mysql高性能索引
独立索引:
独立索引是指索引列不能是表达式的一部分,也不能是函数的参数
例1:
SELECT actor_id FROM actor WHERE actor_id+1=5 --这种写法,就算在actor_id上建立了索引,也不起效
例2:
SELECT .... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10 --这也是一种错误的写法
多列索引(联合索引)&选择合适的索引列顺序:
多列索引(Multiple-Column Indexes)也称为复合索引(composite index),也即同时对多个列建立索引。
什么时候用多列索引?
- 当出现服务器对多个索引做相交操作时(通常有多个AND条件),通常意味着需要一个包含所有相关列的多列索引,而不是多个独立的单列索引。
- 当服务器需要对多个索引做联合操作时(通常有多个OR条件),通常需要耗费大量CPU和内存资源在算法的缓存、排序和合并操作上。特别是当其中有些索引的选择性不高,需要合并扫描返回大量数据的时候。
多列索引的生效规则:
比如(a,b,c),abc都是拍好序的,在任意一段a的下面b都是排好序的,任何一段b下面c都是拍好序的。多列索引的生效原则是从前往后依次使用生效,如果中间某个索引没有使用,那么断点前面的索引部分起作用,断点后面的索引没有起作用;
还需注意:(a,b,c)多列索引和 (a,c,b)是不一样的,看上面的图也看得出来关系顺序是不一样的;
分析几个实际例子来加强理解

(0)select * from mytable where a=3 and b=5 and c=4; --abc三个索引都在where条件里面用到了,而且都发挥了作用
(1)select * from mytable where c=4 and b=6 and a=3; --这条语句列出来只想说明 mysql没有那么笨,where里面的条件顺序在查询之前会被mysql自动优化,效果跟上一句一样
(2)select * from mytable where a=3 and c=7; --a用到索引,b没有用,所以c是没有用到索引效果的
(3)select * from mytable where a=3 and b>7 and c=3; --a用到了,b也用到了,c没有用到,这个地方b是范围值,也算断点,只不过自身用到了索引
(4)select * from mytable where b=3 and c=4; --因为a索引没有使用,所以这里 bc都没有用上索引效果
(5)select * from mytable where a>4 and b=7 and c=9; --a用到了 b没有使用,c没有使用
(6)select * from mytable where a=3 order by b; --a用到了索引,b在结果排序中也用到了索引的效果,前面说了,a下面任意一段的b是排好序的
(7)select * from mytable where a=3 order by c; --a用到了索引,但是这个地方c没有发挥排序效果,因为中间断点了,使用 explain 可以看到 filesort
(8)select * from mytable where b=3 order by a; --b没有用到索引,排序中a也没有发挥索引效果
对于如何选择索引的列顺序有一个经验法则:将选择性最高的列放到索引最前列。(参考①)
当不需要考虑排序和分组时,将选择性最高的列放到前面通常是很好的。这时候索引的作用只是用于优化WHERE条件的查找
前缀索引和索引的选择性:
前缀索引能有效减小索引文件的大小,提高索引的速度。但是前缀索引也有它的坏处:
1.不能再OORDER BY 或 GROUP BY 中使用前缀索引;
2.也不能把他们用作覆盖索引(Covering index)。
建立前缀索引的语法:
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
示例:
ALTER TABLE city ADD KEY(cityname(7));
什么叫做索引的选择性呢?①
所谓索引的选择性(Selectivity),是指不重复索引值(也叫作基数,Cardinality)与表记录数(#T)的比值
Selectivity = Cardinality / #T
显然选择性的取值范围为(0,1],选择性越高的索引值价值越大
SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles;
- +-------------+
- | Selectivity |
- +-------------+
- | 0.0379 |
- +-------------+
比如employees表只有一个索引<emp_no>,那么如果我们想按名字搜索一个人,就只能全表扫描了:
EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido';
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
这样全表扫描效率很低,所以我们考虑到把名字建立索引,有两种选择,建<first_name>或<first_name,last_name>,看下两个索引的选择性:
SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees;
+-------------+
| Selectivity |
+-------------+
| 0.0042 |
+-------------+
SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees;
