小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现
小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现
上一章我们聊了聊通过一致性正则的半监督方案,使用大量的未标注样本来提升小样本模型的泛化能力。这一章我们结合FGSM,FGM,VAT看下如何使用对抗训练,以及对抗训练结合半监督来提升模型的鲁棒性。本章我们会混着CV和NLP一起来说,VAT的两篇是CV领域的论文,而FGM是CV迁移到NLP的实现方案,一作都是同一位作者大大。FGM的tensorflow实现详见Github-SimpleClassification
我们会集中讨论3个问题
- 对抗样本为何存在
- 对抗训练实现方案
- 对抗训练为何有效
存在性

对抗训练
下面我们看下如何在模型训练过程中引入对抗样本,并训练模型给出正确的预测
监督任务
这里的对抗训练和GAN这类生成对抗训练不同,这里的对抗主要指微小扰动,在CV领域可以简单解释为肉眼不可见的轻微扰动(如下图)

不过两类对抗训练的原理都可以被经典的min-max公式涵盖
- max:对抗的部分通过计算delta来最大化损失
- min:训练部分针对扰动后的输入进行训练最小化损失函数
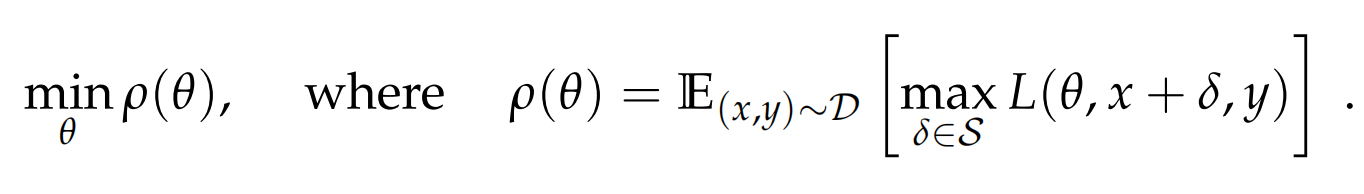
以上损失函数的视角,也可以切换成成极大似然估计的视角,也就是FGM中如下的公式,通过计算r,来使得扰动后y的条件概率最小化

于是问题就被简化成了如何计算扰动。最简单的方案就是和梯度下降相同沿用当前位置的一阶导数,梯度下降是沿graident去最小化损失,那沿反方向进行扰动不就可以最大化损失函数。不过因为梯度本身是对当前位置拟合曲线的线性化,所以需要控制步长来保证局部的线性,反向传播中我们用learning rate来控制步长,这里则需要控制扰动的大小。同时对抗扰动本身也需要控制扰动的幅度,不然就不符合微小扰动这个前提,放到NLP可以理解为为了防止扰动造成语义本身产生变化。
FGSM使用了\(l_{\infty}\) norm来对梯度进行正则化,只保留了方向信息丢弃了gradient各个维度上的scale
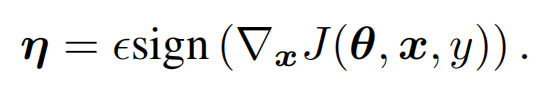
而FGM中作者选择了l2 norm来对梯度进行正则化,在梯度上更多了更多的信息,不过感觉在模型初始拟合的过程中也可能引入更多的噪音。

