Python20 - Day09
python并发编程之多线程理论
1、什么是线程?
进程只是用来把资源集中到一起(进程是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
多线程(多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间。
2、线程的创建开销小
创建一个进程,需要申请空间
创建线程,无需申请空间,所以开销小
3、线程与进程的区别
Threads share the address space of the process that created it; processes have their own address space.
Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
New threads are easily created; new processes require duplication of the parent process.
Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
4、为何要用多线程?
多线程指的是,在一个进程中开启多个线程,简单的将:如果多个任务共用一块地址空间,那么必须在一个进程内开启多个线程。详细阐述:
1、多线程共享一个进程的地址空间;
2、线程比进程更轻量级,线程比进程更容易创建和撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这个特性很有用;
3、若多个线程都是cpu密集型的,那么并不能获得性能上的增强,但如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而会加快程序执行的速度;
4、在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(这一条并不使用python)
python并发编程之多线程
1、threading模块
2、开启线程的两种方式
1、方式一
#方式一
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
print('主线程')
2、方式二
from threading import Thread
import time
class Sayhi(Thread):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
time.sleep(2)
print('%s say hello' % self.name) if __name__ == '__main__':
t = Sayhi('egon')
t.start()
print('主线程')
2、在一个进程下开启多个线程与一个进程下开启多个子进程的区别
谁的开启速度快
from threading import Thread
from multiprocessing import Process
import os def work():
print('hello') if __name__ == '__main__':
#在主进程下开启线程
t=Thread(target=work)
t.start()
print('主线程/主进程')
'''
打印结果:
hello
主线程/主进程
''' #在主进程下开启子进程
t=Process(target=work)
t.start()
print('主线程/主进程')
'''
打印结果:
主线程/主进程
hello
'''
from threading import Thread
from multiprocessing import Process
import os def work():
print('hello',os.getpid()) if __name__ == '__main__':
#part1:在主进程下开启多个线程,每个线程都跟主进程的pid一样
t1=Thread(target=work)
t2=Thread(target=work)
t1.start()
t2.start()
print('主线程/主进程pid',os.getpid()) #part2:开多个进程,每个进程都有不同的pid
p1=Process(target=work)
p2=Process(target=work)
p1.start()
p2.start()
print('主线程/主进程pid',os.getpid())
同一进程内的线程共享该进程的数据?
from threading import Thread
from multiprocessing import Process
import os
def work():
global n
n=0 if __name__ == '__main__':
# n=100
# p=Process(target=work)
# p.start()
# p.join()
# print('主',n) #毫无疑问子进程p已经将自己的全局的n改成了0,但改的仅仅是它自己的,查看父进程的n仍然为100 n=1
t=Thread(target=work)
t.start()
t.join()
print('主',n) #查看结果为0,因为同一进程内的线程之间共享进程内的数据
3、线程相关的其他方法
Thread实例对象的方法
# isAlive(): 返回线程是否活动的。
# getName(): 返回线程名。
# setName(): 设置线程名。 threading模块提供的一些方法:
# threading.currentThread(): 返回当前的线程变量。
# threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
# threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
from threading import Thread
import threading
from multiprocessing import Process
import os def work():
import time
time.sleep(3)
print(threading.current_thread().getName()) if __name__ == '__main__':
#在主进程下开启线程
t=Thread(target=work)
t.start() print(threading.current_thread().getName())
print(threading.current_thread()) #主线程
print(threading.enumerate()) #连同主线程在内有两个运行的线程
print(threading.active_count())
print('主线程/主进程') '''
打印结果:
MainThread
<_MainThread(MainThread, started 140735268892672)>
[<_MainThread(MainThread, started 140735268892672)>, <Thread(Thread-1, started 123145307557888)>]
主线程/主进程
Thread-1
'''
主线程等待子线程结束
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
t.join()
print('主线程')
print(t.is_alive())
'''
egon say hello
主线程
False
'''
4、守护线程
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁
需要强调的是:运行完毕并非终止运行
#1.对主进程来说,运行完毕指的是主进程代码运行完毕 #2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
#1 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束, #2 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.setDaemon(True) #必须在t.start()之前设置
