Azkaban(三)Azkaban的使用
界面介绍
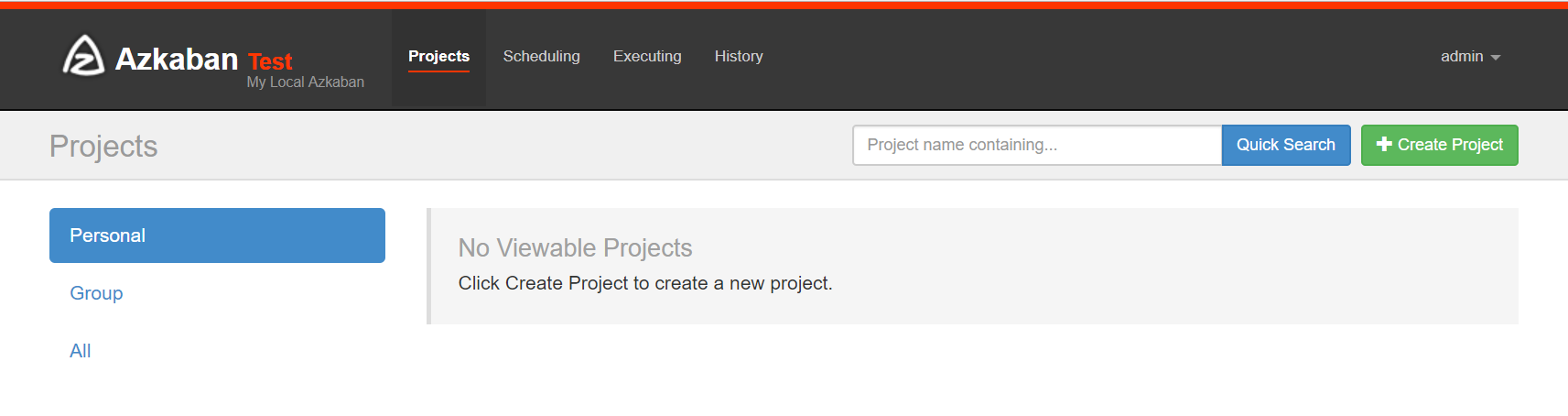
首页有四个菜单
- projects:最重要的部分,创建一个工程,所有flows将在工程中运行。
- scheduling:显示定时任务
- executing:显示当前运行的任务
- history:显示历史运行任务
介绍projects部分
概念介绍
创建工程:创建之前我们先了解下之间的关系,一个工程包含一个或多个flows,一个flow包含多个job。job是你想在azkaban中运行的一个进程,可以是简单的linux命令,可是java程序,也可以是复杂的shell脚本,当然,如果你安装相关插件,也可以运行插件。一个job可以依赖于另一个job,这种多个job和它们的依赖组成的图表叫做flow。
1、Command 类型单一 job 示例
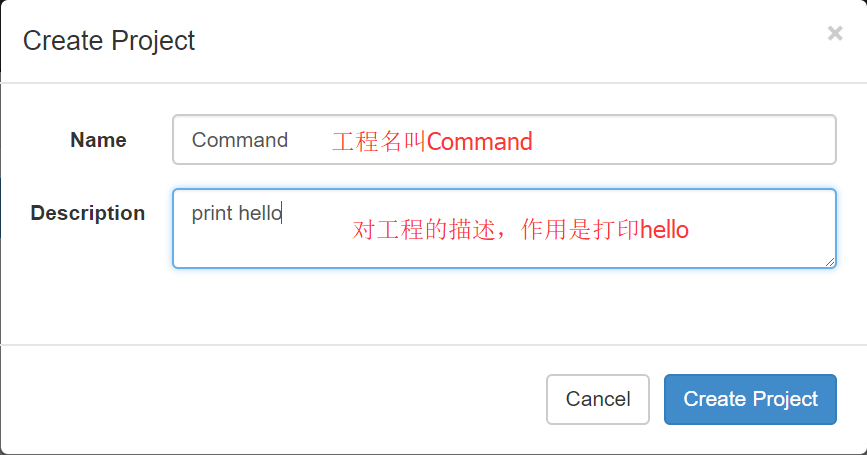
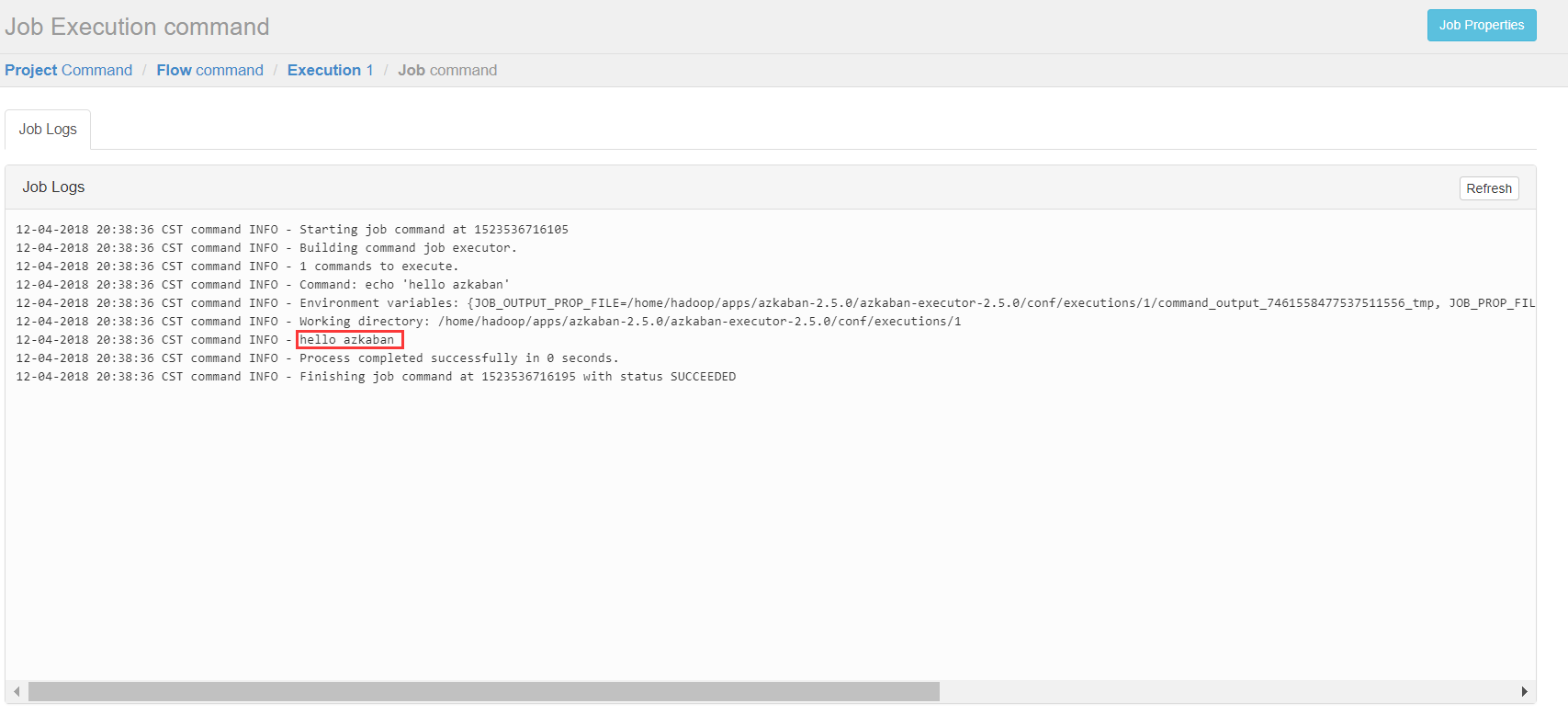
(1)首先创建一个工程,填写名称和描述
(2)点击创建之后
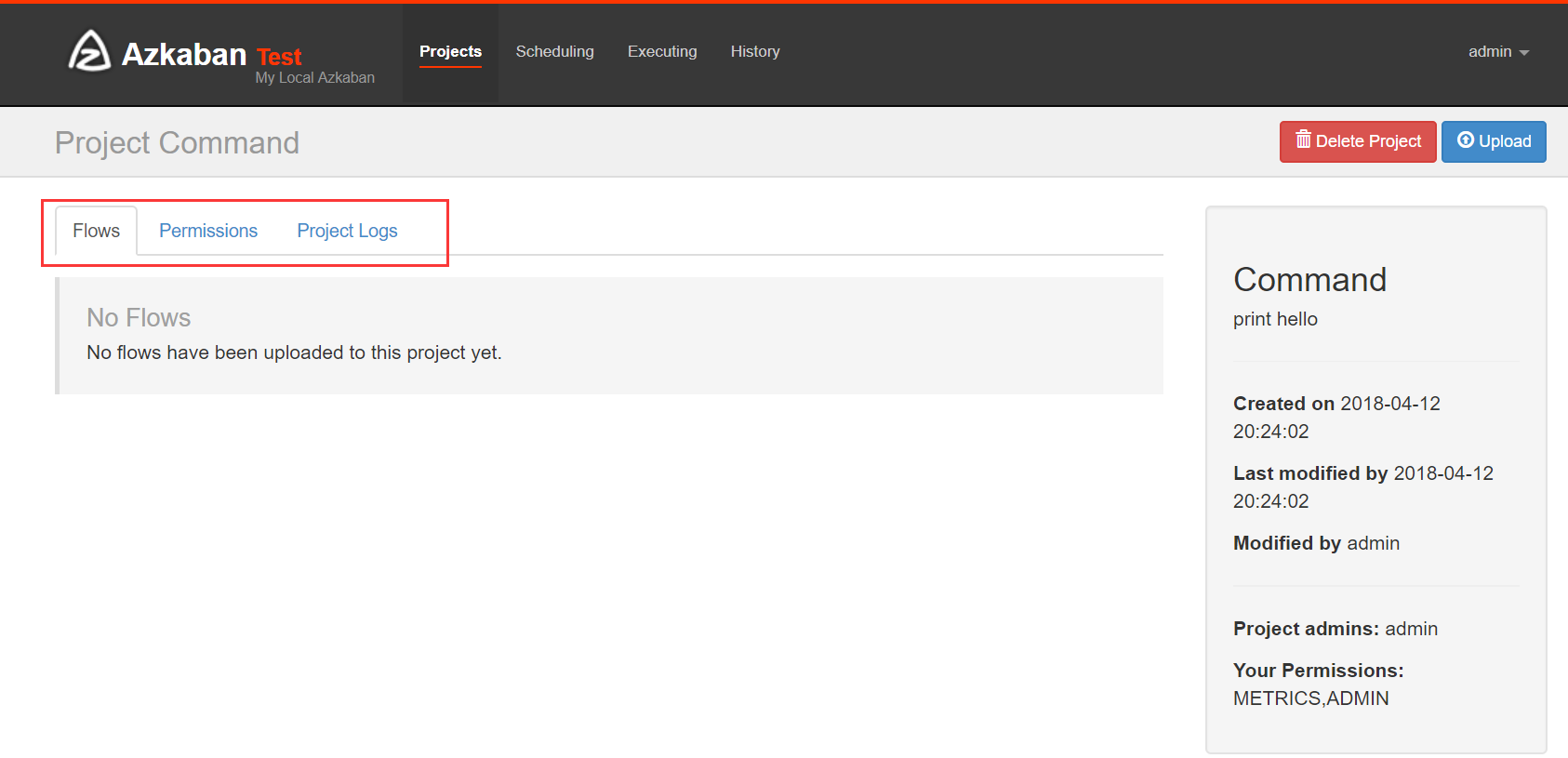
Flows:工作流程,有多个job组成
Permissions:权限管理
Project Logs:工程日志
(3)job的创建
创建job很简单,只要创建一个以.job结尾的文本文件就行了,例如我们创建一个工作,用来打印hello,名字叫做command.job
#command.job
type=command
command=echo 'hello'
一个工程不可能只有一个job,我们现在创建多个依赖job,这也是采用azkaban的首要目的。
