Online ML那点事>-
一:译自wiki:
|
|
KeyWord:标签反馈; |
Survey:
online machine learning is a model of induction that learns one instance at a time. The goal in on-line learning is to predict labels for instances. For example, the instances could describe the current conditions of thestock
market, and an online algorithm predicts tomorrow's value of a particular stock. The key defining characteristic of on-line learning is that soon after the prediction is made, the true label of the instance is discovered. This information can then be used
to refine the prediction hypothesis used by the algorithm. The goal of the algorithm is to make predictions that are close to the true labels.
在线机器学习一次学习一个模型。其目标是预测实例的标签。比如:实例可以形容为股票市场的现状,在线学习算法预测特定条件下股票明天的值;在线学习的关键特征是在预测被确定不就之后,实例被贴上标签。这种信息可以用来更行算法的参数假设。算法的目标是尽可能的使预测贴近真实标签;(用标签实例来更新模型?只更新模型的少量参数,而不必重新训练整个模型)。
More formally, an online algorithm proceeds in a sequence of trials. Each trial can be decomposed into three steps. First the algorithm receives an instance. Second the algorithm predicts the label of the instance. Third the algorithm receives the true label
of the instance.[1] The third stage is the most crucial as the algorithm can
use this label feedback to update its hypothesis for future trials. The goal of the algorithm is to minimize some performance criteria. For example, with stock market prediction the algorithm may attempt to minimize sum of the square distances between
the predicted and true value of a stock. Another popular performance criterion is to minimize the number of mistakes when dealing with classification problems. In addition to applications of a sequential nature, online learning algorithms are also relevant
in applications with huge amounts of data such that traditional learning approaches that use the entire data set in aggregate are computationally infeasible.
更一般化的说,在线学习算法有一些列方法,每种方法都可分解为以下几步:首先,算法接受一个实例;接着算法预测实例的标签;第三 算法接受实例的真实标签(有正确和错误之分,根据结果来调整算法)。第三步比较重要,因为算法根据标签反馈来更新算法参数,来更新未来试验预测的假设。 算法的目的是最小化某些性能标准(?)。例如,在股票市场,算法尝试最小化股票预测和现实股票真实值的偏差(整个模型是动态的)。可以用来处理那些数据量太大而计算能力不能一次性处理整个训练集的情况。(有没有觉得像人的学习过程,一个一个,而不是简单背规则,然后错了就错了)
Because on-line learning algorithms continually receive label feedback, the algorithms are able to adapt and learn in difficult situations. Many online algorithms can give strong guarantees on performance even when the instances are not generated by a distribution.
As long as a reasonably good classifier exists, the online algorithm will learn to predict correct labels. This good classifier must come from a previously determined set that depends on the algorithm. For example, two popular on-line algorithmsperceptron
and winnow can perform well when a hyperplane exists that splits the data into two categories. These algorithms can even be modified to do provably well even if the hyperplane is allowed to infrequently change during the on-line learning trials.
因为算法不断的接受标签反馈,算法可以适应困难条件下的学习。许多在线学习算法可以在实例由于干扰而没有被生成的时也有良好表现。一旦良好的分类器被建立,算法感知器可以预测正确标签。算法必须依赖于已存的良好算法。比如现存的两个流行算法感知器和winnow在一个二分类超平面存在时可以表现良好。这些算法甚至可以在分裂反馈之后被修改。
Unfortunately, the main difficulty of on-line learning is also a result of the requirement for continual label feedback. For many problems it is not possible to guarantee that accurate label feedback will be available in the near future. For example, when
designing a system that learns how to do optical character recognition, typically some expert must label previous instances to help train the algorithm. In actual use of the OCR application, the expert is no longer available and no inexpensive outside source of accurate labels is available. Fortunately,
there is a large class of problems where label feedback is always available. For any problem that consists of predicting the future, an on-line learning algorithm just needs to wait for the label to become available. This is true in our previous example of
stock market prediction and many other problems.
在线学习的主要困难是不断的接受标签反馈。对于很多问题,它不能保证精确的标签反馈在不就之后被获得,当设计一个光学字符识别系统,一些专家必须保提前标签一些实例训练算法。标签的获得是困难的,也许在将来,我们的在线学习算法只需要等待足量的标签。
一个典型的在线监督学习算法:A prototypical online supervised learning algorithm
In the setting of supervised learning, or learning from examples, we are interested in learning a function , where
, where
is thought of as a space of inputs and as a space of outputs, that predicts well on instances that are drawn from a joint probability distribution
as a space of outputs, that predicts well on instances that are drawn from a joint probability distribution
on . In this setting, we are given aloss
. In this setting, we are given aloss
function  , such that
, such that
measures the difference between the predicted value and the true value
and the true value .
.
The ideal goal is to select a function , where
, where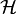
is a space of functions called a hypothesis space, so as to minimize the expected risk:

In reality, the learner never knows the true distribution over instances. Instead, the learner usually has access to a training set of examples
that are assumed to have been drawni.i.d. from the true distribution.
A common paradigm in this situation is to estimate a function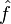 throughempirical
throughempirical
risk minimization or regularized empirical risk minimization (usuallyTikhonov regularization). The choice of loss function
here gives rise to several well-known learning algorithms such as regularizedleast squares andsupport
vector machines.
The above paradigm is not well-suited to the online learning setting though, as it requires complete a priori knowledge of the entire training set. In the pure online learning approach, the learning algorithm should update a sequence of functions
in a way such that the function depends only on the previous function
depends only on the previous function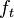
and the next data point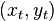 . This approach has low memory requirements in the sense that it only requires storage of a representation of the current
. This approach has low memory requirements in the sense that it only requires storage of a representation of the current
function and the next data point.
A related approach that has larger memory requirements allows to depend on
and all previous data points . We focus solely on the former approach here, and we consider both the case where the data
. We focus solely on the former approach here, and we consider both the case where the data
is coming from an infinite stream and the case where the data is coming from a finite training set,
and the case where the data is coming from a finite training set,
in which case the online learning algorithm may make multiple passes through the data.
总结:放个图,估计不会遭到批判:
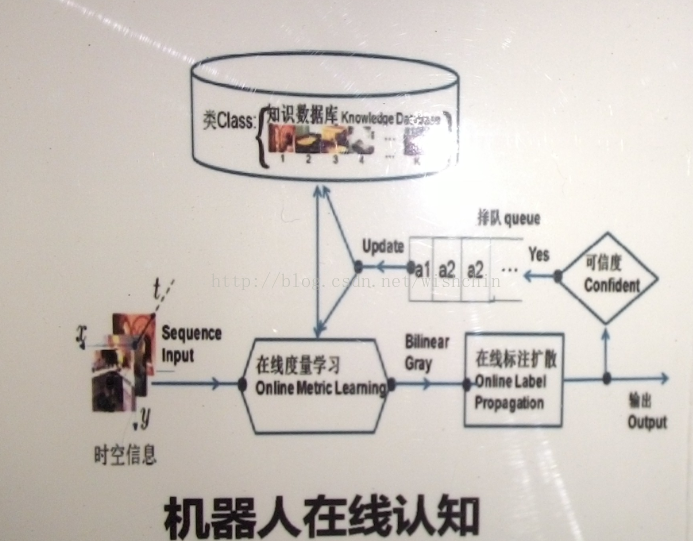
原文链接:http://blog.csdn.net/viewcode/article/details/9029043
机器学习:需要从已知的数据 学习出需要的模型;
在线算法:需要及时处理收集的数据,并给出预测或建议结果,并根据标签反馈,更新模型。
通用的在线学习算法步骤如下:
1. 收集和学习现有的数据;
2. 依据模型或规则,做出决策,给出结果;
3. 根据真实的结果,来训练和学习规则或模型。
常用的在线学习算法:
Perceptron: 感知器
PA: passive Perceptron
PA-I
PA-II
Voted Perceptron
confidence-weighted linear linear classification: 基于置信度加权的线性分类器
Weight Majority algorithm
AROW:adaptive regularization of weighted vector :加权向量的自适应正则化
"NHERD":Normal Herd 正态解群
一些算法伪代码,代码然后配上语言描述,就清晰多了.
感知器Perceptron:
线性分类器,是一个利用超平面来进行二分类的分类器,每次利用新的数据实例,预测,比对,更新,来调整超平面的位置。
相对于SVM,感知器不要每类数据与分类面的间隔最大化。