t.start() print('主线程')
print(t.is_alive())
'''
主线程
True
'''
python GIL
1、介绍
'''
定义:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
'''
结论:在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
2、GIL介绍(Global Interpreter Lock)
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都是一样的,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
保护不同的数据的安全,就应该加不同的锁
每次执行python程序,都会产生一个独立的进程。
'''
#验证python test.py只会产生一个进程
#test.py内容
import os,time
print(os.getpid())
time.sleep(1000)
'''
python3 test.py
#在windows下
tasklist |findstr python
#在linux下
ps aux |grep python
在一个python的进程内,不仅有test.py的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有的线程都运行在这一个进程内。
#1 所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码)
例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。 #2 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
综上,如果多个线程的target=work,那么执行流程是:
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码执行。
解释器的代码是所有线程共享的。所以垃圾回收线程也可能访问到解释器的代码而去执行。
三、GIL与Lock
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理:
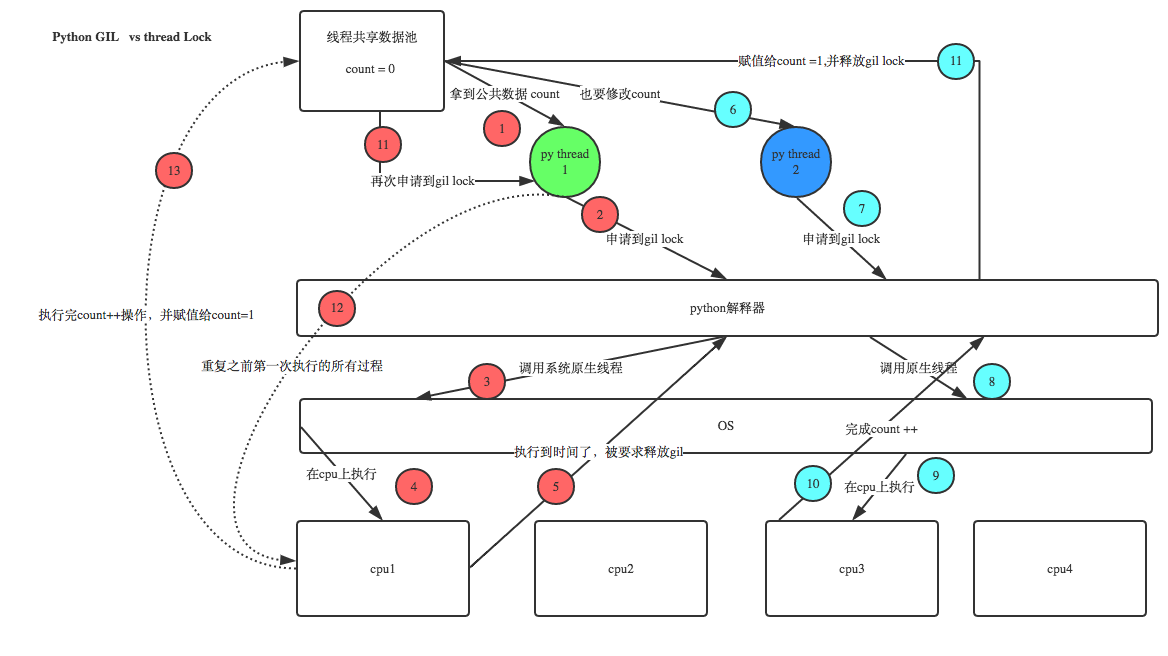
四、GIL与多线程
有了GIL的存在,同一时刻同一进程中只有一个线程被执行。
对计算来说,cpu越多越好,但是对于I/O来说,再多的CPU也没用
#分析:
我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是:
方案一:开启四个进程
方案二:一个进程下,开启四个线程 #单核情况下,分析结果:
如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜
如果四个任务是I/O密集型,方案一创建进程的开销大,且进程的切换速度远不如线程,方案二胜 #多核情况下,分析结果:
如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜
如果四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜 #结论:现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
五、多线程性能测试
计算密集型:多线程效率高
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(100000000):
res*=i if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(4):
p=Process(target=work) #耗时5s多
p=Thread(target=work) #耗时18s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
I/O密集型:多线程效率高
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():
time.sleep(2)
print('===>') if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(400):
# p=Process(target=work) #耗时12s多,大部分时间耗费在创建进程上
p=Thread(target=work) #耗时2s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
应用:
多线程用户I/O密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
paramiko模块
1、SSHClient
基于用户名密码:
import paramiko # 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='120.92.84.249', port=22, username='root', password='xxx') # 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
print(result.decode('utf-8'))
# 关闭连接
ssh.close()
基于公钥密钥连接:
import paramiko
private_key = paramiko.RSAKey.from_private_key_file('/tmp/id_rsa')
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='120.92.84.249', port=22, username='root', pkey=private_key)
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
print(result.decode('utf-8'))
# 关闭连接
ssh.close()
SFTPClient:
基于用户名和密码:
import paramiko
transport = paramiko.Transport(('120.92.84.249',22))
transport.connect(username='root',password='xxx')
sftp = paramiko.SFTPClient.from_transport(transport)
# 将location.py 上传至服务器 /tmp/test.py
sftp.put('/tmp/id_rsa', '/etc/test.rsa')
# 将remove_path 下载到本地 local_path
sftp.get('remove_path', 'local_path')
transport.close()
基于公钥密钥上传下载:
import paramiko
private_key = paramiko.RSAKey.from_private_key_file('/tmp/id_rsa')
transport = paramiko.Transport(('120.92.84.249', 22))
transport.connect(username='root', pkey=private_key )
sftp = paramiko.SFTPClient.from_transport(transport)
# 将location.py 上传至服务器 /tmp/test.py
sftp.put('/tmp/id_rsa', '/tmp/a.txt')
# 将remove_path 下载到本地 local_path
sftp.get('remove_path', 'local_path')
transport.close()
Python20 - Day09的更多相关文章
- DAY09、函数
一.函数的定义:跟变量名的定义大同小异 1.声明函数的关键词:def 2.函数(变量)名:使用函数的依据 3.参数列表:() 参数个数可以为0到n个,但()一定不能丢,完成功能的必要条件 4.函数 ...