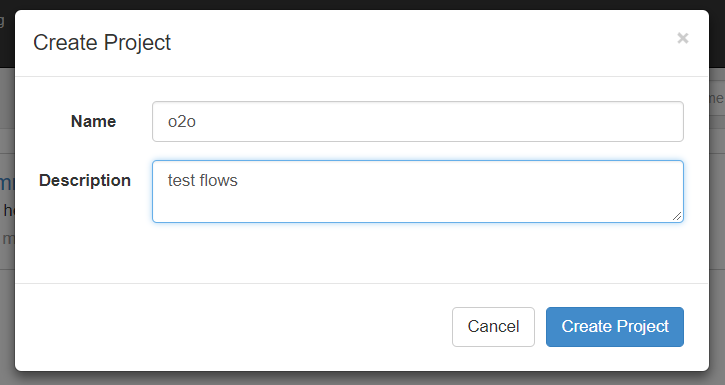
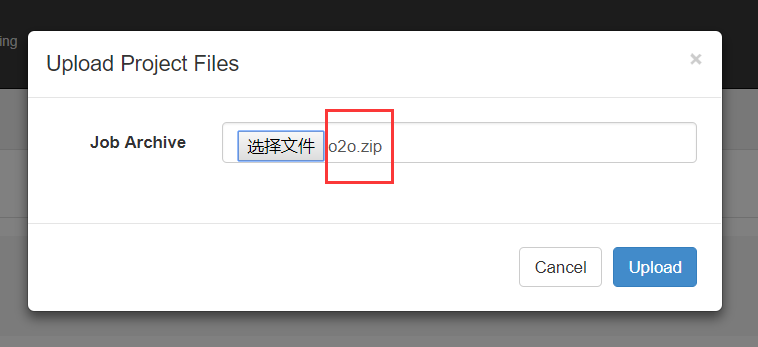
(4)将 job 资源文件打包
注意:只能是zip格式
(5)通过 azkaban web 管理平台创建 project 并上传压缩包
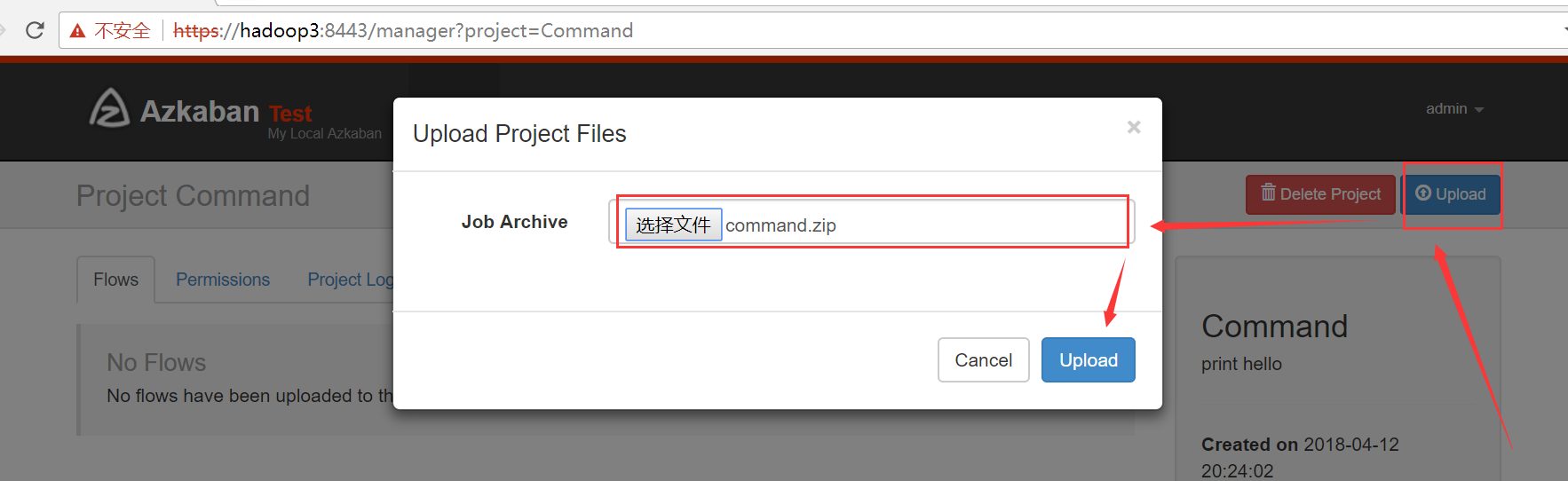
2、Command 类型多 job 工作流 flow
(1)创建项目
我们说过多个jobs和它们的依赖组成flow。怎么创建依赖,只要指定dependencies参数就行了。比如导入hive前,需要进行数据清洗,数据清洗前需要上传,上传之前需要从ftp获取日志。
定义5个job:
1、o2o_2_hive.job:将清洗完的数据入hive库
2、o2o_clean_data.job:调用mr清洗hdfs数据
3、o2o_up_2_hdfs.job:将文件上传至hdfs
4、o2o_get_file_ftp1.job:从ftp1获取日志
5、o2o_get_file_fip2.job:从ftp2获取日志
依赖关系:
3依赖4和5,2依赖3,1依赖2,4和5没有依赖关系。
o2o_2_hive.job
type=command
# 执行sh脚本,建议这样做,后期只需维护脚本就行了,azkaban定义工作流程
command=sh /job/o2o_2_hive.sh
dependencies=o2o_clean_data
o2o_clean_data.job
type=command
# 执行sh脚本,建议这样做,后期只需维护脚本就行了,azkaban定义工作流程
command=sh /job/o2o_clean_data.sh
