谣言检测——(PSA)《Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks》
论文信息
论文标题:Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks
论文作者:Jiaying Wu、Bryan Hooi
论文来源:2022, arXiv
论文地址:download
论文代码:download
Abstract
开源的数据集存在虚假相关性,这种虚假相关性来自三个方面:
- event-based data collection and labeling schemes assign the same veracity label to multiple highly similar posts from the same underlying event;
- merging multiple data sources spuriously relates source identities to veracity labels;
- labeling bias;
在 event-separated 的设置下,现有最先进的模型准确性下降了 40% 以上,和简单的线性分类器差不多。本文为解决这个问题,提出了 Publisher Style Aggregation(PSA),是一种通用的方法,可以聚合发布者的发布信息,以及写作风格和立场等。
1 Introduction
现有数据集的构建过程中存在虚假的 属性-标签相关性。回顾基于事件的数据集采集框架,首先对事实有价值的事件自动检测,然后剔除大量包含相同事件关键词高度相似的微博。此外,一些基准数据集还通过合并现有多个源的数据样本,来平衡类分布。
忽略虚假信息会导致不公平的过度预测,从而限制了模型的泛化和适应性。在情绪分类、参数推理理解 和 事实验证 等一些自然语言处理任务中也发现了类似的问题,但社交媒体谣言检测的任务仍未得到充分的探索。
2 Spurious Correlations in Event-Based Datasets
2.1 Event-Based Data Collection
Newsworthy Event Selection
从具有权威的事实核查网络收集事件,或由专业人士确定候选事件。
Keyword-Based Microblog Retrieval
现有的数据集通常是基于事件的自动数据收集策略,即对每个事件:
- 从其 claim 中提取关键词;
- 通过基于关键词的搜索获取微博;
- 选择有影响力的微博;
事件关键字大多是中立的(例如,地点、人或对象),携带很少或没有立场。
Microblog Labeling Scheme
Event-level labeling assigns all source posts under an event with the same event-level factchecking label.
Post-level labeling annotates every source post independently.
2.2 Possible Causes of Spurious Correlations
在每个 Event 下,基于自动关键字的微博检索框架收集了大量具有相同标签的高度相似的关键词共享样本,甚至获得了相同的微博文本(Fig.1)。因此,事件关键字和类标签之间的相关性导致强文本线索,难以概括当前 Event 。

根据现有工程所采用的 post-level data splitting scheme,也就是使用关键词相关性对帖子进行收集。
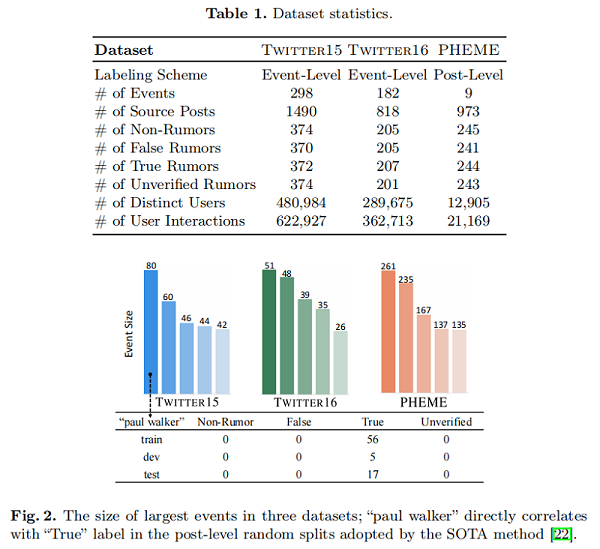