有了对抗样本,下一步就是如何让模型对扰动后的样本给出正确的分类结果。所以最简单的训练方式就是结合监督loss,和施加扰动之后的loss。FGSM中作者简单用0.5的权重来做融合。所以模型训练的方式是样本向前传递计算Loss,冻结梯度,计算扰动,对样本施加扰动再计算Loss,两个loss加权计算梯度。不过部分实现也有只保留对抗loss的操作,不妨作为超参对不同任务进行调整~
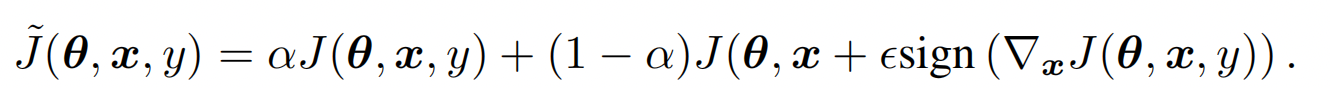
在使用对抗扰动时有两个需要注意的点
- 施加扰动的位置:对输入层扰动更合理
- 扰动和扰动层的scale:扰动层归一化
对于CV任务扰动位置有3个选择,输入层,隐藏层,或者输出层,对于NLP任务因为输入离散,所以输入层被替换成look up之后的embedding层。
作者基于万能逼近定理【简单说就是一个线性层+隐藏层如果有unit足够多可以逼近Rn上的任意函数0】指出因为输出层本身不满足万能逼近定理条件,所以对输出层(linear-softmax layer)扰动一般会导致模型underfit,因为模型会没有足够的能力来学习如何抵抗扰动。
而对于激活函数范围在[-inf, inf]的隐藏层进行扰动,会导致模型通过放大隐藏层scale来忽略扰动的影响。
因此一般是对输入层进行扰动,在下面FGM的实现中作者对word embedding进行归一化来规避上面scale的问题。不过这里有一个疑问就是对BERT这类预训练模型是不能对输入向量进行归一化的,那么如何保证BERT在微调的过程中不会通过放大输入层来规避扰动呢?后来想到的一个点是在探测Bert Finetune对向量空间的影响中提到的,微调对BERT各个层的影响是越接近底层影响越小的,所以从这个角度来说也是针对输入层做扰动更合理些~
半监督任务
以上的对抗训练只适用于标注样本,因为需要通过loss来计算梯度方向,而未标注样本无法计算loss,最简单的方案就是用模型预估来替代真实label。于是最大化loss的扰动,变成使得预测分布变化最大的扰动。
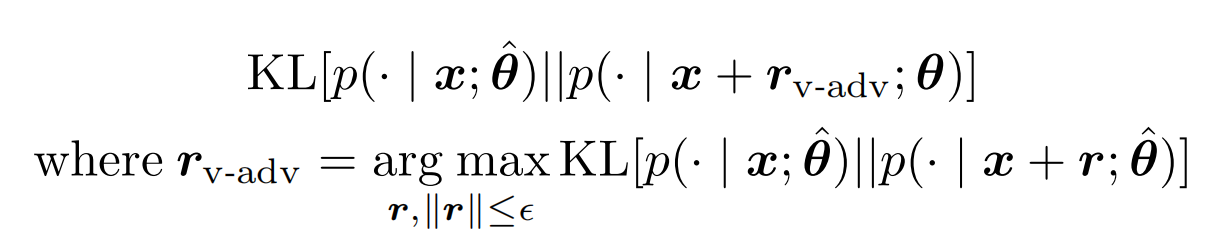
以上的虚拟扰动r无法直接计算,于是泰勒展开再次登场,不过这里因为把y替换成了模型预估p,所以一阶导数为0,于是最大化KL近似为最大化二阶导数的部分
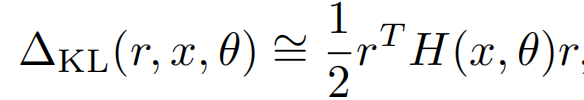
而以上r的求解,其实就是求解二阶海森矩阵的最大特征值对应的特征向量,以下u就是最大特征值对应的单位特征向量
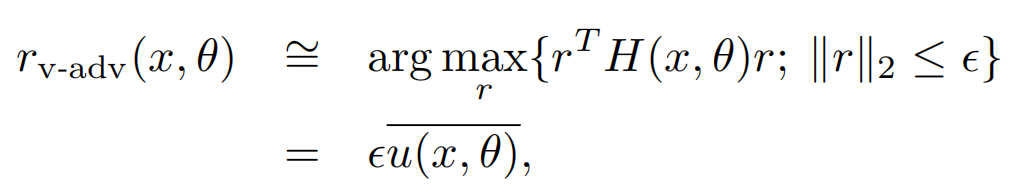
因为海森矩阵的计算复杂度较高,一般会采用迭代近似的方式来计算(详见REF12),简单说就是随机向量d(和u非正交),通过反复的下述迭代会趋近于u

而以上Hd同样可以被近似计算,因为上面KL的一阶导数为0,所以我们可以用KL~rHr的一阶差分来估计Hd,于是也就得了d的近似值
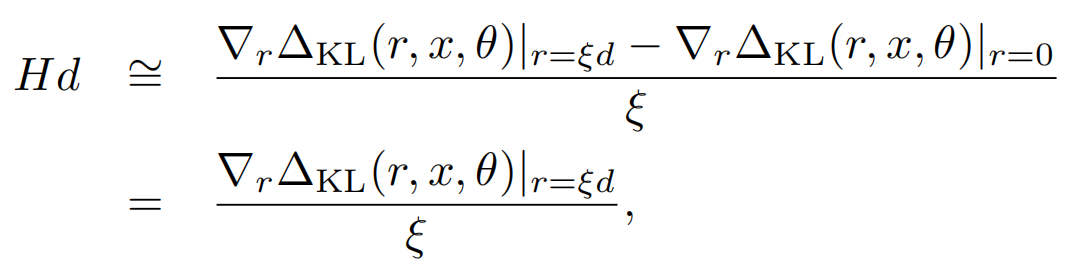
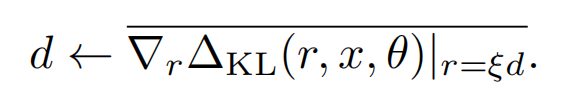

