Android Room使用详解
使用Room将数据保存在本地数据库
Room提供了SQLite之上的一层抽象, 既允许流畅地访问数据库, 也充分利用了SQLite.
处理大量结构化数据的应用, 能从在本地持久化数据中极大受益. 最常见的用例是缓存有关联的数据碎片. 以这种方式, 在设备不能访问网络的时候, 用户依然能够浏览离线内容. 任何用户发起的改变, 都应该在设备重新在线之后同步到服务器.
因为Room为你充分消除了这些顾虑, 使用Room而非SQLite是高度推荐的.
添加依赖
Room的依赖添加方式如下:
dependencies {
def room_version = "1.1.1"
implementation "android.arch.persistence.room:runtime:$room_version"
annotationProcessor "android.arch.persistence.room:compiler:$room_version"
// optional - RxJava support for Room
implementation "android.arch.persistence.room:rxjava2:$room_version"
// optional - Guava support for Room, including Optional and ListenableFuture
implementation "android.arch.persistence.room:guava:$room_version"
// Test helpers
testImplementation "android.arch.persistence.room:testing:$room_version"
}
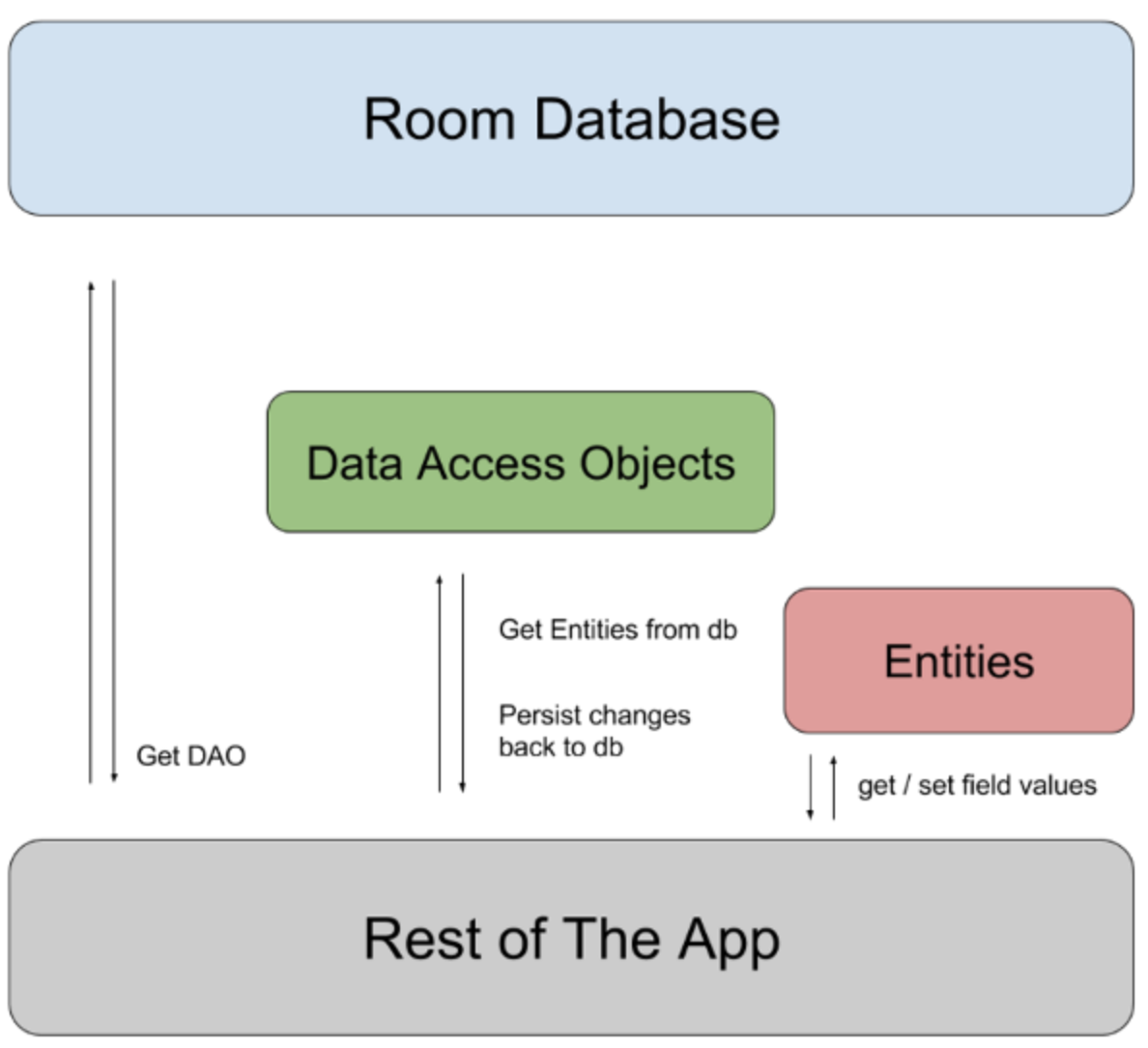
Room有3个主要构件:
- Database: 包含了数据库持有者, 并对于连接应用上持久化的相关数据, 作为一个主要的访问点, 来服务. 注解了@Database的类应该满足以下条件:
- 继承了RoomDatabase的抽象类;
- 包含实体列表, 而这些实体与该注解之下数据库关联;
- 包含一个抽象方法, 无参且返回一个注解了@Dao的类;
在运行时, 你可以通过调用Room.databaseBuilder()或者Room.inMemoryDatabaseBuilder()方法请求Database实例.
