Python爬虫简单入门及小技巧
刚刚申请博客,内心激动万分。于是为了扩充一下分类,随便一个随笔,也为了怕忘记新学的东西由于博主十分怠惰,所以本文并不包含安装python(以及各种模块)和python语法。
目标
前几天上B站时看到一部很好玩的番剧,名字《笨女孩》,实际上是由同名的搞笑向漫画动画化的。大家都知道动画一般一周一更,很难满足我们的需求,所以我们就来编写一个爬虫,来爬取漫画咯。
那么本文的目标就是爬取《初音MIX》这部漫画(因为笨女孩我已经爬取过了>_<)。这部漫画我记得是小学的时候看的,也是我第一次接触日漫。
网上有很多的漫画网站,我们就选漫画之家好了!

需要的模块
request 用于下载网页
re python自带的正则模块
BeautifulSoup 用于解析html,让我们查找元素更方便(不过这次没用上)
开始!
Step1:确定需要爬取的网页地址
熟练运用网站的搜索工具,进入检索页面http://manhua.dmzj.com/tags/search.shtml?s=初音Mix
我们找到了目标地址http://manhua.dmzj.com/chuyinmix
接下来打开CH001,看到我们要爬取的图片
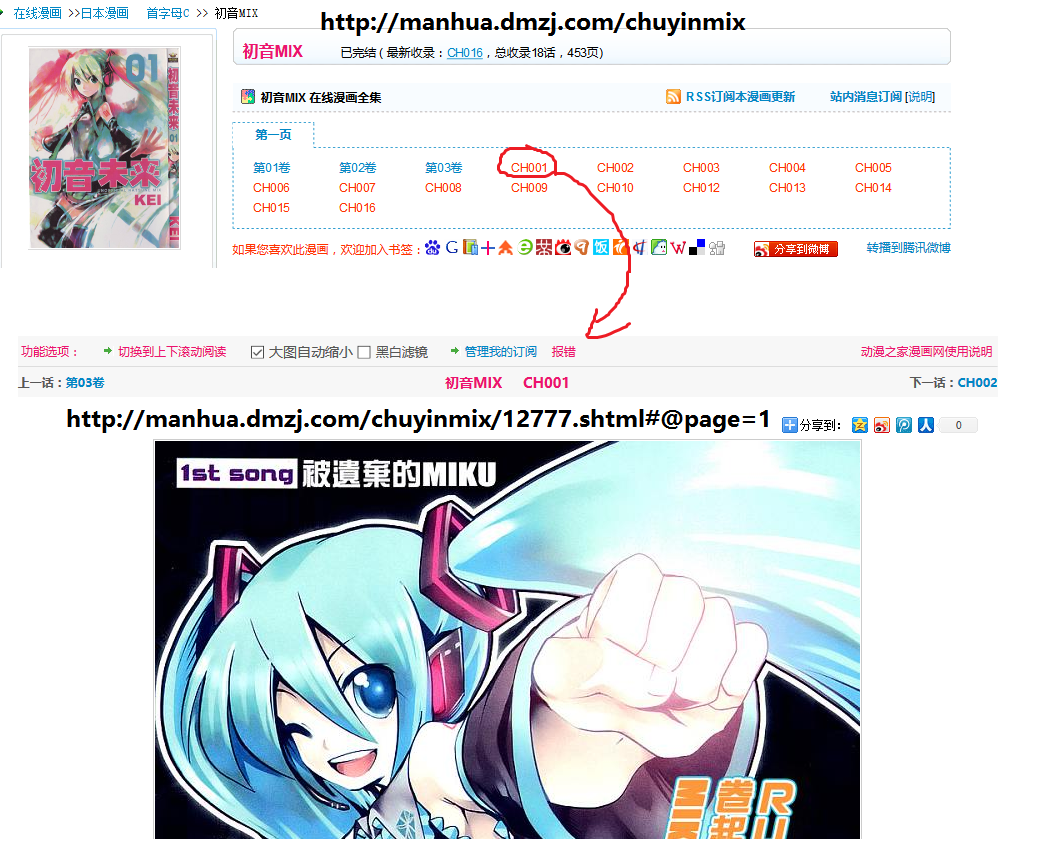
对图片网页进行分析(F12打开自带工具),以便我们查出图片的链接
很快查到图片链接及链接在代码中的位置
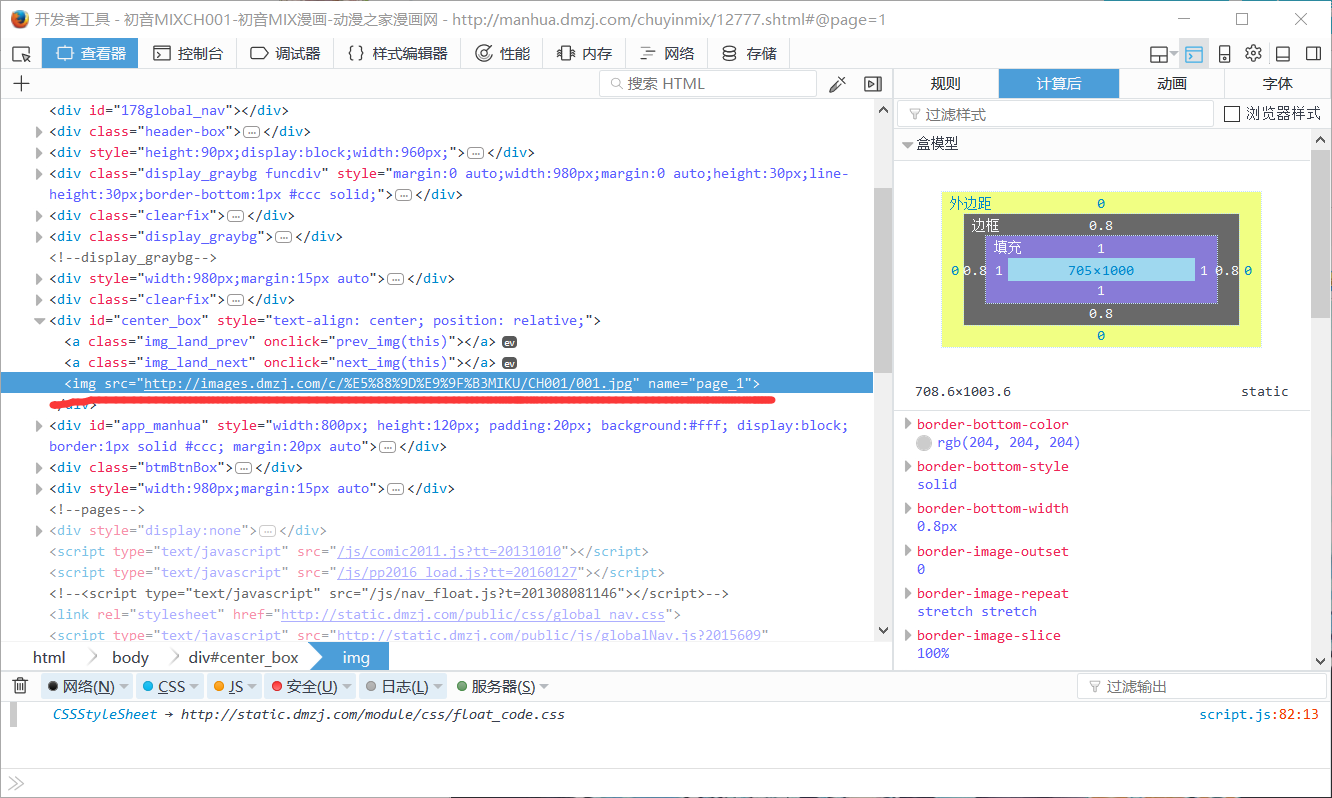
但是当我们查看源代码时,并没有找到此标签
