复数据的方法
1. 循环list中的所有元素然后删除重复 public static List removeDuplicate(List list) { for ( int i = 0 ; i < list. ...
随机推荐
- hdu1527下沙小面的(二)
B - 下沙小面的(2) Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Submit ...
- 【BZOJ 3470】3470: Freda’s Walk 期望
3470: Freda’s Walk Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 42 Solved: 22 Description 雨后的Poet ...
- 直接插入排序(初级版)之C++实现
直接插入排序(初级版)之C++实现 一.源代码:InsertSortLow.cpp /*直接插入排序思想: 假设待排序的记录存放在数组R[1..n]中.初始时,R[1]自成1个有序区,无序区为R[2. ...
- [BZOJ4561][JLOI2016]圆的异或并(扫描线)
考虑任何一条垂直于x轴的直线,由于圆不交,所以这条直线上的圆弧构成形似括号序列的样子,且直线移动时圆之间的相对位置不变. 将每个圆拆成两边,左端加右端删.每次加圆时考虑它外面最内层的括号属于谁.用se ...
- Azure ServiceBus的消息中带有@strin3http//schemas.microsoft.com/2003/10/Serialization/�
今天碰到一个很讨厌的问题,使用nodejs 接收Azure service bus队列消息的时候,出现了:@strin3http//schemas.microsoft.com/2003/10/Seri ...
- 【ACM-ICPC 2018 徐州赛区网络预赛】E. End Fantasy VIX 血辣 (矩阵运算的推广)
Morgana is playing a game called End Fantasy VIX. In this game, characters have nn skills, every ski ...
- 【原】MySQL实用SQL积累
[文档简述] 本文档用来记录一些常用的SQL语句,以达到快速查询的目的. [常用SQL] 1.mysql数据库中获取某个表的所有字段名 select COLUMN_NAME from informat ...
- ActiveMQ Cluster (ActiveMQ 集群) 配置
构建高可用的ActiveMQ系统在生产环境中是非常重要的,对于这个apache的消息中间件实现高可用非常简单,只要在Apache ActiveMQ单点基本配置基础上做一次配置变更(如果在一台设备上部署 ...
- Reverse Engineering the NC ECU (revisited) -- SH7508
http://forum.miata.net/vb/showthread.php?t=536601 Hey all! About 5 years ago, there was a great thre ...
- ASP.NET Web API教程 分页查询
首先增加支持分页的API方法 public IEnumerable<UserInfo> GetUserInfos(int pageindex, int size) { ...