- Entity: 表示数据库内的表.
- DAO: 包含用于访问数据库的方法.
这些构件, 以及它们与app余下内容的关系, 如下图:
下面的代码片断, 包含了一个数据库配置示例, 有一个实体和一个DAO:
User.java
@Entity
public class User {
@PrimaryKey
private int uid; @ColumnInfo(name = "first_name")
private String firstName; @ColumnInfo(name = "last_name")
private String lastName; // Getters and setters are ignored for brevity,
// but they're required for Room to work.
}
UserDao.java
@Dao
public interface UserDao {
@Query("SELECT * FROM user")
List<User> getAll(); @Query("SELECT * FROM user WHERE uid IN (:userIds)")
List<User> loadAllByIds(int[] userIds); @Query("SELECT * FROM user WHERE first_name LIKE :first AND "
+ "last_name LIKE :last LIMIT 1")
User findByName(String first, String last); @Insert
void insertAll(User... users); @Delete
void delete(User user);
}
AppDatabase.java
@Database(entities = {User.class}, version = 1)
public abstract class AppDatabase extends RoomDatabase {
public abstract UserDao userDao();
}
在创建了以上文件之后, 你能够使用以下代码来创建一个database实例:
AppDatabase db = Room.databaseBuilder(getApplicationContext(), AppDatabase.class, "database-name").build();
备注: 在实例化AppDatabase对象的时候, 你应该使用单例模式, 因为每一个RoomDatabase实例都是非常耗时的, 而且你也应该很少访问多个实例.
使用Room实体定义数据
在使用Room持久化库的时候, 把相关联的域的集合定义为实体. 对于每一个实体, 数据库都会创建一个表, 该表来持有数据项.
默认情况下, Room会为实体中定义的每个域创建一个列. 如果实体中有你不想持久化的域, 可以使用@Ignore来注解掉. 在Database类中, 你必须通过entities数据来引用实体类.
下面的代码片断展示了如何定义一个实体:
@Entity
public class User {
@PrimaryKey
public int id; public String firstName;
public String lastName; @Ignore
Bitmap picture;
}
在持久化一个域, Room必须能够访问它. 你可以将域设置为public, 或者你可以提供该的getter/setter. 如果你使用了getter/setter的方式, 一定要记住: 在Room里面, 它们是基于JavaBeans转换的.
备注: 实体要么有个空的构造器(如果相应的DAO类能够访问每一个持久化域的话), 要有构造器里面的参数, 数据类型和名字跟实体里面定义的域相匹配. Room也能够使用包含全部或者部分域的构造器, 例如, 一个构造器只能获取所有域中的几个.
使用主键
每一个实体必须定义至少1个主键. 即使只有一个域, 你依然需要使用@PrimaryKey来注解它. 而且, 如果你想Room分配自动ID给实体的话, 你需要设置@PrimaryKey的autoGenerate属性. 如果实体有一个复合主键的话, 你需要使用注解@Entity的primaryKeys属性, 示例代码如下:
@Entity(primaryKeys = {"firstName", "lastName"})
public class User {
public String firstName;
public String lastName;
@Ignore
Bitmap picture;
}
默认情况下, Room使用实体类的名字作为数据库表的名字. 如果你想要表拥有一个不同的名字, 设置@Entity注解的tableName属性, 示例代码如下:
@Entity(tableName = "users") public class User { ... }
注意: SQLite中表名是大小写敏感的.
跟tableName属性相似的是, Room使用域的名字作为数据库中列的名字. 如果你想要列有一个不同的名字的话, 给域添加@ColumnInfo注解, 示例代码如下:
@Entity(tableName = "users")
public class User {
@PrimaryKey
public int id; @ColumnInfo(name = "first_name")
public String firstName; @ColumnInfo(name = "last_name")
public String lastName; @Ignore
Bitmap picture;
}
注解索引和唯一性
依赖于你如何访问数据, 你也许想要在数据库中建立某些域的索引, 以加速查询速度. 要给实体添加索引, 需要在@Entity中引入indices属性, 并列出你想要在索引或者复合索引中引入的列的名字. 下列代码说明了注解的处理过程:
@Entity(indices = {@Index("name"),
@Index(value = {"last_name", "address"})})
public class User {
@PrimaryKey
public int id;
public String firstName;
public String address;
@ColumnInfo(name = "last_name")
public String lastName;
@Ignore
Bitmap picture;
}
有些时候, 数据库中的某些域或几组域必须是唯一的. 你可以通过将注解@Index的unique属性设置为true, 强制完成唯一的属性.
下面的代码示例防止表有两行数据在列firstName和lastName拥有相同值:
@Entity(indices = {@Index(value = {"first_name", "last_name"},
unique = true)})
public class User {
@PrimaryKey
public int id;
@ColumnInfo(name = "first_name")
public String firstName;
@ColumnInfo(name = "last_name")
public String lastName;
@Ignore
Bitmap picture;
}
定义对象之间的关系
因为SQLite是关系型数据库, 你可以指定对象之间的关系. 尽管大多数对象关系的映射允许实体对象引用彼此, 而Room却显式地禁止了这个特性. 要想了解这个讨论背后的原因, 请查看这篇文章. //todo
尽管你不能使用直接的对象关系, Room仍然允许你在实体之间定义外键约束.
比如, 如果有一个实体类Book, 你可以使用@ForeignKey注解定义它和实体User的关系, 示例代码如下:
@Entity(foreignKeys = @ForeignKey(entity = User.class,
parentColumns = "id",
childColumns = "user_id"))
public class Book {
@PrimaryKey
public int bookId; public String title; @ColumnInfo(name = "user_id")
public int userId;
}
外键非常强大, 因为它允许你指定做什么操作, 在引用实体更新的时候. 比如, 你可以告诉SQLite为用户删除所有的书, 在相应的User实例被删除时, 而该User被Book通过在@ForeignKey注解里面声明onDelete = CASCADE而关联.
备注: SQLite将@Insert(onConflict = REPLACE)作为REMOVE和REPLACE的集合来操作, 而非单独的UPDATE操作. 这个取代冲突值的方法能够影响你的外键约束.
创建嵌套对象
有些时候, 在数据库逻辑中, 你想将一个实体或者POJO表示为一个紧密联系的整体, 即使这个对象包含几个域. 在这些情况下, 你能够使用@Embedded注解来表示一个对象, 而你想将这个对象分解为表内的子域. 然后你可以查询这些嵌套域, 就像你查询其它的独立列一样.
举个例子, User类包含一个Address类的域, 这个域表示的是street, city, state, postCode这几个域的复合. 为了在表中单独存储复合的列, 在User类里面, 引入一个注解了@Embedded的Address域, 就像如下代码片断展示的一样:
public class Address {
public String street;
public String state;
public String city;
@ColumnInfo(name = "post_code")
public int postCode;
}
@Entity
public class User {
@PrimaryKey
public int id;
public String firstName;
@Embedded
public Address address;
}
这个表表示User对象包含如下几列: id, firstName, street, state, city和post_code.
备注: 嵌套的域同样可以包含其它的嵌套域.
如果实体拥有多个相同类型的嵌套域, 你可以通过设置prefix属性保留每一列唯一. 然后Room给嵌套对象的每一个列名的起始处添加prefix设置的给定值.
通过Room DAO访问数据
要通过Room持久化库访问应用的数据, 你需要使用数据访问对象(data access objects, 即DAOs). Dao对象集形成了Room的主要构成, 因为每一个DAO对象都引入了提供了抽象访问数据库的方法.
使用DAO对象而非查询构造器或者直接查询来访问数据库, 你可以分开不同的数据库架构组成. 此外, DAO允许你轻易地模拟数据库访问.