dependencies=o2o_up_2_hdfs
o2o_up_2_hdfs.job
type=command
#需要配置好hadoop命令,建议编写到shell中,可以后期维护
command=hadoop fs -put /data/*
#多个依赖用逗号隔开
dependencies=o2o_get_file_ftp1,o2o_get_file_ftp2
o2o_get_file_ftp1.job
type=command
command=wget "ftp://file1" -O /data/file1
o2o_get_file_ftp2.job
type=command
command=wget "ftp:file2" -O /data/file2
可以运行unix命令,也可以运行python脚本(强烈推荐)。将上述job打成zip包。
ps:为了测试流程,我将上述command都改为echo +相应命令





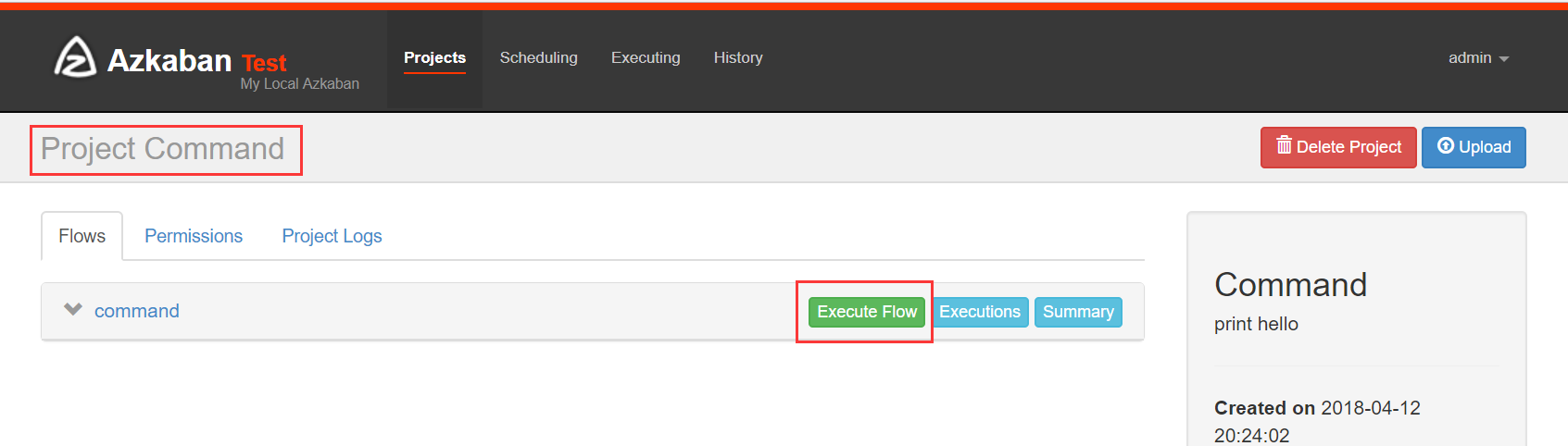
(2)上传
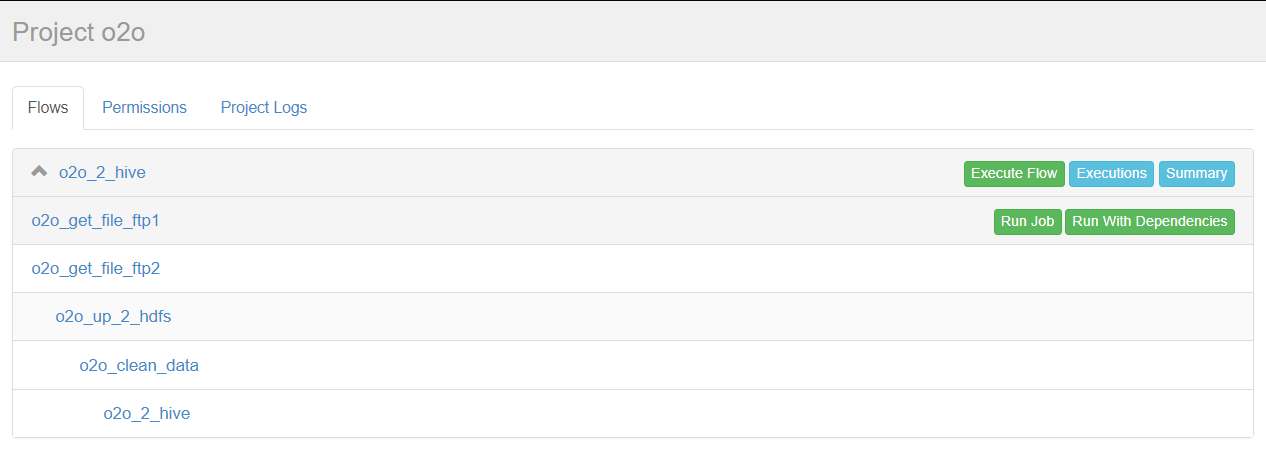
点击o2o_2_hive进入流程,azkaban流程名称以最后一个没有依赖的job定义的。

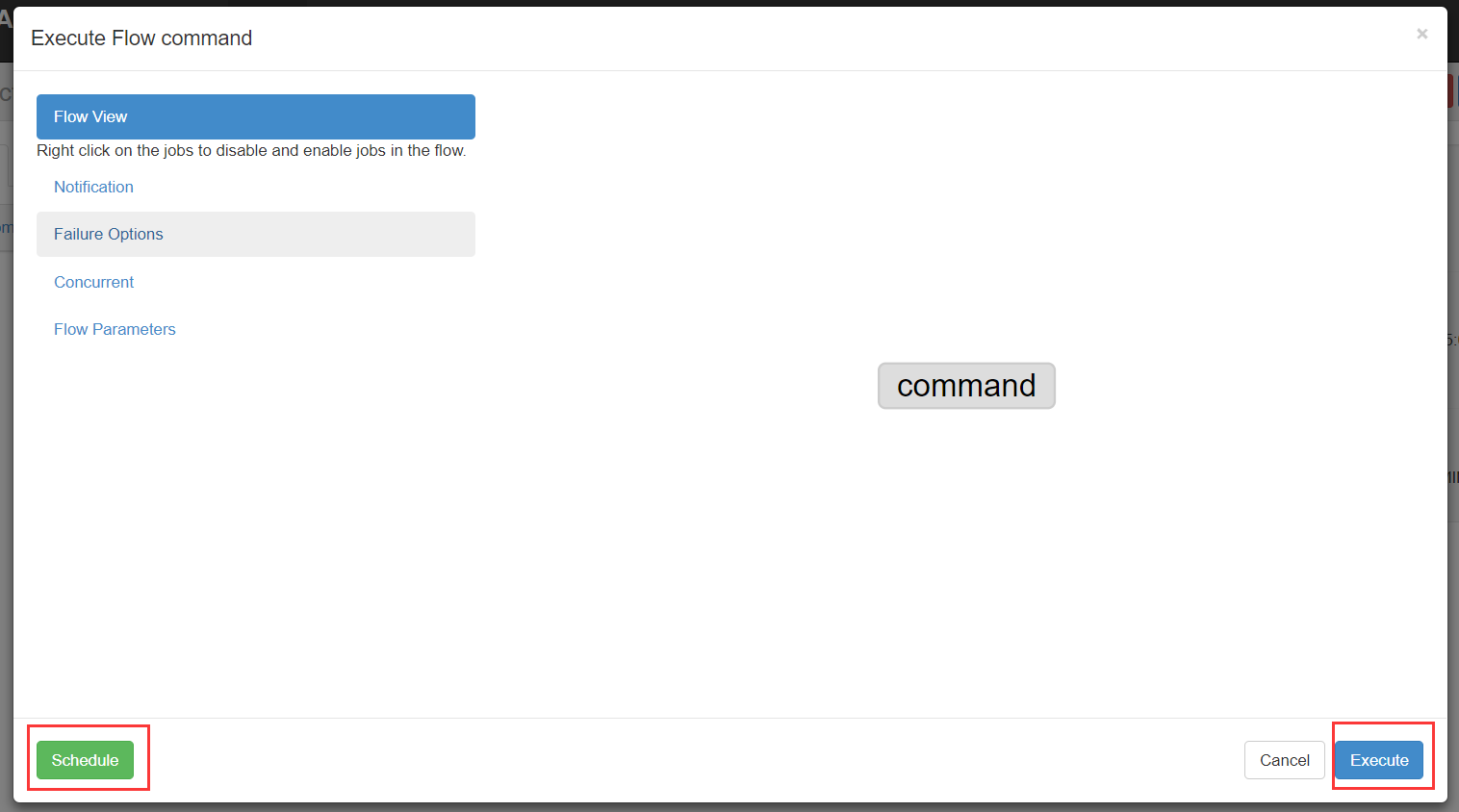
右上方是配置执行当前流程或者执行定时流程。
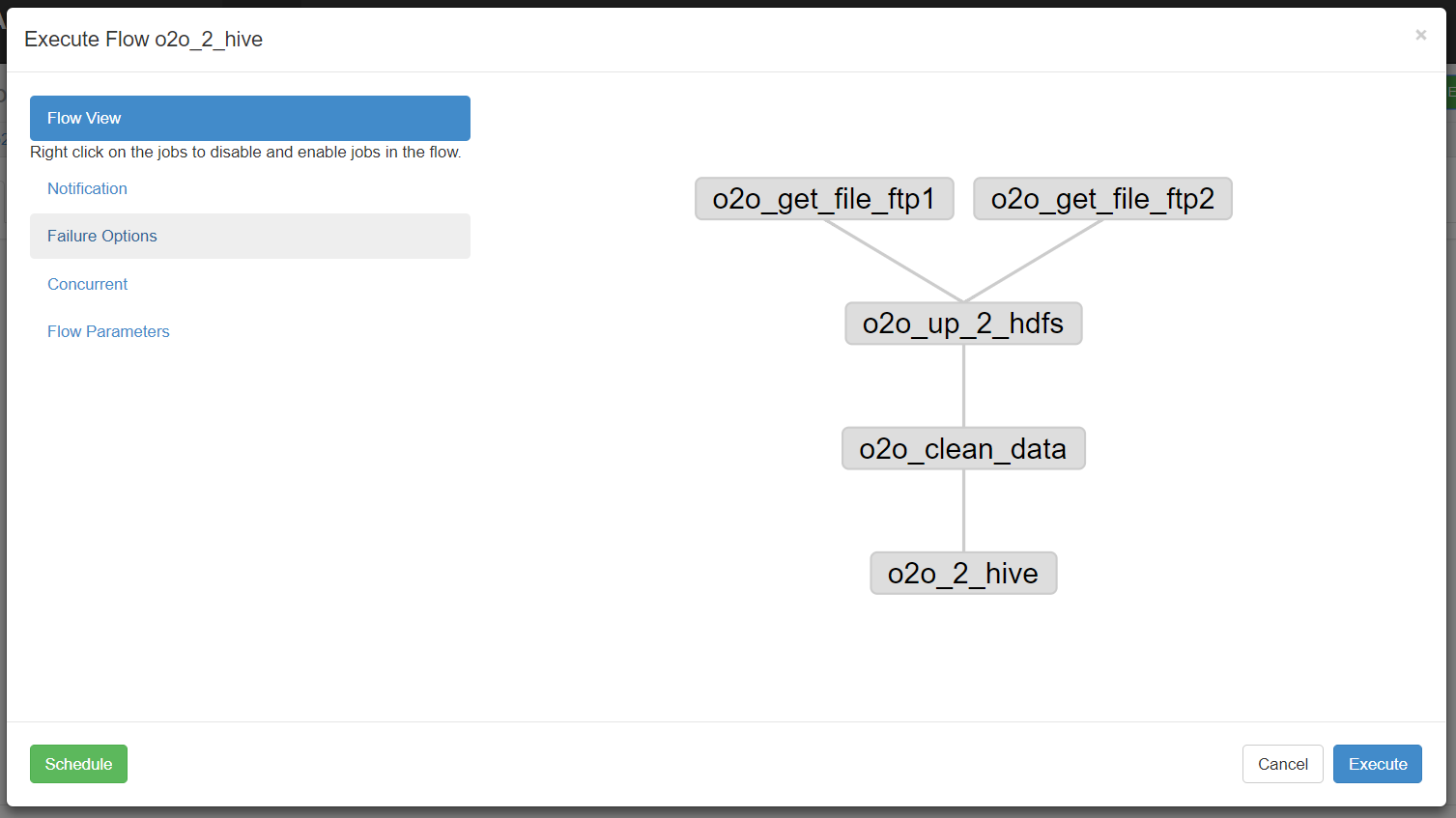
说明
Flow view:流程视图。可以禁用,启用某些job
Notification:定义任务成功或者失败是否发送邮件
Failure Options:定义一个job失败,剩下的job怎么执行
Concurrent:并行任务执行设置