平均感知器Average Perceptron:
线性分类器,其学习的过程,与Perceptron感知器的基本相同,只不过,它将所有的训练过程中的权值都保留下来,然后,求均值。
优点:克服由于学习速率过大,所引起的训练过程中出现的震荡现象。即超平面围着一个中心,忽左忽右之类...
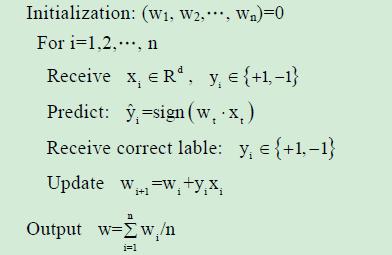
Passive Aggressive Perceptron:
修正权值时,增加了一个参数Tt,预测正确时,不需要调整权值,预测错误时,主动调整权值。并可以加入松弛变量的概念,形成其算法的变种。
优点:能减少错误分类的数目,而且适用于不可分的噪声情况。
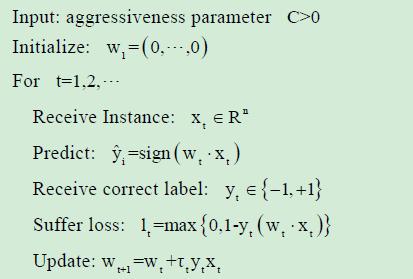
Tt 有三种计算方法:
a. Tt = lt / (||Xt||^2)
b. Tt = min{C, lt / ||Xt||^2}
c. Tt = lt / (||Xt||^2 + 1/(2C))
分别对应PA, PA-I, PA-II 算法,三种类型。
Voted Perceptron:
存储和使用所有的错误的预测向量。
优点:实现对高维数据的分类,克服训练过程中的震荡,训练时间比SVM要好。
缺点:不能保证收敛.

Confidence Weight:(线性分类器)
每个学习参数都有个信任度(概率),信任度小的参数更应该学习,所以会得到更频繁的修改机会。信任度,用参数向量的高斯分布表示。
权值w符合高斯分布N(u, 离差阵),而 由w*x的结果,可以预测其分类的结果。
并对高斯分布(的参数)进行更新。
这种方法能提供分类的准确性,并加快学习速度。其理论依据在在于算法正确的预测概率不小于高斯分布的一个值。

AROW: adaptive regularition of weighted vector
具有的属性:大间隔训练large margin training,置信度权值confidence weight,处理不可分数据(噪声)non-separable
相对于SOP(second of Perceptron),PA, CW, 在噪声情况下,其效果会更好.

Normal herding: (线性分类器)
NHerd算法在计算全协方差阵和对角协方差阵时,比AROW更加的积极。

Weight Majority:
每个维度都可以作为一个分类器,进行预测;然后,依据权值,综合所有结果,给出一个最终的预测。
依据最终的预测和实际测量结果,调整各个维度的权值,即更新模型。
易于实施,错误界比较小,可推导。

