机器学习(2):Softmax回归原理及其实现
Softmax回归用于处理多分类问题,是Logistic回归的一种推广。这两种回归都是用回归的思想处理分类问题。这样做的一个优点就是输出的判断为概率值,便于直观理解和决策。下面我们介绍它的原理和实现。
1.原理
a.问题
考虑\(K\)类问题,假设已知训练样本集\(D\)的\(n\)个样本\(\{(x_{i},t_{i})| i=1,...,n\}\) ,其中,\(x_i \in R^d\) 为特征向量,\(t_{i} \) 为样本类别标签,和一般而分类问题不同,Softmax回归采用了标签向量来定义类别,其定义如下:
\(t_{i}=\begin{pmatrix}
0\\
\vdots \\
1\\
\vdots\\
0
\end{pmatrix}\begin{matrix}
0\\
\vdots\\
k\\
\vdots\\
K
\end{matrix}\) -------------------(1)
标签向量为0 − 1的\(K\)维向量,若属于\(k\)类,则向量的\(k\)分量为1,其他分量均为0
为计算每个样本的所属类别概率,首先定义回归函数:
\(p(C_{k}|x)=\frac{exp(w_{k}^{T}x)}{\sum_{k=1}^{K}exp(w_{k}^{T}x)}\) -------------------(2)
其中\(w_{k}\) 为第\(k\)类的回归参数。根据回归函数,样本\(x_{i}\)的概率:
\(p(x_{i}|w_{1} , ... , w_{K})=\prod_{k=1}^{K}p(C_{k}|x)^{t_{ik}}\)-------------------(3)
其中,\(t_{i} = (t _{i1} , ... , t _{ik} , ... , t _{iK})^{T}\)为\(x\)的标签向量。
我们的目标是:估计回归参数\(w_{1} , ... , w_{K}\)。用什么办法呢,极大似然估计法。
b.算法
i)构造目标函数
我们采用极大似然法估计回归参数\(w_{1} , ... , w_{K}\)。我们的目标是期望所有样本的获得概率最大化,因此构造如下似然函数:
\((P(D|w_{1} , ... , w_{K})=\frac{1}{n}\prod_{i=1}^{n}\prod_{k=1}^{K}p(C_{k}|x)^{t_{ik}}\)-------------------(4)
为了计算方便,对以上似然函数取负对数,将问题转化为最小化问题,从而最优化问题的目标函数为:
\(\underset{w_1,...,w_K}{min}E(w_1,...,w_K) \)-------------------(5)
其中
\(E(w_{1} , ... , w_{K})=\frac{1}{n}\sum_{i=1}^{n}\sum_{k=1}^{K}t_{ik}\textbf{ln}p(C_{k}|x)\)
ii)梯度下降法
求解算法许多,这里我们考虑采用梯度下降迭代法,主要解决梯度和步长的问题,第\(k\)个回归参数\(w_k\)的更新迭代公式如下:
\(w_{k}^{new}=w_{k}^{old}-\lambda\frac{\partial E}{\partial w_k}\) -------------------(6)
其中\(\lambda\)步长,即学习率,\(\frac{\partial E}{\partial w_k}\)为关于\(w_k\)的梯度,具体计算公式如下:
\(\frac{\partial E}{\partial w_k}=-\frac{1}{n}\left [ \sum_{i=1}^{n}\left ( t_{ik}-P(C_k|x_i) \right )x_i \right ]\) -------------------(7)
对梯度加入权重因此会获得更好的效果,因此(2)可改进为:
\(\frac{\partial E}{\partial w_k}=-\frac{1}{n}\left [ \sum_{i=1}^{n}\left ( t_{ik}-P(C_k|x_i) \right )x_i \right ] + \lambda w_k\) -------------------(8)
梯度技巧提示:求解单个分量的梯度,然后在整合成向量表示形式。
提示:梯度求解需要复合梯度求导,对数求导以及\(\frac{x}{x+a}\)的求导,例如:
链式求导法则:若\(h(x)=f(g(x))\),则\({h}'(x)={f}'(g(x)){g}'(x)\)
对数:\({lnx}'=\frac{1}{x}\)
分数:\({(\frac{x}{x+a})}'=\frac{a}{(x+a)^2}\)
2.实现
我们将根据公式(2)和(8),利用python实现Softmax回归。先看随着迭代,精度变化的趋势图,如下图所示:
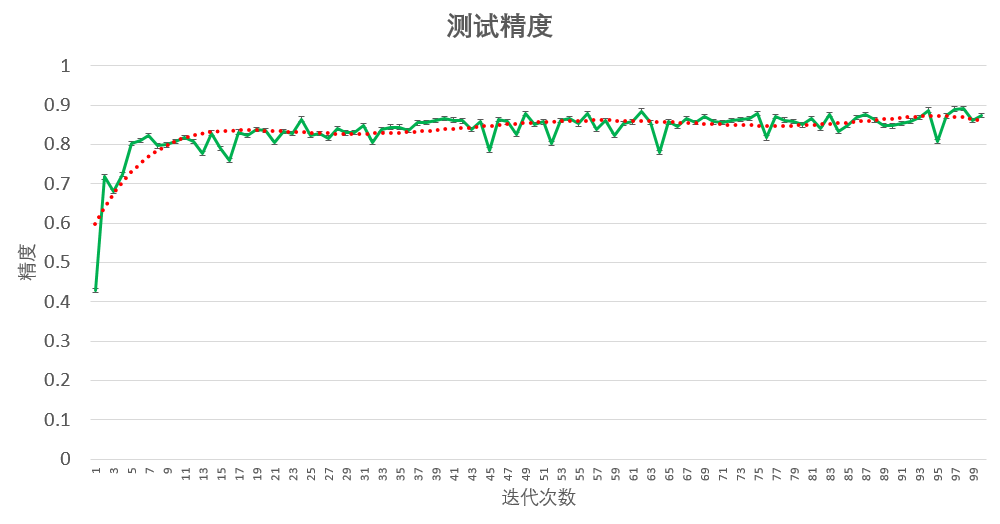
精度在迭代开始不久就收敛到很好的结果,但后期会出现较大的波动,可见其收敛并不理想,要达到90%的精度,就需要更久的迭代次数了,比如十万次迭代等。改进的手段是改进特征的描述。深度学习就可以很好的学习特征的算法。
最后贴上码农最爱的代码(修改自《python 实现 softmax分类器(MNIST数据集)》):
# encoding=utf8
'''
Created on 2017-7-1 @author: Administrator
''' import random
import time
import math
import pandas as pd
import numpy as np from sklearn.model_selection import train_test_split as ttsplit
from sklearn.metrics import accuracy_score as eva_score
from matplotlib import pyplot as plt class SoftMaxRegression(object):
'''
Softmax回归分类器
''' def __init__(self, learning_step=0.000001 ,max_iteration=100000,weight_lambda=0.01,iseva = True):
'''
构造函数
'''
self.learning_step = learning_step # 学习速率
self.max_iteration = max_iteration # 最大迭代次数
self.weight_lambda = weight_lambda # 衰退权重
self.iseva = iseva # 是否评估
def cal_e(self,x,l):
'''
计算指数:exp(wx)
''' theta_l = self.w[l]
