Spark详解(02) - Spark概述
Spark详解(02) - Spark概述
什么是Spark
Hadoop主要解决,海量数据的存储和海量数据的分析计算。
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Hadoop与Spark历史
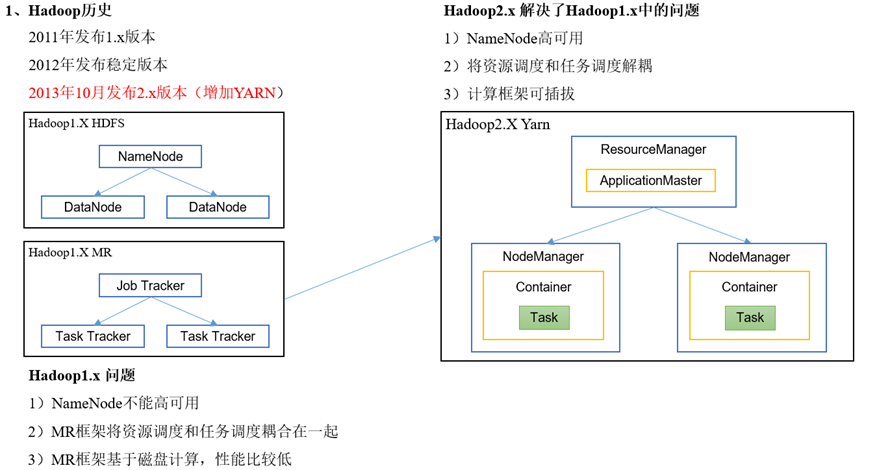
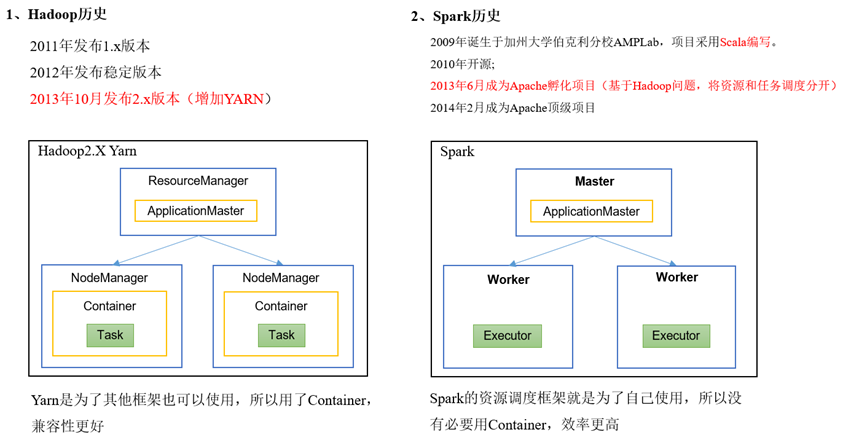
Hadoop的Yarn框架比Spark框架诞生的晚,所以Spark自己也设计了一套资源调度框架。
Hadoop与Spark框架对比
Spark内置模块
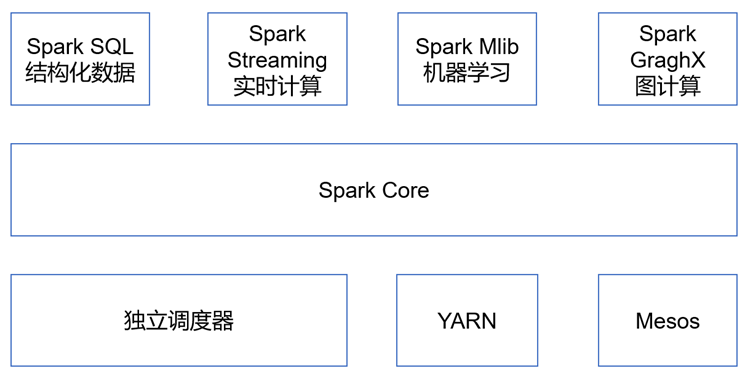
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据
导入等额外的支持功能。
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
Spark特点
1)快:与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中的。
2)易用:Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便地在这些Shell中使用Spark集群来验证解决问题的方法。
3)通用:Spark提供了统一的解决方案。Spark可以用于,交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。减少了开发和维护的人力成本和部署平台的物力成本。
4)兼容性:Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。
Spark运行架构
运行架构
Spark框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
如下图所示,它展示了一个 Spark执行时的基本结构。图形中的Driver表示master,负责管理整个集群中的作业任务调度。图形中的Executor 则是 slave,负责实际执行任务。
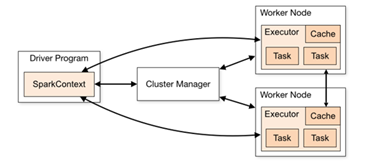
核心组件
Driver和Executor任务的管理者
Driver和Executor是临时程序,当有具体任务提交到Spark集群才会开启的程序。
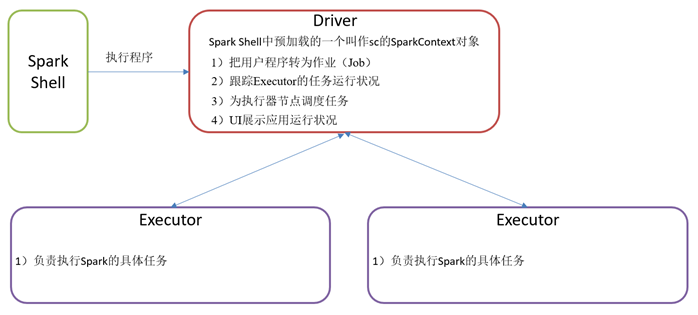
- Driver
Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业执行时主要负责:
将用户程序转化为作业(job)
在Executor之间调度任务(task)
跟踪Executor的执行情况
通过UI展示查询运行情况
实际上,我们无法准确地描述Driver的定义,因为在整个的编程过程中没有看到任何有关Driver的字眼。所以简单理解,所谓的Driver就是驱使整个应用运行起来的程序,也称之为Driver类。
- Executor
Spark Executor是集群中工作节点(Worker)中的一个JVM进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。
Executor有两个核心功能:
负责运行组成Spark应用的任务,并将结果返回给驱动器进程
它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
Master和Worker 集群资源管理
Spark集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master和Worker,这里的Master是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于Yarn环境中的RM, 而Worker呢,也是进程,一个Worker运行在集群中的一台服务器上,由Master分配资源对数据进行并行的处理和计算,类似于Yarn环境中NM。
Master:Spark特有资源调度系统的Leader。掌管着整个集群的资源信息,类似于Yarn框架中的ResourceManager。
Worker: Spark特有资源调度系统的Slave,有多个。每个Slave掌管着所在节点的资源信息,类似于Yarn框架中的NodeManager。
Master和Worker是Spark的守护进程、集群资源管理者,即Spark在特定模式下正常运行所必须的进程。
ApplicationMaster
Hadoop用户向YARN集群提交应用程序时,提交程序中应该包含ApplicationMaster,用于向资源调度器申请执行任务的资源容器Container,运行用户自己的程序任务job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
说的简单点就是,ResourceManager(资源)和Driver(计算)之间的解耦合靠的就是ApplicationMaster。
核心概念
Executor与Core(核)
Spark Executor是集群中运行在工作节点(Worker)中的一个JVM进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点Executor的内存大小和使用的虚拟CPU核(Core)数量。
应用程序相关启动参数如下:
|
名称 |
说明 |
|
--num-executors |
配置Executor的数量 |
|
--executor-memory |
配置每个Executor的内存大小 |
|
--executor-cores |
配置每个Executor的虚拟CPU core数量 |
并行度(Parallelism)
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。
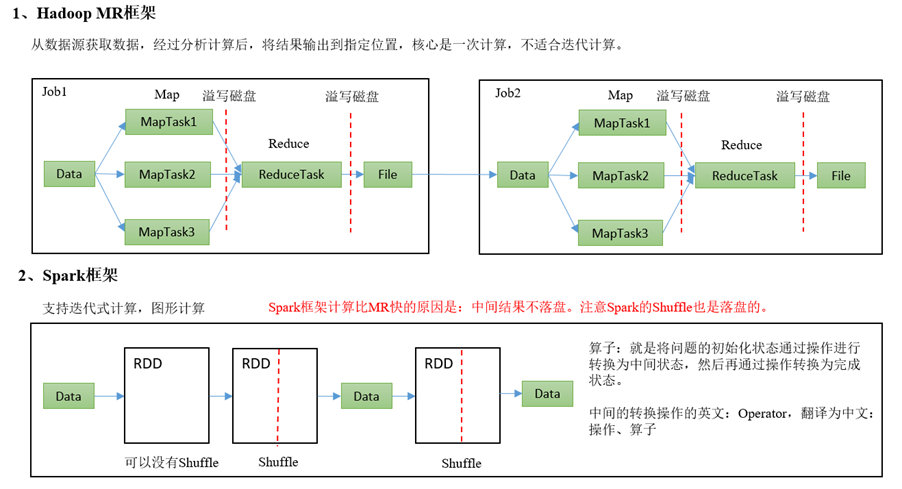
有向无环图(DAG)
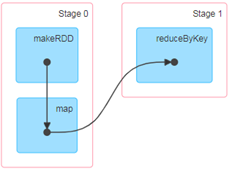
大数据计算引擎框架我们根据使用方式的不同一般会分为四类,其中第一类就是Hadoop所承载的MapReduce,它将计算分为两个阶段,分别为 Map阶段 和 Reduce阶段。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。 由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及实时计算。
这里所谓的有向无环图,并不是真正意义的图形,而是由Spark程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观,更便于理解,可以用于表示程序的拓扑结构。
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
提交流程
所谓的提交流程,其实就是开发人员根据需求写的应用程序通过Spark客户端提交给Spark运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,这里不进行详细的比较,但是因为国内工作中,将Spark引用部署到Yarn环境中会更多一些,所以本文的提交流程是基于Yarn环境的。
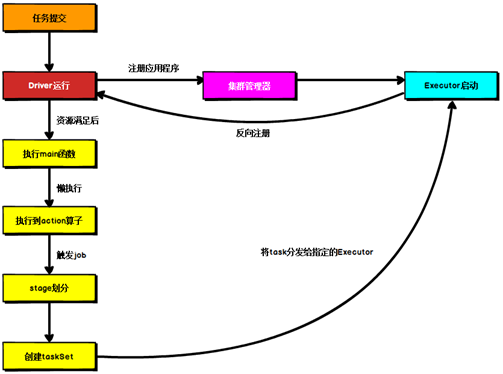
Spark应用程序提交到Yarn环境中执行的时候,一般会有两种部署执行的方式:Client和Cluster。两种模式主要区别在于:Driver程序的运行节点位置。
Yarn Client模式
Client模式将用于监控和调度的Driver模块在客户端执行,而不是在Yarn中,所以一般用于测试。
Driver在任务提交的本地机器上运行
Driver启动后会和ResourceManager通讯申请启动ApplicationMaster
ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,负责向ResourceManager申请Executor内存
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程
Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数
之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分stage,每个stage生成对应的TaskSet,之后将task分发到各个Executor上执行。
Yarn Cluster模式
Cluster模式将用于监控和调度的Driver模块启动在Yarn集群资源中执行。一般应用于实际生产环境。
在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,
随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程
Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,
之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分stage,每个stage生成对应的TaskSet,之后将task分发到各个Executor上执行。
Spark详解(02) - Spark概述的更多相关文章
- HTTP 权威指南 详解 ( 一、概述 )
HTTP 权威指南 详解 ( 一.概述 ) 最近在解读 <http权威指南> 这本书.之前对于http 的理解仅限于 知道我需要向服务端发送一个 get or post 请求,然后等待服务 ...
- Spark详解
原文连接 http://xiguada.org/spark/ Spark概述 当前,MapReduce编程模型已经成为主流的分布式编程模型,它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的 ...
- TCP/IP详解学习笔记- 概述
TCP/IP详解学习笔记(1)-- 概述1.TCP/IP的分层结构 网络协议通常分不同层次进行开发,每一层分别负责不同的同信功能.TCP/IP通常被认为是一个四层协议系统. 如图所 ...