具体来说,前 5 个最大的事件覆盖了 PHEME 中 96.09% 的数据样本,而大型事件(包含超过5个关键词共享推文)覆盖了 Twitter 15 和 Twitter16 中超过70% 的样本。大的事件规模导致特定事件的 keyword-label 相关性的流行,进一步加剧了问题。
为了平衡标签,Twitter 15 和 Twitter16 合并了来自包括[4,12,16] 在内的多个来源的推文,并从经过验证的媒体账户中提取其他新闻事件。虽然不同的数据源所覆盖的事件不重叠,但数据源和标签之间的直接相关性可能会导致数据源特征和标签之间的虚假相关性。
如 Fig 3 所示,来自每个源的推文的 user interaction count(评论和转发)和 interaction time range of tweets 形成了不同的模式。例如,所有来自 PLOS_ONE 的推文都是“True”,传播得很快,往往会引起更少的互动。这些特定于源的传播模式可能被基于图或时间的模型所利用。

Labeling Bias
由于文本内容相似,简单的为其自动设置相同标签,会带来严重的标签偏差,举例如 Fig.4 所示:

3 Event-Separated Rumor Detection
3.1 Problem Formulation

现有的方法大多忽略了底层的 microblog-event 关系,采用了 event-mixed post-level data splits ,导致 $\mathcal{E}_{t r}$ 和 $\mathcal{E}_{t e}$ 之间存在显著的重叠。然而,在实践中,测试数据的先验知识并不总是得到保证(例如,模型从训练和测试数据中重复推文获得的性能收益不太可能推广),而以前的假设可能导致事件内文本相似性导致的性能高估。
为了消除这些混杂的事件特异性相关性,本文建议研究一个更实际的问题,即 event-separated rumor detection,其中 $\mathcal{E}_{t r} \cap \mathcal{E}_{t e}=\varnothing$。由于潜在的事件分布转移,这项任务具有挑战性,因此它提供了一种评估去偏谣言检测性能的方法。
3.2 Existing Approaches
Propagation-Based
(1) TD-RvNN
(2) GLAN
(3) BiGCN
(4) SMAN
Content-Based
(1) BERT
(2) XLNet
(3) RoBERTa
(4) DistilBERT
Data Splitting
对于所有三个数据集,我们抽取 10% 的实例进行验证,然后将剩下的 3:1 分成训练集和测试集。具体来说,分别根据 Twitter15、Twitter16、PHEME 上发布的公开事件 id 获得了事件分离分割。
3.3 SOTA Models’Performance is Heavily Overestimated
Fig.5 显示了事件混合和事件分离的谣言检测性能之间的鲜明对比。此外,尽管在所有三个数据集上具有最佳事件分离性能的一致性,但所有模型在 Twitter 15 和 Twitter16 上实现的事件混合性能都显著高于 PHEME,前者采用事件级标记,后者采用后级标记(见第1.1节)。这一差距与我们的假设相一致,即直接的 event-label 相关性会导致额外的偏差。
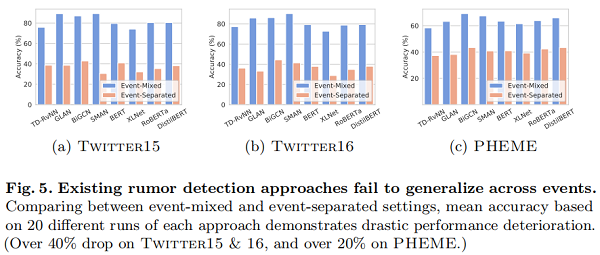
结果表明,现有的方法严重依赖于虚假的事件特异性相关性。尽管在事件混合设置下表现良好,但这些模型不能推广到看不见的事件,导致现实世界的适应性较差。
4 Proposed Method
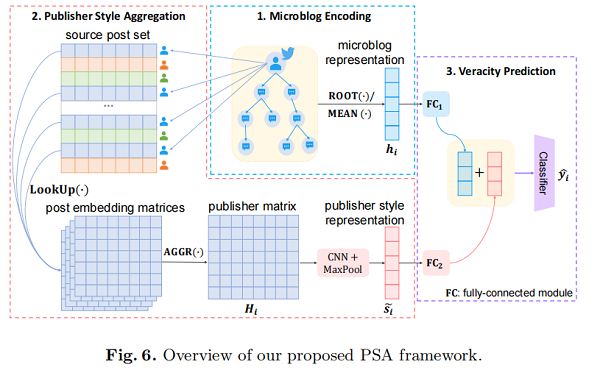
