用Python爬取文章,并转PDF格式电子书
wkhtmltopdf [软件],这个是必学准备好的,不然这个案例是实现不出来的
获取文章内容代码 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF)
发送请求, 对于url地址发送请求
解析数据, 提取内容
保存数据, 先保存成html文件
再把html文件转成PDF
代码实现 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF)
请求数据
python学习交流群:660193417###
import requests # 数据请求模块
url = f'https://blog.csdn.net/fei347795790/article/list/1' # 确定请求网址
# headers 请求头, 主要用于伪装python, 防止程序被服务器识别出来
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36'
}
# 用requests模块里面get方式发送请求
response = requests.get(url=url, headers=headers)
print(response.text)
<Response [200]> 响应对象 200 表示请求成功
解析数据, 提取内容 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF)
python学习交流群:660193417###
for index in href:
html_data = requests.get(url=index, headers=headers).text
selector_1 = parsel.Selector(html_data)
title = selector_1.css('#articleContentId::text').get()
content = selector_1.css('#content_views').get()
article_content = html_str.format(article=content)
print(title)
print(article_content)
break
保存数据 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF)
python学习交流群:660193417###
html_path = 'html\\' + title +'.html'
with open(html_path, mode='w', encoding=' utf-8') as f:
f.write(article_content)
print(title,'保存成功')

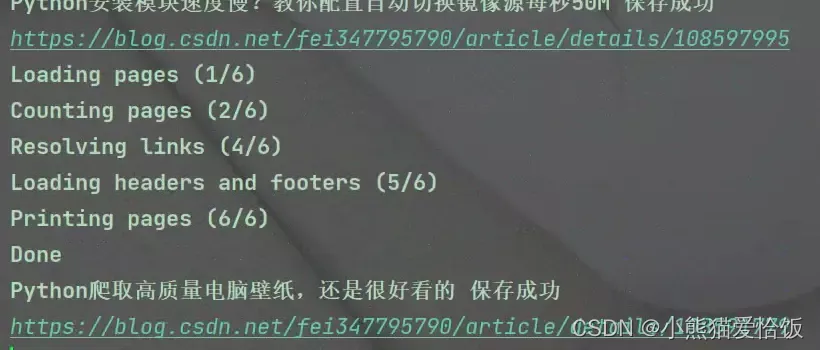
转制为pdf文件 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF)
html_path = 'html\\ + title + '.html'
pdf_path = 'pdf\\' + title + '.pdf'
with open(html_path, mode='w', encoding='utf-8') as f:
f.write(article_content)
config = pdfkit.configuration(wkhtmltopdf=r'C:\01-Software-installation\wkhtmltopdf\bin\wkhtmltopdf.exe')
ppdfkit.from_file(html_path,pdf_path,configuration=config)
print(title,'保存成功')
来!试试看!
用Python爬取文章,并转PDF格式电子书的更多相关文章
- python 爬取文章
这里我们利用强大的python爬虫来爬取一篇文章.仅仅做一个示范,更高级的用法还要大家自己实践. 好了,这里就不啰嗦了,找到一篇文章的url地址:http://www.duanwenxue.com/a ...
- 假期学习【十一】Python爬取百度词条写入csv格式 python 2020.2.10
今天主要完成了根据爬取的txt文档,从百度分类从信息科学类爬取百度词条信息,并写入CSV格式文件. txt格式文件如图: 为自己爬取内容分词后的结果. 代码如下: import requests fr ...
- 用Python抓取漫画并制作mobi格式电子书
想看某一部漫画,但是用手机看感觉屏幕太小,用电脑看吧有太不方面.正好有一部Kindle,决定写一个爬虫把漫画爬取下来,然后制作成 mobi 格式的电子书放到kindle里面看. 一.编写爬虫程序 用C ...
- python 爬取文章后存储excel 以及csv
import requests from bs4 import BeautifulSoup import random import openpyxl xls=openpyxl.Workbook() ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
- python爬取微信公众号
爬取策略 1.需要安装python selenium模块包,通过selenium中的webdriver驱动浏览器获取Cookie的方法.来达到登录的效果 pip3 install selenium c ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
随机推荐
- go sync.map源码解析
go中的map是并发不安全的,同时多个协程读取不会出现问题,但是多个协程 同时读写就会出现 fatal error:concurrent map read and map write的错误.通用的解决 ...
- 【面试普通人VS高手系列】什么叫做阻塞队列的有界和无界
昨天一个3年Java经验的小伙伴私信我,他说现在面试怎么这么难啊! 我只是面试一个业务开发,他们竟然问我: 什么叫阻塞队列的有界和无界.现在面试也太卷了吧! 如果你也遇到过类似问题,那我们来看看普通人 ...
- Java数组-2022年4月17日
目录 数组 数组Array 数组的常见异常 数组的遍历 数组的扩容 数组类型的返回值 可变长数组 排序算法 二维数组 测试代码 数组 数组Array ArrayList概念:一个连续的空间,存储多个相 ...
- Halo 开源项目学习(三):注册与登录
基本介绍 首次启动 Halo 项目时需要安装博客并注册用户信息,当博客安装完成后用户就可以根据注册的信息登录到管理员界面,下面我们分析一下整个过程中代码是如何执行的. 博客安装 项目启动成功后,我们可 ...
- 菜B的初来乍到。
1.简单自我介绍 031702220:我是默默无闻的黄恒杰:我的爱好是健身:我最喜欢紫荆园的青椒炒肉:薛之谦的<其实>:苦心人天不负,三千越甲可吞吴. 2.阅读与思考 (1)回想一下你初入 ...
- 干货长文:Linux 文件系统与持久性内存介绍
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 1.Linux 虚拟文件系统介绍 在 Linux 系统中一切皆文件,除了通常所说的狭义的文件以 ...
- Android8.0 后台服务保活的一种思路
原文地址:Android8.0 后台服务保活的一种思路 | Stars-One的杂货小窝 项目中有个MQ服务,需要一直连着,接收到消息会发送语音,且手机要在锁屏也要实现此功能 目前是使用广播机制实现, ...
- 使用WebDriverManager实现自动获取浏览器驱动程序
原理: 自动到指定的地址下载相应的浏览器驱动保存到缓存区 ~/.cache/selenium 痛点: 解决因Chrome浏览器升级,driver需要同步升级,要重新下载驱动的问题 区别: 传统方式 需 ...
- 不可不知的 MySQL 升级利器及 5.7 升级到 8.0 的注意事项
数据库升级,是一项让人喜忧参半的工程.喜的是,通过升级,可以享受新版本带来的新特性及性能提升.忧的是,新版本可能与老的版本不兼容,不兼容主要体现在以下三方面: 语法不兼容. 语义不兼容.同一个SQL, ...
- MySQL闪回工具之binlog2sql
一.binlog2sql 1.1 安装binlog2sql git clone https://github.com/danfengcao/binlog2sql.git && cd b ...