DAO要么是接口, 要么是抽象类. 如果DAO是抽象类的话, 它可以随意地拥有一个将RoomDatabase作为唯一参数的构造器. Room在运行时创建DAO的实现.
备注: Room并不支持在主线程访问数据库, 除非在Builder调用allowMainThreadQueries()方法, 因为它很可能将UI锁上较长一段时间. 但是, 异步查询--返回LiveData/Flowable实例的查询--则从此规则中免除, 因为它们在需要的时候会在后台线程异步地运行查询.
方便地定义方法
使用DAO类, 可以非常方便地表示查询.
插入
当你创建了一个DAO方法并注解了@Insert的时候, Room生成了一个实现, 在单个事务中将所有的参数插入数据库.
下面的代码片断展示了几个示例查询:
@Dao
public interface MyDao {
@Insert(onConflict = OnConflictStrategy.REPLACE)
public void insertUsers(User... users); @Insert
public void insertBothUsers(User user1, User user2); @Insert
public void insertUsersAndFriends(User user, List<User> friends);
}
如果@Insert方法只接收了一个参数, 它可以返回一个long, 表示新插入项的rowId; 如果参数是数组或者集合, 同时地, 它应该返回long[]或者List<Long>.
更新
按照惯例, 在数据库中, Update方法修改了作为参数传递的实体集合. 它使用查询来匹配每一个实体的主键.
下面的代码片断展示了如何定义这个方法:
@Dao
public interface MyDao {
@Update
public void updateUsers(User... users);
}
尽管通常情况下并不需要, 但是依然可以将这个方法返回int值, 表示在数据库中被修改的行数.
删除
按照惯例, Delete方法从数据库中删除了作为参数传递的实体集合. 它使用主键找到要删除的实体.
下面的代码片断展示了如何定义这个方法:
@Dao
public interface MyDao {
@Delete
public void deleteUsers(User... users);
}
尽管通常情况下并不需要, 但是依然可以将这个方法返回int值, 表示从数据库中删除的行数.
查询
@Query是在DAO类中使用的主要的注解. 它允许你在数据库中执行读写操作. 每一个@Query方法都在编译时被证实, 因为, 如果查询有问题出现的话, 会出现编译错误而非运行失败.
Room也证实查询的返回值, 以确定返回对象的域的名字是否跟查询响应中对应列的名字匹配, Room使用如下两种方式提醒你:
- 如果只有一些域匹配, 它会给予警告;
- 如果没有域匹配, 它会给予错误;
简单查询
@Dao
public interface MyDao {
@Query("SELECT * FROM user")
public User[] loadAllUsers();
}
这是一个非常简单的查询, 加载了所有User. 在编译时, Room知晓这是在查询user表中所有列.
如果查询语句包含语法错误, 或者user表在数据库中并不存在, Room会在编译时展示恰当的错误信息.
查询语句中传参
大多数时候, 你需要向查询语句中传参, 以执行过滤操作, 比如, 只展示大于某个年龄的user.
要完成这个任务, 在Room注解中使用方法参数, 如下所示:
@Dao
public interface MyDao {
@Query("SELECT * FROM user WHERE age > :minAge")
public User[] loadAllUsersOlderThan(int minAge);
}
当这个查询在编译时处理的时候, Room匹配到 :minAge, 并将它跟方法参数minAge绑定. Room使用参数名来执行匹配操作. 如果不匹配的话, app编译时会发生错误.
你也可以在查询中传递多个参数, 或者将参数引用多次, 如下所示:
@Dao
public interface MyDao {
@Query("SELECT * FROM user WHERE age BETWEEN :minAge AND :maxAge")
public User[] loadAllUsersBetweenAges(int minAge, int maxAge); @Query("SELECT * FROM user WHERE first_name LIKE :search "
+ "OR last_name LIKE :search")
public List<User> findUserWithName(String search);
}
返回列的子集
大多数情况下, 你只需要实体中的几个域. 比如, UI中只需要展示用户的姓和名, 而非用户的每一个细节. 通过只查询UI中展示的列, 将节省宝贵的资源, 查询也更快.
Room允许从查询中返回基于Java的对象, 只要结果列集合能够映射成返回对象. 比如, 你创建了一个POJO来获取用户的名和姓:
public class NameTuple {
@ColumnInfo(name="first_name")
public String firstName;
@ColumnInfo(name="last_name")
public String lastName;
}
现在, 你可以在查询方法中使用这个POJO了:
@Dao
public interface MyDao {
@Query("SELECT first_name, last_name FROM user")
public List<NameTuple> loadFullName();
}
Room明白: 查询返回了列first_name和last_name, 这些值能够映射到NameTuple为的域中.