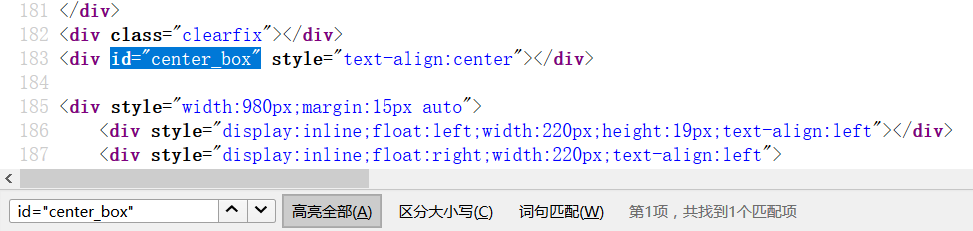 因为爬虫爬取的页面是静态的html文件,没有经过其他脚本的“加工”。所以动态的脚本之类是无法作用的(PhantomJS,Selenium之类除外)。但是作为爬虫入门文章,我们还是考虑“绕过”这种烦人的东西,“绕过”方法作为一个小技巧
因为爬虫爬取的页面是静态的html文件,没有经过其他脚本的“加工”。所以动态的脚本之类是无法作用的(PhantomJS,Selenium之类除外)。但是作为爬虫入门文章,我们还是考虑“绕过”这种烦人的东西,“绕过”方法作为一个小技巧
技巧一:若爬取网页较困难时,尝试爬取手机网页
很轻松的找到手机的检索地址http://m.dmzj.com/search/初音mix.html
它的界面是这样的
 (手机上的网站在电脑上看真low。。。)
(手机上的网站在电脑上看真low。。。)
很轻松的找到详细页面http://m.dmzj.com/info/chuyinmix.html
这时再打开CH001,查看网页源代码,找到这么一段
mReader.initData({"id":12777,"comic_id":6132,"chapter_name":"CH001","chapter_order":10,"createtime":1284436621,
"folder":"c\/\u521d\u97f3MIKU\/CH001","page_url":["https:\/\/images.dmzj.com\/c\/\u521d\u97f3MIKU\/CH001\/001.jpg",
"https:\/\/images.dmzj.com\/c\/\u521d\u97f3MIKU\/CH001\/002.png", ...
