技术专家说 | 如何基于 Spark 和 Z-Order 实现企业级离线数仓降本提效?
市场的变幻,政策的完善,技术的革新……种种因素让我们面对太多的挑战,这仍需我们不断探索、克服。
今年,网易数帆将持续推出新栏目「金融专家说」「技术专家说」「产品专家说」等,聚集数帆及合作伙伴的数字化转型专家天团,聚焦大数据、云原生、人工智能等科创领域,带来深度技术解读及其在各行业落地应用等一系列知识分享,为企业数字化转型成功提供有价值的参考。

今天由网易数帆大数据离线技术专家尤夕多带来能帮助标准化企业级离线数仓优化存储,提高性能,且已在网易内部实践验证过的成熟技术方案,为大家提供技术思路参考。
一、Spark 企业级离线数仓面临的痛点
企业级数仓类的任务基本以 ETL 类型为主,典型的读取多张表的数据经过一系列 SQL 算子转换后写到一张表。那么除了在性能上 Spark3 已经有了充分的保障,剩下的使用痛点集中在了写这个环节。Hive 和 Spark2 在写这个环节也存在很多问题,比如小文件&文件倾斜,数据压缩率不理想,动态分区写难以优化。针对这些问题,下面我们逐个分析当前的状况,并给出新的解决方案。
小文件 & 文件倾斜
传统的解决方案是在 SQL 后面增加一个 DISTRIBUTE BY $columns ,这本质上是增加一次额外的 Shuffle 来对数据重新分区,产出的文件质量强依赖于这个 Shuffle 字段,然而在大部分场景中,数据倾斜是必然的,这造成了部分计算分区需要处理特别大的数据量,不仅带来文件倾斜问题,在性能上也会拖累整个任务完成时间。
对执行引擎有一定了解的同学可能会用非常 hack 方式来优化DISTRIBUTE BY rand() * files,但是这无论是我们内部已经复现的 rand() 导致数据不一致,还是 Spark 社区抛出来的问题:Repartition + Stage retries could lead to incorrect data ,都足以证明这是一个有缺陷的方案,可能会导致数据不一致,我们应当避免这种使用方式。
除此之外,一些有经验的同学会通过取模的方式来调整倾斜的数据,比如DISTRIBUTE BY columncolumn % 100, columncolumn。这是一种可行的解决方案,但存在几个缺陷:
1)存在优化上限;通过优化调试很难判断最佳的取模范围,只能给一个相对可以接受的优化结果
2)有很大的优化代价;需要非常了解字段的数据分布情况,再经过不断调试验证最终找到较为合理的值
3)维护成本比较高;可能过1个月,数据发生了一些变化,那么之前优化的取模值就变得不合理
数据压缩率不理想