- Linux用户、用户组权限管理详解 --- 02
2,用户.用户组管理操作详解: 2.1 adduser 添加用户: adduser [-u uid][-g group][-d home][-s shell] -u:直接给出userID ...
- Scala高手实战****第20课:Scala提取器、注解深度实战详解及Spark源码鉴赏
Spark中的源码的提取器和注解 @SparkContext.scala @ volatile 线程专用 保证线程间共享内容的一致性 @volatile private var _dagSchedul ...
- spark——详解rdd常用的转化和行动操作
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark第三篇文章,我们继续来看RDD的一些操作. 我们前文说道在spark当中RDD的操作可以分为两种,一种是转化操作(trans ...
- Web服务器项目详解 - 00 项目概述
目录 00 项目概述 01 线程同步机制包装类 02 半同步/半反应堆线程池(上) 03 半同步/半反应堆线程池(下) 04 http连接处理(上) 05 http连接处理(中) 06 http连接处 ...
- 翻译「C++ Rvalue References Explained」C++右值引用详解 Part1:概述
本文系对「C++ Rvalue References Explained」 该文的翻译,原文作者:Thomas Becker. 该文较详细的解释了C++11右值引用的作用和出现的意义,也同时被Scot ...
- Android Loader详解一:概述
装载器从android3.0开始引进.它使得在activity或fragment中异步加载数据变得简单.装载器具有如下特性: 它们对每个Activity和Fragment都有效. 他们提供了异步加载数 ...
- nmap详解之基础概述
概述 nmap是一个网络探测和安全扫描程序,系统管理者和个人可以使用这个软件扫描大型的网络,获取那台主机正在运行以及提供什么服务等信息.nmap支持很多扫描技术,例如:UDP.TCP connect( ...
随机推荐
- Python与Windows桌面
Python更换windows桌面 目录 Python更换windows桌面 前言 准备工作 代码 效果展示 Tips-如何更有仪式感 前言 每天下班,有时候会留下一些事情需要明天更进 为了防止忘记, ...
- [题解] Atcoder Regular Contest ARC 151 A B C D E 题解
点我看题 昨天刚打的ARC,题目质量还是不错的. A - Equal Hamming Distances 对于一个位置i,如果\(S_i=T_i\),那么不管\(U\)的这个位置填什么,对到\(S\) ...
- 一天十道Java面试题----第五天(spring的事务传播机制------>mybatis的优缺点)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 41.spring的事务传播机制 42 .spring事务什么时候会失效 43 .什么的是bean的自动装配.有哪些方式? ...
- 测试架构师CAP原理(最简单)
测试架构师CAP原理(最简单) 很多人都不是很了解CAP理论,其实CAP很简单,不要想复杂了! C:一致性,就是数据一致性,就是数据不出错! A:可用性,就是说速度快,不延迟,无论请求成功失败都很快返 ...
- <五>掌握左值引用和初识右值引用
1:C++的引用,引用和指针的区别? 1:从汇编指令角度上看,引用和指针没有区别,引用也是通过地址指针的方式访问指向的内存 int &b=a ; 是需要将a的内存地址取出并存下来, b=20; ...
- html页面跳转方式
js里的方法 第一种: window.location.href = XXXX; 第二种: window.setTimeout("javascript:location.href='xxxx ...
- FlinkSQL之Windowing TVF
Windowing TVF 在Flink1.13版本之后出现的替代之前的Group window的产物,官网描述其 is more powerful and effective //TVF 中的tu ...
- Vue报错:component has been registered but not used
原因: eslint代码检查到你注册了组件但没有使用,然后就报错了.比如代码: 比如Vue中注册了File组件,而实际上却没有使用到(直接取消注册为好): ... impor ...
- 如何在JavaScript中使用for循环
前言 循环允许我们通过循环数组或对象中的项并做一些事情,比如说打印它们,修改它们,或执行其他类型的任务或动作.JavaScript有各种各样的循环,for循环允许我们对一个集合(如数组)进行迭代. 在 ...
- PHP 模仿表单提交
function curl($url,$data,$headers){ $curl = curl_init(); // 启动一个CURL会话 curl_setopt($curl, CURLOPT_UR ...