MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection概述
1.针对的问题
为了在未修剪视频中建模时间关系,以前的多种方法使用一维时间卷积。然而,受核大小的限制,基于卷积的方法只能直接获取视频的局部信息,不能学习视频中时间距离较远的片段之间的直接关系。因此,这种方法不能模拟片段之间的远程交互作用,而这对动作检测可能很重要。
多头自注意力虽然可以对视频中的长期关系建模,然而,现有的方法依赖于在输入帧本身上对这种长期关系建模,一个时序token只包含很少的帧,这通常与动作实例的持续时间相比太短了。此外,在这种设置中,transformers需要明确地学习由于时间一致性而产生的相邻token之间的强关系,而这对于时间卷积来说很自然的(即局部归纳偏差)。因此,纯粹的transformer体系结构可能不足以建模复杂的动作检测时序依赖关系。
2.主要贡献
(1)提出了一种高效的ConvTransformer用于建模未修剪视频中的复杂时序关系;
(2)引入一个新分支来学习与实例中心相关的位置,这有助于在密集标注的视频中进行动作检测;
(3)在3个具有挑战性的密集标注动作数据集上改进了最先进的技术。
3.方法
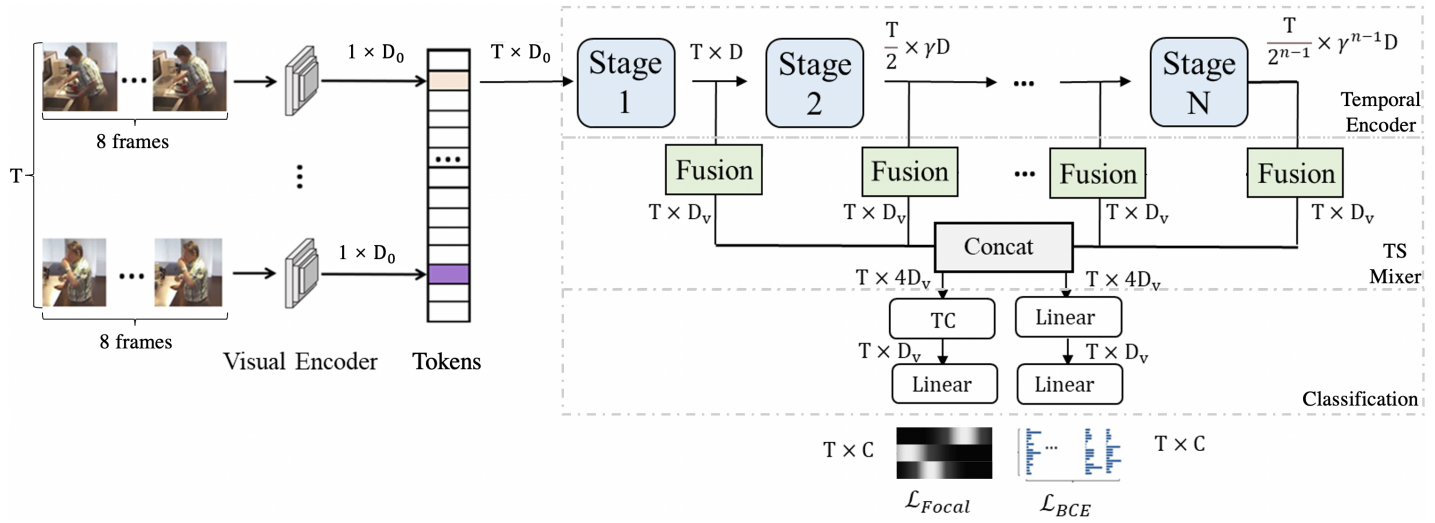
本文提出了一种新的transformer:MS-TCT,它继承了transformer编码器结构,同时利用了时间卷积技术。可以在不同的时间尺度上对全局和局部的时间token进行建模。
模型由4部分组成:
(1)对初步视频表示进行编码的视觉编码器(Visual Encoder),使用I3D主干编码视频。每个视频分为T个不重叠的片段(训练时),每个片段由8帧组成。这样的RGB帧作为输入片段提供给I3D网络。每一个片段级特征(I3D的输出)都可以看作是一个时间步的transformer token(即时序token)。沿着时间轴堆叠token,形成T × D0视频token表示,被送入时间编码器。
(2)在不同时间尺度上对时间关系进行结构建模的时间编码器(即时间编码器)。每个stage都为一个下面的模块
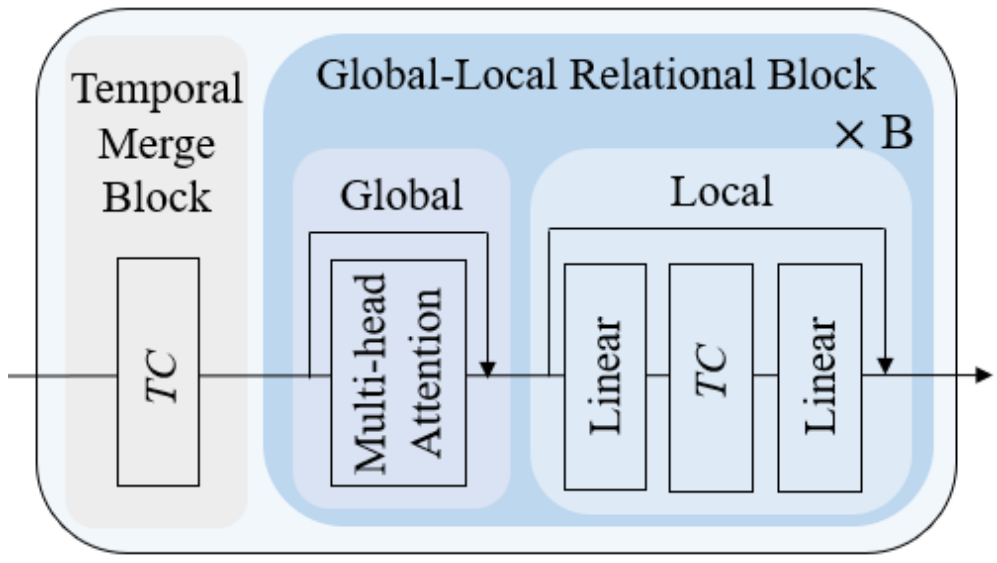
包括(1)一个时序合并块和(2)×B Global-Local关系块。每个全局-局部关系块包含一个全局和一个局部关系块。其中Linear和TC分别表示核大小为1和k的一维卷积层。早期阶段学习带有较多时序token的细粒度动作表示,而后期阶段学习带有较少时序token的粗粒度表示。
时间合并块可以减少token的数量(即时序分辨率),同时增加特征维数。通过单个卷积层将token数量减半,并将通道大小扩展×γ,Global-Local关系块包含全局关系块和局部关系块,前者通过多头自注意力层对长期动作依赖关系进行建模,后者使用一个时间卷积层通过输入来自相邻token的上下文信息(即局部归纳偏差)来增强token表示。每个阶段最后一个Global-Local关系块的输出token被组合并提供给下面的Temporal Scale Mixer。
(3)一个时间尺度混合器,称为TS混合器,它结合了多尺度的时间表征,将时间编码器产生的多尺度token聚合起来,形成统一的视频表示,具体结构如下:
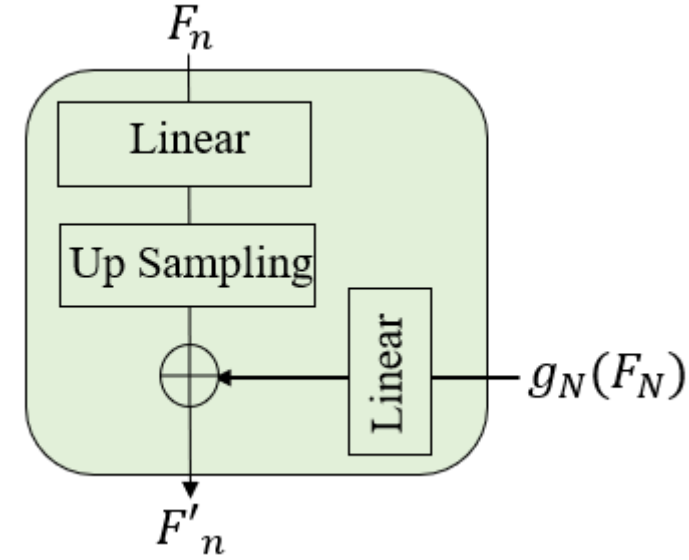
为了预测动作概率,分类模块需要以原始的时间长度作为网络输入进行预测。因此,通过执行上采样和线性投影步骤在时间维度上插入token,阶段n的输出tokens Fn调整大小并向上采样到T×Dv,由于早期阶段(低语义)具有较高的时间分辨率,而后期阶段(高语义)具有较低的时间分辨率。为了平衡分辨率和语义,最后一阶段N的上采样token经过线性层处理,并与每一阶段(N < N)上采样的token求和。最后,将所有refine tokens串联起来,得到最终的多尺度视频表示Fv∈RT×NDv。
(4)一个分类模块,预测类的概率。联合学习两个分类任务,引入了一个新的分类分支来学习动作实例的热图,它基于动作中心和持续时间而随时间变化。使用这种热图表示的目的是在学习到的MS-TCT tokens中编码时间相对位置。首先需要构建class-wise ground-truth热图响应,通过考虑一组一维高斯滤波器的最大响应构建了G∗ 。每个高斯滤波器对应于视频中的一个动作类实例,在时间上以特定的动作实例为中心。然后在预测的热图和ground-truth热图间应用action focus loss,另一个分支执行常见的多标签分类,通过BCE损失进行训练。
模型结构如下:
MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection概述的更多相关文章
- Temporal Action Detection with Structured Segment Networks (ssn)【转】
Action Recognition: 行为识别,视频分类,数据集为剪辑过的动作视频 Temporal Action Detection: 从未剪辑的视频,定位动作发生的区间,起始帧和终止帧并预测类别 ...