由此, Room能够产生适当的代码. 如果查询返回了太多列, 或者返回了NameTuple类中并不存在的列, Room将展示警告信息.
备注: POJO也可以使用@Embedded注解.
传递参数集
一些查询可能要求你传入可变数目的参数, 直到运行时才知道精确的参数数量.
比如, 你可能想要搜索地区子集下的所有用户. Room明白参数表示集合的时机, 并在运行时自动地基于提供了参数数目展开它.
@Dao
public interface MyDao {
@Query("SELECT first_name, last_name FROM user WHERE region IN (:regions)")
public List<NameTuple> loadUsersFromRegions(List<String> regions);
}
可观察查询
在执行查询的时候, 经常想要在数据发生改变的时候自动更新UI. 要达到这个目的, 需要在查询方法描述中返回LiveData类型的值. 在数据库更新的时候, Room生成所有必要的代码以更新LiveData.
@Dao
public interface MyDao {
@Query("SELECT first_name, last_name FROM user WHERE region IN (:regions)")
public LiveData<List<User>> loadUsersFromRegionsSync(List<String> regions);
}
备注: 在1.0版本的时候, Room使用查询中访问的表的列表来决定是否更新LiveData实例.
RxJava响应式查询
Room也可以从定义的查询中返回RxJava2中的Publisher和Flowable.
要使用这个功能, 在build.gradle文件中添加依赖: android.arch.persistence.room:rxjava2. 之后, 你可以返回在RxJava2中定义的数据类型, 如下所示:
@Dao
public interface MyDao {
@Query("SELECT * from user where id = :id LIMIT 1")
public Flowable<User> loadUserById(int id);
}
游标直接访问
如果你的应用逻辑要求直接访问返回的行, 你可以从查询中返回Cursor对象, 如下所示:
@Dao
public interface MyDao {
@Query("SELECT * FROM user WHERE age > :minAge LIMIT 5")
public Cursor loadRawUsersOlderThan(int minAge);
}
注意: 十分不推荐使用Cursor API. 因为它并不保证行是否存在以及行包含什么值.
除非你有需要Cursor的代码并且并不轻易的修改它的时候, 你才可以使用这个功能.
查询多表
有些查询可能要求访问多个表以计算结果. Room允许你写任何查询, 所以你也可以联接表. 此外, 如果响应是可观测数据类型, 诸如Flowable/LiveData, Room观察并证实查询中引用的所有表.
下面的代码片段展示了如何执行表联接, 以合并包含借书用户的表和包含在借书数据的表的信息:
@Dao
public interface MyDao {
@Query("SELECT * FROM book "
+ "INNER JOIN loan ON loan.book_id = book.id "
+ "INNER JOIN user ON user.id = loan.user_id "
+ "WHERE user.name LIKE :userName")
public List<Book> findBooksBorrowedByNameSync(String userName);
}
你也可以从这些查询中返回POJO. 比如, 你可以写查询加载用户和它的宠物名:
@Dao
public interface MyDao {
@Query("SELECT user.name AS userName, pet.name AS petName "
+ "FROM user, pet "
+ "WHERE user.id = pet.user_id")
public LiveData<List<UserPet>> loadUserAndPetNames(); // You can also define this class in a separate file, as long as you add the
// "public" access modifier.
static class UserPet {
public String userName;
public String petName;
}
}
迁移Room数据库
当应用中添加或者改变特性的时候, 需要修改实体类以反映出这些改变. 当用户升级到最新版本的时候, 你不想用户失去所有数据, 尤其是如果你还不能从远程服务器恢复这些数据的时候.
Room持久化库允许写Migration类来保留用户数据. 每一个Migration类指定了startVersion和endVersion. 在运行时, Room运行每一个Migration类的migrate()方法, 使用正确的顺序迁移数据库到最新版本.
注意: 如果你不提供必要的迁移, Room会重建数据库, 这意味着你会失去原有数据库中的所有数据.