- Python异常处理和进程线程-day09
写在前面 上课第九天,打卡: 最坏的结果,不过是大器晚成: 一.异常处理 - 1.语法错误导致的异常 - 这种错误,根本过不了python解释器的语法检测,必须在程序运行前就修正: - 2.逻辑上的异 ...
- day09:Servlet详解
day09 Servlet概述 生命周期方法: void init(ServletConfig):出生之后(1次): void service(ServletRequest request, ...
- python开发学习-day09(队列、多路IO阻塞、堡垒机模块、mysql操作模块)
s12-20160312-day09 *:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: ...
- 学习日常笔记<day09>Http协议
1 Http协议入门 1.1 什么是http协议 http协议: 对浏览器客户端 和 服务器端 之间数据传输的格式规范 1.2 查看http协议的工具 1)使用火狐的firebug插件(右键-> ...
- day09——初识函数
day09 函数的定义 # len() s = 'alexdsb' count = 0 for i in s: count += 1 print(count) s = [1,2,23,3,4,5,6] ...
- day09 python函数 返回值 参数
day09 python 一.函数 1.函数 函数是对功能的封装 语法: 定义函数: def 函数名(形参): ...
- Python学习day09 - Python进阶(3)
figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { position: relative; } img { max- ...
- day09 Django: 组件cookie session
day09 Django: 组件cookie session 一.cookie和session都是会话跟踪技术 1.什么是会话 可以理解为客户端和服务端之间的一次会 ...
随机推荐
- 初识Qt布局管理器
Qt布局管理器的类有4种,它们分别为QHBoxLayout.QVBoxLayout.QGridLayout和QStackLayout.其中,QHBoxLayout实现水平布局,QVBoxLayout实 ...
- C语言程序设计I—第九周教学
第九周教学总结(28/10-03/11) 教学内容 第三章 分支结构 3.3 查询自动售货机中商品的价格 课前准备 在蓝墨云班课发布资源: PTA:2018秋第九周作业1 3.3 分享码:530571 ...
- 四步掌握CAN节点隔离设计
四步掌握CAN节点隔离设计 “隔离”是模块为CAN节点设备提供可靠数据传输的首要保障,通常隔离模块的“隔离”是指模块上电后,能为节点提供信号隔离及电源隔离,隔离电压等级以2500VDC.3500VDC ...
- 【LeetCode415】Add Strings
题目描述: 解决思路: 此题较简单,和前面[LeetCode67]方法一样. Java代码: public class LeetCode415 { public static void main(St ...
- jQuery hide() 参数callback回调函数执行问题
$("#b").click(function() { $("div").hide(1000,bbb); //-------------1 bbb是一个函数,但这 ...
- 解决MAC下修改系统文件没权限的问题
问题 用brew在mac上可以轻松的管理软件, 不过最新的mac系统升级后, brew执行update命令时会报权限不足的错误, 而且会提示执行命令sudo chown -R $(whoami) /u ...
- HBase--大数据系统的数据库方案
本文主要围绕以下三方面来讨论HBase:是什么.为什么.怎样做. 1. 什么是HBase HBase是一个开源的.分布式的.非关系型数据库,其设计思想来源于Google的Big Table.通过集群管 ...
- 《Java 程序设计》课堂实践项目-类定义
<Java 程序设计>课堂实践项目类定义 课后学习总结 目录 改变 类定义实验要求 课堂实践成果 课后思考 改变 修改了博客整体布局,过去就贴个代码贴个图很草率,这次布局和内容都有修改. ...
- Linux下开发python django程序(设置admin后台管理上传文件和前台上传文件保存数据库)
1.项目创建相关工作参考前面 2.在models.py文件中定义数据库结构 import django.db import modelsclass RegisterUser(models.Model) ...
- code first 创建数据库,add-migration update-database
第一步: 第二步: