Sparse Autoencoder(一)
Neural Networks
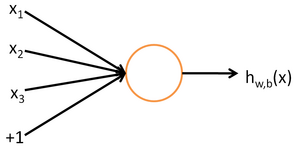
We will use the following diagram to denote a single neuron:
This "neuron" is a computational unit that takes as input x1,x2,x3 (and a +1 intercept term), and outputs
, where
is called the activation function. In these notes, we will choose
to be the sigmoid function:
Thus, our single neuron corresponds exactly to the input-output mapping defined by logistic regression.
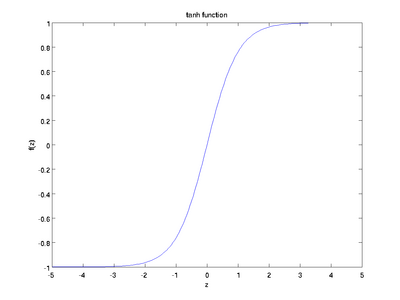
Although these notes will use the sigmoid function, it is worth noting that another common choice for f is the hyperbolic tangent, or tanh, function:
Here are plots of the sigmoid and tanh functions:
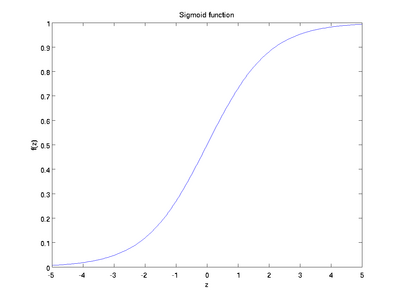
Finally, one identity that'll be useful later: If f(z) = 1 / (1 + exp( − z)) is the sigmoid function, then its derivative is given by f'(z) = f(z)(1 − f(z))
sigmoid 函数 或 tanh 函数都可用来完成非线性映射
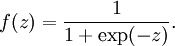
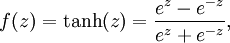
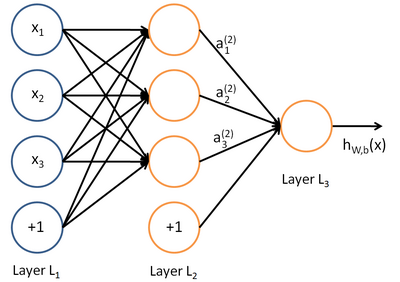
Neural Network model
A neural network is put together by hooking together many of our simple "neurons," so that the output of a neuron can be the input of another. For example, here is a small neural network:
In this figure, we have used circles to also denote the inputs to the network. The circles labeled "+1" are called bias units, and correspond to the intercept term. The leftmost layer of the network is called the input layer, and the rightmost layer the output layer (which, in this example, has only one node). The middle layer of nodes is called the hidden layer, because its values are not observed in the training set. We also say that our example neural network has 3 input units (not counting the bias unit), 3 hidden units, and 1 output unit.
Our neural network has parameters (W,b) = (W(1),b(1),W(2),b(2)), where we write
to denote the parameter (or weight) associated with the connection between unit j in layer l, and unit i in layerl + 1. (Note the order of the indices.) Also,
is the bias associated with unit i in layer l + 1.
We will write
to denote the activation (meaning output value) of unit i in layer l. For l = 1, we also use
to denote the i-th input. Given a fixed setting of the parameters W,b, our neural network defines a hypothesis hW,b(x) that outputs a real number. Specifically, the computation that this neural network represents is given by:
每层都是线性组合 + 非线性映射
In the sequel, we also let
denote the total weighted sum of inputs to unit i in layer l, including the bias term (e.g.,
), so that
.
Note that this easily lends itself to a more compact notation. Specifically, if we extend the activation function
We call this step forward propagation.
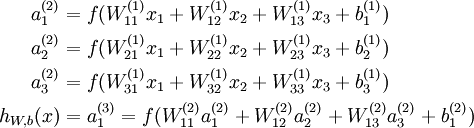
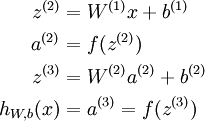
Backpropagation Algorithm
for a single training example (x,y), we define the cost function with respect to that single example to be:
This is a (one-half) squared-error cost function. Given a training set of m examples, we then define the overall cost function to be:
J(W,b;x,y) is the squared error cost with respect to a single example; J(W,b) is the overall cost function, which includes the weight decay term.
Our goal is to minimize J(W,b) as a function of W and b. To train our neural network, we will initialize each parameter
will be the same for all values of i, so that
for any input x). The random initialization serves the purpose of symmetry breaking.
One iteration of gradient descent updates the parameters W,b as follows:
The two lines above differ slightly because weight decay is applied to W but not b.
The intuition behind the backpropagation algorithm is as follows. Given a training example (x,y), we will first run a "forward pass" to compute all the activations throughout the network, including the output value of the hypothesis hW,b(x). Then, for each node i in layer l, we would like to compute an "error term"
that measures how much that node was "responsible" for any errors in our output.
For an output node, we can directly measure the difference between the network's activation and the true target value, and use that to define
(where layer nl is the output layer). For hidden units, we will compute
- 1,Perform a feedforward pass, computing the activations for layers L2, L3, and so on up to the output layer
.
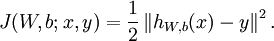
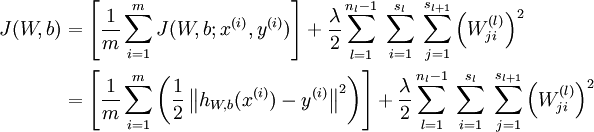
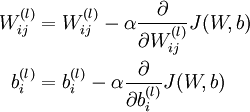
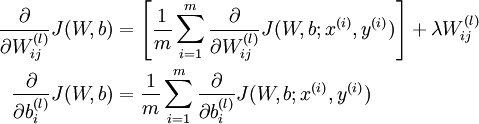
2,For each output unit i in layer nl (the output layer), set
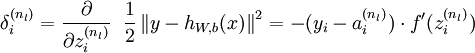
For
For each node i in layer l, set
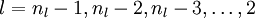
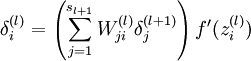
4,Compute the desired partial derivatives, which are given as:
We will use "
" to denote the element-wise product operator (denoted ".*" in Matlab or Octave, and also called the Hadamard product), so that if
, then
. Similar to how we extended the definition of
to apply element-wise to vectors, we also do the same for
(so that
).
The algorithm can then be written:
- 1,Perform a feedforward pass, computing the activations for layers
,
, up to the output layer
, using the equations defining the forward propagation steps
2,For the output layer (layer
), set
3,For
- Set
4,Compute the desired partial derivatives:
Implementation note: In steps 2 and 3 above, we need to compute
for each value of
. Assuming
is the sigmoid activation function, we would already have
stored away from the forward pass through the network. Thus, using the expression that we worked out earlier for
, we can compute this as
.
Finally, we are ready to describe the full gradient descent algorithm. In the pseudo-code below,
is a matrix (of the same dimension as
), and
is a vector (of the same dimension as
). Note that in this notation, "
times
- 1,Set
,
(matrix/vector of zeros) for all
.
- 2,For
to
,
- Use backpropagation to compute
and
.
- Set
.
- Set
.
- 3,Update the parameters:
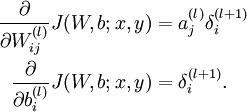
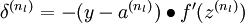
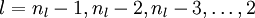
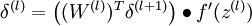
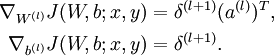
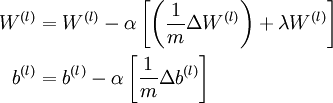
Sparse Autoencoder(一)的更多相关文章
- Deep Learning 1_深度学习UFLDL教程:Sparse Autoencoder练习(斯坦福大学深度学习教程)
1前言 本人写技术博客的目的,其实是感觉好多东西,很长一段时间不动就会忘记了,为了加深学习记忆以及方便以后可能忘记后能很快回忆起自己曾经学过的东西. 首先,在网上找了一些资料,看见介绍说UFLDL很不 ...
- (六)6.5 Neurons Networks Implements of Sparse Autoencoder
一大波matlab代码正在靠近.- -! sparse autoencoder的一个实例练习,这个例子所要实现的内容大概如下:从给定的很多张自然图片中截取出大小为8*8的小patches图片共1000 ...
- UFLDL实验报告2:Sparse Autoencoder
Sparse Autoencoder稀疏自编码器实验报告 1.Sparse Autoencoder稀疏自编码器实验描述 自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值, ...