为了解决事件分离谣言检测的挑战,我们提出了 Publisher Style Aggregation(PSA),这是一种新的方法,可以根据每个出版商的聚合帖子来学习可推广的 publisher 特征,如 Fig.6 所示。
4.1 Consistency of Publisher Style
源帖子发布者是非常有影响力的用户。每个发布者独特的可信度立场和写作风格可以表现出独特的特征,这有助于决定他们的帖子的真实性。为了获得更直观的观点,我们在 Fig.7 中说明了Twitter15 发布者对每个类的倾向。
具体来说,对于发布者 $u$,我们定义了 $u$ 在class $c$ 下的 tendency score :
$\frac{ \text{ (microblogs posted by u under class c)}}{\text{(microblogs posted by u)}} $
Fig.7 显示,大多数发布者在一个特定类别上的得分要么接近 $0$,要么接近 $1$,即,大多数发布者倾向于在一个单一的真实性标签下发布微博,这验证了我们关于发布者风格一致性的假设。
4.2 Content-Based Microblog Encoding
在每个数据集中,所有的源文章和评论构成了一个大小为 |V| 的词汇表。在之后,我们将每个源特征特征 $\mathbf{r}_{i} \in \mathbb{R}^{|V|}$ 及其相关评论特征 $\mathbf{r}_{i}^{j} \in \mathbb{R}^{|V|}$ 表示为相应源特征或评论中所有 one-hot word vectors 的和。
RootText: Source post 是经过事实核查的,所以可以直接使用Souce Post 作为每个微博实例 $T_{i}$ 的表示—— $\mathbf{h}_{i}:=\mathbf{r}_{i}$
MeanText:我们还建议考虑用户的评论,以更稳健的可信度测量。在这里,我们采用均值池法将源帖子和评论特征压缩为微博表示:
$\mathbf{h}_{i}:=\frac{\mathbf{r}_{i}+\sum\limits _{j=1}^{k} \mathbf{r}_{i}^{j}}{k+1}$
我们获得了基于 RootText 或Meant的微博 $T_{i}$ 编码 $\mathbf{h}_{i} \in \mathbb{R}^{|V|}$,并通过具有 ReLU 激活函数的两层全连接神经网络提取高级特征 $\tilde{\mathbf{h}}_{i} \in \mathbb{R}^{n}$。然后,我们通过将 $\tilde{\mathbf{h}}_{i}$ 通过输出维数 $|\mathcal{C}|$ 的最终全连接层,防止过拟合进行精度预测。
4.3 Publisher Style Aggregation
如 4.1 节所示,在极具影响力的 source post 中,写作立场和可信度在固定的时间框架内保持相对稳定。受此启发,我们进一步提出了Publisher Style Aggregation(PSA),这是一种可推广的方法,它联合利用每个发布者产生的多个微博实例,并提取独特的发布者特征,以增强在每个微博中学习到的本地特征。更具体地说,
(1) 查找每个发布者生成的一组微博实例;
(2) 通过聚合这些源帖子的文本特征学习发布者的发布者风格表示 ;
(3) 增强每个微博的表示$\tilde{\mathbf{h}}_{i}$;
Publisher Style Modeling