Room.databaseBuilder(getApplicationContext(), MyDb.class, "database-name")
.addMigrations(MIGRATION_1_2, MIGRATION_2_3).build(); static final Migration MIGRATION_1_2 = new Migration(1, 2) {
@Override
public void migrate(SupportSQLiteDatabase database) {
database.execSQL("CREATE TABLE `Fruit` (`id` INTEGER, "
+ "`name` TEXT, PRIMARY KEY(`id`))");
}
}; static final Migration MIGRATION_2_3 = new Migration(2, 3) {
@Override
public void migrate(SupportSQLiteDatabase database) {
database.execSQL("ALTER TABLE Book "
+ " ADD COLUMN pub_year INTEGER");
}
};
注意: 要保证迁移逻辑按照预期进行, 需要使用全查询而非引用表示查询的常量.
在迁移完成之后, Room会证实这个计划, 以确保迁移正确在发生了. 如果Room发现了问题, 它会抛出包含不匹配信息的异常.
迁移测试
写Migration并不是没有价值的, 不能恰当的写Migration会在应用中引起崩溃. 在保持应用的稳定性, 你应该事先测试Migration. Room提供了一个Maven测试工具. 但是, 如果要使这个工具工作, 你需要导出数据库schema.
导出schema
在编译的时候, Room会导出数据库schem信息, 形成一个Json文件. 要导出schema, 需要在build.gradle文件中设置room.schemaLocation注解处理器属性, 如下所示:
build.gradle:
android {
...
defaultConfig {
...
javaCompileOptions {
annotationProcessorOptions {
arguments = ["room.schemaLocation":
"$projectDir/schemas".toString()]
}
}
}
}
你应该保存导出的Json文件--这些文件表示了数据库schema的历史--在你的版本控制体系中, 因为它允许Room创建老版本数据库用于测试.
要测试这些Migration, 需要在测试需要的依赖中添加 anroid.arch.persistence.room:testing , 并在资产文件夹下添加schema地址, 如下所示:
build.gradle:
android {
...
sourceSets {
androidTest.assets.srcDirs += files("$projectDir/schemas".toString())
}
}
测试包提供了MigrationTestHelper类, 它能够读取这些schema文件. 它也实现了JUnit4 TestRule接口, 所有它能够管理已创建的数据库.
示例Migration测试如下:
@RunWith(AndroidJUnit4.class)
public class MigrationTest {
private static final String TEST_DB = "migration-test"; @Rule
public MigrationTestHelper helper; public MigrationTest() {
helper = new MigrationTestHelper(InstrumentationRegistry.getInstrumentation(),
MigrationDb.class.getCanonicalName(),
new FrameworkSQLiteOpenHelperFactory());
} @Test
public void migrate1To2() throws IOException {
SupportSQLiteDatabase db = helper.createDatabase(TEST_DB, 1); // db has schema version 1. insert some data using SQL queries.
// You cannot use DAO classes because they expect the latest schema.
db.execSQL(...); // Prepare for the next version.
db.close(); // Re-open the database with version 2 and provide
// MIGRATION_1_2 as the migration process.
db = helper.runMigrationsAndValidate(TEST_DB, 2, true, MIGRATION_1_2); // MigrationTestHelper automatically verifies the schema changes,
// but you need to validate that the data was migrated properly.
}
}
测试数据库
在使用Room持久化库创建数据库的时候, 证实应用数据库和用户数据的稳定性非常重要.
有两种方式测试你的数据库:
- 在真机上;
- 在虚拟机上(不推荐);
备注: 在运行应用的测试的时候, Room允许你创建模拟DAO类的实例. 使用这种方式的话, 如果不是在测试数据库本身的话, 你不必创建完成的数据库. 这个功能是可能的, 因为DAO并不泄露任何数据库细节.
真机测试
测试数据库实现的推荐途径是在真机上运行JUnit测试. 因为这些测试并不创建Activity, 它们应该比UI测试执行地更快.
在设置测试的时候, 你应该创建内存版本数据库, 以确保测试更加地密封. 如下所示:
@RunWith(AndroidJUnit4.class)
public class SimpleEntityReadWriteTest {
private UserDao mUserDao;
private TestDatabase mDb; @Before
public void createDb() {
Context context = InstrumentationRegistry.getTargetContext();
mDb = Room.inMemoryDatabaseBuilder(context, TestDatabase.class).build();
mUserDao = mDb.getUserDao();
} @After
public void closeDb() throws IOException {
mDb.close();
} @Test
public void writeUserAndReadInList() throws Exception {
User user = TestUtil.createUser(3);
user.setName("george");
mUserDao.insert(user);
List<User> byName = mUserDao.findUsersByName("george");
assertThat(byName.get(0), equalTo(user));
}
}
虚拟机测试
Room使用了SQLite支持库, 后者提供了在Android Framework类里面匹配的接口. 这个支持允许你传递自定义的支持库实现来测试数据库查询.