传统的解决方案是在 SQL 后面增加一个 SORT BY column,这本质上是在写之前增加一次分区内的排序来提高数据压缩率。或者结合Shuffle增加DISTRIBUTEBYcolumn,这本质上是在写之前增加一次分区内的排序来提高数据压缩率。或者结合 Shuffle增加 DISTRIBUTE BY column,这本质上是在写之前增加一次分区内的排序来提高数据压缩率。或者结合Shuffle增加DISTRIBUTEBYcolumns SORT BY $columns 让相同数据落到一个分区后再做局部排序进一步提高数据压缩率。那么问题来了,首先这也绕不过 小文件 & 文件倾斜的问题,这里就不再重复。其次传统的字典排序不能很好的保留多维场景下数据的聚集分布,这里的多维在数仓场景下可以理解成多字段。而优秀的数据聚集分布可以在查询阶段提高数据文件的 Data Skipping 比例。我们目前大部分任务都只考虑任务本身的性能,需要逐渐重视下游任务查询的性能,从而形成一个良好的循环。
动态分区写场景难以优化
动态分区一般出现在写大表的任务,单天的数据量往往超过 1TB,当然从业务角度出发这是合理的,拆分区后下游任务查询非常灵活高效。但是动态分区类的任务本身优化就非常麻烦,自带小文件问题,压缩率不高,加上数据量大,这简直就是“强强联合”。而且仔细思考一下就可以发现,动态分区场景下,小文件和压缩率其实是互斥的,如果以尽可能少的文件数优先,那么我们需要考虑用分区字段作为 Shuffle 和排序字段,让相同分区数据落到一个计算分区内,但是压缩率高低却取决于其他数据字段,造成低压缩率现象。而如果以压缩率优先,那么我们需要考虑数据字段作为 Shuffle 和排序字段,但此时相同分区数据会落到不同计算分区,产生大量小文件。
面对这一系列问题,我们基于Spark3 + Z-Order提出了以下这些解决方案,并且已经在线上环境取得了非常好的效果。
二、Rebalance + Z-Order
2.1 方案介绍
Z-Order 是一种可以将多维数据压缩到一维的技术,在时空索引以及图像方面使用较广。Z曲线可以以一条无限长的一维曲线填充任意维度的空间,对于数据库的一条数据来说,我们可以将其多个要排序的字段看作是数据的多个维度,z曲线可以通过一定的规则将多维数据映射到一维数据上,构建 z-value 进而可以基于该一维数据进行排序。
基于最经典的使用方式DISTRIBUTE BY + SORT BY,我们提出了新一代的优化方案REBALANCE + Z-Order。REBALANCE 可以在尽可能满足 DISTRIBUTE BY 语义的情况下同时解决 小文件 & 文件倾斜问题。这里用“尽可能满足”这个词是因为,文件倾斜本质上是由于计算分区倾斜导致,那么我们把倾斜分区拆成多个的同时也就破坏了 DISTRIBUTE BY 语义,当然这不影响数准确性,也不会带来其他问题。基于 Z-Order 算法的排序替换了默认的字典排序,允许在多维场景下继续保留多维数据的聚集分布,在提高压缩率的同时可以加速下游任务的查询性能。
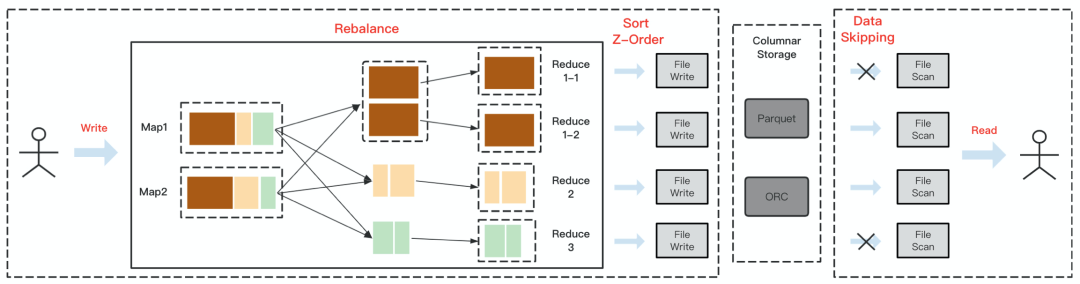
图1 Rebalance + Z-Order
上图展示了Rebalance + Z-Order 运作原理,涉及表的上游任务以及下游任务。首先 Rebalance 以Shuffle 的形式存在,并在 Shuffle 读阶段做分区的拆分和合并,保证每个 Reduce 分区处理相同规模的数据量。基于 Z-Order 的 Data Skipping 优化强依赖于文件格式,我们知道 Parquet 和 ORC 这类主流的列式存储格式会在写数据的同时记录数据的统计信息,比如 Parquet默认会以 Row Group 粒度记录字段的min/max 值,在查询这个文件的过程中,我们会把被 Push Down 的谓语条件和这些统计值做对比,如果不满足条件那么我们可以直接 Skip 这个 Row Group 甚至整个文件,避免拉取无效的数据,这就是 Data Skipping 过程。
2.2 案例分析
落地到具体任务中,可以进行从 Spark2 升级到 Spark3 再做 Z-Order 优化的操作。
- Spark2 -> Spark3
在实际操作中,由于引入了一次 Shuffle,任务会多一个 Stage,但执行时间却大幅度缩短。这是因为原本的任务在最后一个 Stage 存在数据膨胀和严重倾斜的情况,导致单个计算分区处理的数据量非常大。经过 Rebalance 后,额外的 Stage 把膨胀的数据打散,并且解决了倾斜问题,最终得到了 4 倍性能提升。不过此时出现了另一个问题,数据压缩率下降了,计算分区内的数据膨胀+倾斜虽然跑的慢,反而有着较高的压缩率。
- Spark3 + Z-Order
为了解决压缩率的问题,我们增加了 Z-Order 优化,可以看到压缩率提升了 12 倍 ,对比 Spark2 时期的任务也有近 25% 的提升。而且由于 IO 下降,计算性能也没有因为多一次 Z-Order 变慢。从而实现同时治理任务性能,小文件以及数据压缩率的目标。
三、Two-Phase Rebalance + Z-Order
3.1 方案介绍
前面我们提到过,动态分区场景下小文件和数据压缩率其实是互斥的,但是显然相比于在业务层面的优化,我们还是有很大的空间在引擎层面同时改善这两个痛点。我们提出了Two-Phase Rebalance + Z-Order,以压缩率优先的前提下尽可能减少小文件。
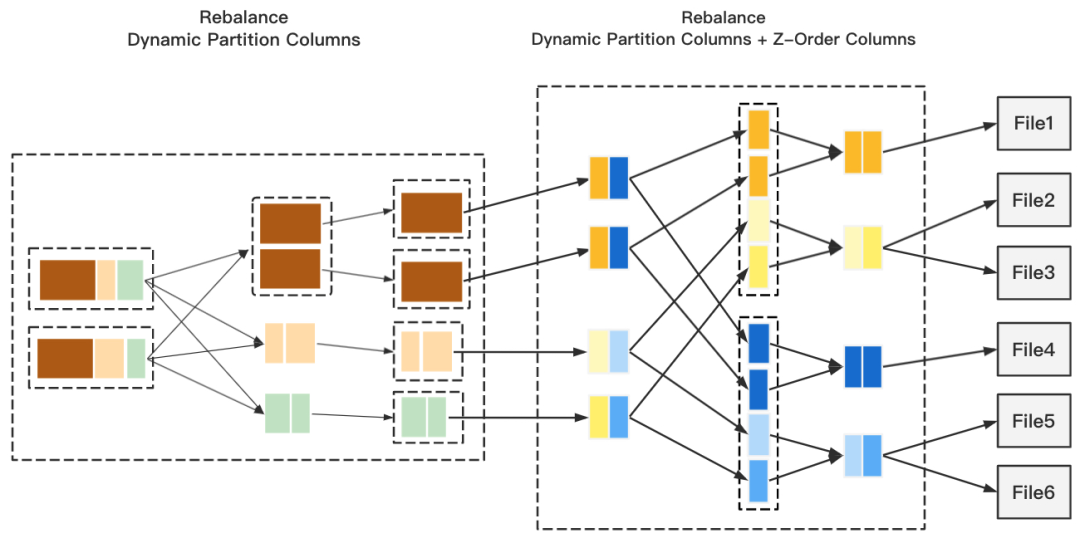
图2 Two-Phase Rebalance
如上图,整个流程分由2阶段Rebalance + Z-Order 组成,第一阶段的 Rebalance 我们采用动态分区字段,目的是把文件数降到最低,但是此时压缩率是不高的,第二阶段的 Rebalance 采用动态分区字段 + Z-Order 字段,保证输出最大的压缩率,最后通过 Z-Order 完成分区内的排序。这里可能有同学会问,为什么第二阶段 Rebalance 不会产生小文件?这是由于AQE Shuffle Read 在拆分 Reduce 分区过程中继承了 Map 顺序性,也就是说 Redcue 分区拉取到的 Map 一定是连续的,而我们在第一阶段 Rebalance 后,连续的 Map 意味着他们拥有相同的分区值,所以我们可以实现尽可能的避免小文件产生。
3.2 案例分析
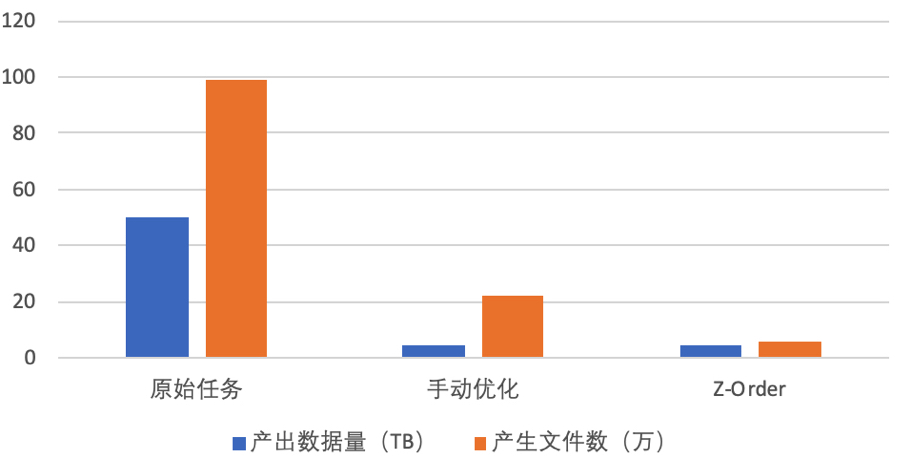
图3 对比图
上图展示了一个任务从手动优化切换到 Z-Order 优化的效果,手动优化也是采用前面提到的DISTRIBUTE BY + SORT BY 结合取模的方式,当然手动优化前的任务更加惨不忍睹。Two-Phase Rebalance + Z-Order 优化后,压缩率相比手动优化提升近 13%,相比原始任务提升近 8 倍,文件数相比手动优化下降近 3 倍,相比原始任务下降近 14 倍。与此同时,任务计算性能也有近 15% 的提升。
四、Two Phase Rebalance + Z-Order + Zstd
4.1 方案介绍
Two Phase Rebalance + Z-Order 已经满足了优化的需求,但是由于相比手动优化会多一次 Shuffle,导致任务过程中的 Shuffle 数据量会增加。这是临时数据,在任务结束后会自动清理,但如果我们本地磁盘冗余不够,也会出现存储空间不足的问题。因此我们引入了更高压缩率的算法 Zstd,在尽可能减少对任务性能影响的前提下减少 Shuffle 过程数据量。
4.2 案例分析
在具体案例中,两种压缩算法有一些区别,Zstd 相比于默认的 Lz4 节省近 60% Shuffle 数据,并且测试下来无明显性能影响,这是由于 IO 大幅度减少弥补了额外的 cpu 耗时。未来,我们的团队也会针对 Zstd 做更多的推广优化。
小结
本文介绍了我们基于 Spark3 + Z-Order对于企业级离线数仓类任务的优化方案,初步解决了当前在迁移和在历史使用 Spark 的痛点。过程中也有一些体会和感悟:没有一种技术方案可以完美解决所有的问题,但我们也要尽力去找到那个需要妥协的点,而在此之前,优化空间是巨大的。
专家介绍
尤夕多
网易数帆大数据离线技术专家,Apache Kyuubi PMC member,Apache Spark Contributor。
作者:网易数帆社区
链接:https://juejin.cn/post/7132809068011339812/
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
技术专家说 | 如何基于 Spark 和 Z-Order 实现企业级离线数仓降本提效?的更多相关文章
- 基于Spark和SparkSQL的NetFlow流量的初步分析——scala语言
基于Spark和SparkSQL的NetFlow流量的初步分析--scala语言 标签: NetFlow Spark SparkSQL 本文主要是介绍如何使用Spark做一些简单的NetFlow数据的 ...
- 基于Spark的电影推荐系统(推荐系统~7)
基于Spark的电影推荐系统(推荐系统~7) 22/100 发布文章 liuge36 第四部分-推荐系统-实时推荐 本模块基于第4节得到的模型,开始为用户做实时推荐,推荐用户最有可能喜爱的5部电影. ...
- 基于Spark ALS构建商品推荐引擎
基于Spark ALS构建商品推荐引擎 一般来讲,推荐引擎试图对用户与某类物品之间的联系建模,其想法是预测人们可能喜好的物品并通过探索物品之间的联系来辅助这个过程,让用户能更快速.更准确的获得所需 ...
- 【基于spark IM 的二次开发笔记】第一天 各种配置
[基于spark IM 的二次开发笔记]第一天 各种配置 http://juforg.iteye.com/blog/1870487 http://www.igniterealtime.org/down ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...
- UserView--第一种方式set去重,基于Spark算子的java代码实现
UserView--第一种方式set去重,基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import java.util.Ha ...
- 基于Spark自动扩展scikit-learn (spark-sklearn)(转载)
转载自:https://blog.csdn.net/sunbow0/article/details/50848719 1.基于Spark自动扩展scikit-learn(spark-sklearn)1 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
随机推荐
- SpringCloud 客户端负载均衡:Ribbon
目录 Ribbon 介绍 开启客户端负载均衡,简化 RestTemplate 调用 负载均衡策略 Ribbon 介绍 Ribbon 是 Netflix 提供的一个基于 Http 和 TCP 的客户端负 ...
- Eclipse for C/C++ 开发环境部署保姆级教程
Eclipse for C/C++ 开发环境部署保姆级教程 工欲善其事,必先利其器. 对开发人员来说,顺手的开发工具必定事半功倍.自学编程的小白不知道该选择那个开发工具,Eclipse作为一个功能强大 ...
- 【Azure 应用服务】NodeJS Express + MSAL 实现API应用Token认证(AAD OAuth2 idToken)的认证实验 -- passport.authenticate('oauth-bearer', {session: false})
问题描述 在前两篇博文中,对NodeJS Express应用 使用MSAL + AAD实现用户登录并获取用户信息,获取Authorization信息 ( ID Token, Access Token) ...
- ASP.NET Core 应用配置指定地址和端口
更新记录 本文迁移自Panda666原博客,原发布时间:2021年5月10日. 几种方式 ASP.NET Core 应用配置指定地址和端口支持以下几种主要方式: 1.在命令行模式启动应用时设置 --u ...
- 【RocketMQ】NameServer的启动
NameServer是一个注册中心,Broker在启动时向所有的NameServer注册,生产者Producer和消费者Consumer可以从NameServer中获取所有注册的Broker列表,并从 ...
- Bika LIMS 开源LIMS集—— SENAITE的安装
安装环境 操作系统 Ubuntu 18.04 LTS Python 2.x. Plone 4 安装步骤 Ubuntu等Linux.Mac系统一般安装有Python的环境,但由于需要安装Python扩展 ...
- canal的使用
一.简介 canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实 ...
- 3D还原货拉拉女孩身亡真相,这一环值得反思!
货拉拉女孩跳车身亡的消息,让人惋惜又震惊.司机多次偏离原始路线,女孩最终选择跳车,结果不幸身亡. 货拉拉女孩跳车真相被3D还原 有人质疑平台监管不力,造成如此惨剧,有人吐槽企业压榨员工,司机绕路是不得 ...
- Event Loop我知道,宏任务微任务是什么鬼?
在介绍宏任务和微任务之前,先抛出一个问题.相信大家在面试的时候,会遇到这样的相似的问题: setTimeout(function(){undefined console.log('1') }); ne ...
- SAP ABAP 快速入门之 开发环境 (Environment)
报表是学习ABAP 原则和工具的很好的 起点.ABAP 报表在许多领域都有使用,本章将介绍简单ABAP 报表的开发. Hello ABAP 让我们以'Hello World' 开始. 每一个abap ...