哈哈近似了一圈估计有的盆友们已经蒙圈了,可以对照着下面的计算方案再回来理解下上面的公式,计算虚拟扰动的算法如下(其中1~4可以多次迭代)
- 对embedding层施加随机扰动d
- 向前传递计算扰动后的logit
- 扰动logit和原始logit计算KL距离
- 对KL计算梯度
- 对梯度做归一化得到虚拟扰动的近似
- 对embedding层施加虚拟扰动,再计算一遍KL作为虚拟对抗部分的loss
这里暂时没有实现VAT因为时间复杂度有些高,之后有需要再补上VAT的部分
合理性
对抗扰动可以理解为一种正则方案,核心是为了提高模型鲁棒性,也就是样本外的泛化能力,这里给出两个视角
- 对比L1正则

- 对比一致性正则
这里和上一章我们提到的半监督之一致性正则有着相通之处,一致性正则强调模型应该对轻微扰动的样本给出一致的预测,但并没有对扰动本身进行太多的探讨,而对抗训练的核心在于如何对样本进行扰动。但核心都是扩充标注样本的覆盖范围,让标注样本的近邻拥有一致的模型预测。
效果
FGM论文是在LSTM,Bi-LSTM上做的测试会有比较明显的2%左右ErrorRate的下降。我在BERT上加入FGM在几个测试集上尝试指标效果并不明显,不过这里开源数据上测试集和训练集相似度比较高,而FGM更多是对样本外的泛化能力的提升。不过我在公司数据上使用FMG输出的预测概率的置信度会显著下降,一般bert微调会容易得到0.999这类高置信度预测,而加入FGM之后prob的分布变得更加合理,这个效果更容易用正则来进行解释。以下也给出了两个比赛方案链接里面都是用fgm做了优化也有一些insights,感兴趣的朋友可能在你的测试集上也实验下~
不过一言以蔽之,FGM的对抗方案,主要通过正则来约束模型学习,更多是锦上添花,想要学中送碳建议盆友们脚踏实地的去优化样本,优化标注,以及确认你的任务目标定义是否合理~
Reference
- FGSM- Explaining and Harnessing Adversarial Examples, ICLR2015
- FGM-Adversarial Training Methods for Semi-Supervised Text Classification, ICLR2017
- VAT-Virtual adversarial training: a regularization method for supervised and semi-supervised learning
- VAT-Distributional Smoothing with Virtual Adversarial Training
- Min-Max公式 Towards Deep Learning Models Resistant to Adversarial Attacks
- FGM-TF实现
- VAT-TF实现
- NLP中的对抗训练
- 苏神yyds:对抗训练浅谈:意义、方法和思考(附Keras实现)
- 天池大赛疫情文本挑战赛线上第三名方案分享
- 基于同音同形纠错的问题等价性判别第二名方案
- Eigenvalue computation in the 20th century
小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现的更多相关文章
- 小样本利器1.半监督一致性正则 Temporal Ensemble & Mean Teacher代码实现
这个系列我们用现实中经常碰到的小样本问题来串联半监督,文本对抗,文本增强等模型优化方案.小样本的核心在于如何在有限的标注样本上,最大化模型的泛化能力,让模型对unseen的样本拥有很好的预测效果.之前 ...
- 小样本利器3. 半监督最小熵正则 MinEnt & PseudoLabel代码实现
在前两章中我们已经聊过对抗学习FGM,一致性正则Temporal等方案,主要通过约束模型对细微的样本扰动给出一致性的预测,推动决策边界更加平滑.这一章我们主要针对低密度分离假设,聊聊如何使用未标注数据 ...
- GAN实战笔记——第七章半监督生成对抗网络(SGAN)
半监督生成对抗网络 一.SGAN简介 半监督学习(semi-supervised learning)是GAN在实际应用中最有前途的领域之一,与监督学习(数据集中的每个样本有一个标签)和无监督学习(不使 ...
- 小样本利器4. 正则化+数据增强 Mixup Family代码实现
前三章我们陆续介绍了半监督和对抗训练的方案来提高模型在样本外的泛化能力,这一章我们介绍一种嵌入模型的数据增强方案.之前没太重视这种方案,实在是方法过于朴实...不过在最近用的几个数据集上mixup的表 ...
- cips2016+学习笔记︱NLP中的消岐方法总结(词典、有监督、半监督)
歧义问题方面,笔者一直比较关注利用词向量解决歧义问题: 也许你寄希望于一个词向量能捕获所有的语义信息(例如run即是动车也是名词),但是什么样的词向量都不能很好地进行凸显. 这篇论文有一些利用词向量的 ...
- 详解使用EM算法的半监督学习方法应用于朴素贝叶斯文本分类
1.前言 对大量需要分类的文本数据进行标记是一项繁琐.耗时的任务,而真实世界中,如互联网上存在大量的未标注的数据,获取这些是容易和廉价的.在下面的内容中,我们介绍使用半监督学习和EM算法,充分结合大量 ...
- 数据量与半监督与监督学习 Data amount and semi-supervised and supervised learning
机器学习工程师最熟悉的设置之一是访问大量数据,但需要适度的资源来注释它.处于困境的每个人最终都会经历逻辑步骤,当他们拥有有限的监督数据时会问自己该做什么,但很多未标记的数据,以及文献似乎都有一个现成的 ...
- [论文][半监督语义分割]Adversarial Learning for Semi-Supervised Semantic Segmentation
Adversarial Learning for Semi-Supervised Semantic Segmentation 论文原文 摘要 创新点:我们提出了一种使用对抗网络进行半监督语义分割的方法 ...
- 常见半监督方法 (SSL) 代码总结
经典以及最新的半监督方法 (SSL) 代码总结 最近因为做实验需要,收集了一些半监督方法的代码,列出了一个清单: 1. NIPS 2015 Semi-Supervised Learning with ...
随机推荐
- 学习打卡day14&&构建之法阅读笔记第二篇
对于书中所提到的结对编程我还是有些许感受的,在大二上学期我就有和同学合作,共同完成编码.有时候可能是我来做非常非常简易的前端页面部分,然后给同学一个基础框架,让同学往框架里面填充,时而遇到问题我再来沟 ...
- 如何离线安装posh-git
不用上github 1.下载post-git离线安装包 地址:https://files.cnblogs.com/files/xcr1234/posh-git-master.zip 2,用Powers ...
- python基础练习题(斐波那契数列)
day4 --------------------------------------------------------------- 实例006:斐波那契数列 题目 斐波那契数列. 题目没说清楚, ...
- VDO虚拟数据优化
VDOVirtual Data Optimize 虚拟数据优化 是一种通过压缩或删除存储设备上的数据来优化存储空间的技术. VDO 是红帽公司收购了 Permabit 公司后获取的新技术,并与2019 ...
- Mybatis Plus之内置Mapper实践
MyBatis Plus,作为对MyBatis的进一步增强,大大简化了我们的开发流程,提高了开发速度 配置 由于Mybatis Plus是建立在Mybatis之上的,所以其已经依赖了Mybatis,故 ...
- 2003031121-浦娟-python数据分析五一假期作业
项目 内容 课程班级博客链接 20级数据班(本) 这个作业要求链接 Python作业 博客名称 2003031121-浦娟-python数据分析五一假期作业 要求 每道题要有题目,代码(使用插入代码, ...
- .NET混合开发解决方案13 自定义WebView2中的上下文菜单
系列目录 [已更新最新开发文章,点击查看详细] WebView2控件应用详解系列博客 .NET桌面程序集成Web网页开发的十种解决方案 .NET混合开发解决方案1 WebView2简介 .NE ...
- 记录在EF Core级联更新时出现的错误The database operation was expected to affect 1 row(s), but actually affected 0 row(s) (低级错误导致)
错误提示:The database operation was expected to affect 1 row(s), but actually affected 0 row(s); data ma ...
- kvm 虚拟化技术 1.2之kvm基础操作
1.虚拟机基础操作 (1).查看.编辑.备份kvm配置文件以及查看kvm状态 [root@hd1 ~]# cd /etc/libvirt/qemu [root@hd1 qemu]# ls centos ...
- Jenkins安装详解
一.Jenkins是什么 Jenkins是一个独立的开源自动化服务器,可用于自动执行与构建,测试,交付或者部署软件相关的各种任务,是跨平台持续集成和持续交付应用程序,提高工作效率.使用Jenkins不 ...