假设发布者 $u_{i}$ 已经产生了 $m_{i} \geq 1$ 微博实例,相应的源帖子表示为 $\mathcal{P}\left(u_{i}\right)= \left\{p_{k} \mid u_{k}=u_{i}, k=1, \ldots, N\right\}$ ;注意,在训练期间只使用可访问的数据。我们将第 $j$ 个 帖子 $p_{i}^{j} \in \mathcal{P}\left(u_{i}\right)$ 视为一个最大长度为 $L$ 的词标记序列。然后,我们构造了一个基于可训练的 $d$ 维词嵌入的嵌入矩阵 $\mathbf{W}_{i}^{j} \in \mathbb{R}^{L \times d}$。我们聚合 $u_{i}$ 的所有后嵌入矩阵 $\mathbf{H}_{i} \in \mathbb{R}^{L \times d}$,得到相应的 publisher matrix $\mathbf{H}_{i} \in \mathbb{R}^{L \times d}$ 如下:
$\mathbf{H}_{i}=\operatorname{AGGR}\left(\left\{\mathbf{W}_{i}^{j}\right\}_{j=1}^{m_{i}}\right),$
其中,AGGR 运算符可以是 MEAN 或 SUM。
为了捕获 high-level publisher 的特征,我们对每个 $\mathbf{H}_{i}$ 应用卷积来提取潜在的发布者风格的特征。具体来说,我们使用三个具有不同窗口大小的卷积层来学习具有不同粒度的特征。每一层由F滤波器组成,每个过滤器输出一个特征映射 $\mathbf{f}_{*}=\left[f_{*}^{1}, f_{*}^{2}, \ldots, f_{*}^{L-k+1}\right]$,与
$f_{*}^{j}=\operatorname{ReLU}\left(\mathbf{W}_{f} \cdot \mathbf{H}_{i}[j: j+k-1]+b\right)$
其中 $\mathbf{W}_{f} \in \mathbb{R}^{k \times d}$ 为卷积核,$k$ 为窗口大小,$b \in \mathbb{R}$ 为偏差项。我们执行最大池化来提取每个 $\mathbf{f}_{*}$ 的最显著值,并将这些值堆栈以形成一个样式特征向量的 $\mathbf{s} \in \mathbb{R}^{F}$。然后,我们将三个 CNN 层产生的 $\mathbf{S}_{*}$ 连接起来,获得 $\tilde{\mathbf{s}}_{i} \in \mathbb{R}^{3 F}$:
$\tilde{\mathbf{s}}_{i}=\text { Concat }\left[\mathbf{s}_{1} ; \mathbf{s}_{2} ; \mathbf{s}_{3}\right] $
我们用相应的发布者风格表示 $\tilde{\mathbf{s}}_{i}$ 来增加微博表示 $\tilde{\mathbf{h}}_{i} \in \mathbb{R}^{n}$。最后,我们利用一个全连接层来预测微博的准确性标签 $\hat{\mathbf{y}}_{i}$:
$\hat{\mathbf{y}}_{i}=\operatorname{Softmax}\left(\mathbf{W}_{2}^{\top}\left(\tilde{\mathbf{h}}_{i}+\mathbf{W}_{1}^{\top} \tilde{\mathbf{s}}_{i}\right)\right)$
其中,转换 $\mathbf{W}_{1} \in \mathbb{R}^{3 F \times n}$ 和 $\mathbf{W}_{2} \in \mathbb{R}^{n \times|\mathcal{C}|}$。我们还在最后一层之前应用 dropout,以防止过拟合。通过最小化 $\hat{\mathbf{y}}_{i}$ 和真实标签 $y_{i}$ 之间的交叉熵损失来优化模型参数
5 Experiments
Model Performance
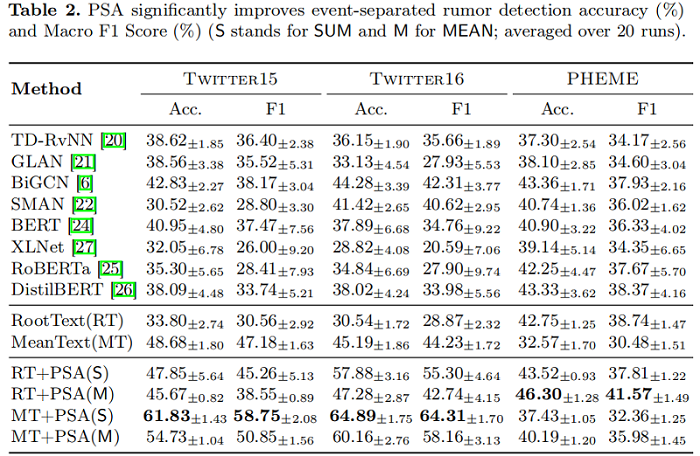
