学以致用:Python爬取廖大Python教程制作pdf

当我学了廖大的Python教程后,感觉总得做点什么,正好自己想随时查阅,于是就开始有了制作PDF这个想法。
想要把教程变成PDF有三步:
- 先生成空html,爬取每一篇教程放进一个新生成的div,这样就生成了包含所有教程的html文件(
BeautifulSoup) - 将html转换成pdf(
wkhtmltopdf) - 由于廖大是写教程的,反爬做的比较好,在爬取的过程中还需要代理ip(阿布云代理)
BeautifulSoup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
安装
pip3 install BeautifulSoup4
开始使用
将一段文档传入 BeautifulSoup 的构造方法,就能得到一个文档的对象, 可以传入一段字符串或一个文件句柄.
如下所示:
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html"))
soup = BeautifulSoup("<html>data</html>")
- 首先,文档被转换成Unicode,并且HTML的实例都被转换成Unicode编码.
- 然后,Beautiful Soup选择最合适的解析器来解析这段文档,如果手动指定解析器那么Beautiful Soup会选择指定的解析器来解析文档.
对象的种类
Beautiful Soup 将复杂 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为 4 种: Tag , NavigableString , BeautifulSoup , Comment .
Tag:通俗点讲就是HTML中的一个个标签,类似div,p。NavigableString:获取标签内部的文字,如,soup.p.string。BeautifulSoup:表示一个文档的全部内容。Comment:Comment对象是一个特殊类型的NavigableString对象,其输出的内容不包括注释符号.
Tag
Tag就是html中的一个标签,用BeautifulSoup就能解析出来Tag的具体内容,具体的格式为soup.name,其中name是html下的标签,具体实例如下:
print soup.title输出title标签下的内容,包括此标签,这个将会输出<title>The Dormouse's story</title>
print soup.head输出head标签下的内容<head><title>The Dormouse's story</title></head>
如果 Tag 对象要获取的标签有多个的话,它只会返回所以内容中第一个符合要求的标签。
Tag 属性
每个 Tag 有两个重要的属性 name 和 attrs:
name:对于Tag,它的name就是其本身,如soup.p.name就是pattrs是一个字典类型的,对应的是属性-值,如print soup.p.attrs,输出的就是{'class': ['title'], 'name': 'dromouse'},当然你也可以得到具体的值,如print soup.p.attrs['class'],输出的就是[title]是一个列表的类型,因为一个属性可能对应多个值,当然你也可以通过get方法得到属性的,如:print soup.p.get('class')。还可以直接使用print soup.p['class']
get
get方法用于得到标签下的属性值,注意这是一个重要的方法,在许多场合都能用到,比如你要得到<img src="#">标签下的图像url,那么就可以用soup.img.get('src'),具体解析如下:
# 得到第一个p标签下的src属性
print soup.p.get("class")
string
得到标签下的文本内容,只有在此标签下没有子标签,或者只有一个子标签的情况下才能返回其中的内容,否则返回的是None具体实例如下:
# 在上面的一段文本中p标签没有子标签,因此能够正确返回文本的内容
print soup.p.string
# 这里得到的就是None,因为这里的html中有很多的子标签
print soup.html.string
get_text()
可以获得一个标签中的所有文本内容,包括子孙节点的内容,这是最常用的方法。
搜索文档树
BeautifulSoup 主要用来遍历子节点及子节点的属性,通过Tag取属性的方式只能获得当前文档中的第一个 tag,例如,soup.p。如果想要得到所有的<p> 标签,或是通过名字得到比一个 tag 更多的内容的时候,就需要用到 find_all()
find_all(name, attrs, recursive, text, **kwargs )
find_all是用于搜索节点中所有符合过滤条件的节点。