- 七、Sparse Autoencoder介绍
目前为止,我们已经讨论了神经网络在有监督学习中的应用.在有监督学习中,训练样本是有类别标签的.现在假设我们只有一个没有带类别标签的训练样本集合 ,其中 .自编码神经网络是一种无监督学习算法,它使用 ...
- CS229 6.5 Neurons Networks Implements of Sparse Autoencoder
sparse autoencoder的一个实例练习,这个例子所要实现的内容大概如下:从给定的很多张自然图片中截取出大小为8*8的小patches图片共10000张,现在需要用sparse autoen ...
- 【DeepLearning】Exercise:Sparse Autoencoder
Exercise:Sparse Autoencoder 习题的链接:Exercise:Sparse Autoencoder 注意点: 1.训练样本像素值需要归一化. 因为输出层的激活函数是logist ...
- Sparse AutoEncoder简介
1. AutoEncoder AutoEncoder是一种特殊的三层神经网络, 其输出等于输入:\(y^{(i)}=x^{(i)}\), 如下图所示: 亦即AutoEncoder想学到的函数为\(f_ ...
- Exercise:Sparse Autoencoder
斯坦福deep learning教程中的自稀疏编码器的练习,主要是参考了 http://www.cnblogs.com/tornadomeet/archive/2013/03/20/2970724 ...
- DL二(稀疏自编码器 Sparse Autoencoder)
稀疏自编码器 Sparse Autoencoder 一神经网络(Neural Networks) 1.1 基本术语 神经网络(neural networks) 激活函数(activation func ...
- sparse autoencoder
1.autoencoder autoencoder的目标是通过学习函数,获得其隐藏层作为学习到的新特征. 从L1到L2的过程成为解构,从L2到L3的过程称为重构. 每一层的输出使用sigmoid方法, ...
随机推荐
- tload---显示系统负载
tload命令以图形化的方式输出当前系统的平均负载到指定的终端.假设不给予终端机编号,则会在执行tload指令的终端机显示负载情形. 语法 tload(选项)(参数) 选项 -s:指定闲时的刻度: - ...
- Redis批量执行(如list批量添加)命令工具 —— pipeline管道应用
前言 Redis使用的是客户端-服务器(CS)模型和请求/响应协议的TCP服务器.这意味着通常情况下一个请求会遵循以下步骤: 使用Redis管道提升性能 (1)客户端向服务端发送一个查询请求,并监听S ...
- 数据库中Select For update语句的解析
----------- Oracle -----------------– Oracle 的for update行锁 键字: oracle 的for update行锁 SELECT-FOR UPDAT ...
- 洛谷—— P1003 铺地毯
https://www.luogu.org/problem/show?pid=1003 题目描述 为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形 ...
- Chrome无界面浏览模式与自定义插件加载问题
环境:Python 3.5.x + Selenium 3.4.3 + Chromedriver 2.30 + Chrome 60 beta或Chromium Canary 61 + WIN10 Chr ...
- hadoop云盘client的设计与实现(一)
近期在hadoop云盘client项目.在做这个项目曾经对hadoop是一点都不了解呀,在网上查了好久.将client开发的是非常少的,在做这个项目的过程中遇到非常多奇葩的问题. 并且试图换过好多方案 ...
- HDOJ 5411 CRB and Puzzle 矩阵高速幂
直接构造矩阵,最上面一行加一排1.高速幂计算矩阵的m次方,统计第一行的和 CRB and Puzzle Time Limit: 2000/1000 MS (Java/Others) Memory ...
- Android带索引联系人列表
网上Android联系人列表的样例也非常多,都和微信的联系人差点儿相同,因为项目用到了联系人列表索引功能(产品把字母item给去掉了),只是也还是好实现.这里我也来分享分享我的实现,免得以后忘了.那先 ...
- swift具体解释之八---------------下标脚本
swift具体解释之八-----下标脚本 下标脚本 能够定义在类(Class).结构体(structure)和枚举(enumeration)这些目标中.能够觉得是訪问对象.集合或序列的快捷方式.不须要 ...
- LSTM模型
摘自:http://www.voidcn.com/article/p-ntafyhkn-zc.html (二)LSTM模型 1.长短期记忆模型(long-short term memory)是一种特殊 ...