Hive的介绍及安装
简介

Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能。
本质是将 SQL 转换为 MapReduce 程序。
Hive组件
用户接口:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command lineinterface)为 shell 命令行;JDBC/ODBC 是 Hive 的 JAVA 实现,与传统数据库JDBC 类似;WebGUI 是通过浏览器访问 Hive。
元数据存储:通常是存储在关系数据库如 mysql/derby 中。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
Hive 与 Hadoop 的关系
Hive 利用HDFS 存储数据,利用 MapReduce 查询分析数据
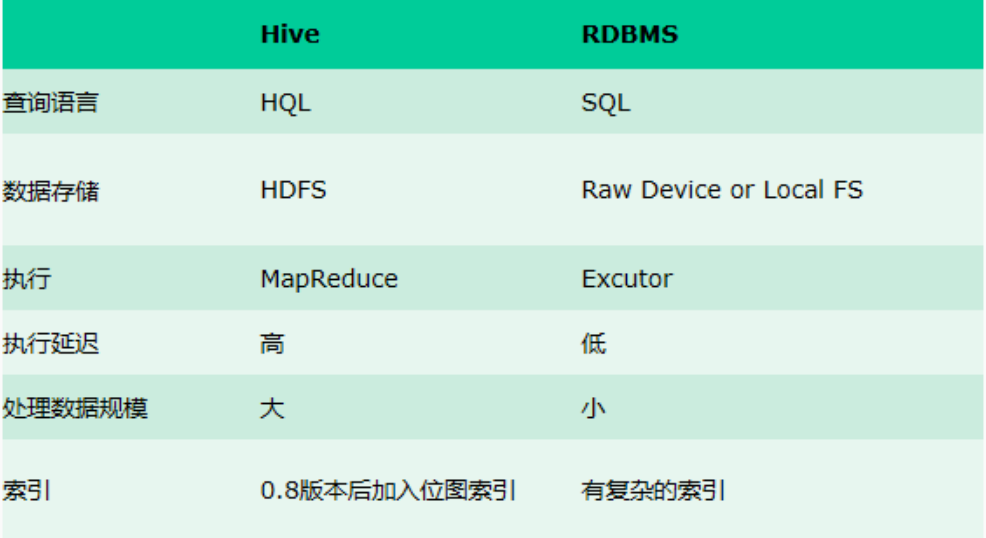
Hive 与传统数据库 对比
hive 用于海量数据的离线数据分析。
hive 具有 sql 数据库的外表,但应用场景完全不同,hive 只适合用来做批量数据统计分析。
1、具备数据存储的能力,使用Hadoop hdfs来进行数据的存储
2、具备ETL的能力,使用Hadoop MapReduce进行数据的ETL (提供sql转化成MapReduce的能力)
Hive数据模型
Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式,在创建表时指定数据中的分隔符,Hive 就可以映射成功,解析数据。
Hive 中包含以下数据模型:
db :在 hdfs 中表现为 hive.metastore.warehouse.dir 目录下一个文件夹
table :在 hdfs 中表现所属 db 目录下一个文件夹
external table :数据存放位置可以在 HDFS 任意指定路径
partition :在 hdfs 中表现为 table 目录下的子目录
bucket :在 hdfs 中表现为同一个表目录下根据 hash 散列之后的多个文件
一些专业术语
增量(上次导出之后的新数据):i_s.Peking.orders_20130711_000.lzo
加密:i_s.peking.orders_20130711_000.md5
表结构:i_s.peking.orders_20130711_000.xml
全量(表中所有的数据):a_s.Peking.orders_20130711_000.lzo
加密:a_s.peking.orders_20130711_000.md5
表结构:a_s.peking.orders_20130711_000.xml
PV:页面访问量,即PageView,用户每次对网站的访问均被记录,用户对同一页面的多次访问,访问量累计。
UV:独立访问用户数:即UniqueVisitor,访问网站的一台电脑客户端为一个访客。一天内相同的客户端只被计算一次。
数据仓库:Data Warehouse,简写为 DW 或 DWH
数据库:database,简写DB
联机事务处理 OLTP(On-Line Transaction Processing) --> 关系型数据库RDBMS
联机分析处理 OLAP(On-Line Analytical Processing) --> 数据仓库
ETL(抽取 Extra, 转化 Transfer, 装载 Load)
源数据层(ODS)
数据仓库层(DW)
数据应用层(DA 或 APP)
元数据(Meta Date)
Hive MySQL版本的安装
内置derby版缺点:不同路径启动 hive,每一个 hive 拥有一套自己的元数据,无法共享
安装hive
上传hive的安装包并解压
切换到hive安装目录的配置文件路径中修改配置信息
cd /export/servers/hive/conf
vi hive-env.sh
export HADOOP_HOME=/export/servers/hadoop-2.7.4
vi hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
<description>password to use against metastore database</description>
</property>
</configuration>
安装mysql
yum install -y mysql mysql-server mysql-devel
#启动mysql服务
/etc/init.d/mysqld start
mysql
USE mysql;
#设置用户及密码
UPDATE user SET Password=PASSWORD('hadoop') WHERE user='root';
#刷新权限
FLUSH PRIVILEGES;
#设置权限
GRANT ALL PRIVILEGES ON . TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
#设置开机启动mysql服务
chkconfig mysqld on
注意把mysql数据库驱动mysql-connector-java-5.1.32.jar放置在hive lib/目录中
启动hive前,先启动HDFS及YARN集群
Hive几种使用方式:
1.Hive交互shell bin/hive
2.Hive JDBC服务(参考java jdbc连接mysql)
3.hive启动为一个服务器,来对外提供服务
bin/hiveserver2
nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
启动成功后,可以在别的节点上用beeline去连接
bin/beeline -u jdbc:hive2://mini1:10000 -n root
或者
bin/beeline
! connect jdbc:hive2://mini1:10000
4.Hive命令
hive -e ‘sql’
bin/hive -e 'select * from t_test'
Hive的介绍及安装的更多相关文章
- Hive学习之一 《Hive的介绍和安装》
一.什么是Hive Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据 ...
