HBase 架构与工作原理5 - Region 的部分特性
本文系转载,如有侵权,请联系我:likui0913@gmail.com
Region
Region 是表格可用性和分布的基本元素,由列族(Column Family)构成的 Store 组成。对象的层次结构如下:
- Table
- Region
- Store (由每个 Region 中的列族组成的存储块)
- MemStore (每个 Region 中存储在内存中的 Store)
- StoreFile (每个 Region 中被持久化后的 Store)
- Block (StoreFile 内被分块存储后的块)
其中 StoreFile 在 HDFS 中的存储路径为:
/hbase
/data
/<Namespace> (Namespaces in the cluster)
/<Table> (Tables in the cluster)
/<Region> (Regions for the table)
/<ColumnFamily> (ColumnFamilies for the Region for the table)
/<StoreFile> (StoreFiles for the ColumnFamily for the Regions for the table)
1. Region 数量
通常而言,HBase 被设计成每台服务器运行一个数量较小的(20 - 200)但大小相对较大(5 - 20 GB)的 Region。那么为什么应该保持 Region 数量较低?
以下是保持较低 Region 数量的一些原因:
每个 MemStore 需要 2MB 的 MSLAB(MemStore-local 分配的 buffer)- 相当于每个 Region 的每个列族(ClounmFamily)需要 2MB 的 MSLAB。那么 1000 个有 2 个列族的 Region 将使用 2MB * 1000 * 2 = 4000MB ~= 3.9GB 的堆内存,甚至都还没有开始存储数据。注:MSLAB 的大小是可配置的,默认为 2MB.
- 如果以相同的速率填充所有的 Region,则全局内存使用情况会在因为 Region 太多而产生 compaction 操作时,强制进行微小的刷新。举个例子:平均填充1000个Region(有一个列族),假如有5GB的全局 MemStore 使用的下限(RegionServer有一个大的堆),一旦它达到5GB,它将强制刷新最大的 Region,那时每个 Region 大约都是 5MB 的数据,所以它会刷新这个 Region。稍后再插入 5MB,它将刷新另一个 Region,依次类推。目前这个是 Region 数量的主要限制因素。更多请参阅。。。
举个实例来说:目前的一个集群单台 RegionServer 分配的内存大小为 32GB,其中所有的 MemStore 的最大大小比例设置为 0.4,即最大大小为 32GB * 0.4 = 12.8GB
Master 很讨厌太多的 Region,因为这可能需要大量的时间分配并批量移动。
在比较旧版本的 HBase(HFile v2, 0.90 之前的版本)中,几个 RegionServer 上的大量的 Region 会导致存储文件索引上升,增加堆使用量,并可能在 RS 导致内存压力或 OOME。
- 另外一个问题是 Region 数量对 MapReduce 作业的影响。每个 HBase Region 都有一个映射器是很典型的,因此,每个 RS 仅托管 5 个 Region 可能不足以获得足够数量的 MapReduce 作业任务,但是 1000 个 Region 又将生成太多的任务。
请参考Determining region count and size配置 Region 数量。
2. Region-RegionServer 的分配
当 HBase 启动 RegionServer 分配时,简要过程如下:
- Master 在启动时调用 AssignmentManager;
- AssignmentManager 查看 hbase:meta 中的现有 Region 分配;
- 如果 Region 分配仍然有效(即,如果 RegionServer 仍处于联机状态),则保留分配;
- 如果分配无效,则调用 LoadBalancerFactory 来分配 Region。负载均衡器将 Region 分配给 RegionServer;