备注: 尽管这个设置允许测试运行地很快, 但它并不是值得推荐的, 因为运行在自己以及用户真机上面的SQLite版本, 可能并不匹配你的虚拟机上面的SQLite版本.
使用Room引用复杂数据
Room提供了功能支持基数数据类型和包装类型之间的转变, 但是并不允许实体间的对象引用.
使用类型转换器
有时候, 应用需要使用自定义数据类型, 该数据类型的值将保存在数据库列中. 要添加这种自定义类型的支持, 你需要提供TypeConverter, 用来将自定义类型跟Room能够持久化的已知类型相互转换.
比如, 如果我们想要持久化Date类型, 我们需要写下面的TypeConverter来在数据库中保存等价的Unix时间戳:
public class Converters {
@TypeConverter
public static Date fromTimestamp(Long value) {
return value == null ? null : new Date(value);
}
@TypeConverter
public static Long dateToTimestamp(Date date) {
return date == null ? null : date.getTime();
}
}
上述示例定义了2个方法, 一个把Date转变成Long, 一个把Long转变成Date. 因为Room已经知道如何持久化Long对象, 它将使用这个转换器持久化Date类型的值.
接下来, 添加@TypeConverters注解到AppDatabbase类上, 之后Room就能够在AppDatabase中定义的每一个实体和DAO上使用这个转换器.
AppDatabase.java
@Database(entities = {User.class}, version = 1)
@TypeConverters({Converters.class})
public abstract class AppDatabase extends RoomDatabase {
public abstract UserDao userDao();
}
使用这些转换器, 你之后就能够在其它的查询中使用自定义的类型, 就像你使用基本数据类型一样, 如下所示:
User.java
@Entity
public class User {
...
private Date birthday;
}
UserDao.java
@Dao
public interface UserDao {
...
@Query("SELECT * FROM user WHERE birthday BETWEEN :from AND :to")
List findUsersBornBetweenDates(Date from, Date to);
}
你也可以限制@TypeConverters的使用范围, 包括单个实体, DAO和DAO方法.
理解为什么Room不允许对象引用
要点: Room不允许实体类间的对象引用. 相反, 你必须显式地请求应用需要的数据.
从数据库到对应对象模型的映射关系是通用最佳实践, 在服务器端也运行良好. 即使是在程序加载它们正在访问的域的时候, 服务器依然执行良好.
然而在客户端, 这种类型的懒加载并不可行, 因为它通常发生在UI线程, 而在UI线程止查询硬盘信息产生了显著的性能问题. UI线程只有16ms计算和绘制Activity更新的布局, 所以, 即使查询花费了仅仅5ms, 看起来依然是应用绘制超时, 引起显著的视觉差错. 如果有另外的事件并行运行, 或者, 设备正在运行其它的硬盘密集型任务, 查询要完成就要花费更多的时间. 然而, 如果不使用懒加载, 应用获取超过需要的数据, 也会引起内存消耗问题.
对象关系型映射通常将这个决定留给开发者, 让他们做出应用用例最佳的选择. 开发者通常决定在应用和UI之间共享模型. 然后, 这个解决方案并不权衡地很好, 因为UI随着时间改变, 共享模型会产生对于开发者而言难以参与和debug的问题.
比如, UI加载Book对象列表, 同时每一本书有个Author对象. 最初你可能设计查询使用懒加载, 之后Book对象使用getAuthor()方法返回作者. getAuthor()方法的首次调用查询了数据库. 之后一段时间, 你发现同样需要展示作者姓名. 你轻易地添加如下这样的方法调用:
authorNameTextView.setText(book.getAuthor().getName());
然后, 这个貌似无辜的改变引起Author表在主线程被查询.
如果你提前查询作者信息, 而在你不再需要这个数据之后, 将很难改变加载的方式. 比如, UI不再需要展示Author信息, 而应用依然高效地加载不同展示的数据, 浪费了宝贵的内存空间. 应用的效率将会降级, 如果Author类引用了其它的表, 如Books.
要使用Room同时引用多个实体, 需要创建包含每个实体的POJO类, 之后写联接了相应表的查询语句. 这个结构良好的模型, 结合了Room鲁棒的查询证实能力, 允许应用在加载资源时消耗更少的资源, 提升了应用的性能和用户体验.
Android Room使用详解的更多相关文章
- android:ToolBar详解
android:ToolBar详解(手把手教程) 泡在网上的日子 发表于 2014-11-18 12:49 第 124857 次阅读 ToolBar 42 来源 http://blog.mosil.b ...
- Android之canvas详解
首先说一下canvas类: Class Overview The Canvas class holds the "draw" calls. To draw something, y ...
- 【转】Android Canvas绘图详解(图文)
转自:http://www.jcodecraeer.com/a/anzhuokaifa/androidkaifa/2012/1212/703.html Android Canvas绘图详解(图文) 泡 ...
- Android 核心分析 之八Android 启动过程详解
Android 启动过程详解 Android从Linux系统启动有4个步骤: (1) init进程启动 (2) Native服务启动 (3) System Server,Android服务启动 (4) ...
- Android GLSurfaceView用法详解(二)
输入如何处理 若是开发一个交互型的应用(如游戏),通常需要子类化 GLSurfaceView,由此可以获取输入事件.下面有个例子: java代码: package eoe.ClearTes ...
- Android编译过程详解(一)
Android编译过程详解(一) 注:本文转载自Android编译过程详解(一):http://www.cnblogs.com/mr-raptor/archive/2012/06/07/2540359 ...
- android屏幕适配详解
android屏幕适配详解 官方地址:http://developer.android.com/guide/practices/screens_support.html 一.关于布局适配建议 1.不要 ...
- Android.mk文件详解(转)
源:Android.mk文件详解 从对Makefile一无所知开始,折腾了一个多星期,终于对Android.mk有了一个全面些的了解.了解了标准的Makefile后,发现Android.mk其实是把真 ...
- Android Studio 插件开发详解四:填坑
转载请标明出处:http://blog.csdn.net/zhaoyanjun6/article/details/78265540 本文出自[赵彦军的博客] 在前面我介绍了插件开发的基本流程 [And ...
- Android Studio 插件开发详解三:翻译插件实战
转载请标明出处:http://blog.csdn.net/zhaoyanjun6/article/details/78113868 本文出自[赵彦军的博客] 一:概述 如果不了解插件开发基础的同学可以 ...
随机推荐
- Linux命令的那些事(三)
回顾linux命令那些事,前面大致总结了常用的Linux命令 回顾Linux命令那些事(一) clear/mkdir/rmdir/ls/rm/pwd/cd/touch/tree/man/--help ...
- OpenSSH技术详解
一.什么是Openssh OpenSSH 是 SSH (Secure SHell) 协议的免费开源实现.SSH协议族可以用来进行远程控制, 或在计算机之间传送文件.而实现此功能的传统方式,如teln ...
- Spring Boot之拦截器与过滤器(完整版)
作者:liuxiaopeng 链接:http://www.cnblogs.com/paddix 作者:蓝精灵lx原文:https://blog.csdn.net/liuxiao723846/artic ...
- [C++]模板类和模板函数
参考: C++ 中模板使用详解 C++模板详解 概念 为了避免因重载函数定义不全面而带来的调用错误,引入了模板机制 定义 模板是C++支持参数化多态的工具,使用模板可以使用户为类或者函数声明一种一般模 ...
- 拒绝滥用golang defer机制
原文链接 : http://www.bugclosed.com/post/17 defer机制 go语言中的defer提供了在函数返回前执行操作的机制,在需要资源回收的场景非常方便易用(比如文件关闭, ...
- 笨办法学Python - 习题6-7: Strings and Text & More Printing
目录 1.习题 6: 字符串(string) 和文本 2.加分习题: 3.我的答案 4.习题总结 5.习题 7: 更多打印 6.习题总结 1.习题 6: 字符串(string) 和文本 学习目标:了解 ...
- NuGet 让程序集版本变得混乱
之前引用的 System.Net.Http.Formatting ,是依赖于 System.Net.Http 2.0的. 更新引用后它是依赖于 System.Net.Http 4.0 的.而且一 ...
- Currency Exchange 货币兑换 Bellman-Ford SPFA 判正权回路
Description Several currency exchange points are working in our city. Let us suppose that each point ...
- LeetCode 566. Reshape the Matrix (C++)
题目: In MATLAB, there is a very useful function called 'reshape', which can reshape a matrix into a n ...
- 20145214 《网络对抗技术》 MSF基础应用
20145214 <网络对抗技术> MSF基础应用 1.实验后回答问题--用自己的话解释什么是exploit,payload,encode 如果把MSF比作一把枪的话,payload应该是 ...