- 吴超老师课程--Hive的介绍和安装
1.Hive1.1在hadoop生态圈中属于数据仓库的角色.他能够管理hadoop中的数据,同时可以查询hadoop中的数据. 本质上讲,hive是一个SQL解析引擎.Hive可以把SQL查询转换为 ...
- 从零自学Hadoop(14):Hive介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 本系列已 ...
- hive学习笔记_hive的介绍与安装
一.什么是Hive Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据 ...
- Hive介绍及安装
Hive介绍及安装 介绍: Hive是基于Hadoop的数据仓库解决方案.由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性. 简单来说 ...
- Hive介绍和安装部署
搭建环境 部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放 Hadoop等组件运行包.因为该目录用于安装h ...
- 从零自学Hadoop(19):HBase介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一篇, ...
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
- Hadoop入门进阶课程8--Hive介绍和安装部署
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
随机推荐
- HUE配置文件hue.ini 的database模块详解(包含qlite、mysql、 psql、和oracle)(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! Hue配置文件里,提及到,提供有postgresql_psycopg2, mysql, sqlite3 or oracle. 注意:Hue本身用到的是sqlite3. 在哪里呢, ...
- C/C++ -- Gui编程 -- Qt库的使用 -- 标准对话框
-----mywidget.cpp----- #include "mywidget.h" #include "ui_mywidget.h" #include & ...
- Go语言学习笔记十三: Map集合
Go语言学习笔记十三: Map集合 Map在每种语言中基本都有,Java中是属于集合类Map,其包括HashMap, TreeMap等.而Python语言直接就属于一种类型,写法上比Java还简单. ...
- k折交叉验证
原理:将原始数据集划分为k个子集,将其中一个子集作为验证集,其余k-1个子集作为训练集,如此训练和验证一轮称为一次交叉验证.交叉验证重复k次,每个子集都做一次验证集,得到k个模型,加权平均k个模型的结 ...
- SpringMVC源码阅读:定位Controller
1.前言 SpringMVC是目前J2EE平台的主流Web框架,不熟悉的园友可以看SpringMVC源码阅读入门,它交代了SpringMVC的基础知识和源码阅读的技巧 本文将通过源码分析,弄清楚Spr ...
- Hive中自定义Map/Reduce示例 In Python
Hive支持自定义map与reduce script.接下来我用一个简单的wordcount例子加以说明.使用Python开发(如果使用Java开发,请看这里). 开发环境: python:2.7.5 ...
- VS2013 项目项目安装和部署
版权声明:本文为博主原创文章,未经博主允许不得转载. 1.release 模式下生成项目 2.解决方案 右键 添加 新建项目 其他项目类型 安装和部署 3.操作前将待打包项目发布路径指向上述 ...
- [转]Mongodb的下载和安装
本文转自:https://www.cnblogs.com/htyj/p/8260602.html 下载 下载地址:http://dl.mongodb.org/dl/win32/x86_64 说明:z ...
- 四:Jquery-animate
动画效果: 1.显示/隐藏动画效果 动态的改变当前元素的宽,高和不透明度 show([duration],[fn]); //显示当前元素 hide([duration],[fn]); //隐藏当前元素 ...
- gRPC的通讯过程
在 HTTP2 协议正式开始工作前, 如果已经知道服务器是 HTTP2 的服务器, 通讯流程如下: 客户端必须首先发送一个连接序言,其逻辑结构: PRI * HTTP/2.0\r\n\r\nSM\r\ ...