这么明显的地址,真的是毫无防备。。。
那么我们找到了图片位置,可以开始爬取了
Step2:从检索页面到详细页面再到图片页面,进行爬取
通过简单的操作得到python代码
#!usr/bin/env python
#coding=utf-8
import requests, re
from bs4 import BeautifulSoup headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Referer":"http://m.dmzj.com/"}
url="http://m.dmzj.com/info/chuyinmix.html"
html=requests.get(url, headers=headers)
soup=BeautifulSoup(html.content, "lxml")
print(soup.prettify())
这里简单的介绍一下最常见的,最基础的,同时也最容易被绕过的反爬虫操作
在Http协议中,客户端通过发送Http请求头来请求网页。
在python等程序或脚本发送的请求头中user-agent并非像浏览器的一样,他们就像是“python-requests/2.14.2”。
而一般浏览器的user-agent就像“Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0”。
这样服务器就可以通过user-agent来区别爬虫和浏览器。
但是我们也可以通过修改请求头来绕过,然而服务器也不傻,他们又顺便检查了请求头Referer这一项。
Referer指的是浏览器通过哪一页面打开当前页面。
就像通过百度搜索“初音我老婆”,任意点开一个页面时Referer就记录着百度搜索结果的页面地址。
当然我们也可以修改Referer呵呵。
运行后可以看到此页面的源代码。
这时通过正则表达式来查找所需内容。
#!usr/bin/env python
#coding=utf-8
import requests, re headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Referer":"http://m.dmzj.com/"}
urlRoot="http://m.dmzj.com/info/chuyinmix.html"
urlPre="http://m.dmzj.com/view/6132/"
html=requests.get(urlRoot, headers=headers)
nameList=re.findall('(?<=chapter_name":")[^"]+', html.text);
idList=re.findall('(?<="id":)[^,]+', html.text);
for i in range(15):
url=urlPre+idList[i]+".html"
html=requests.get(url, headers=headers)
print(html.text)
运行结果显示没问题,于是开始尝试爬取一张图片
#!usr/bin/env python
#coding=utf-8
import requests, re, os headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Referer":"http://m.dmzj.com/"}
urlRoot="http://m.dmzj.com/info/chuyinmix.html"
urlPre="http://m.dmzj.com/view/6132/"
html=requests.get(urlRoot, headers=headers)
nameList=re.findall('(?<=chapter_name":")[^"]+', html.text);
idList=re.findall('(?<="id":)[^,]+', html.text);
for i in range(15):
url=urlPre+idList[i]+".html"
html=requests.get(url, headers=headers)
print(html.text)
urlList=re.findall('https:\\\\/\\\\/[^"]+', html.text)
for idx, string in enumerate(urlList):
img=requests.get(string.replace(r"\/", "/").encode().decode("unicode-escape"), headers=headers)
ext=string.split(".")[-1]
if not os.path.exists(nameList[i]):
os.mkdir(nameList[i])
file=open(nameList[i]+"\%03d.%s"%(idx, ext), "ab")
file.write(img.content)
file.close()
break
break
技巧二:利用str.encode().decode("unicode-escape")转换url中的Unicode编码看来成功了呵呵 >_<
于是放开手脚,全部爬取
#!usr/bin/env python
#coding=utf-8
import requests, re, os headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Referer":"http://m.dmzj.com/"}
urlRoot="http://m.dmzj.com/info/chuyinmix.html"
urlPre="http://m.dmzj.com/view/6132/"
html=requests.get(urlRoot, headers=headers)
nameList=re.findall('(?<=chapter_name":")[^"]+', html.text);
idList=re.findall('(?<="id":)[^,]+', html.text);
for i in range(15):
url=urlPre+idList[i]+".html"
html=requests.get(url, headers=headers)
urlList=re.findall('https:\\\\/\\\\/[^"]+', html.text)
for idx, string in enumerate(urlList):
img=requests.get(string.replace(r"\/", "/").encode().decode("unicode-escape"), headers=headers)
ext=string.split(".")[-1]
if not os.path.exists(nameList[i]):
os.mkdir(nameList[i])
file=open(nameList[i]+"\%03d.%s"%(idx, ext), "ab")
file.write(img.content)
file.close()
一分钟后,爬取成功>_<
总结本次爬取简单使用了python的requests, re, os库,简单介绍了HTTP请求头和最常见的反爬虫机制,纯属娱乐凑文章哈哈
Python爬虫简单入门及小技巧的更多相关文章
- python爬虫抓站的一些技巧总结
使用python爬虫抓站的一些技巧总结:进阶篇 一.gzip/deflate支持现在的网页普遍支持gzip压缩,这往往可以解决大量传输时间,以VeryCD的主页为例,未压缩版本247K,压缩了以后45 ...