Flow Parametters:参数设置。
(3)执行一次
设置好上述参数,点击execute。
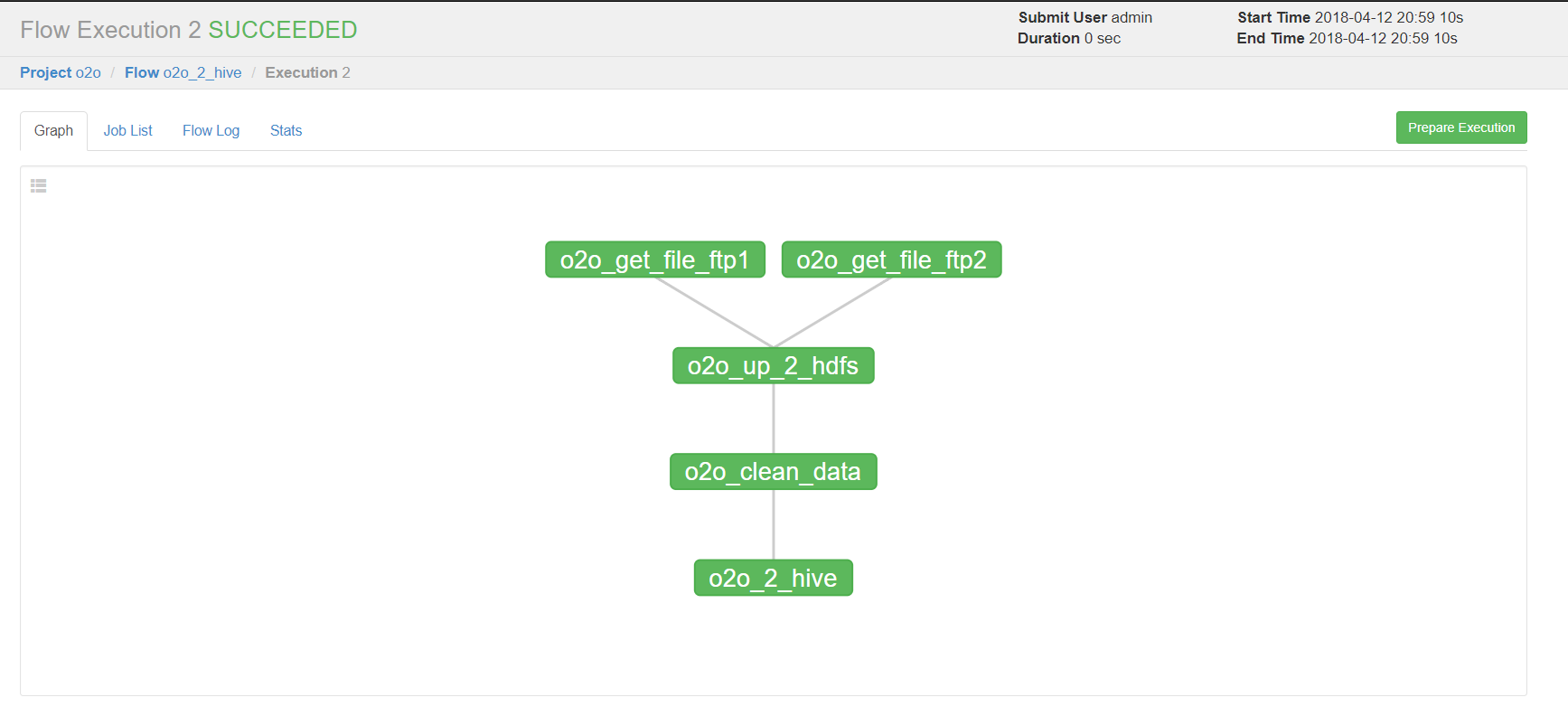
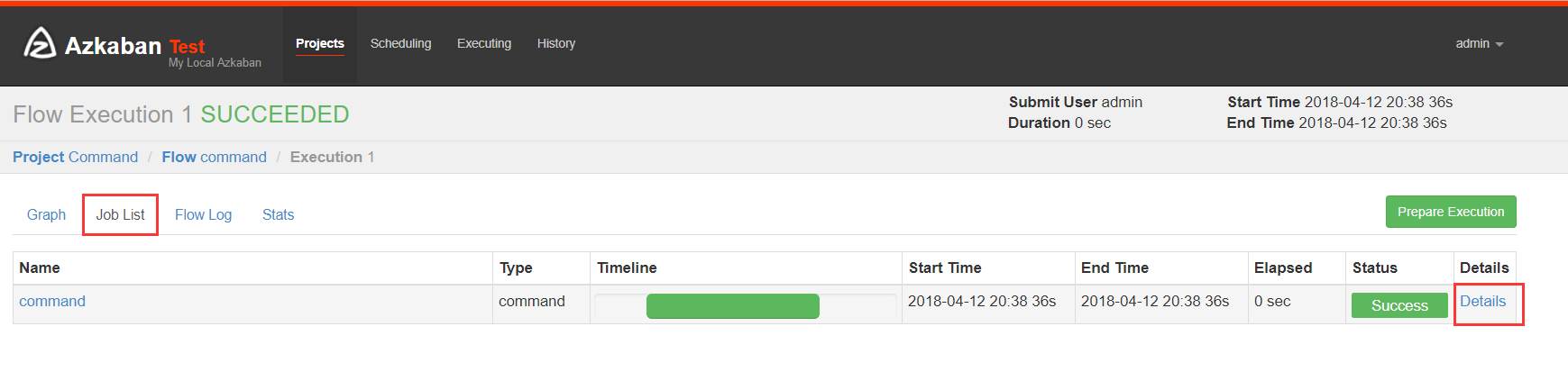
绿色代表成功,蓝色是运行,红色是失败。可以查看job运行时间,依赖和日志,点击details可以查看各个job运行情况。
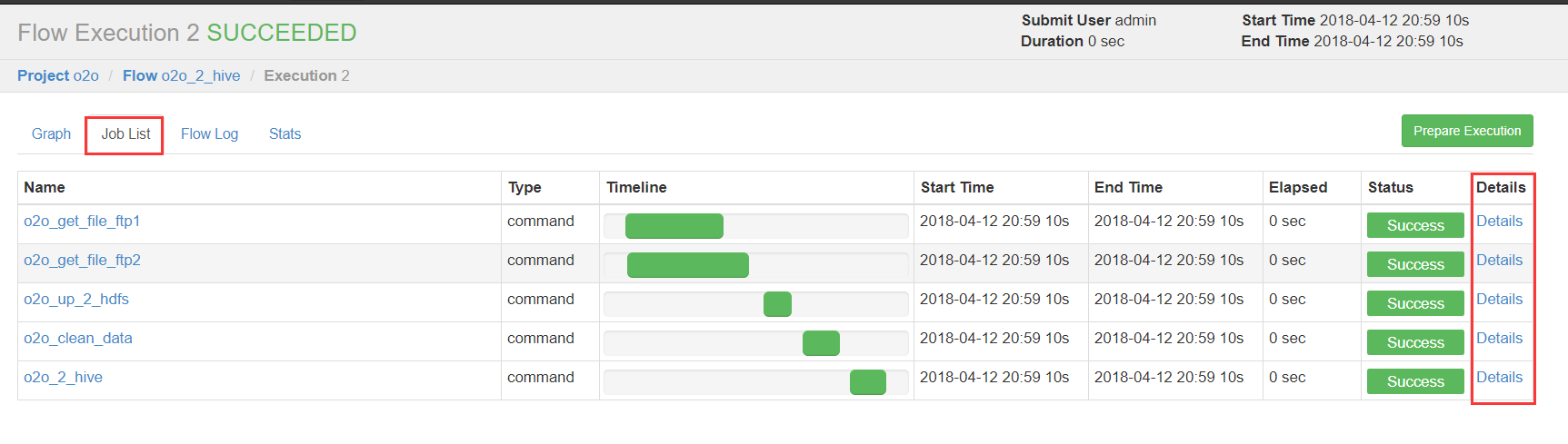
(4)执行定时任务
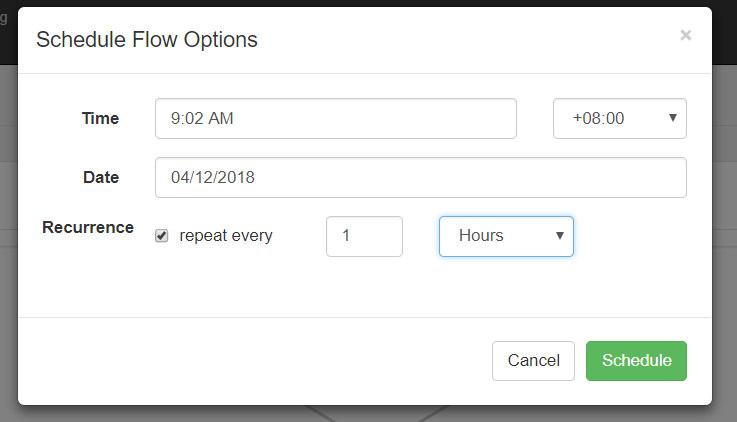
这时候注意到cst了吧,之前需要将配置中时区改为Asia/shanghai。
可以选择"天/时/分/月/周"等执行频率。

可以查看下次执行时间。
3、操作 MapReduce 任务
(1)创建 job 描述文件
mapreduce_wordcount.job
# mapreduce_wordcount.job
type=command
dependencies=mapreduce_pi
command=/home/hadoop/apps/hadoop-2.7.5/bin/hadoop
jar
/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar
wordcount /wordcount/input /wordcount/output_azkaban
mapreduce_pi.job
# mapreduce_pi.job
type=command
command=/home/hadoop/apps/hadoop-2.7.5/bin/hadoop
jar
/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar
pi 5 5
(2)创建 project 并上传 zip 包

(3)启动执行

4、Hive 脚本任务
(1) 创建 job 描述文件和 hive 脚本
Hive 脚本如下
test.sql
create database if not exists azkaban;
use azkaban;
drop table if exists student;
create table student(id int,name string,sex string,age int,deparment string) row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/student.txt' into table student;
create table student_copy as select * from student;
insert overwrite directory '/aztest/hiveoutput' select count(1) from student_copy;
!hdfs dfs -cat /aztest/hiveoutput/000000_0;
drop database azkaban cascade;
Job 描述文件:
hivef.job
# hivef.job
type=command
command=/home/hadoop/apps/apache-hive-2.3.3-bin/bin/hive -f 'test.sql'
(2)将所有 job 资源文件打到一个 zip 包中
(3)在 azkaban 的 web 管理界面创建工程并上传 zip 包
5、启动 job
Azkaban(三)Azkaban的使用的更多相关文章
- 分布式计算(三)Azkaban介绍
转载自:Azkaban学习之路 (一)Azkaban的基础介绍 目录 一.为什么需要工作流调度器 二.工作流调度实现方式 三.常见工作流调度系统 四.各种调度工具对比 五.Azkaban 与 Oozi ...
- Azkaban学习之路 (三)Azkaban的使用
界面介绍 首页有四个菜单 projects:最重要的部分,创建一个工程,所有flows将在工程中运行. scheduling:显示定时任务 executing:显示当前运行的任务 history:显示 ...
- 初识Azkaban
先说下hadoop 内置工作流的不足 (1)支持job单一 (2)硬编码 (3)无可视化 (4)无调度机制 (5)无容错机制 在这种情况下Azkaban就出现了 1)Azkaban是什么 Azkaba ...
- Azkaban 2.5.0 搭建
一.前言 最近试着参照官方文档搭建 Azkaban,发现文档很多地方有坑,所以在此记录一下. 二.环境及软件 安装环境: 系统环境: ubuntu-12.04.2-server-amd64 安装目录: ...
- hadoop工作流引擎之azkaban [转]
介绍 Azkaban是twitter出的一个任务调度系统,操作比Oozie要简单很多而且非常直观,提供的功能比较简单.Azkaban以Flow为执行单元进行定时调度,Flow就是预定义好的由一个或多个 ...
- Oozie和Azkaban的技术选型和对比
1 两种调度工具功能对比图 下面的表格对上述2种hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在区别 特性 ...
- hadoop工作流引擎之azkaban
Azkaban是twitter出的一个任务调度系统,操作比Oozie要简单很多而且非常直观,提供的功能比较简单.Azkaban以Flow为执行单元进行定时调度,Flow就是预定义好的由一个或多个可存在 ...
- Azkaban 2.5.0 搭建和一些小问题
安装环境: 系统环境: ubuntu-12.04.2-server-amd64 安装目录: /usr/local/ae/ankaban JDK 安装目录: export JAVA_HOME=/usr/ ...
- 工作流调度器azkaban(以及各种工作流调度器比对)
1:工作流调度系统的作用: (1):一个完整的数据分析系统通常都是由大量任务单元组成:比如,shell脚本程序,java程序,mapreduce程序.hive脚本等:(2):各任务单元之间存在时间先后 ...
随机推荐
- N制和PAL制区别
- HTTP协议(1)-------- 网络编程
1. HTTP简介 HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议.它可以使浏览器更加高效,使网络传输减少. ...
- 《A First Course in Abstract Algebra with Applications》-chaper1-数论-棣莫弗定理
定理1.24 (棣莫弗定理) 对每个实数x和每个正整数n有 基于棣莫弗定理的推论如下:
- Java时间格式转换工具类
把当前时间修改成指定时间 //把当前时间修改成指定时间 public String dateUtil(Integer seconds, String dateFormatPattern){ Date ...
- 重新找回spyder3-editor 里的code completion
升级到spyder3之后, 突然丢失了code autocompletion在editor context里. 觉得太不爽了. 虽然在ipython窗格里TAB键的自动完成功能依然完好. 仔细观察 T ...
- mysql 允许远程登录
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION;flush privileges;
- 【转】线程间操作无效: 从不是创建控件“textBox2” 的线程访问它。
using System;using System.Collections.Generic;using System.ComponentModel;using System.Data;using Sy ...
- sort函数(cmp)、map用法---------------Tju_Oj_2312Help Me with the Game
这道题里主要学习了sort函数.sort的cmp函数写法.C++的map用法(其实和数组一样) Your task is to read a picture of a chessboard posit ...
- 图片压缩-KMeans
下面给大家一起分享使用KMeans自动聚类,压缩图片像素点.每种图片可能他们的维度都不同,比如jpg一共有(w,h,3)三维,但是灰度图只有一维(w,h,1),也有四维的图片(w,h,4)等等.我们可 ...
- C - A Plug for UNIX (又是建图坑)
题目链接:https://cn.vjudge.net/contest/68128#problem/C 没理解好题意真的麻烦,一上午就这么过去了..... 具体思路:按照 源点 ->插座-> ...