product = np.dot(theta_l,x) return math.exp(product) def cal_probability(self,x,k):
'''
计算样本属于第k类的概率,对应公式(2)
''' molecule = self.cal_e(x,k)
denominator = sum([self.cal_e(x,i) for i in range(self.K)]) return molecule/denominator def cal_partial_derivative(self,x,y,k):
'''
计算第k类的参数梯度,对应公式(8)
''' first = int(y==k) # 计算示性函数
second = self.cal_probability(x,k) # 计算后面那个概率 return -x*(first-second) + self.weight_lambda*self.w[k] def predict_(self, x):
'''
预测测试样本
'''
result = np.dot(self.w,x)
row, column = result.shape # 找最大值所在的列
_positon = np.argmax(result)
m, n = divmod(_positon, column) return m def train(self, features, labels, test_features=None, test_labels=None):
'''
训练模型
'''
self.K = len(set(labels)) self.w = np.zeros((self.K,len(features[0])+1))
time = 0
self.score = []
while time < self.max_iteration:
#print('loop %d' % time)
time += 1
index = random.randint(0, len(labels) - 1) x = features[index]
y = labels[index] x = list(x)
x.append(1.0)
x = np.array(x)
#计算每一类的梯度
derivatives = [self.cal_partial_derivative(x,y,k) for k in range(self.K)] for k in range(self.K):
self.w[k] -= self.learning_step * derivatives[k]#负梯度为下降最快的方向 if self.iseva == True and time%1000 == 0:
self.acc_score(test_features, test_labels) return self.score
def predict(self,features):
'''
预测测试样本集
'''
labels = []
for feature in features:
x = list(feature)
x.append(1) x = np.matrix(x)
x = np.transpose(x) labels.append(self.predict_(x))
return labels def acc_score(self,test_features,test_labels):
'''
评估精度
'''
label_predict = self.predict(test_features)
predict_score = eva_score(test_labels, label_predict)
print predict_score self.score.append(predict_score) if __name__=='__main__': print("Import data")
raw_data = pd.read_csv('../data/train.csv', header=0)
data = raw_data.values
imgs = data[0::, 1::]
labels = data[::, 0]
train_features, test_features, train_labels, test_labels = ttsplit(
imgs, labels, test_size=0.33, random_state=23323)
print train_features.shape
print test_features.shape print("Training model")
learning_step = 0.000001 # 学习速率
max_iteration = 100000 # 最大迭代次数
weight_lambda = 0.01 # 衰退权重
iseva = True # 是否评估
smr = SoftMaxRegression(learning_step,max_iteration,weight_lambda,iseva)
scores = smr.train(train_features, train_labels,test_features,test_labels)
print scores
#print("Predicting model")
#test_predict = smr.predict(test_features) #print("Envaluate model")
#score = accuracy_score(test_labels, test_predict)
#print("The accruacy socre is " + str(score)) print("Plot accuracy")
idx = range(len(scores)) plt.plot(idx,scores,color="b",linewidth= 5) plt.xlabel("iter",fontsize="xx-large")
plt.ylabel("accuracy",fontsize="xx-large")
plt.title("Test accuracy")
plt.legend(["testing accuracy"],fontsize="xx-large",loc='upper left');
plt.show()
请参考推导及伪代码:softmax的简单推导和python实现
3.参考资料
[1].DeepLearning之路(二)SoftMax回归
机器学习(2):Softmax回归原理及其实现的更多相关文章
- 机器学习之softmax回归笔记
本次笔记绝大部分转自https://www.cnblogs.com/Luv-GEM/p/10674719.html softmax回归 Logistic回归是用来解决二类分类问题的,如果要解决的问题是 ...