- hbase:meta 使用 RegionServer 分配(如果需要)和 RegionServer 的开始码(RegionServer进程的开始时间)在 RegionServer 打开 Region 时进行更新。
3. 故障转移
当 RegionServer 失败时:
- 由于 RegionServer 关闭,它上面的 Region 会立即变得不可用;
- Master 将检测到 RegionServer 失败;
- Region 分配将被视作无效,并将像启动顺序一个被重新分配;
- 重新尝试进行中的查询,不会丢失;
- 在以下时间段内,操作将切换到新的 RegionServer:
ZooKeeper session timeout + split time + assignment/replay time
4. 负载平衡
Region 可以被负载平衡器(LoadBalancer)定期的移动。
5. 状态转换
HBase 维持每个 Region 的状态,并将它们的状态保存在 hbase:meat 表中,hbase:meta 的 Region 状态则保存在 Zookeeper 中。在 Master Web UI 中可以查看转换中的 Region 状态。以下是可能的 Region 状态列表:
- OFFLINE: 该 Region 处于离线状态,无法打开
- OPENING: 该 Region 正在打开
- OPEN: 该 Region 已经打开,并且 RegionServer 已经通知 Master
- FAILED_OPEN: RegionServer 打开该 Region 失败
- CLOSING: 该 Region 正在关闭
- CLOSED: RegionServer 关闭了该 Region,并通知了 Master
- FAILED_CLOSE: RegionSever 关闭该 Region 失败
- SPLITTING: RegionServer 通知 Master Region 正在分裂(splitting)
- SPLIT: RegionServer 通知 Master Region 已经完成分裂
- SPLITTING_NEW: 该 Region 正在进行通过分裂创建新的 Region
- MERGING: RegionServer 通知 master 该 region 正在与另外一个 region 合并
- MERGED: RegionServer 通知 master 该 region 已经合并完成
- MERGING_NEW: 该 Region 由两个 Region 合并完成
状态转换图如下:
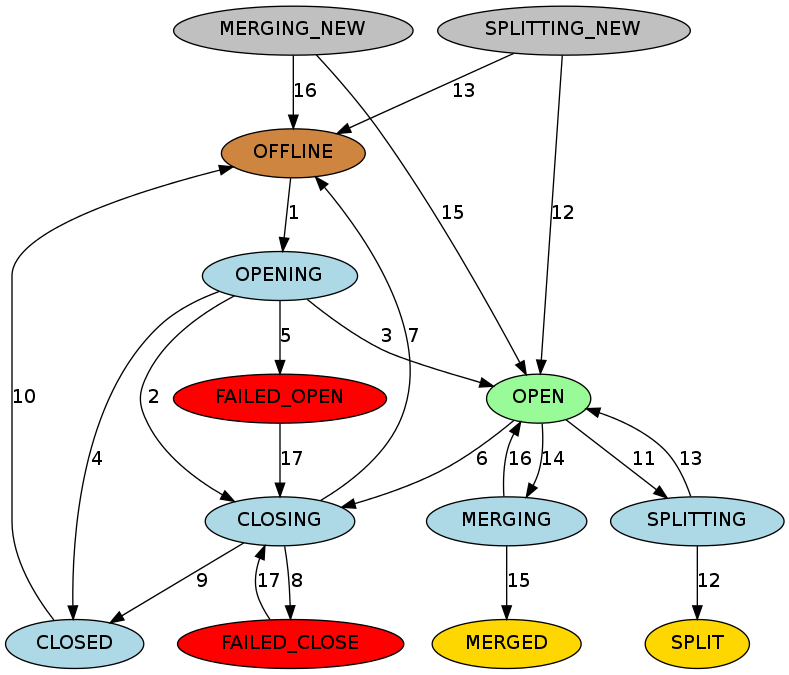
图示说明:
- 棕色:离线状态,一种特殊状态,可以是暂时的(打开之前关闭后)、最终的(被 disabled 表的 regions)或者初始的(新建表的 region)
- 淡绿色:在线状态,region 可以为请求提供服务
- 淡蓝色:过渡状态,瞬时的
- 红色:失败状态,需要管理员关注,通常无法写入数据可能就是它照成的
- 黄金:regions split/merged 后的最终状态
- 灰色:通过 split/merged 并创建的新的 region 的初始状态
过渡状态描述
Master将Region从
OFFLINE转换成OPENING状态,并尝试将该区域分配给RegionServer。RegionServer可能收到也可能未收到开放Region的请求。Master会重试将打开Region请求发送RegionServer,直到RPC通过或Master用完重试。在RegionServer收到打开Region请求后,RegionServer开始打开Region;如果Master重试超时,则即使RegionServer正在打开Region,Master也会通过将Region转换为
CLOSING状态并尝试关闭它来阻止RegionServer继续打开该Region;RegionServer打开该Region后,它将继续尝试通知Master,直到Master将该Region转换为
OPEN状态并通知RegionServer,该Region才算打开;如果RegionServer无法打开Region,它会通知Master。然后Master将该Region转换为
CLOSED状态,并尝试在其它的RegionServer上打开该Region;如果Master无法打开某个Region,则会将Region转换为
FAILED_OPEN状态,并且在管理员使用HBase shell操作之前或服务器死亡之前不会采取进一步的操作;Master将Region从