我们观察到,MeanText 在 Twitter15 和 Twitter16 上优于现有方法,而 RootText 的准确率仅比 PHEME 上的最佳基线低 0.6%。由于 PHEME 对每个微博独立贴标签,源帖子将包含最独特的特征。
我们提出的PSA方法,将 AGGR 实现为 SUM 或 MEAN,显著增强了 RootText 和 MEAN 基分类器。最佳的 PSA 组合比最佳基线表现更好;它们在 Twitter15 上的事件分离谣言检测准确率提高了19.00%,在 Twitter 16 上提高了 20.61%,在 PHEME 上提高了 2.94%。与现有的方法不同,PSA 显式地从多个事件中聚合了发布者风格的特性,从而增强了模型学习事件不变特征的能力。因此,PSA能够捕捉到与独特的出版商特征相关的立场和风格,从而导致实质性的性能改进。
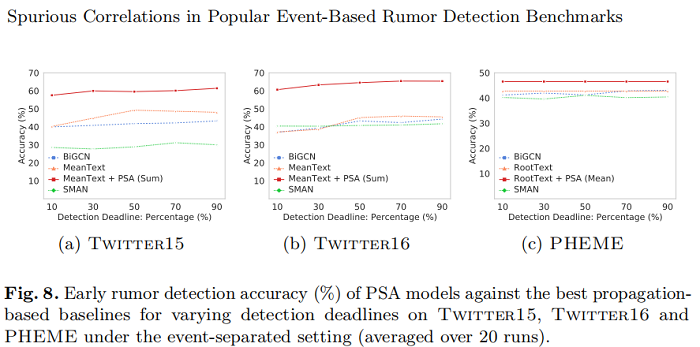
即使只有最早的 10% 的评论,PSA 在 Twitter15 上达到 57.53%,在 Twitter 16 上达到60.65%,在 PHEME 上达到46.30%。请注意,RootText(+PSA)模型在所有截止日期内都保持了稳定的性能,因为它们仅基于源帖子提供即时预测。结果表明,用 publisher style representations 的表示来增强谣言检测模型,达到了效率和有效性。
为了研究 PSA 的泛化能力,在 Twitter15 和 Wwitter16 上进行了跨数据集实验,其中模型在一个数据集上进行训练,在另一个数据集上进行测试。为了进行公平的比较,我们使用了相同的事件分离数据分割。如果来自数据集 $A$ 的训练集和来自数据集 $B$ 的测试集之间存在重叠事件,我们将删除训练集中与这些事件相关的所有实例,并将它们替换为从 $A$ 的测试集中随机抽样的相同数量的非重叠实例。
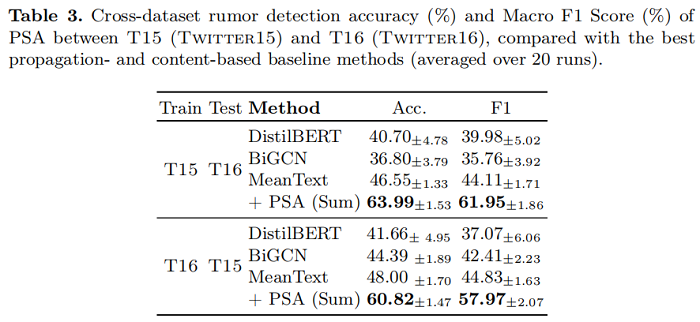
跨数据集设置本质上更具挑战性,因为训练和测试事件源于不同的时间框架,这可以产生时间概念的转移。然而,表3显示,PSA 在 Twitter15上的基础分类器,在Twitter16上分别提高了12.82%,这进一步证明了PSA对未知事件的通用性。
6 Conclusion
在本文中,我们系统地分析了基于事件的数据收集方案如何在社交媒体谣言检测基准数据集中创建特定于事件和源的虚假相关性。我们研究了事件分离谣言检测去除事件特定相关性的任务,并通过实证证明了现有方法的泛化能力的严重局限性。为了更好地解决这一任务,我们建议PSA使用聚合的发布者风格的特性来增强微博表示。在三个真实数据集上进行的广泛实验表明,在交叉事件、跨数据集和早期谣言检测方面有了实质性的改进。
谣言检测——(PSA)《Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks》的更多相关文章
- 谣言检测(ClaHi-GAT)《Rumor Detection on Twitter with Claim-Guided Hierarchical Graph Attention Networks》
论文信息 论文标题:Rumor Detection on Twitter with Claim-Guided Hierarchical Graph Attention Networks论文作者:Erx ...
- 谣言检测——《MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection》
论文信息 论文标题:MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection论文作者:Jiaqi Zheng, ...