- 【深度学习】softmax回归——原理、one-hot编码、结构和运算、交叉熵损失
1. softmax回归是分类问题 回归(Regression)是用于预测某个值为"多少"的问题,如房屋的价格.患者住院的天数等. 分类(Classification)不是问&qu ...
- Softmax 回归原理介绍
考虑一个多分类问题,即预测变量y可以取k个离散值中的任何一个.比如一个邮件分类系统将邮件分为私人邮件,工作邮件和垃圾邮件.由于y仍然是一个离散值,只是相对于二分类的逻辑回归多了一些类别.下面将根据多项 ...
- 机器学习 —— 基础整理(五)线性回归;二项Logistic回归;Softmax回归及其梯度推导;广义线性模型
本文简单整理了以下内容: (一)线性回归 (二)二分类:二项Logistic回归 (三)多分类:Softmax回归 (四)广义线性模型 闲话:二项Logistic回归是我去年入门机器学习时学的第一个模 ...
- 机器学习之线性回归---logistic回归---softmax回归
在本节中,我们介绍Softmax回归模型,该模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签 可以取两个以上的值. Softmax回归模型对于诸如MNIST手写数字分类等问题 ...
- 【机器学习】Softmax 和Logistic Regression回归Sigmod
二分类问题Sigmod 在 logistic 回归中,我们的训练集由 个已标记的样本构成: ,其中输入特征.(我们对符号的约定如下:特征向量 的维度为 ,其中 对应截距项 .) 由于 logis ...
- 机器学习(三)—线性回归、逻辑回归、Softmax回归 的区别
1.什么是回归? 是一种监督学习方式,用于预测输入变量和输出变量之间的关系,等价于函数拟合,选择一条函数曲线使其更好的拟合已知数据且更好的预测未知数据. 2.线性回归 于一个一般的线性模型而言,其 ...
- 100天搞定机器学习|Day8 逻辑回归的数学原理
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 机器学习——softmax回归
softmax回归 前面介绍了线性回归模型适用于输出为连续值的情景.在另一类情景中,模型输出可以是一个像图像类别这样的离散值.对于这样的离散值预测问题,我们可以使用诸如 softmax 回归在内的分类 ...
随机推荐
- leetcode之 两数之和
# -*- coding: utf-8 -*- # @Time : 2018/9/27 21:41 # @Author : cxa # @File : twonum.py # @Software: P ...
- C# 读取指定文件夹下所有文件
#region 读取文件 //返回指定目录中的文件的名称(绝对路径) string[] files = System.IO.Directory.GetFiles(@"D:\Test" ...
- 读书笔记 effective c++ Item 52 如果你实现了placement new,你也要实现placement delete
1. 调用普通版本的operator new抛出异常会发生什么? Placement new和placement delete不是C++动物园中最常遇到的猛兽,所以你不用担心你对它们不熟悉.当你像下面 ...
- [问题解决]同时显示多个Notification时PendingIntent的Intent被覆盖?
情况是这样的,使用NotificationManager触发多个Notification: private Notification genreNotification(Context context ...
- J2V8 For Android
J2V8是基于Google的JavaScript引擎V8的Java开源项目,实现Java和JavaScript的相互调用.并对Android平台提供支持,最新版本提供了aar格式的类库包方便Andro ...
- TCP包服务器接受程序
//功能:客户端发送TCP包,此程序接受到,将字母转换为大写,在发送到客户端#include <stdio.h>#include <sys/socket.h>#include ...
- php 的swoole 和websocket 连接wss
1. 下载证书 $serv = new swoole_server('0.0.0.0', 9501, SWOOLE_PROCESS, SWOOLE_SOCK_TCP | SWOOLE_SSL); $s ...
- 漂亮的SVG时钟
漂亮的SVG时钟 效果图: 代码如下,复制即可使用: <!DOCTYPE html> <html lang="en"> <head> <m ...
- Python模块Pygame安装
一.使用pip安装Python包 大多数较新的Python版本都自带pip,因此首先可检查系统是否已经安装了pip.在Python3中,pip有时被称为pip3. 1.在Linux和OS X系统中检查 ...
- 计算a+b
输入: 1 2 结果: 3 说明:只能输入数字,两数间只有一个空格 代码如下:(vc6编译) #include <stdio.h> #include <conio.h> voi ...