OPEN转换为CLOSING状态。持有Region的RegionServer可能已经或可能未收到关闭Region请求。Maater将重试向服务器发送关闭请求,直到RPC通过或Master用尽重试;如果RegionServer不在线或引发NotServingRegionException,则Master将该Region转换为
OFFLINE状态,并将其重新分配给其它的RegionServer;如果RegionServer处于联机状态,但在Master用完重试之后无法访问,则Master会将该Region移至
FAILED_CLOSE状态,并且不会采取进一步的操作,直到操作员从HBase shell进行干预或服务器死亡;如果RegionServer获得关闭Region请求,它会关闭该Region并通知Master。Master将该Reguib移至CLOSED状态并重新分配给其它的RegionServer;
在分配Region之前,如果Region处于
CLOSED状态,Master会自动将Region转换为OFFLINE状态;当一个RegionServer即将分裂(split)一个Region时,它通知Master,Master将Region从
OPEN转换为SPLITTING状态,并将要创建的两个新Region添加到RegionServer。这两个Region最初处于SPLITTING_NEW状态。在通知Master后,RegionServer开始分裂Region。一旦经过了不返回的地方,RegionServer会再次通知Master,以便Master可以更新hbase:meta表。不管怎样,在服务器通知分裂完成之前,Master不会更新Region的状态。如果分裂成功,则分裂的Region从
SPLITTING转换为SPLIT状态,并且两个新的Region从SPLITTING_NEW转换为OPEN状态。如果分裂失败,则分裂Region将从
SPLITTING回到OPEN状态,并且创建的两个新的Region将从SPLITTING_NEW转换为OFFLINE状态;当一个RegionServer即将合并(merge)两个Region时,它首先通知Master,Master将两个待合并的Region从
OPEN转换为MERGING状态,并将拥有两个合并的Region内容的新的Region添加到并添加到RegionServer。新的Region最初处于MERGING_NEW状态。通知Master后,RegionServer开始合并这两个Region。一旦经过不返回的地方,RegionServer再次通知Master,以便Master可以更新META表。但是,Master不会更新Region状态,直到RegionServer通知合并已完成。如果合并成功,则两个合并的 Region将从
MERGING状态变为MERGED状态,并且新的 Region 将从MERGING_NEW转换为OPEN状态;如果合并失败,则将两个合并的Region从
MERGING更改回OPEN状态,并且创建的用于容纳合并Region内容的新的Region将从MERGING_NEW转换为OFFLINE状态。对于处于
FAILED_OPEN或FAILED_CLOSE状态的Region,Master在通过HBase Shell重新分配它们时尝试再次关闭它们。
可能产生的影响
了解Region的状态变化过程十分重要,因为Region的状态在发生更改时,如果发生异常,很可能需要管理员人工介入。而在人工介入之前,很有可能会影响到部分表的正常使用,示例可参见:(HBase 部分表无法写入数据的异常处理)[https://blog.csdn.net/t894690230/article/details/78508862]
参考链接
HBase 架构与工作原理5 - Region 的部分特性的更多相关文章
- HBase 架构与工作原理2 - HBase 组件
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.HBase 组件概览 Master-Slave 模式: HBase 体系结构遵循传统的 master-slave 模式,由一 ...
- HBase(三)HBase架构与工作原理
一.系统架构 注意:应该是每一个 RegionServer 就只有一个 HLog,而不是一个 Region 有一个 HLog. 从HBase的架构图上可以看出,HBase中的组件包括Client.Zo ...