- 谣言检测(GACL)《Rumor Detection on Social Media with Graph Adversarial Contrastive Learning》
论文信息 论文标题:Rumor Detection on Social Media with Graph AdversarialContrastive Learning论文作者:Tiening Sun ...
- 谣言检测(PLAN)——《Interpretable Rumor Detection in Microblogs by Attending to User Interactions》
论文信息 论文标题:Interpretable Rumor Detection in Microblogs by Attending to User Interactions论文作者:Ling Min ...
- 谣言检测(PSIN)——《Divide-and-Conquer: Post-User Interaction Network for Fake News Detection on Social Media》
论文信息 论文标题:Divide-and-Conquer: Post-User Interaction Network for Fake News Detection on Social Media论 ...
- 谣言检测(RDEA)《Rumor Detection on Social Media with Event Augmentations》
论文信息 论文标题:Rumor Detection on Social Media with Event Augmentations论文作者:Zhenyu He, Ce Li, Fan Zhou, Y ...
- 谣言检测()——《Debunking Rumors on Twitter with Tree Transformer》
论文信息 论文标题:Debunking Rumors on Twitter with Tree Transformer论文作者:Jing Ma.Wei Gao论文来源:2020,COLING论文地址: ...
- 谣言检测()《Data Fusion Oriented Graph Convolution Network Model for Rumor Detection》
论文信息 论文标题:Data Fusion Oriented Graph Convolution Network Model for Rumor Detection论文作者:Erxue Min, Yu ...
- 谣言检测()《Rumor Detection with Self-supervised Learning on Texts and Social Graph》
论文信息 论文标题:Rumor Detection with Self-supervised Learning on Texts and Social Graph论文作者:Yuan Gao, Xian ...
随机推荐
- CF1703C Cypher 题解
题意:模拟一个 \(n\) 位密码锁. 做法:直接模拟,注意往后推,即若为 \(U\) 变为 \(D\),若为 \(D\) 变为 \(U\).注意 \(0\) 和 \(9\) 进行操作时的特判. #i ...
- ShardingSphere数据库读写分离
码农在囧途 最近这段时间来经历了太多东西,无论是个人的压力还是个人和团队失误所带来的损失,都太多,被骂了很多,也被检讨,甚至一些不方便说的东西都经历了,不过还好,一切都得到了解决,无论好坏,这对于个人 ...
- 从零开始搭建Vue2.0项目(一)之快速开始
从零开始搭建Vue2.0项目(一)之项目快速开始 前言 该样板适用于大型,严肃的项目,并假定您对Webpack和有所了解vue-loader.确保还阅读vue-loader的文档,了解常见的工作流程配 ...
- 缓冲流的原理和BufferedOutputStream字节缓冲输出流
缓冲流的原理 BufferedOutputStream字节缓冲输出流 package com.yang.Test.BufferedStudy; import java.io.BufferedOutpu ...
- vscode 个人配置 settings.json
{ "workbench.colorTheme": "Default Dark+", "workbench.iconTheme&quo ...
- MySQL主从复制之并行复制说明
传统单线程复制说明 众所周知,MySQL在5.6版本之前,主从复制的从节点上有两个线程,分别是I/O线程和SQL线程. I/O线程负责接收二进制日志的Event写入Relay Log. SQL线程读取 ...
- React报错之useNavigate() may be used only in context of Router
正文从这开始~ 总览 当我们尝试在react router的Router上下文外部使用useNavigate 钩子时,会产生"useNavigate() may be used only i ...
- 节后复工,Apache DolphinScheduler喜迎7位新Committer
Apache DolphinScheduler(Incubating)社区在节后上周第一周就迎来了好消息,经过 Apache DolphinScheduler PPMC 们的推荐和投票,我们高兴的宣布 ...
- MySQL的三值逻辑
MySQL 采用三值逻辑 SELECT 1 = 1; SELECT 1 = 2; SELECT 1 = NULL; SELECT 1 != NULL; 上面四条语句的结果分别为: 可见MySQL采用三 ...
- Redis 14 发布订阅
参考源 https://www.bilibili.com/video/BV1S54y1R7SB?spm_id_from=333.999.0.0 版本 本文章基于 Redis 6.2.6 概述 Redi ...