Voted Perceptron:
存储和使用所有的错误的预测向量。
优点:实现对高维数据的分类,克服训练过程中的震荡,训练时间比SVM要好。
缺点:不能保证收敛
以上Perceptron, PA, CW, AROW, NHerd都是Jubatus分布式在线机器学习 框架能提供的算法。
Jubatus与Mahout的异同?
两者都是针对分布式处理的机器学习算法库,有较强的伸缩性和运行在普通的硬件上。
但Mahout由于mapreduce的架构,对一些比较复杂的机器学习算法还无法及时支持,且对于实时在线处理数据流也支持比较弱。
Jubatus偏重于在线处理方式,具有较高吞吐量和低延迟的特点,这与Jubatus模型的同步和共享能力相关,并且Jubatus是将数据都是在内存中进行处理分析的。
http://en.wikipedia.org/wiki/Jubatus
Online ML那点事>-的更多相关文章
- PL真有意思(五):数据类型
前言 现在大多数程序设计语言中都有表达式和/或对象的类型概念.类型起着两种主要作用: 为许多操作提供了隐含的上下文信息,使程序员可以在许多情况下不必显示的描述这种上下文.比如int类型的两个对象相加就 ...
- 在生产中部署ML前需要了解的事
在生产中部署ML前需要了解的事 译自:What You Should Know before Deploying ML in Production MLOps的必要性 MLOps之所以重要,有几个原因 ...
- 痞子衡嵌入式:ARM Cortex-M内核那些事(3.3)- 为AI,ML而生(M55)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是ARM Cortex-M55. 鼠年春节,大家都在时刻关心 2019nCoV 疫情发展,没太多心思搞技术,就在这个时候,ARM 不声不响 ...
- CV牛人牛事简介之一
CV牛人牛事简介之一 [论坛按] 发帖人转载自:http://doctorimage.cn/2013/01/01/cv-intro-niubility/#6481970-qzone-1-83120-8 ...
- iOS 11: CORE ML—浅析
本文来自于腾讯Bugly公众号(weixinBugly),未经作者同意,请勿转载,原文地址:https://mp.weixin.qq.com/s/OWD5UEiVu5JpYArcd2H9ig 作者:l ...
- 使用ML.NET + Azure DevOps + Azure Container Instances打造机器学习生产化
介绍 Azure DevOps,以前称为Visual Studio Team Services(VSTS),可帮助个人和组织更快地规划,协作和发布产品.其中一项值得注意的服务是Azure Pipeli ...
- 使用ML.NET + ASP.NET Core + Docker + Azure Container Instances部署.NET机器学习模型
本文将使用ML.NET创建机器学习分类模型,通过ASP.NET Core Web API公开它,将其打包到Docker容器中,并通过Azure Container Instances将其部署到云中. ...
- 一位ML工程师构建深度神经网络的实用技巧
一位ML工程师构建深度神经网络的实用技巧 https://mp.weixin.qq.com/s/2gKYtona0Z6szsjaj8c9Vg 作者| Matt H/Daniel R 译者| 婉清 编辑 ...
- 机器学习规则:ML工程最佳实践----rule_of_ml section 3【翻译】
作者:黄永刚 ML Phase III: 缓慢提升.精细优化.复杂模型 第二阶段就已经接近结束了.首先你的月收益开始减少.你开始要在不同的指标之间做出平衡,你会发现有的涨了而有的却降了.事情变得有趣了 ...
随机推荐
- eas之视图冻结与解冻
// 冻结视图 table.getViewManager().freeze(verticalIndex, horizonIndex); //冻结视图:该方法在table还没显示的时候使用,也就是该方法 ...
- 【剑指Offer】15、反转链表
题目描述: 输入一个链表,反转链表后,输出新链表的表头. 解题思路: 本题比较简单,有两种方法可以实现:(1)三指针.使用三个指针,分别指向当前遍历到的结点.它的前一个结点以及后一个结 ...
- Django链接Mysql 8.0 出现错误(1045:Access denied for user 'root'@'localhost' (using password: NO) 的一种解决方法
运行环境: Django版本2.0 ; Mysql 版本 8.0.11; 错误代码: django.db.utils.OperationalError: (1045:Access denied fo ...
- Java设计模式之 — 单例(Singleton)
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/8860649 写软件的时候经常需要用到打印日志功能,可以帮助你调试和定位问题,项目上 ...
- SpringCloud Config 分布式配置中心
一.分布式系统面临的问题---配置问题 微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量服务.由于每个服务都需要必要的配置信息才能运行,所以一套集中式的 ...
- MySQL Workbench常用快捷键及修改快捷键的方法
常用快捷键: 1.执行整篇sql脚本:[Ctrl]+[Shift]+[Enter] 2.执行当前行:[Ctrl]+[Enter] 3.注释/取消注释:[Ctrl]+[/] 4.格式化sql语句(美化s ...
- MySQL出现no mycat database selected的问题分析
1.先抛开mycat来处理 2.在查询表时,要指定是哪个数据库,然后再查询. ①.如果再MySQL Workbench中,先使用use tablename;,然后在执行操作语句:或者在语句上指定要查询 ...
- java 线程 错失的信号、notify() 与notifyAll的使用
package org.rui.thread.block; import java.util.Timer; import java.util.TimerTask; import java.util.c ...
- Fitnesse Page 简单使用
more information- http://www.fitnesse.org/FitNesse.UserGuide 1.1 Edit 点击该按钮,则可以开始编辑(如果该按钮没有出现,则这个页 ...
- u-boot学习(五):u-boot启动内核
u-boot的目的是启动内核.内核位于Flash中,那么u-boot就要将内核转移到内存中.然后执行命令执行之.这些操作是由bootcmd命令完毕的. bootcmd=nand read.jffs2 ...