- HBase 架构与工作原理3 - HBase 读写与删除原理
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.前言 在 HBase 中,Region 是有效性和分布的基本单位,这通常也是我们在维护时能直接操作的最小单位.比如当一个集群 ...
- HBase 架构与工作原理4 - 压缩、分裂与故障恢复
本文系转载,如有侵权,请联系我:likui0913@gmail.com Compacation HBase 在读写的过程中,难免会产生无效的数据以及过小的文件,比如:MemStore 在未达到指定大小 ...
- HBase 架构与工作原理1 - HBase 的数据模型
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.应用场景 HBase 与 Google 的 BigTable 极为相似,可以说 HBase 就是根据 BigTable 设计 ...
- 转载->CPU的内部架构和工作原理
CPU的内部架构和工作原理 本片博客转自:http://www.cnblogs.com/onepixel/p/8724526.html 感谢博主分享! 内部架构 CPU 的根本任务就是执行指令,对计 ...
- CPU处理器架构和工作原理浅析
CPU处理器架构和工作原理浅析 http://c.biancheng.net/view/3456.html 汇编语言是学习计算机如何工作的很好的工具,它需要我们具备计算机硬件的工作知识. 基本微机设计 ...
- 1、cpu架构和工作原理
cpu架构和工作原理 计算机有5大基本组成部分,运算器,控制器,存储器,输入和输出.运算器和控制器封装到一起,加上寄存器组和cpu内部总线构成中央处理器(CPU).cpu的根本任务,就是执行指令,对计 ...
- CPU的内部架构和工作原理 (转,相当不错)
http://blog.chinaunix.net/uid-23069658-id-3563960.html 一直以来,总以为CPU内部真是如当年学习<计算机组成原理>时书上所介绍的那样, ...
随机推荐
- EnterpriseDb公司的Postgres Enterprise Manager 安装图解
磨砺技术珠矶,践行数据之道,追求卓越价值 回到上一级页面: PostgreSQL基础知识与基本操作索引页 回到顶级页面:PostgreSQL索引页 [作者 高健@博客园 luckyjackg ...
- Linux命令学习笔记2(mysql安装和mysql-python安装)
linux下 强制安装 rpm安装包(切换到root用户): rpm -ivh bluefish-shared-data-2.2.7-1.el6.noarch.rpm --nodeps --forc ...
- 12-[数据库]--图形工具Navicat
1.Navicat介绍 在生产环境中操作MySQL数据库还是推荐使用命令行工具mysql,但在我们自己开发测试时,可以使用可视化工具Navicat,以图形界面的形式操作MySQL数据库 官网下载:ht ...
- nginx反向代理解决wechat图片问题
在nginx 中nginx.conf开启反向代理 location ^~ /wechat_image/ { add_header 'Access-Control-Allow-Origin' " ...
- Async方法死锁的问题 Don't Block on Async Code(转)
今天调试requet.GetRequestStreamAsync异步方法出现不返回的问题,可能是死锁了.看到老外一篇文章解释了异步方法死锁的问题,懒的翻译,直接搬过来了. http://blog.st ...
- Python 的AES加密与解密-需要安装的模块
踩雷1: #先导入所需要的包 pip3 install Crypto #再安装pycrtpto pin3 install pycrypto from Crypto.Cipher import AES ...
- 模拟websocket推送消息服务mock工具二
模拟websocket推送消息服务mock工具二 在上一篇博文中有提到<使用electron开发一个h5的客户端应用创建http服务模拟后端接口mock>使用electron创建一个模拟后 ...
- KClient——kafka消息中间件源码解读
目录 kclient消息中间件 kclient-processor top.ninwoo.kclient.app.KClientApplication top.ninwoo.kclient.app.K ...
- 如何批量删除QQ浏览器指定历史记录和导出指定的历史记录
QQ浏览器的历史记录只有清空历史记录和删除选中项两个功能.有时我不想删除所有的历史记录,只是想删除指定的历史记录保留对自己有用的历史记录,方便自己以后查找.但是删除选中项功能只能一项一项的选择,才能批 ...
- 微软职位内部推荐-SW Engineer II for Enterprise Platform
微软近期Open的职位: Job posting title: SDE II Location: China, Beijing Group Overview Discovery & Colla ...