- 转载:用python爬虫抓站的一些技巧总结
原文链接:http://www.pythonclub.org/python-network-application/observer-spider 原文的名称虽然用了<用python爬虫抓站的一 ...
- 用python爬虫抓站的一些技巧总结 zz
用python爬虫抓站的一些技巧总结 zz 学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自动收邮件的脚本, ...
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- [转]用python爬虫抓站的一些技巧总结 zz
来源网站:http://www.pythonclub.org/python-network-application/observer-spider 学用python也有3个多月了,用得最多的还是各类爬 ...
随机推荐
- Unity脚本生命周期 图解
简单总结的话就是: Awake():初始化时执行,类似c#中的构造函数 OnEnable() Start() FixUpdate() Update() OnDisable() OnDestory() ...
- Unity 烘焙的2种方式
游戏场景通常有许多光源,使用实时渲染会非常消耗性能,解决办法是烘焙,烘焙有2种方式. 1, 在3dmax等模型制作软件中对场景进行烘焙.将烘焙好的模型以及贴图导入到unity3d. 相对复杂但效果好 ...
- ABBYY迎国庆·庆中秋限时折扣狂潮,再来一波
继ABBYY 早秋限时活动之后,ABBYY官方为迎国庆,庆中秋,折扣狂潮,又来一波.上次活动由于时间短,任务急,数量少,使得不少小伙伴抱憾而止,选择默默等待良机.现在,良机来了,即便没有上次的打折力度 ...
- 使用RestTemplate上传文件给远程接口
MultiValueMap request = new LinkedMultiValueMap(1); ByteArrayResource is = new ByteArrayResource(mul ...
- LeetCode Golang 9.回文数
9. 回文数 第一种办法 :itoa 转换为字符串进行处理: package main import ( "strconv" "fmt" ) //判断一个整数是 ...
- Eclipse本地创建新的GIT分支,并推送至远程Git分支
本地创建新的GIT分支: 1.右击要创建新分支的项目——Team——Switch To——New Branch…: 2.在弹出的对话框中name框中输入要创建的分支名称,(如果是当前显示的要拷贝的分支 ...
- CSS布局总结(一)
前言:今天是学校为期六周的实训第一天,实训课感觉很水,第一天讲的竟然是HTML...实训老师丢了一个静态页面给我们做.感觉很久没写过这种东西,突然觉得自己的基本功很渣.布局这方面感觉需要总结一下,然后 ...
- NetApp 存储的常用概念普及
NetApp 存储的常用概念和命令1. Volume 和qtree卷(volume)是filer 上的一个基本空间单位,它可以是基于aggr划出的灵活卷(flexvol),也可以是直接由物理盘组成的传 ...
- Spring+Mybatis+SpringMVC后台与前台分页展示实例
摘要:本文实现了一个后台由spring+Mybatis+SpringMVC组成,分页采用PageHelper,前台展示使用bootstrap-paginator来显示效果的分页实例.整个项目由mave ...
- 今天修了一个bug,关于debug日志的问题
是别人的代码,很诡异. 就是开了debug日志,没问题. 关了debug日志,就出问题. 开始我以为是debug日志拖慢了速度,所以有一些竞态环境的影响. 后来发现是在debug日志里面有一些side ...