name参数:是Tag的名字,如p,div,title
# 1. 节点名
print(soup.find_all('p'))
# 2. 正则表达式
print(soup.find_all(re.compile('^p')))
# 3. 列表
print(soup.find_all(['p', 'a']))
另外 attrs 参数可以也作为过滤条件来获取内容,而 limit 参数是限制返回的条数。
CSS 选择器
以 CSS 语法为匹配标准找到 Tag。同样也是使用到一个函数,该函数为select(),返回类型是 list。它的具体用法如下:
# 1. 通过 tag 标签查找
print(soup.select(head))
# 2. 通过 id 查找
print(soup.select('#link1'))
# 3. 通过 class 查找
print(soup.select('.sister'))
# 4. 通过属性查找
print(soup.select('p[name=dromouse]'))
# 5. 组合查找
print(soup.select("body p"))
wkhtmltopdf
- wkhtmltopdf主要用于HTML生成PDF。
- pdfkit是基于wkhtmltopdf的python封装,支持URL,本地文件,文本内容到PDF的转换,其最终还是调用wkhtmltopdf命令。
安装
先安装wkhtmltopdf,再安装pdfkit。
- https://wkhtmltopdf.org/downloads.html
- pdfkit
pip3 install pdfkit
转换url/file/string
import pdfkit
pdfkit.from_url('http://google.com', 'out.pdf')
pdfkit.from_file('index.html', 'out.pdf')
pdfkit.from_string('Hello!', 'out.pdf')
转换url或者文件名列表
pdfkit.from_url(['google.com', 'baidu.com'], 'out.pdf')
pdfkit.from_file(['file1.html', 'file2.html'], 'out.pdf')
转换打开文件
with open('file.html') as f:
pdfkit.from_file(f, 'out.pdf')
自定义设置
options = {
'page-size': 'Letter',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'custom-header' : [
('Accept-Encoding', 'gzip')
]
'cookie': [
('cookie-name1', 'cookie-value1'),
('cookie-name2', 'cookie-value2'),
],
'no-outline': None,
'outline-depth': 10,
}
pdfkit.from_url('http://google.com', 'out.pdf', options=options)
使用代理ip
爬取十几篇教程之后触发了这个错误:

看来廖大的反爬虫做的很好,于是只好使用代理ip了,尝试了免费的西刺免费代理后,最后选择了付费的 蘑菇代理 ,感觉响应速度和稳定性还OK。
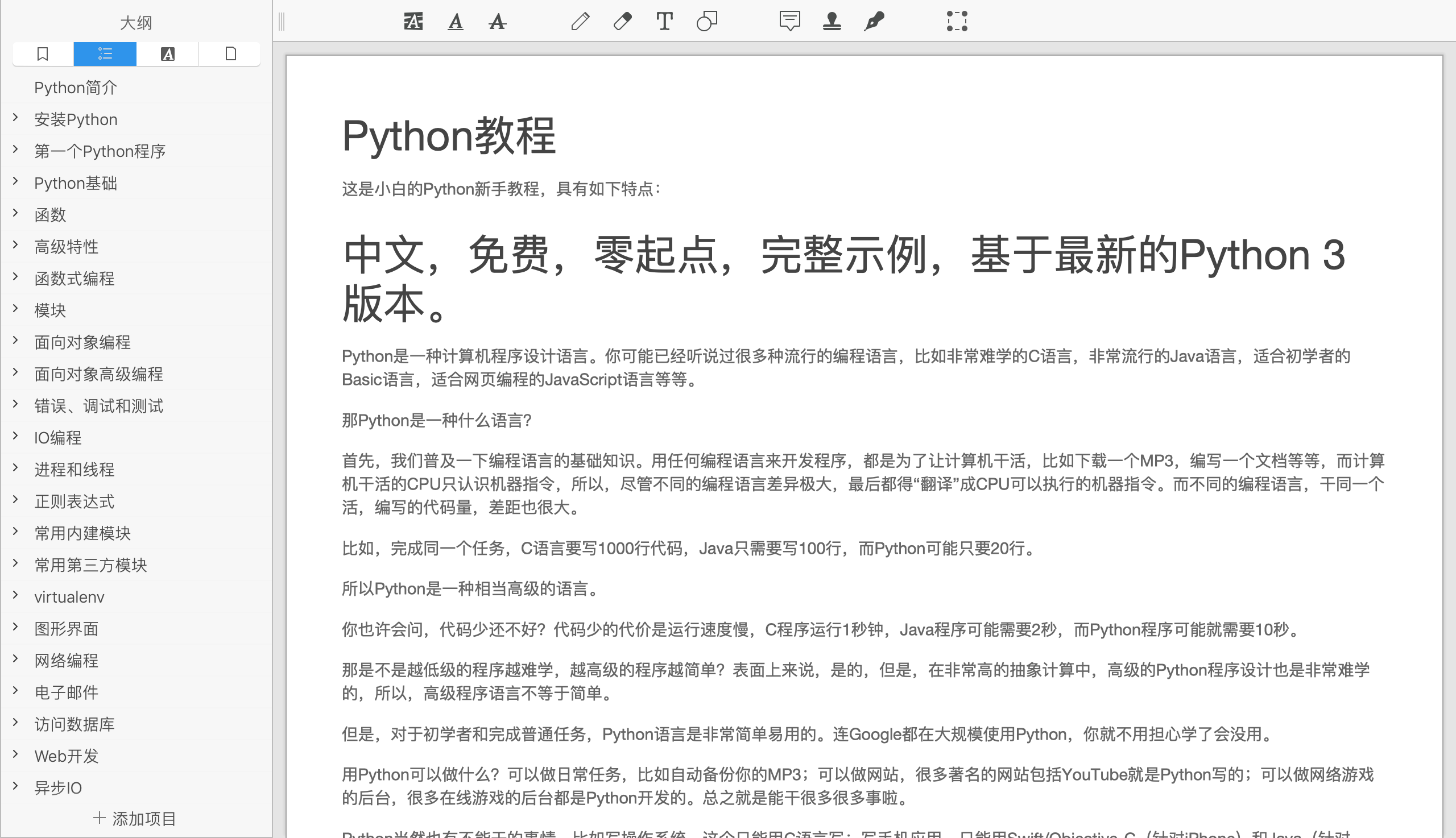
运行结果
运行过程截图:
生成的效果图:
代码如下:
import re
import time
import pdfkit
import requests
from bs4 import BeautifulSoup
# 使用 阿布云代理
def get_soup(target_url):
proxy_host = "http-dyn.abuyun.com"
proxy_port = "9020"
proxy_user = "**"
proxy_pass = "**"
proxy_meta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host": proxy_host,
"port": proxy_port,
"user": proxy_user,
"pass": proxy_pass,
}
proxies = {
"http": proxy_meta,
"https": proxy_meta,
}
headers = {'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
flag = True
while flag:
try:
resp = requests.get(target_url, proxies=proxies, headers=headers)
flag = False
except Exception as e:
print(e)
time.sleep(0.4)
soup = BeautifulSoup(resp.text, 'html.parser')
return soup
def get_toc(url):
soup = get_soup(url)
toc = soup.select("#x-wiki-index a")
print(toc[0]['href'])
return toc
# ⬇️教程html
def download_html(url, depth):
soup = get_soup(url)
# 处理目录
if int(depth) <= 1:
depth = '1'
elif int(depth) >= 2:
depth = '2'
title = soup.select("#x-content h4")[0]
new_a = soup.new_tag('a', href=url)
new_a.string = title.string
new_title = soup.new_tag('h' + depth)
new_title.append(new_a)
print(new_title)
# 加载图片
images = soup.find_all('img')
for x in images:
x['src'] = 'https://static.liaoxuefeng.com/' + x['data-src']
# 将bilibili iframe 视频更换为链接地址
iframes = soup.find_all('iframe', src=re.compile("bilibili"))
for x in iframes:
x['src'] = "http:" + x['src']
a_tag = soup.new_tag("a", href=x['src'])
a_tag.string = "vide play:" + x['src']
x.replace_with(a_tag)
div_content = soup.find('div', class_='x-wiki-content')
return new_title, div_content
def convert_pdf(template):
html_file = "python-tutorial-pdf.html"
with open(html_file, mode="w") as code:
code.write(str(template))
pdfkit.from_file(html_file, 'python-tutorial-pdf.pdf')
if __name__ == '__main__':
# html 模板
template = BeautifulSoup(
'<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <link rel="stylesheet" href="https://cdn.liaoxuefeng.com/cdn/static/themes/default/css/all.css?v=bc43d83"> <script src="https://cdn.liaoxuefeng.com/cdn/static/themes/default/js/all.js?v=bc43d83"></script> </head> <body> </body> </html>',
'html.parser')
# 教程目录
toc = get_toc('https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000')
for i, x in enumerate(toc):
url = 'https://www.liaoxuefeng.com' + x['href']
# ⬇️教程html
content = download_html(url, x.parent['depth'])
# 往template添加新的教程
new_div = template.new_tag('div', id=i)
template.body.insert(3 + i, new_div)
new_div.insert(3, content[0])
new_div.insert(3, content[1])
time.sleep(0.4)
convert_pdf(template)
参考文档:
学以致用:Python爬取廖大Python教程制作pdf的更多相关文章
- 适合初学者的Python爬取链家网教程
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: TinaLY PS:如有需要Python学习资料的小伙伴可以加点击下 ...
- 使用python爬取天气预报,[python入门案例]
# 天气网余姚地区爬虫案例 import requests from lxml import etree class WeatherSpider: def __init__(self): self.u ...
- Python 爬取各大代理IP网站(元类封装)
import requests from pyquery import PyQuery as pq base_headers = { 'User-Agent': 'Mozilla/5.0 (Windo ...
- Python爬取51job实例
用Python爬取51job里面python相关职业.工作地址和薪资. 51job上的信息 程序代码 from bs4 import BeautifulSoup from urllib.request ...
- python制作爬虫爬取京东商品评论教程
作者:蓝鲸 类型:转载 本文是继前2篇Python爬虫系列文章的后续篇,给大家介绍的是如何使用Python爬取京东商品评论信息的方法,并根据数据绘制成各种统计图表,非常的细致,有需要的小伙伴可以参考下 ...
- Python爬取微信好友
前言 今天看到一篇好玩的文章,可以实现微信的内容爬取和聊天机器人的制作,所以尝试着实现一遍,本文记录了实现过程和一些探索的内容 来源: 痴海 链接: https://mp.weixin.qq.com/ ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python爬取《龙岭迷窟》的数据,看看质量剧情还原度到底怎么样
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:简单 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
随机推荐
- VirtualBox安装及Linux基本操作(操作系统实验一)
VirtualBox安装教程博客链接(转载)https://blog.csdn.net/u012732259/article/details/70172704 实验名称:Linux的基本操作 实验目的 ...
- 安装mysql后遇到的一些问题
我们安装好了mysql(cnetos7上是安装mariadb)后,出现如下图所示的问题,我们可以用netstat -lntup查看以下服务器的端口,mysql的端口一般默认为 3306,查看服务是否启 ...
- ACM数论之旅14---抽屉原理,鸽巢原理,球盒原理(叫法不一又有什么关系呢╮(╯▽╰)╭)
这章没有什么算法可言,单纯的你懂了原理后会不会运用(反正我基本没怎么用过 ̄ 3 ̄) 有366人,那么至少有两人同一天出生(好孩子就不要在意闰年啦( ̄▽ ̄")) 有13人,那么至少有两人同一月 ...
- Java容器深入浅出之Map、HashMap、Hashtable及其它实现类
在Java中,Set的底层事实上是基于Map实现的,Map内部封装了一个Entry内部接口,由实现类来封装key-value对,当value值均为null时,key的集合就形成了Set.因此,Map集 ...
- behavior
http://www.css88.com/book/css/properties/only-ie/behavior.htm 语法: behavior:<url> | url(#objID) ...
- Java的checked exception与unchecked exception
在Java中exception分为checked exception和unchecked异常,两者有什么区别呢? 从表象来看, checked异常就是需要在代码中try ... catch ...的异 ...
- 【比赛】NOIP2017 总结
一.比赛过程 Day1: 拿到题目后,立即把所有题目都看了一遍,发现没有很虚的期望DP和概率DP,感到很庆幸.然后发现今年的题目顺序好像有点不对,T1是数论,T2像是模拟,这难道是把两天的基础题放到一 ...
- BZOJ5389 比例查询 【离线】
题目链接 BZOJ5389 题解 太\(sb\)了,这种题都想不出来 发现复杂度允许\(n\sqrt{n}\),我们可以对于每个位置\(\sqrt{n}\)枚举约数,然后维护比例的最晚出现的位置,维护 ...
- BZOJ.4034 [HAOI2015]树上操作 ( 点权树链剖分 线段树 )
BZOJ.4034 [HAOI2015]树上操作 ( 点权树链剖分 线段树 ) 题意分析 有一棵点数为 N 的树,以点 1 为根,且树点有边权.然后有 M 个 操作,分为三种: 操作 1 :把某个节点 ...
- golang简单实现二叉树的数据添加和遍历
代码实现 package tree import "fmt" type Node struct { elem interface{} left, right *Node } typ ...