+-------------+
| Selectivity |
+-------------+
| 0.9313 |
+-------------+
从结果看显然<first_name>选择性太低,<first_name,last_name>选择性好。但是first_name和last_name加起来长度为30,有没有兼顾长度和选择性的办法?可以考虑用first_name和last_name的前几个字符建立索引,例如<first_name, left(last_name, 3)>,看看其选择性:
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees;
+-------------+
| Selectivity |
+-------------+
| 0.7879 |
+-------------+
选择性还不错,但离0.9313还是有点距离,那么把last_name前缀加到4:
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees;
+-------------+
| Selectivity |
+-------------+
| 0.9007 |
+-------------+
这时选择性已经很理想了,而这个索引的长度只有18,比<first_name, last_name>短了接近一半,我们把这个前缀索引 建上:
ALTER TABLE employees
ADD INDEX `first_name_last_name4` (first_name, last_name(4));
此时再执行一遍按名字查询,比较分析一下与建索引前的结果:
SHOW PROFILES;
+----------+------------+---------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------------------------------------+
| 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' |
| 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' |
+----------+------------+---------------------------------------------------------------------------------+
性能的提升是显著的,查询速度提高了120多倍。
聚簇索引
覆盖索引
冗余索引和覆盖索引
未使用的索引
应该删除未被使用的索引。有两个工具可以帮助定位未使用的索引。
1.在Percona Server或者MariaDB中先打开userstates服务器变量(默认是关闭的),然后让服务器正常运行一段时间,再通过查询INFORMATION_SCHEMA.INDEX_STATISTICS就能查到每个索引的使用频率。
2.在Percona Toolkit中的pt-index-usage,该工具可以读取查询日志,并对日志中的每条查询进行EXPLAIN操作,然后打印出关于索引和查询的报告
索引和锁
InnoDB只有在访问行的时候才会对其枷锁,而索引能够减少InnoDB访问的行数,从而减少锁的数量
InnoDB在二级索引上使用共享(读)锁,但访问主键索引需要排他(写)锁。这消除了覆盖索引的可能性,并且使得SELECT FOR UPDATE比LOCK IN SHARE MODE 或非锁定查询要慢很多
InnoDB的主键选择与插入优化
在使用InnoDB存储引擎时,如果没有特别的需要,请永远使用一个与业务无关的自增字段作为主键。为什么呢?
因为InnoDB使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)。
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如下图所示:
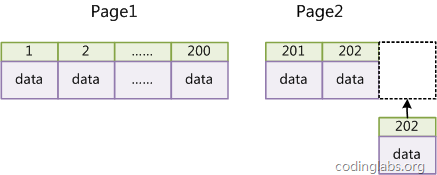
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置:
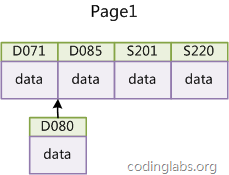
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
因此,只要可以,请尽量在InnoDB上采用自增字段做主键。
mysql高性能索引的更多相关文章
- mysql高性能索引策略
转载说明:http://www.nyankosama.com/2014/12/19/high-performance-index/ 1. 引言 随着互联网时代地到来,各种各样的基于互联网的应用和服务进 ...
- 高性能mysql——高性能索引策略
<高性能MySQL>读书笔记 一. 索引的优点 1. 索引可以让服务器快速定位到表的指定位置,大大减少了服务器需要扫描的数量: 2. 最常见的B-Tree索引按照顺序存储数据,可以用来做o ...
- php面试专题---16、MySQL创建高性能索引考点
php面试专题---16.MySQL创建高性能索引考点 一.总结 一句话总结: 注意:只写精品 1.索引的基础? 类似书籍的目录:索引类似于书籍的目录,要想找到一本书的某个特定主题,需要先查找书的目录 ...
- MySQL全面瓦解24:构建高性能索引(策略篇)
学习如果构建高性能的索引之前,我们先来了解下之前的知识,以下两篇是基础原理,了解之后,对面后续索引构建的原则和优化方法会有更清晰的理解: MySQL全面瓦解22:索引的介绍和原理分析 MySQL全面瓦 ...
- MySQL全面瓦解25:构建高性能索引(案例分析篇)
回顾一下上面几篇索引相关的文章: MySQL全面瓦解22:索引的介绍和原理分析 MySQL全面瓦解23:MySQL索引实现和使用 MySQL全面瓦解24:构建高性能索引(策略篇) 索引的十大原则 1. ...
- MySQL 创建高性能索引
索引是存储引擎用于快速找到记录的一种数据结构.除了加速查找,索引在其他方面也有一些有用的属性.索引对于良好的性能非常关键.尤其是当表中的数据量越来越大时,索引对性能的影响愈发重要.在数据量较小且负载较 ...
- MySQL创建高性能索引
参考<高性能MySQL>第3版 1 索引基础 1.1 索引作用 在MySQL中,查找数据时先在索引中找到对应的值,然后根据匹配的索引记录找到对应的数据行,假如要运行下面查询语句: 如果在u ...
- Mysql优化之创建高性能索引(一)
1.索引基础 索引对于良好的性能非常关键.尤其是当表中的数据量越来越大时,索引对性能的影响愈发重要.但是不恰当的索引随着数据量的增加,也会使整个数据库的性能下降. 举个例子: ; 如果在id上建立索引 ...
- 高性能MySQL之索引深入原理分析
一.背景 我们工作中经常打交道的就是索引,那么到底什么是索引呢?例如,当一个SQL查询比较慢的时候,你可能会说给“某个字段加个索引吧”之类的解决方案. 总的来说索引的出现其实就是为了提高数据查询的效率 ...
随机推荐
- 天梯赛 L2-022. (数组模拟链表) 重排链表
题目链接 题目描述 给定一个单链表 L1→L2→...→Ln-1→Ln,请编写程序将链表重新排列为 Ln→L1→Ln-1→L2→....例如:给定L为1→2→3→4→5→6,则输出应该为6→1→5→2 ...
- 天梯赛 L2-002. (模拟) 链表去重
题目链接 题目描述 给定一个带整数键值的单链表L,本题要求你编写程序,删除那些键值的绝对值有重复的结点.即对任意键值K,只有键值或其绝对值等于K的第一个结点可以被保留.同时,所有被删除的结点必须被保存 ...
- 2016.5.18——leetcode:Majority Element
Majority Element 本题收获: 1.初步了解hash,nth_element的用法 2.题目的常规思路 题目: Given an array of size n, find the ma ...
- Lucene7.1.0版本的索引创建与查询以及维护,包括新版本的一些新特性探索!
一 吐槽 lucene版本更新实在太快了,往往旧版本都还没学会,新的就出来,而且每个版本改动都特别大,尤其是4.7,6,6,7.1.......ε=(´ο`*)))唉,但不可否认,新版本确实要比旧版本 ...
- 【FCS NOI2018】福建省冬摸鱼笔记 day1
省冬的第一天. 带了本子,笔,一本<算法导论>就去了.惊讶于为什么同学不带本子记笔记. 他们说:“都学过了.”,果然这才是巨神吧. 第一天:数论,讲师:zzx 前几页的课件挺水,瞎记了点笔 ...
- ubuntu git 简单入门【转】
转自:http://blog.chinaunix.net/uid-20718384-id-3334859.html 1. 安装 sudo apt-get install git-core 2. 初始 ...
- 005_MAC下的VMware fushion快捷键(折中)
由于MAC和VMware Fushion虚拟机之间有一些快捷键的映射,所以Windows虚拟机就找了一个折中的方案.现总结MAC下的win常用快捷键==> <1>最小化窗口(Alt ...
- vue项目中遇到的一些问题
或访问:https://github.com/littleHiuman/experiences-about-vue 欢迎补充! vuex 状态 vue-cli 命令行 vue vue vue-rou ...
- Hadoop(二):MapReduce程序(Java)
Java版本程序开发过程主要包含三个步骤,一是map.reduce程序开发:第二是将程序编译成JAR包:第三使用Hadoop jar命令进行任务提交. 下面拿一个具体的例子进行说明,一个简单的词频统计 ...
- 你真的了解js伪数组吗?深入js伪数组
关于js伪数组 具有length属性: 按索引方式存储数据: 不具有数组的push().pop()等方法: 你可能知道怎么把伪数组转换为数组,但是你知道这里边的原理吗? 假如页面有一组li元素 < ...