- 论文阅读: End-to-end Learning of Action Detection from Frame Glimpses in Videos
End-to-End Learning of Action Detection from Frame Glimpses in Videos CVPR 2016 Motivation: 本 ...
- Object Detection / Human Action Recognition 项目
https://towardsdatascience.com/real-time-and-video-processing-object-detection-using-tensorflow-open ...
- 【论文笔记】Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition 2018-01-28 15:4 ...
- 行为识别(action recognition)相关资料
转自:http://blog.csdn.net/kezunhai/article/details/50176209 ================华丽分割线=================这部分来 ...
- 【计算机视觉】行为识别(action recognition)相关资料
================华丽分割线=================这部分来自知乎==================== 链接:http://www.zhihu.com/question/3 ...
- ASP.NET MVC的Action Filter
一年前写了一篇短文ASP.NET MVC Action Filters,整理了Action Filter方面的资源,本篇文章详细的描述Action Filter.Action Filter作为一个可以 ...
- Recent papers on Action Recognition | 行为识别最新论文
CVPR2019 1.An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognit ...
- .Net MVC 自定义Action类型,XmlAction,ImageAction等
MVC开发的时候,难免会用到XML格式数据,如果将XML数据当作字符串直接返回给前台,其实这不是真正意义上的xmL,你可以看到ContentType是text/html而非XML类型,这往往会造成前端 ...
- 老刘 Yii2 源码学习笔记之 Action 类
Action 的概述 InlineAction 就是内联动作,所谓的内联动作就是放到controller 里面的 actionXXX 这种 Action.customAction 就是独立动作,就是直 ...
随机推荐
- MAUI新生4.6-主题设置LightTheme&DarkTheme
通过主题设置,可以在运行时更改应用的主题外观,比如切换亮色主题和暗黑主题.主题设置并没有新的知识点,基本的原理如下: 定义每个应用主题的ResourceDictionary,每个ResourceDic ...
- go的grpc环境源码编译安装
go的grpc环境安装 参考grpc-go官方文档:https://grpc.io/docs/languages/go/quickstart/ 视频教程:https://www.bilibili.co ...
- WCF 服务容器化的一些问题
背景 目前项目当中存有 .NET Framework 和 .NET Core 两种类型的项目,但是都需要进行容器化将其分别部署在 Windows 集群和 Linux 集群当中.在 WCF 进行容器化的 ...
- [python]《Python编程快速上手:让繁琐工作自动化》学习笔记3
1. 组织文件笔记(第9章)(代码下载) 1.1 文件与文件路径 通过import shutil调用shutil模块操作目录,shutil模块能够在Python 程序中实现文件复制.移动.改名和删除: ...
- Java学习笔记:2022年1月11日
Java学习笔记:2022年1月11日 摘要:这篇笔记主要讲解了一些数据在计算机中的存在方式相关的知识点,并由此延伸出了数据在计算机中的操作以及一些数据结构的知识. @ 目录 Java学习笔记:2 ...
- 线段树套线性基——题解P4839 P哥的桶
文章历史 2022-08-03: 文章初稿,由于对算法介绍过于少而被管理员打回重造. 2020-08-06:将算法介绍进行扩写,并删除了一些可有可无的内容或玩梗内容. 管理员审核题解辛苦了. 简要题意 ...
- Matplotlib学习笔记1 - 上手制作一些图表吧!
Matplotlib学习笔记1 - 上手制作一些图表吧! Matplotlib是一个面向Python的,专注于数据可视化的模块. 快速上手 这是使用频率最高的几个模块,在接下来的程序中,都需要把它们作 ...
- CDH-hive内进行删除操作
hive安装后需要修改已建的表及查询操作,在执行修改操作时遇到了如下问题. hive> update dp set name='beijing' where id=1159; FAILED: ...
- 今天学到的新知识--自己的电脑可以像Github Pages、码云 Pages一样发布静态资源
大佬教我的,感觉这个很神奇哦 假设下面这个路径是我的本地电脑静态资源路径 打开powershell窗口 然后按照下图的样子执行命令 复制网址就可以访问啦 然后可以通过 https://iplocati ...
- Python开发的常用组件
1. 生成6位数字随机验证码 import random import string def num_code(length=6): """ 生成长度为length的数字 ...